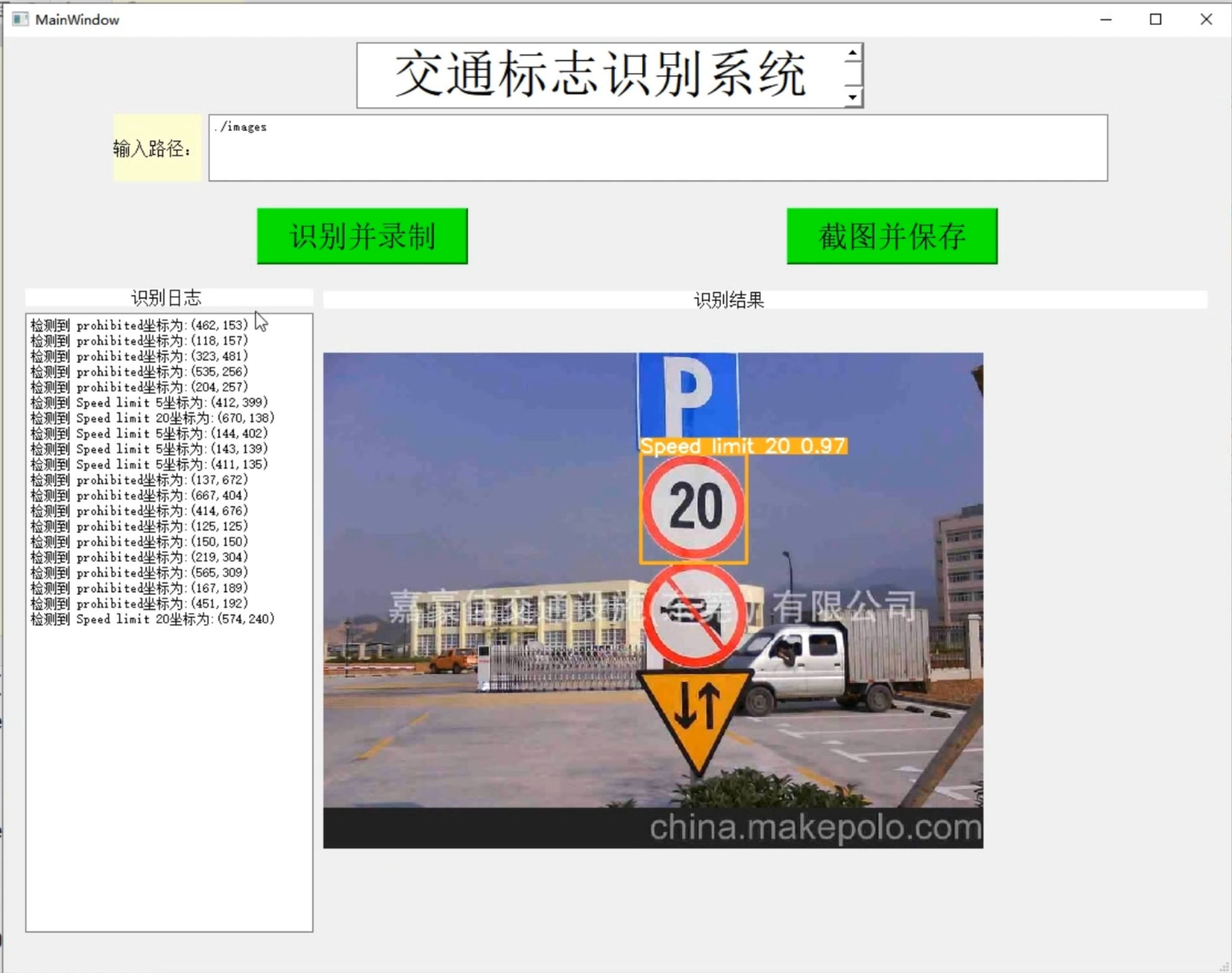
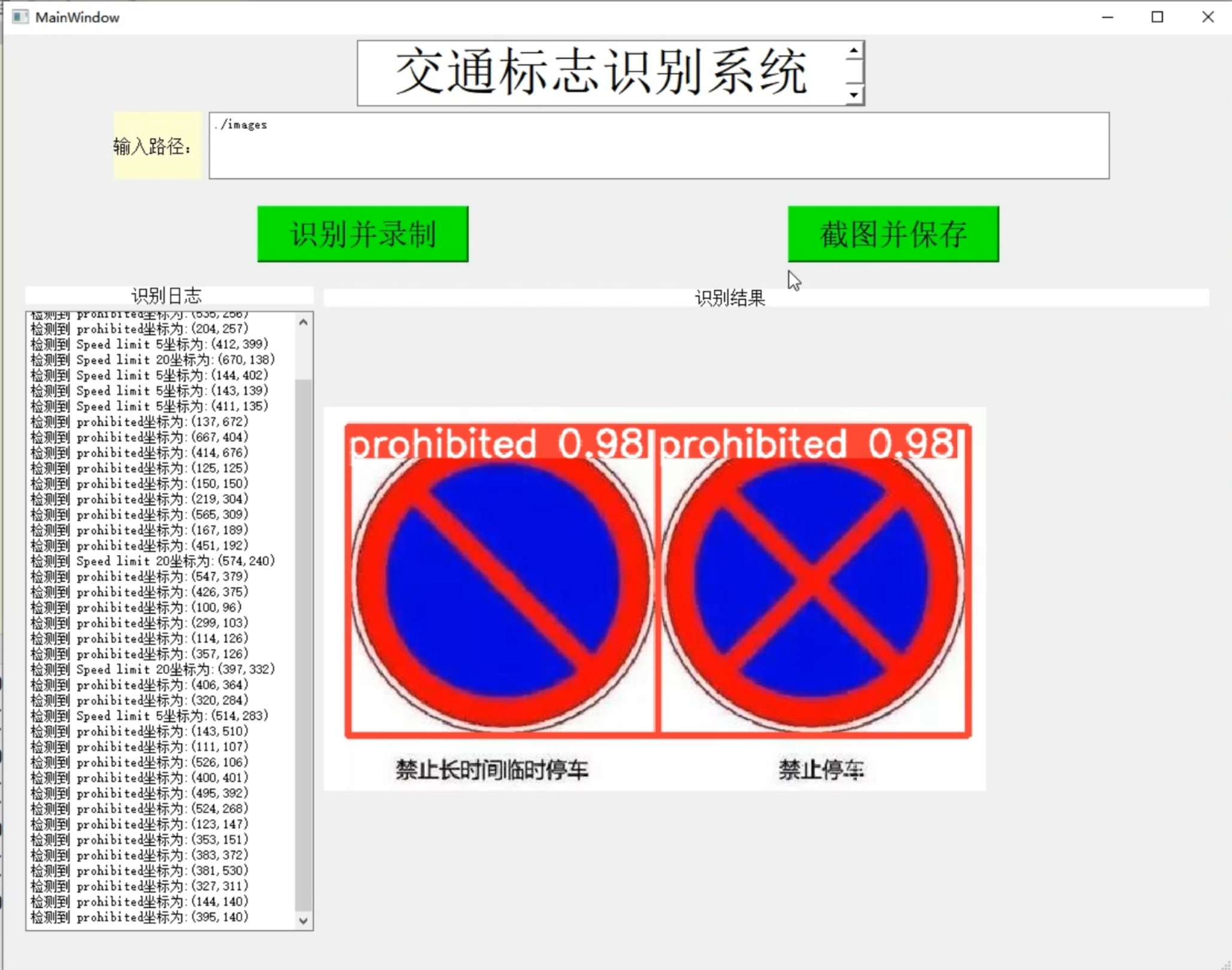
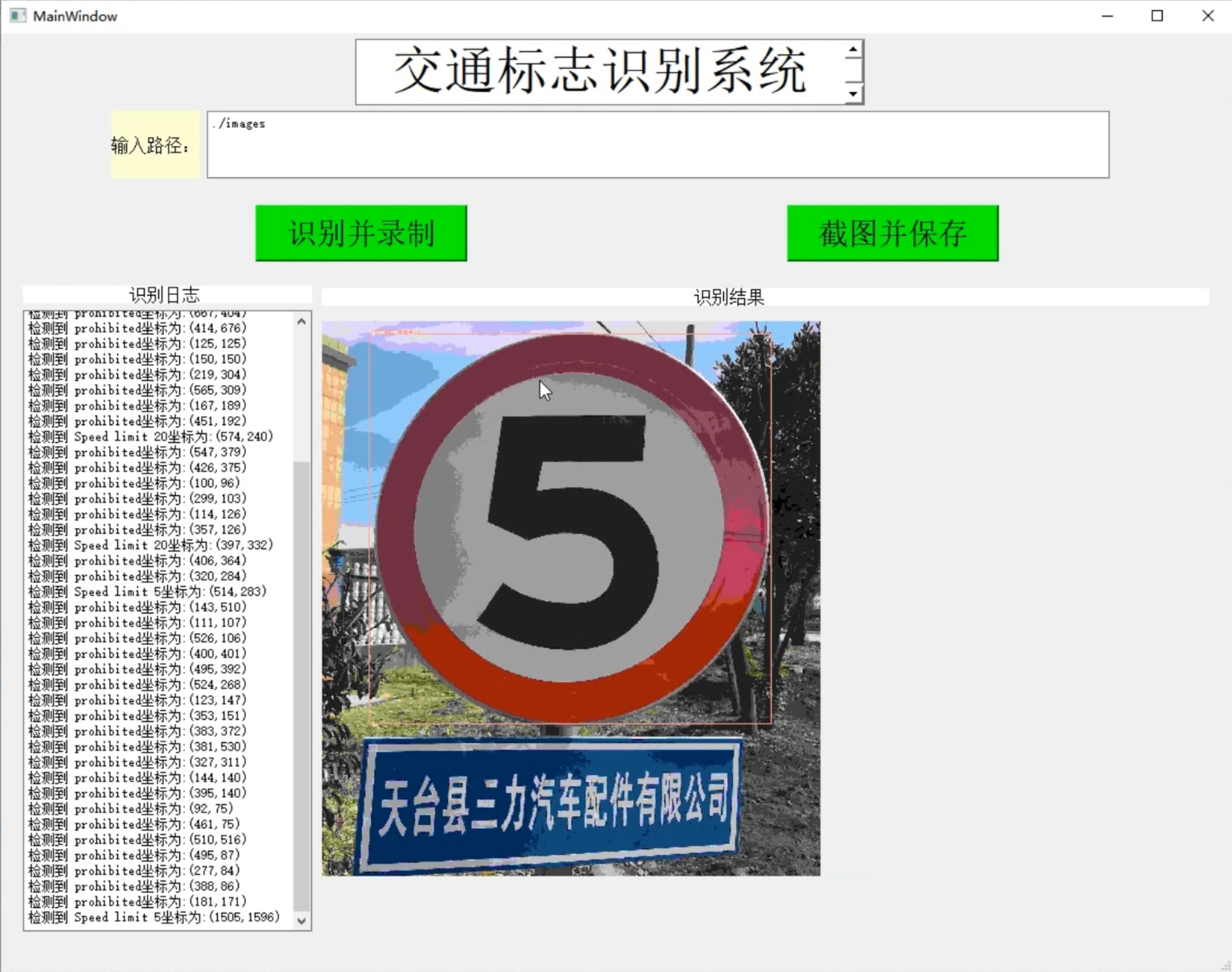
[项目分享]Python基于YOLOv5的交通标志识别系统[源码&技术文档&部署视频&数据集]_哔哩哔哩_bilibili




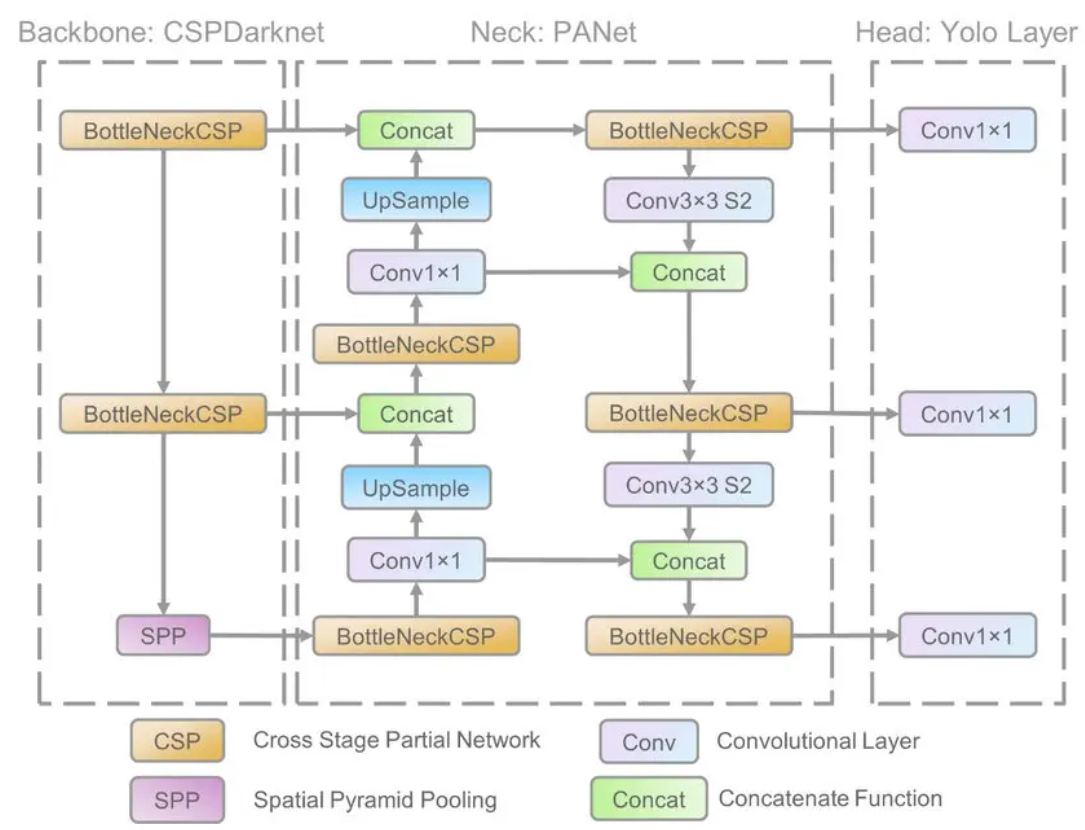
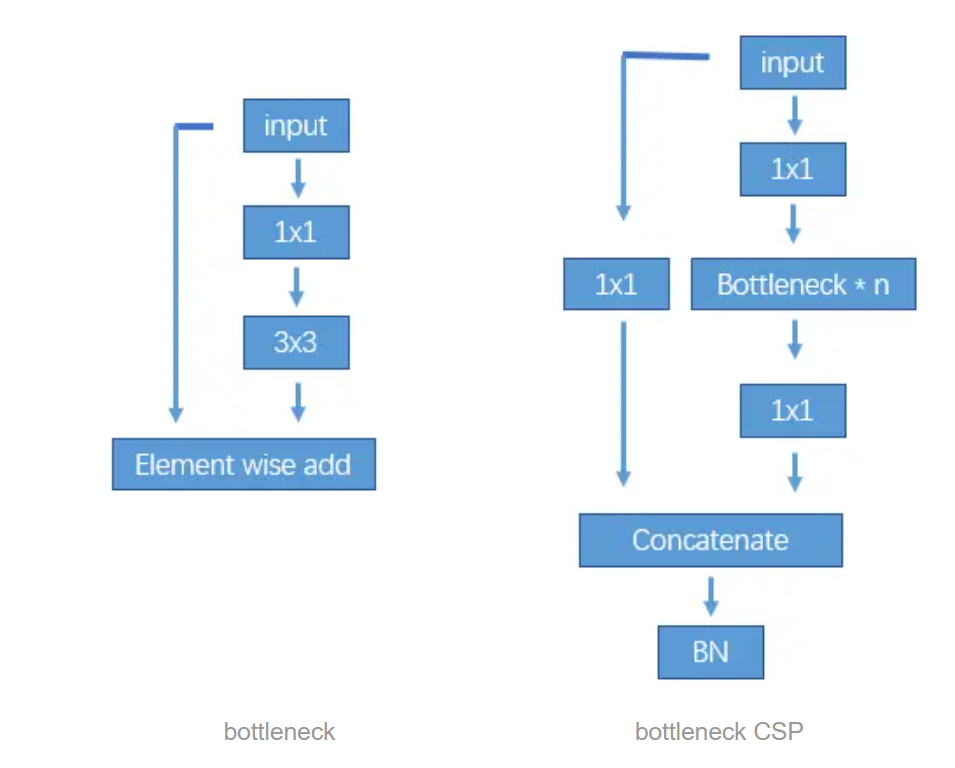
网络结构是首先用Focus将计算图长宽变为原先1/4, channel 数量乘4。再用bottlenectCSP 提取特征,个人理解 CSP 就是更多不同channel的融合吧。
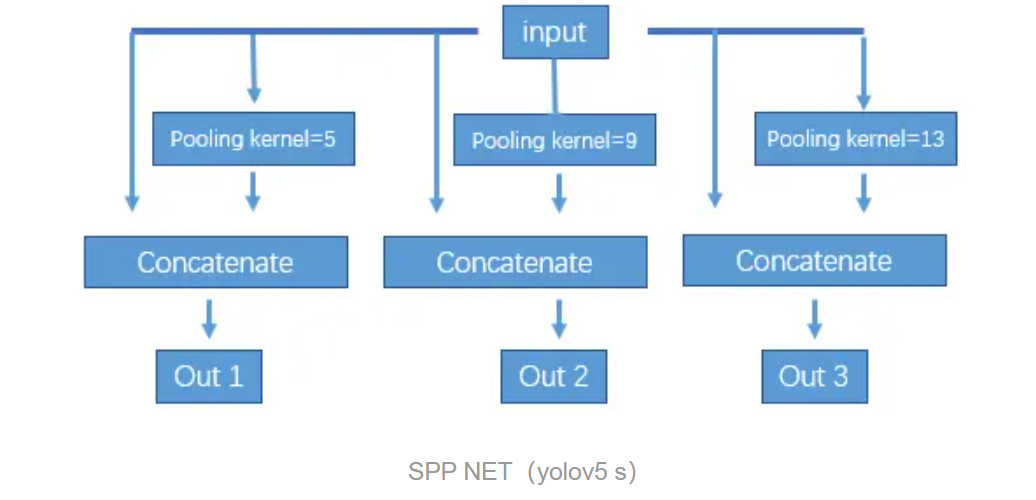
然后再用maxpooling 下采样构建特征金字塔。下采样过每阶段与input cancatenate。
再对下采样产生的feature map 上采样,与backbone里相应的层融合。最后用detect层预测anchors。detect 层输出channel是 (class num + 5)* 每层每grid预测的anchor 数。num class是预测结果为每类的概率,5是anchor的 x, y, w, h 和是否为object的置信度。默认配置经过maxpooling 以后产生三个尺寸的feature map,每个feature map 经过上采样融合等操作后都会用来预测anchor,每个grid 预测三个anchor。比如yolov5 s 预测anchor 有80类。输出 x.shape=(bs, 3, 20, 20, 85)。
在深度学习领域,对于数据量的要求是巨大的,在CV领域,我们通过图像数据增强对现有图像数据进行处理来丰富图像训练集,这样可以有效的泛化模型,解决过拟合的问题。
该博客提出的图像数据增强方式有旋转图像、裁剪图像、水平或垂直翻转图像,改变图像亮度等,为了方便训练模型,我们通常会对数据进行归一化或者标准化以及将图片大小设置为一样。

该博客代码写法上来值得注意的有这几处:
1 首先有 focus 层,对输入图片slice, 把feature map减小增加channel 后面计算速度会快。
2 构建模型(parse_model) 在yolo.py 里面,用一个数组(ch) 存储了每层的输出channel, 后续concatenate的时候很容易构成concatenate后输出的channel 数量。
3 对除了最后一层预测层外,每层output channel都检查是不是8的倍数,保证后续concate的时候不会出问题
4 common.py 里面是各种basic block, 除了bottlenect, CSP, concate层等,还有transformer 等层。
首先导入相关模块:
import tensorflow as tf
import numpy as np
import pandas as pd
import cv2
import matplotlib.pyplot as plt
import os
from sklearn.model_selection import train_test_split
读取图片:target.txt的内容如下所示,前面对应图片名字,后面对应图片的类别
x=[]
y=[]
with open ('./target.txt','r') as f:
for j,i in enumerate(f):
path=i.split()[0]
lable=i.split()[1]
print('读取第%d个图片'%j,path,lable)
src=cv2.imread('./suju/'+path)
x.append(src)
y.append(int(lable))
将数据归一化,并且划训练集和验证集
x=np.array(x)
y=np.array(y)
x.shape,y.shape
y=y[:,None]
x_train,x_test,y_train,y_test=train_test_split(x,y,stratify=y,random_state=0)
#归一化
x_train=x_train.astype('float32')/255
x_test=x_test.astype('float32')/255
y_train_onehot=tf.keras.utils.to_categorical(y_train)
y_test_onehot=tf.keras.utils.to_categorical(y_test)
搭建网络模型
model=tf.keras.Sequential([
tf.keras.Input(shape=(80,80,3)),
tf.keras.layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2,2),strides=(2,2)),
tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2,2),strides=(2,2)),
tf.keras.layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2,2),strides=(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1000,activation='relu'),
tf.keras.layers.Dropout(rate=0.5),
tf.keras.layers.Dense(43,activation='softmax')
])
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
train_history=model.fit(x_train,y_train_onehot,batch_size=100,epochs=8,validation_split=0.2,verbose=1,
)
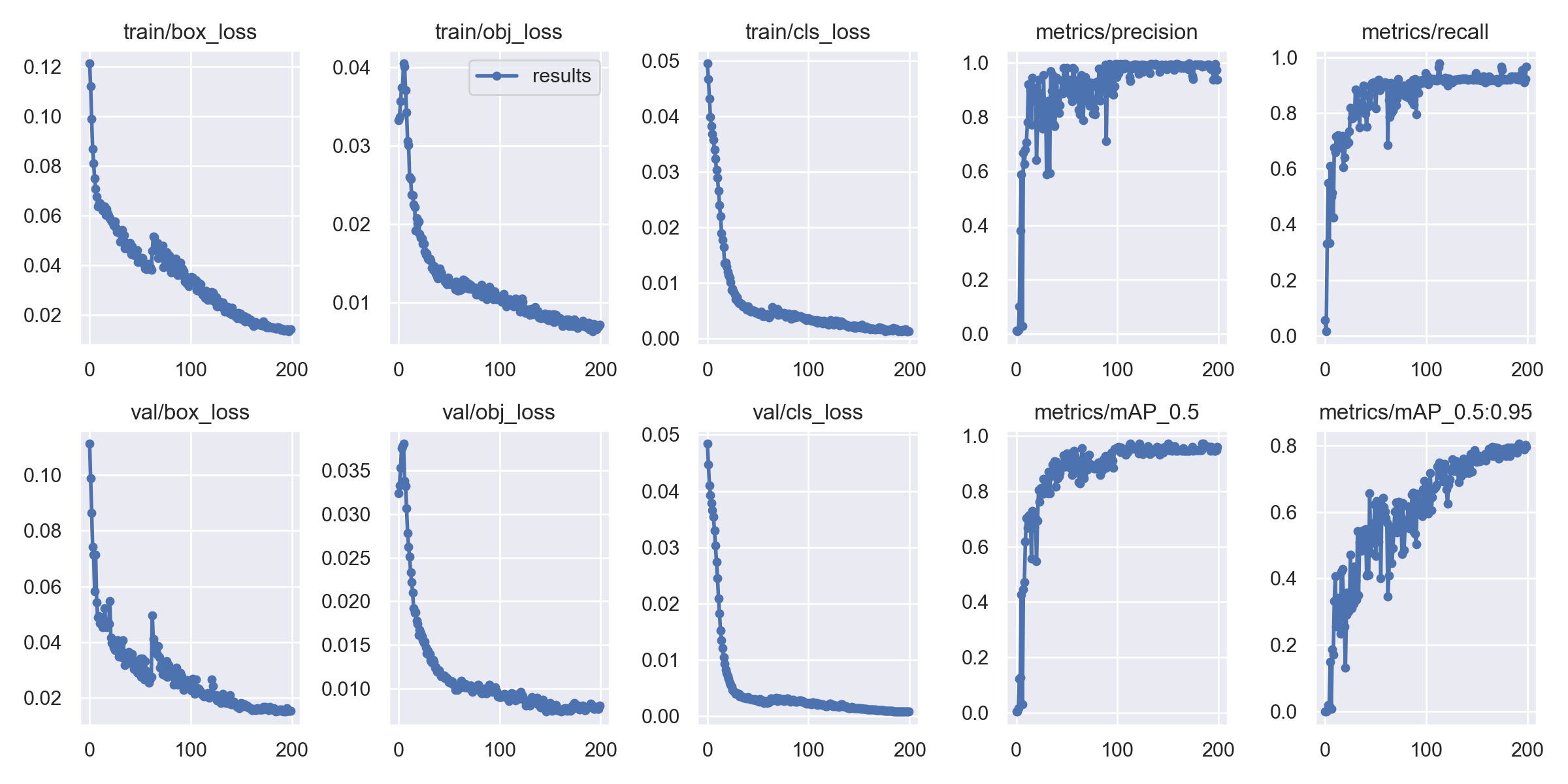
画图显示模型的loss和acc
la=[str(i) for i in range(1,9)]
def show(a,b,c,d):
fig,axes=plt.subplots(1,2,figsize=(10,4))
axes[0].set_title('accuracy of train and valuation')
axes[0].plot(la,train_history.history[a],marker='*')
axes[0].plot(train_history.history[b],marker='*')
axes[0].set_xlabel('epoch')
axes[0].set_ylabel('accuracy')
aa=round(train_history.history[a][7],2)
bb=round(train_history.history[b][7],2)
axes[0].text(la[7],train_history.history[a][7],aa,ha='center',va='bottom')
axes[0].text(la[7],train_history.history[b][7],bb,ha='center',va='top')
#axes[0].set_xticks(la,['as','asd',3,4,5,6,7,8])
# for x1,y1 in zip(la,train_history.history[a]):
# y1=round(y1,2)
# axes[0].text(x1,y1,y1,ha='center',va='bottom',fontsize=10,c='b')
axes[0].legend(['train_accuracy','val_accuracy'])
axes[1].set_title('loss of train and valuation')
axes[1].plot(la,train_history.history[c],marker='*')
axes[1].plot(train_history.history[d],marker='*')
axes[1].set_xlabel('epoch')
axes[1].set_ylabel('loss')
cc=round(train_history.history[c][7],2)
dd=round(train_history.history[d][7],2)
axes[1].text(la[7],train_history.history[c][7],cc,ha='center',va='top')
axes[1].text(la[7],train_history.history[d][7],dd,ha='center',va='bottom')
axes[1].legend(['train_loss', 'val_loss'])
#axes[1].show()
show('accuracy','val_accuracy','loss','val_loss')
保存模型
model.save('traffic_model2.h5')
完整源码&环境部署视频教程&数据集&自定义训练视频教程
参考博客《Python基于YOLOv5的交通标志识别系统[源码&技术文档&部署视频&数据集]》
【1】谢豆,石景文,刘文军,刘澍.一种基于深度学习的交通标志识别算法研究[J].电脑知识与技术:学术版,2022,18(6):116-118.
【2】王泽华,宋卫虎,吴建华.基于改进YOLOv4网络的轻量化交通标志检测模型[J].电脑知识与技术:学术版,2022,18(5):98-101.
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶