憨批的语义分割重制版11——Keras 搭建自己的HRNetV2语义分割平台
最近学了一下HRnet,代码真的好难看懂,还只有Pytorch版本的,Keras复现很有难度,作者写的逻辑很厉害,只能慢慢攻破啦!

传统的卷积神经网络模型是自上而下不断进行特征提取的,如VGG、Mobilenet、Resnet系列等,VGG网络中存在5个步长为(2, 2)最大池化,Mobilenet网络中存在5个步长为(2, 2)的逐层卷积,Resnet网络中存在5个步长为(2, 2)的普通卷积。
这些网络常常存在多个下采样的过程,输入进来的图片利用卷积或者最大池化进行高和宽的压缩。在特征提取的过程中,我们会获得不同形状的特征层。传统的卷积神经网络模型仅仅会有自上而下的特征提取,而HRNet则改变了传统卷积神经网络模型的工作模式,使得网络在工作时刻保持高分辨率特征图。通过下采样以及上采样,在网络进行特征提取时融合不同形状的特征。
最开始的HRNet被用于人体的姿态检测,该论文发表于2019年的CVPR上。在原来HRNet的基础上,官方修改出HRNetV2并且让他可以适应不同任务的需要,语义分割就是其中之一。HRNet提取出来的特征极其丰富,包含各种的分辨率,理论上可以适应不同的CV需求(目标检测、语义分割、实例分割等),本文以HRNetv2做分割为例,进行介绍。

整个HRNetV2由三部分组成,分别是主干部分、特征整合部分、预测头部分。如上图所示,灰色方框的左半部分就是主干部分,灰色部分与右半部分就是分割头部分。
在主干部分,HRNetV2会在特征提取的过程中同时进行下采样与上采样,在这个过程里会获得不同形状特征图并进行特征融合。
在特征整合部分,HRNetV2会将获取到的所有特征图进行特征融合,将宽高较小的特征图网上进行上采样,然后与最大的特征图进行特征融合,然后再利用1个卷积+标准化+激活函数进行特征整合。
在预测头部分,HRNetV2会利用一个卷积核为(1, 1)的卷积调整通道数为num_classes,利用resize进行上采样使得最终输出层,宽高和输入图片一样。。
Github源码下载地址为:
https://github.com/bubbliiiing/hrnet-keras
复制该路径到地址栏跳转。
上图是官方给出的HRNetV2用于分割的示意图,但其实这个图里面遗漏了一些细节。遗漏的细节容易引起误会。
上图将整个HRNetV2的主干分为四个部分,为了方便理解,我们将其命名为Section-1,Section-2,Section-3,Section-4.
Section-1是第一部分,用于进行初步的特征提取,在图中对应了最左边的四个方块。在实际代码中,图片处理的过程不仅仅包含这四个方块。
如果将该部分进行详细绘制,其本质上应该是这样的。

对于输入进来的图片,HRNetV2还会使用两次步长为(2, 2)、卷积核大小为(3, 3)、通道为64的卷积对输入图片进行高和宽的压缩与特征提取。
假设输入进来的图片是[480, 480, 3]的,在经过两次步长为(2, 2)、卷积核大小为(3, 3)、通道为64的卷积后,获得的特征层为[120, 120, 64]。
此时再进行四次bottleneck_Block。这里用到的bottleneck_Block,其实就是Resnet系列里面用到的残差卷积,主要用在Resnet50、Resnet101里面。
bottleneck_Block的结构如下图所示,bottleneck_Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,不经过处理或者经过少量处理直接与输出相接。

由图可知,结构分为两个情况:
如果不发生高宽以及通道的变化,则bottleneck_Block如左图所示,此时残差边不经过任何处理便直接与主干部分相接,输入特征层和输出特征层的shape是相同的。
如果发生高宽以及通道的变化,则bottleneck_Block如右图所示,此时残差边经过少量处理便直接和主干相接,可以改变输出特征层的宽高和通道数。
在经过四次bottleneck_Block后,我们获得的特征层的shape为[120, 120, 256]。
总体上,Section-1的构建代码如下:
def bottleneck_Block(input, out_filters, strides=(1, 1), with_conv_shortcut=False, name=""):
expansion = 4
de_filters = int(out_filters / expansion)
x = Conv2D(de_filters, 1, use_bias=False, kernel_initializer='he_normal', name=name+'.conv1')(input)
x = BatchNormalization(epsilon=1e-5, name=name+'.bn1')(x)
x = Activation('relu')(x)
x = Conv2D(de_filters, 3, strides=strides, padding='same', use_bias=False, kernel_initializer='he_normal', name=name+'.conv2')(x)
x = BatchNormalization(epsilon=1e-5, name=name+'.bn2')(x)
x = Activation('relu')(x)
x = Conv2D(out_filters, 1, use_bias=False, kernel_initializer='he_normal', name=name+'.conv3')(x)
x = BatchNormalization(epsilon=1e-5, name=name+'.bn3')(x)
if with_conv_shortcut:
residual = Conv2D(out_filters, 1, strides=strides, use_bias=False, kernel_initializer='he_normal', name=name+'.downsample.0')(input)
residual = BatchNormalization(epsilon=1e-5, name=name+'.downsample.1')(residual)
x = add([x, residual])
else:
x = add([x, input])
x = Activation('relu')(x)
return x
def stem_net(input):
x = ZeroPadding2D(((1, 1),(1, 1)))(input)
x = Conv2D(64, 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="conv1")(x)
x = BatchNormalization(epsilon=1e-5, name="bn1")(x)
x = Activation('relu')(x)
x = ZeroPadding2D(((1, 1),(1, 1)))(x)
x = Conv2D(64, 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="conv2")(x)
x = BatchNormalization(epsilon=1e-5, name="bn2")(x)
x = Activation('relu')(x)
x = bottleneck_Block(x, 256, with_conv_shortcut=True, name="layer1.0")
x = bottleneck_Block(x, 256, with_conv_shortcut=False, name="layer1.1")
x = bottleneck_Block(x, 256, with_conv_shortcut=False, name="layer1.2")
x = bottleneck_Block(x, 256, with_conv_shortcut=False, name="layer1.3")
return x
Section-2是第二部分,用于进行进一步的特征提取,对应图中中间靠左的12个方块。如果将该部分进行详细绘制,其本质上应该是这样的。

对于输入进来的特征层,HRNetV2分别利用两个卷积进行处理,一个卷积的步长为(1, 1)、通道为32,一个卷积的步长为(2, 2)、通道为64。此时,我们获得一个[120,120, 32]的特征层和一个[60, 60, 64]的特征层。
之后对这两个特征层,分别进行四次basic_Block的处理。这里用到的basic_Block,也是Resnet系列里面用到的残差卷积,主要用在Resnet18、Resnet32里面。
basic_Block的结构如下图所示,basic_Block可以分为两个部分,左边部分为主干部分,存在一次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,不经过处理或者经过少量处理直接与输出相接。

由图可知,结构分为两个情况:
如果不发生高宽以及通道的变化,则basic_Block如左图所示,此时残差边不经过任何处理便直接与主干部分相接,输入特征层和输出特征层的shape是相同的。
如果发生高宽以及通道的变化,则basic_Block如右图所示,此时残差边经过少量处理便直接和主干相接,可以改变输出特征层的宽高和通道数。
在分别经过进行四次basic_Block的处理后,我们依然获得一个[120,120, 32]的特征层和一个[60, 60, 64]的特征层。
之后对[120,120, 32]的特征层进行下采样,与[60, 60, 64]的特征层相加;对[60, 60, 64]的特征层进行上采样,与[120,120, 32]相加。
总体上,Section-2的构建代码如下:
def transition_layer1(x, out_filters_list=[32, 64]):
x0 = Conv2D(out_filters_list[0], 3, padding='same', use_bias=False, kernel_initializer='he_normal', name="transition1.0.0")(x)
x0 = BatchNormalization(epsilon=1e-5, name="transition1.0.1")(x0)
x0 = Activation('relu')(x0)
x1 = ZeroPadding2D(((1, 1),(1, 1)))(x)
x1 = Conv2D(out_filters_list[1], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name = "transition1.1.0.0")(x1)
x1 = BatchNormalization(epsilon=1e-5, name="transition1.1.0.1")(x1)
x1 = Activation('relu')(x1)
return [x0, x1]
def make_stage2(x_list, out_filters_list=[32, 64]):
x0, x1 = x_list
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage2.0.branches.0.0")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage2.0.branches.0.1")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage2.0.branches.0.2")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage2.0.branches.0.3")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage2.0.branches.1.0")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage2.0.branches.1.1")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage2.0.branches.1.2")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage2.0.branches.1.3")
x0_0 = x0
x0_1 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage2.0.fuse_layers.0.1.0")(x1)
x0_1 = BatchNormalization(epsilon=1e-5, name="stage2.0.fuse_layers.0.1.1")(x0_1)
x0_1 = UpsampleLike(name="Upsample1")([x0_1, x0_0])
x0_out = add([x0_0, x0_1])
x0_out = Activation('relu')(x0_out)
x1_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x1_0 = Conv2D(out_filters_list[1], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage2.0.fuse_layers.1.0.0.0")(x1_0)
x1_0 = BatchNormalization(epsilon=1e-5, name="stage2.0.fuse_layers.1.0.0.1")(x1_0)
x1_1 = x1
x1_out = add([x1_0, x1_1])
x1_out = Activation('relu')(x1_out)
return x0_out, x1_out
Section-3是第三部分,用于进行进一步的特征提取,对应图中中间靠右的18个方块。如果将该部分进行详细绘制,其本质上应该是这样的。

对于输入进来的特征层,HRNetV2利用一个步长为(2, 2)、通道为128的卷积对[60, 60, 64]进行处理。此时,我们获得一个[30, 30, 128]的特征层。加上初始的两个特征层,我们存在三个特征层。
之后对这三个特征层,分别进行四次basic_Block的处理。这里用到的basic_Block,与Stage-2里面一样。然后利用[128, 128, 32]、[60, 60, 64]、[30, 30, 128]三个特征层,利用上采样和下采样建立密集连接,完成高度的特征融合。这个过程需要重复四次。
总体上,Section-3的构建代码如下:
def transition_layer2(x, out_filters_list=[32, 64, 128]):
x2 = ZeroPadding2D(((1, 1),(1, 1)))(x[1])
x2 = Conv2D(out_filters_list[2], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="transition2.2.0.0")(x2)
x2 = BatchNormalization(epsilon=1e-5, name="transition2.2.0.1")(x2)
x2 = Activation('relu')(x2)
return [x[0], x[1], x2]
def make_stage3(x_list, num_modules, out_filters_list=[32, 64, 128]):
for i in range(num_modules):
x0, x1, x2 = x_list
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.0.0")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.0.1")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.0.2")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.0.3")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.1.0")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.1.1")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.1.2")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.1.3")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.2.0")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.2.1")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.2.2")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage3." + str(i) + ".branches.2.3")
x0_0 = x0
x0_1 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.0.1.0")(x1)
x0_1 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.0.1.1")(x0_1)
x0_1 = UpsampleLike(name="Upsample." + str(i) + ".2")([x0_1, x0_0])
x0_2 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.0.2.0")(x2)
x0_2 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.0.2.1")(x0_2)
x0_2 = UpsampleLike(name="Upsample." + str(i) + ".3")([x0_2, x0_0])
x0_out = add([x0_0, x0_1, x0_2])
x0_out = Activation('relu')(x0_out)
x1_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x1_0 = Conv2D(out_filters_list[1], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.1.0.0.0")(x1_0)
x1_0 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.1.0.0.1")(x1_0)
x1_1 = x1
x1_2 = Conv2D(out_filters_list[1], 1, use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.1.2.0")(x2)
x1_2 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.1.2.1")(x1_2)
x1_2 = UpsampleLike(name="Upsample." + str(i) + ".4")([x1_2, x1_1])
x1_out = add([x1_0, x1_1, x1_2])
x1_out = Activation('relu')(x1_out)
x2_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x2_0 = Conv2D(out_filters_list[0], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.2.0.0.0")(x2_0)
x2_0 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.2.0.0.1")(x2_0)
x2_0 = Activation('relu')(x2_0)
x2_0 = ZeroPadding2D(((1, 1),(1, 1)))(x2_0)
x2_0 = Conv2D(out_filters_list[2], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.2.0.1.0")(x2_0)
x2_0 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.2.0.1.1")(x2_0)
x2_1 = ZeroPadding2D(((1, 1),(1, 1)))(x1)
x2_1 = Conv2D(out_filters_list[2], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage3." + str(i) + ".fuse_layers.2.1.0.0")(x2_1)
x2_1 = BatchNormalization(epsilon=1e-5, name="stage3." + str(i) + ".fuse_layers.2.1.0.1")(x2_1)
x2_2 = x2
x2_out = add([x2_0, x2_1, x2_2])
x2_out = Activation('relu')(x2_out)
x_list = [x0_out, x1_out, x2_out]
return x_list
Section-4是第四部分,用于进行进一步的特征提取,对应图中中间靠右的24个方块。如果将该部分进行详细绘制,其本质上应该是这样的。

对于输入进来的特征层,HRNetV2利用一个步长为(2, 2)、通道为256的卷积对[30, 30, 128]进行处理。此时,我们获得一个[15, 15, 256]的特征层。加上初始的三个特征层,我们存在四个特征层。
之后对这四个特征层,分别进行四次basic_Block的处理。这里用到的basic_Block,与Stage-2里面一样。然后利用[128, 128, 32]、[60, 60, 64]、[30, 30, 128]、[15, 15, 256]四个特征层,利用上采样和下采样建立密集连接,完成高度的特征融合。这个过程需要重复三次。
总体上,Section-3的构建代码如下:
def transition_layer3(x, out_filters_list=[32, 64, 128, 256]):
x3 = ZeroPadding2D(((1, 1),(1, 1)))(x[2])
x3 = Conv2D(out_filters_list[3], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="transition3.3.0.0")(x3)
x3 = BatchNormalization(epsilon=1e-5, name="transition3.3.0.1")(x3)
x3 = Activation('relu')(x3)
return [x[0], x[1], x[2], x3]
def make_stage4(x_list, num_modules, out_filters_list=[32, 64, 128, 256]):
for i in range(num_modules):
x0, x1, x2, x3 = x_list
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.0.0")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.0.1")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.0.2")
x0 = basic_Block(x0, out_filters_list[0], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.0.3")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.1.0")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.1.1")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.1.2")
x1 = basic_Block(x1, out_filters_list[1], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.1.3")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.2.0")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.2.1")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.2.2")
x2 = basic_Block(x2, out_filters_list[2], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.2.3")
x3 = basic_Block(x3, out_filters_list[3], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.3.0")
x3 = basic_Block(x3, out_filters_list[3], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.3.1")
x3 = basic_Block(x3, out_filters_list[3], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.3.2")
x3 = basic_Block(x3, out_filters_list[3], with_conv_shortcut=False, name="stage4." + str(i) + ".branches.3.3")
x0_0 = x0
x0_1 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.0.1.0")(x1)
x0_1 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.0.1.1")(x0_1)
x0_1 = UpsampleLike(name="Upsample." + str(i) + ".5")([x0_1, x0_0])
x0_2 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.0.2.0")(x2)
x0_2 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.0.2.1")(x0_2)
x0_2 = UpsampleLike(name="Upsample." + str(i) + ".6")([x0_2, x0_0])
x0_3 = Conv2D(out_filters_list[0], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.0.3.0")(x3)
x0_3 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.0.3.1")(x0_3)
x0_3 = UpsampleLike(name="Upsample." + str(i) + ".7")([x0_3, x0_0])
x0_out = add([x0_0, x0_1, x0_2, x0_3])
x0_out = Activation('relu')(x0_out)
x1_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x1_0 = Conv2D(out_filters_list[1], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.1.0.0.0")(x1_0)
x1_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.1.0.0.1")(x1_0)
x1_1 = x1
x1_2 = Conv2D(out_filters_list[1], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.1.2.0")(x2)
x1_2 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.1.2.1")(x1_2)
x1_2 = UpsampleLike(name="Upsample." + str(i) + ".8")([x1_2, x1_1])
x1_3 = Conv2D(out_filters_list[1], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.1.3.0")(x3)
x1_3 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.1.3.1")(x1_3)
x1_3 = UpsampleLike(name="Upsample." + str(i) + ".9")([x1_3, x1_1])
x1_out = add([x1_0, x1_1, x1_2, x1_3])
x1_out = Activation('relu')(x1_out)
x2_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x2_0 = Conv2D(out_filters_list[0], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.2.0.0.0")(x2_0)
x2_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.2.0.0.1")(x2_0)
x2_0 = Activation('relu')(x2_0)
x2_0 = ZeroPadding2D(((1, 1),(1, 1)))(x2_0)
x2_0 = Conv2D(out_filters_list[2], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.2.0.1.0")(x2_0)
x2_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.2.0.1.1")(x2_0)
x2_1 = ZeroPadding2D(((1, 1),(1, 1)))(x1)
x2_1 = Conv2D(out_filters_list[2], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.2.1.0.0")(x2_1)
x2_1 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.2.1.0.1")(x2_1)
x2_2 = x2
x2_3 = Conv2D(out_filters_list[2], 1, use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.2.3.0")(x3)
x2_3 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.2.3.1")(x2_3)
x2_3 = UpsampleLike(name="Upsample." + str(i) + ".10")([x2_3, x2_2])
x2_out = add([x2_0, x2_1, x2_2, x2_3])
x2_out = Activation('relu')(x2_out)
x3_0 = ZeroPadding2D(((1, 1),(1, 1)))(x0)
x3_0 = Conv2D(out_filters_list[0], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.0.0.0")(x3_0)
x3_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.0.0.1")(x3_0)
x3_0 = Activation('relu')(x3_0)
x3_0 = ZeroPadding2D(((1, 1),(1, 1)))(x3_0)
x3_0 = Conv2D(out_filters_list[0], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.0.1.0")(x3_0)
x3_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.0.1.1")(x3_0)
x3_0 = Activation('relu')(x3_0)
x3_0 = ZeroPadding2D(((1, 1),(1, 1)))(x3_0)
x3_0 = Conv2D(out_filters_list[3], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.0.2.0")(x3_0)
x3_0 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.0.2.1")(x3_0)
x3_1 = ZeroPadding2D(((1, 1),(1, 1)))(x1)
x3_1 = Conv2D(out_filters_list[1], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.1.0.0")(x3_1)
x3_1 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.1.0.1")(x3_1)
x3_1 = Activation('relu')(x3_1)
x3_1 = ZeroPadding2D(((1, 1),(1, 1)))(x3_1)
x3_1 = Conv2D(out_filters_list[3], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.1.1.0")(x3_1)
x3_1 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.1.1.1")(x3_1)
x3_2 = ZeroPadding2D(((1, 1),(1, 1)))(x2)
x3_2 = Conv2D(out_filters_list[3], 3, strides=(2, 2), padding='valid', use_bias=False, kernel_initializer='he_normal', name="stage4." + str(i) + ".fuse_layers.3.2.0.0")(x3_2)
x3_2 = BatchNormalization(epsilon=1e-5, name="stage4." + str(i) + ".fuse_layers.3.2.0.1")(x3_2)
x3_3 = x3
x3_out = add([x3_0, x3_1, x3_2, x3_3])
x3_out = Activation('relu')(x3_out)
x_list = [x0_out, x1_out, x2_out, x3_out]
return x_list
通过主干部分的构建,我们最终会在Section-4之后获得4个有效特征层。四个有效特征层的形状为:
[128, 128, 32]、[60, 60, 64]、[30, 30, 128]、[15, 15, 256]。
在该部分,我们会对四个有效特征层进行特征融合。首先对[60, 60, 64]、[30, 30, 128]、[15, 15, 256]三个有效特征层进行上采样,调整成高宽为128x128。然后将调整后的特征层进行堆叠。
即将:[128, 128, 32]、[128, 128, 64]、[128, 128, 128]、[128, 128, 256]四个特征层进行堆叠。之后再利用一个卷积+标准化+激活函数进行特征整合。
inputs = Input(shape=input_shape)
x, num_filters = HRnet_Backbone(inputs, backbone)
x0_0 = x[0]
x0_1 = UpsampleLike()([x[1], x[0]])
x0_2 = UpsampleLike()([x[2], x[0]])
x0_3 = UpsampleLike()([x[3], x[0]])
x = Concatenate(axis=-1)([x0_0, x0_1, x0_2, x0_3])
x = Conv2D(np.sum(num_filters), 1, strides=(1, 1))(x)
x = BatchNormalization(epsilon=1e-5)(x)
x = Activation("relu")(x)
利用1、2步,我们可以获取输入进来的图片的特征,此时,我们需要利用特征获得预测结果。
利用特征获得预测结果的过程可以分为2步:
1、利用一个1x1卷积进行通道调整,调整成Num_Classes。
2、利用resize进行上采样使得最终输出层,宽高和输入图片一样。
x = Conv2D(num_classes, 1, strides=(1, 1))(x)
shape = tf.keras.backend.int_shape(inputs)
x = Lambda(lambda xx : tf.image.resize_images(xx, shape[1:3], align_corners=True))(x)
x = Softmax()(x)
model = Model(inputs, x, name="HRnet")
return model
我们使用的训练文件采用VOC的格式。
语义分割模型训练的文件分为两部分。
第一部分是原图,像这样:

第二部分标签,像这样:

原图就是普通的RGB图像,标签就是灰度图或者8位彩色图。
原图的shape为[height, width, 3],标签的shape就是[height, width],对于标签而言,每个像素点的内容是一个数字,比如0、1、2、3、4、5……,代表这个像素点所属的类别。
语义分割的工作就是对原始的图片的每一个像素点进行分类,所以通过预测结果中每个像素点属于每个类别的概率与标签对比,可以对网络进行训练。
本文所使用的LOSS由两部分组成:
1、Cross Entropy Loss。
2、Dice Loss。
Cross Entropy Loss就是普通的交叉熵损失,当语义分割平台利用Softmax对像素点进行分类的时候,进行使用。
Dice loss将语义分割的评价指标作为Loss,Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。
计算公式如下:
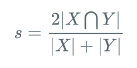
就是预测结果和真实结果的交乘上2,除上预测结果加上真实结果。其值在0-1之间。越大表示预测结果和真实结果重合度越大。所以Dice系数是越大越好。
如果作为LOSS的话是越小越好,所以使得Dice loss = 1 - Dice,就可以将Loss作为语义分割的损失了。
实现代码如下:
def dice_loss_with_CE(beta=1, smooth = 1e-5):
def _dice_loss_with_CE(y_true, y_pred):
y_pred = K.clip(y_pred, K.epsilon(), 1.0 - K.epsilon())
CE_loss = - y_true[...,:-1] * K.log(y_pred)
CE_loss = K.mean(K.sum(CE_loss, axis = -1))
tp = K.sum(y_true[...,:-1] * y_pred, axis=[0,1,2])
fp = K.sum(y_pred , axis=[0,1,2]) - tp
fn = K.sum(y_true[...,:-1], axis=[0,1,2]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
score = tf.reduce_mean(score)
dice_loss = 1 - score
# dice_loss = tf.Print(dice_loss, [dice_loss, CE_loss])
return CE_loss + dice_loss
return _dice_loss_with_CE
首先前往Github下载对应的仓库,下载完后利用解压软件解压,之后用编程软件打开文件夹。
注意打开的根目录必须正确,否则相对目录不正确的情况下,代码将无法运行。
一定要注意打开后的根目录是文件存放的目录。

本文使用VOC格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过Github连接下载VOC12+07的数据集尝试下。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的SegmentationClass中。

在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的train.txt以及val.txt,需要用到根目录下的voc_annotation.py。
如果下载的是我上传的voc数据集,那么就不需要运行根目录下的voc_annotation.py。
如果是自己制作的数据集,那么需要运行根目录下的voc_annotation.py,从而生成train.txt和val.txt。
通过voc_annotation.py我们已经生成了train.txt以及val.txt,此时我们可以开始训练了。训练的参数较多,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的num_classes。
num_classes用于指向检测类别的个数+1!训练自己的数据集必须要修改!
除此之外在train.py文件夹下面,选择自己要使用的主干模型backbone、预训练权重model_path和下采样因子downsample_factor。预训练模型需要和主干模型相对应。下采样因子可以在8和16中选择。

之后就可以开始训练了。
训练结果预测需要用到两个文件,分别是deeplab.py和predict.py。
我们首先需要去deeplab.py里面修改model_path以及num_classes,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
num_classes指向检测类别的个数+1。

完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
我正在使用PostgreSQL9.1.3(x86_64-pc-linux-gnu上的PostgreSQL9.1.3,由gcc-4.6.real(Ubuntu/Linaro4.6.1-9ubuntu3)4.6.1,64位编译)和在ubuntu11.10上运行3.2.2或3.2.1。现在,我可以使用以下命令连接PostgreSQLsupostgres输入密码我可以看到postgres=#我将以下详细信息放在我的config/database.yml中并执行“railsdb”,它工作正常。开发:adapter:postgresqlencoding:utf8reconnect:falsedat
我目前有一个运行Ruby1.8.7和Rails2.3.2的RubyonRails项目我有一些从数据库中读取数据的单元测试,特别是两个连续项目的日期时间列,这两个项目应该相隔24小时。在一项测试中,我将项目2的日期时间设置为与项目1的日期时间相同。当我执行断言以确保两个值相等时,测试在rails2.3.2下工作正常。当我升级到rails2.3.11时,测试失败显示两次之间的差异将关闭并出现以下错误:expectedbutwas.这两个版本的rails中似乎存在浮点转换问题。如何解决float问题? 最佳答案 这也发生在我身上,我最终这
我刚刚开始按照包括AlexOtt在内的各种指南设置cedet。这是我的init文件中目前的内容。(require'cedet)(semantic-load-enable-code-helpers);;imenubreaksifIdon'tenablethis(global-semantic-highlight-func-mode1)(global-semantic-tag-folding-mode)我非常喜欢代码折叠,因为语义比hideshow等包更了解代码我想对ruby进行相同的折叠。我知道cedet还可以做其他事情,但我现在只是试一试。所以我在contrib/文件夹中看到了wi
gemspec语义版本控制运算符~>(又名twiddle-wakka,又名pessimistic运算符)允许限制gem版本但允许进行一些升级。我经常看到它可以读作:"~>3.1"=>"Anyversion3.x,butatleast3.1""~>3.1.1"=>"Anyversion3.1.x,butatleast3.1.1"但是有了一个数字,这条规则就失效了:"~>3"=>"Anyversionx,butatleast3"*NOTTRUE!*"~>3"=>"Anyversion3.x"*True.Butwhy?*如果我想要“任何版本3.x”,我可以只使用“~>3.0”,这是一致的。就
跳过联网激活:OOBE界面直接按Ctrl+Shift+F3进入审核模式。这样就可以直接进入系统进行一些硬件测试等,而不用联网激活导致新机无法退货。需要注意的是,在审核模式下进行的一些操作都会保留,并不会在退出后自动还原!安装的软件在正常开机进系统后还会看见!如果电脑确实没连互联网又不想强行跳过OOBE(网上很多教程会叫你直接结束OOBE进程,但这是不推荐的,因为一些厂商自带优化程序和系统初始化设置在后面都会应用,对于笔记本跳过的话你会发现驱动和内置应用都没有装上。其实这部分脚本就在系统盘的Recovery隐藏文件夹下),可以参考以下方式:https://www.landiannews.com/
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/
给定一个Ruby数组字符串,其中一些项目在引号中包含逗号:my_string.inspect#=>"\"hey,you\",21"我怎样才能得到一个数组:["hey,you","21"] 最佳答案 Ruby标准CSV库的.parse_csv就是这样做的。require'csv'"\"hey,you\",21".parse_csv#=>["hey,you","21"] 关于ruby-用逗号将字符串分割成数组,除非逗号在引号内,我们在StackOverflow上找到一个类似的问题:
在使用Rubyv2.2.2的ElCapitan(MacOSX10.11.1)上安装Rails时,出现以下错误:ERROR:Errorinstallingnokogiri:ERROR:Failedtobuildgemnativeextension./Users/jon/.rvm/rubies/ruby-2.2.2/bin/ruby-r./siteconf20151117-26799-ux15fd.rbextconf.rb--use-system-librariescheckingiftheCcompileraccepts...***extconf.rbfailed***Couldnotc