索引并不是越多越好,索引创建越多,MySQL维护的代价越高,如果SQL未能完全使用到索引,创建索引的意义是不大的。
表x,创建索引a,b,c。主键y。
select * from x where a = '' and b = '' and c = ''
当我们创建的索引abc,此时我们有a,b,c字段的索引是可以匹配到的,不论你a,b,c字段顺序如何,优化器会自动优化为索引的顺序。
select * from x where a = '' and d = ''
我们在此情况可以用到a的索引,但是如果第一个为b或c字段就不行。
select * from x where a like 'aaa%' and b like 'bbb%' # 不行'%aaa'或'%aaa%'
我们可以利用建立的索引找到a和b字段,因为a索引和b索引按照前缀排序的。但是反过来不行
select * from x where a between 5 and 10;
因为是索引按照大小排序的,所以可以使用到索引。但是我们不用a直接用b是不能用到索引的。
select * from x where a = 'aaa' and b between 5 and 10;
当我们是这种情况会找到a,然后根据b的排序找到b的范围值,是可以用到索引的。
select * from x order by a,b,c; # 可以使用索引
select * from x order by b,a,c; # 不能使用索引
创建了a,b,c的索引可以根据a,b,c 排序,否则不能使用。
select * from x group by a,b # 可以使用索引,顺序不对可以,会自动优化,但是得从左边开始
二级索引最后的最后找到主键值需要拿着主键值去聚簇索引进行回表查询。
我们创建索引时可以尽量避免回表的出现,尽量使用索引的字段,否则回表会导致MySQL的性能下降。当然mysql对于大量数据需要回表的情况会直接优化成顺序查找,省的大量回表带来的开销。
这也是为什么我们不要用select * 的原因,如果我们只需要索引字段就select对应字段即可。当所需字段在索引中存在,会进行覆盖索引作为结果返回,不需要回表查值。
select * from x where a = '' and b = '' and c = ''; # 如果数据库中有其他字段除了abc和主键y。
select a,b,c,y from x where a = '' and b = '' and c = ''; # 不需要回表直接覆盖索引。
数据存放目录,与安装目录区分开
mysql> show variables like 'datadir';
+---------------+------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------+
| datadir | D:\mysql\mysql-8.0.22-winx64\data\ |
+---------------+------------------------------------+
1 row in set, 1 warning (0.00 sec)
数据库在文件中就是表现为存放目录下的一个与数据库同名的文件夹,系统数据库会直接存放在数据存放目录下。
描述表结构的文件:表名.frm
描述表数据和索引的文件:表名.ibd
系统表空间:即数据存放目录下的一个12M的文件,如果系统中数据库数据多,会更大。即系统数据库文件ibdata1文件。
独立表空间:在数据存放目录下数据库名的子目录里面,表名.frm 和 表名.ibd 。不过现在8.0.22已经只有表名.ibd了。
描述表结构的文件:表名.frm
描述表数据的文件:表名.MYD
描述表索引的文件:表名.MYI
独立表空间就是由这三个文件组成。
服务器进程文件、日志文件、SSL和RSA证书和密钥。
存放用户账号和权限,一些存储过程、事件定义信息、一些运行时日志,帮助信息,时区信息。
维护服务器有哪些表,哪些视图,哪些触发器,哪些列,哪些索引
维护服务器运行的状态信息,对MySQL的监控
通过视图的形式把前两个表结合起来,让程序员监控MySQL。
我们提到了行格式、页这两个概念。
行格式规定了每条数据,多条数据形成组,多个组存放在一个页中。
如果我们需要管理页的话,我们就需要区和段这个概念。
一个16KB的页来说,连续64个页就是一个区,也就是说一个区的大小为1MB。
连续256个区,就形成了一个组,一个组256MB。
对于每个表空间的第一个组来说,这个组第一个区前三个页面是不一样的。
其余组的第一个区就是最先两个页面不一样。
提问:为什么要使用区来管理?
因为对于页来说没有固定的存储地点,所以页是随意存储的,但是如果数据量已经很大的情况下,我们插入了一个很小的主键值,会建立一个物理存储位置在很后面的页,但是页会被插入到很前面,我们读页信息的时候,就会出现什么情况呢?
就是我们需要IO读取到最后,然后在回到当前继续读,是十分耗时的,也就是随机IO,与顺序IO性能差得多。
第一遍看到这个概念直接被搞蒙了。
InnoDB 中叶子节点存放的区和非叶子节点存放的区是分开的,这就是段的概念。一个为存放叶子节点区的段,和存放索引页区的段。
所以捋一下。每个聚簇索引会有两个段,一个段表示存放叶子页的区,一个段表示存放非叶子页的区。
那按照这样的话,一个表开局就要2M的存储空间,对于几条数据的是不是太大了。
所以出现碎片页的概念,一个区不属于某个段,而是直接属于表空间。它可以存储各个段的页,防止区的浪费。当一个段已经存储了32个碎片区,剩下就会直接创建附属的空闲区来存储页,而不是使用碎片页。
所以区有如下状态:
对于每个区来说都有一个XDES Entry的结构。
当段中存储的区小于32时,是会利用隶属于表空间的碎片区进行存储的。
流程:
当段中的碎片区存储超过32时,就会申请隶属于该段空间的区进行存储。
流程和之前差不多,但是段空间也会维护三个链表FREE和FULL以及NOT_FULL虽然有点区别就是非碎片区的,不过是申请的专属的区,所以流程是差不多的。
前面我们不是提到了段并不是一个实际的存储单元,只是区的引用。
所以需要有一个结构来定义段,就是INODE Entry 结构
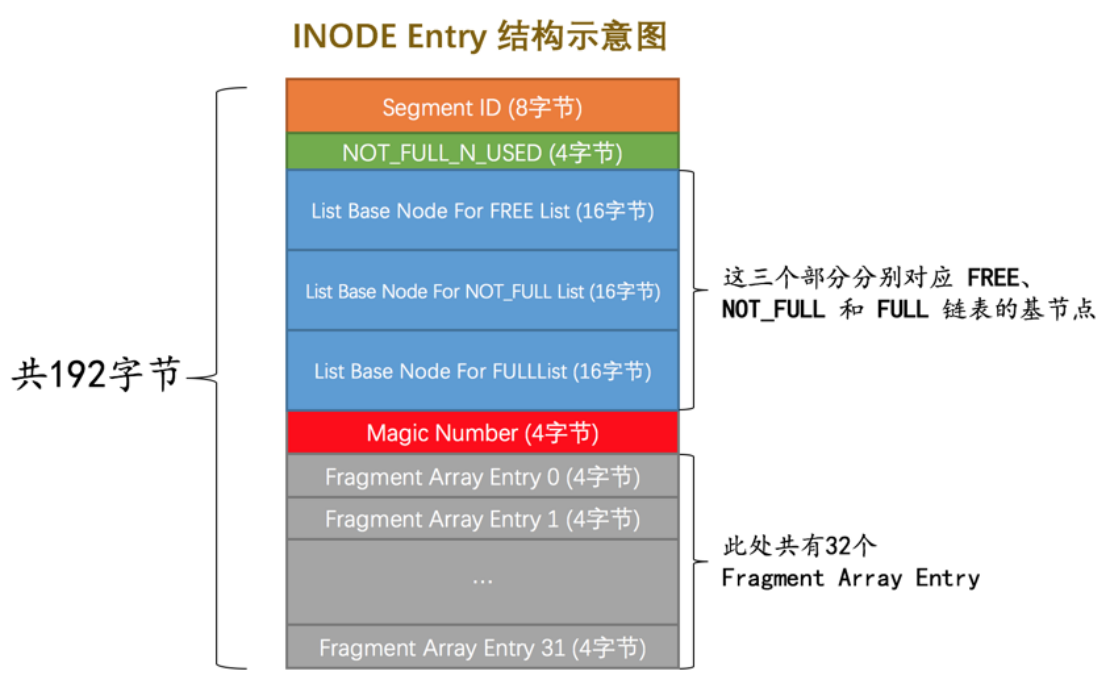
所以在段中,碎片区的引用是在最底下,而专属区的引用是在链表中链着的。
所以你废了吗?
接下来我们可以讲解一下INODE Entry放在哪里呢,就需要介绍之前提到过的每个表空间的第一个区中固定的三个页面,只介绍俩页面
FSP_HDR类型的页面,就是比其他的区的第一个XDES页多了File Space Header就是记录当前表空间的一些属性,其他都是一样的。


Space ID 表示表空间的ID
Size 表空间页的大小
Free Limit 就是当前已经使用的页到多少了,下次直接从这个地址开始分配页面
FRAG_N_USED 表示碎片区已经使用的页
接下来的for FREE List 和for FREE_FRAG List和for FULL_FRAG List 表示表空间维护的三个有关碎片区的链表
Next Unuser Segment ID 表示下一个未分配的段ID,方便分配一个新的段ID
for SEG_INODES_FULL 和 for SEG_INODES_FREE 表示已经放满了INODE Entry 的INODE节点和空闲的INODE节点。(记住是存放INODE Entry也就是段结构的INODE节点)
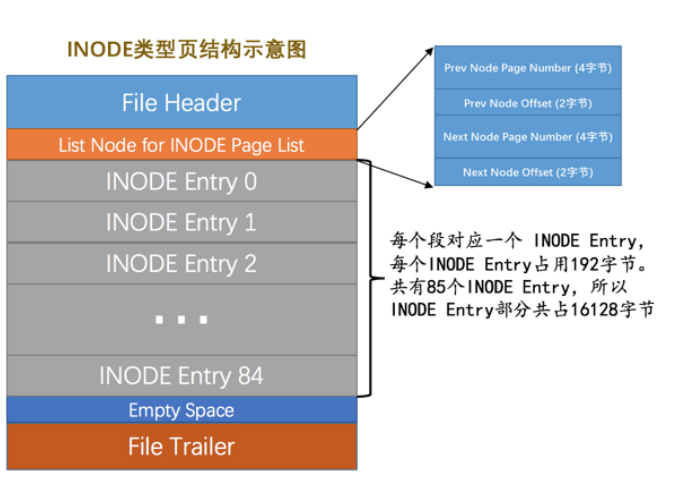
INODE类型结构就是为了存储INODE Entry节点的,最多存储85个段。
结构中List Node for INODE Page List 就是指向上一个INODE节点和下一个INODE节点。
我们就是在这个INODE中存储段的INODE Entry节点的。
如果该页存储满了,就会在上面提到的List Base Node for SEG_INODES_FREE 就是空闲INODE页的基节点的链表引用,取出一个,空的话从碎片区中申请一个页来存放。
所以我们知道了段是怎么存储的,存储在哪里。
同时呢,我们已经知道一个索引会有两个段,一个叶子段,一个非叶子段。
我们怎么找到索引的页呢?
在这个结构之前,我们在数据页是提到过两个引用,但是没有具体介绍
在页结构的Page Header中有如下两个结构

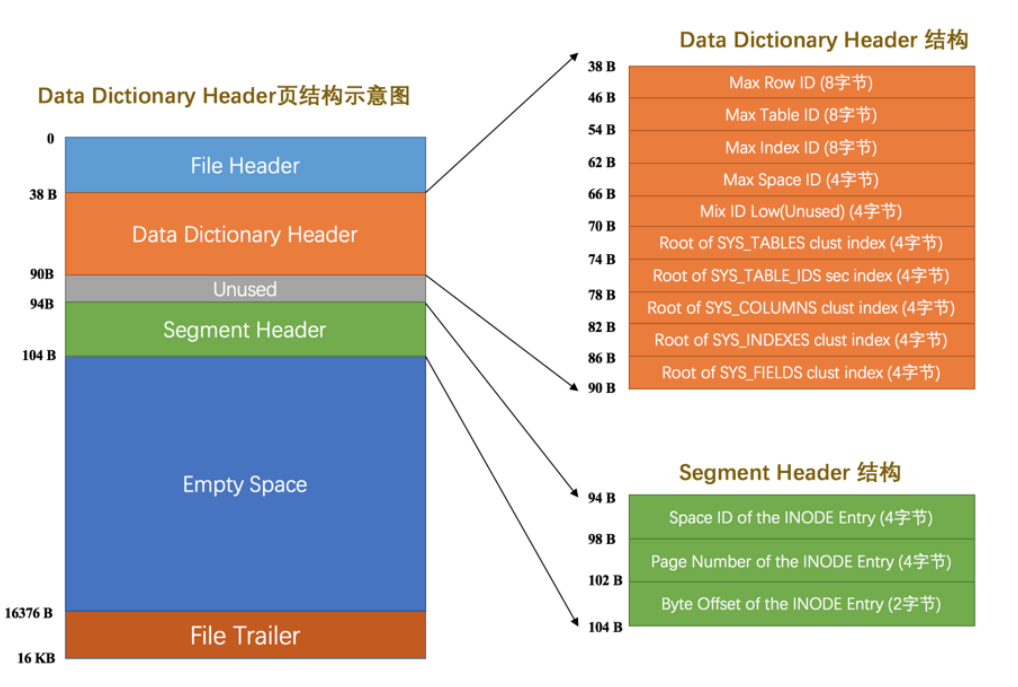
这两个结构就是Segment Header这个结构

Space ID of the INODE Entry 就是INODE对应的表空间
Page Number of the INODE Entry 就是INODE对应的表空间下对应的页号
Byte Offset of the INODE Entry 就是INODE对应的页中对应段的偏移量。
我们就可以通过在索引的ROOT节点存储一个这样的结构,可以找到对应的段。包括叶子段和非叶子段,就是两个这个结构,然后去表空间中找到这两个段的地址即可。
介绍一个概念,数据字典即系统表空间中存放了一些固定的数据,以及数据库中的表,表名,列,列属于那个表等等基本信息。
还有一些已经用了的最大的表ID,最大的索引ID,最大的表空间ID,就是方便下次创建表啊索引啊这一些更方便一点,直接将值进行增加等操作进行赋值即可。
图片出自:《MySQL是怎样运行的:从根儿上理解MySQL》
对其进行总结概括,以及思路重新捋一遍。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po