上一节我们了解了什么是策略梯度,本节开始讲PPO理论之前,我们先提出一个概念,什么在线学习,什么离线学习。
On-policy: Then agent learned and the agent interacting with Environment is the same
Off-policy: Then agent learned and the agent interacting with Environment is not the same
英语确实不好理解,用中文讲就是说,你训练agent需要数据,这些数据可能是你训练的agent和环境交互产生的,那么这就是在线,也可能不是训练的agent产生的,而是另外的agent产生的,这就是离线。
对于一个策略梯度来说在线,离线有什么区别呢?
策略梯度根据上一节的结论,理论上的公式如下,这是一个在线学习的梯度:
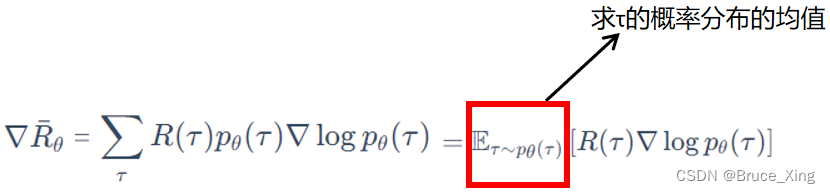
(这里多了一个上一节没有的公式,就是用了一个均值符号)
****************
( 这里插一嘴,李宏毅老师在这里称作是从on-policy 到 off-policy。PPO给我的感觉也是一个离线的算法,但是easy-rl和很多其他博主都说PPO是一个在线,包括PPO2的论文原文也说PPO比其他的on-policy策略要叼。这里也欢迎讨论)
****************
我们找到了一个提升训练效率的方法, 可以从收集数据取更新
,因为
是固定的,就可以重复利用,大大提升效率。但是凭什么
可以训练
啊,你的上一章梯度公式里明明只有一个
,你这公式保熟吗?🍉🍉
这里就不得不提到重要性样Important Sampling
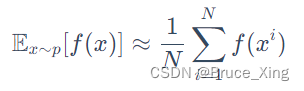
先看这个公式,假设我们有一个函数f(x),我们从一个分部p中采样,把采样到的的x在带入f(x)。这样即使我们不能对f(x)积分,只要采样够多,我们就可以f(x)在p分布中的均值得到一个均值。
现在我们在假设一种情况,如果我们不能从p中去采样,我们只能从另外一个分部q(x)去采样,可以得到f(x)在p分布中的均值吗? 答案是肯定的,具体的推导如下:
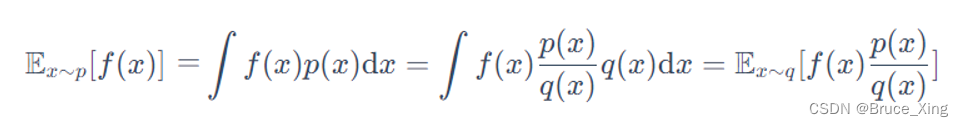
最后结论是这样:
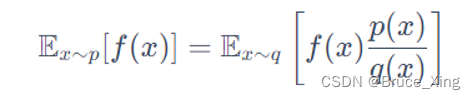
这里看不懂的可以复习下概率论,如果你比较懒也不影响你理解,这里要记住的是,我们已经成功的把从p的采样,改为了从q中的采样。
我们把这个称为重要性权值。如果我们 sample非常多,那么这个重要性权不会有什么影响。但是,but,这是很理想的情况,真是情况不太可能sample的非常均匀且足够,如果这两个分布的方差非常大的话,sample的次数一旦不足,最后结果误差就会非常大!
所以现在提问Q:从p中采样和从q中采样方差Variance一样吗?
根据公式(还是概率论中的公式)来计算一下。

其实p采样和q采样的方差就差了一项重要性权值,,也就是说只要我们保证这两个差别不要太大,结果就还是理想的。举个经典例子,上图

简单来说就是,q分布再右侧概率较大,sample时候容易偏向右,sample出来的正值的点多可能会计算错误,把f(x)均值计算成正的,但实际上它是负值。如果能采样到左边,是一个绝对值很大的负值,就可以很好的纠正最后的计算结果。
经过了这么多的验证,那么我们怎么把PPO从在线推到离线呢,就像这样。其实跟上面说的一样
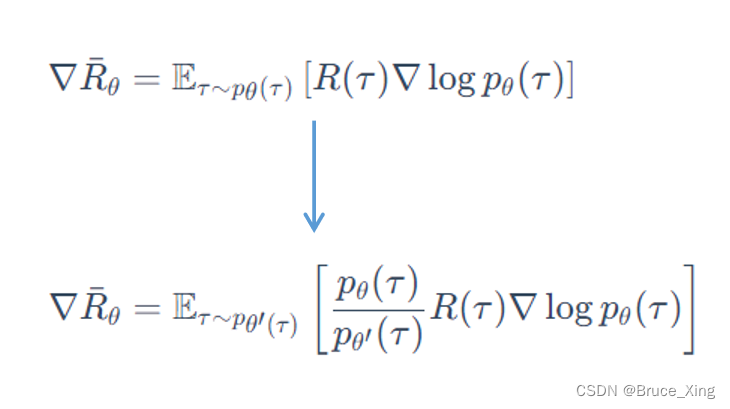
这样整个策略梯度中,我们就可以用来更新
。这样就可以让
采样大量数据,然后更新多次
,大大提升了效率。实际上做策略梯度时,我们并不是用整条轨迹
来做更新,而是根据每一个状态-动作(
) 对来分别计算。实际更新梯度的过程用的其实就是下式:
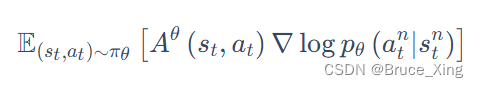
然后在从在线推到离线:
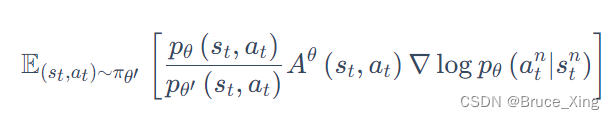
上的
,代表是策略参数为
与环境交互,但实际上现在我们用的是
来采样,现在这个优势就是用
来估算的,这里先不管那么多,假设
。
然后我们在拆分这两项和
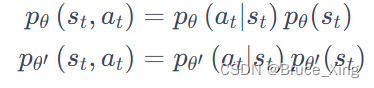
Q:这里恰一个问题:为什么要拆分呢?如果不拆分,或者
,是什么,是我们输入一个动作-状态对,然后输出一个概率,但实际上我们的策略网络并不是这个结构,想一想策略网略是输入一个状态然后输出一个动作的概率分布啊。如果不懂可以接着往后看,看完代码在会后看看以这个问题。
现在梯度下降就可以看做是:
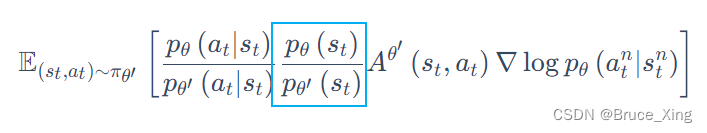
蓝框中的这一项可以消掉,原因可以说是不管是用,还是
看到同一状态的概率是一样的,又或者是这两项不好计算,想一想玩游戏时候,游戏画面复杂众多,好像计算某一个画面的出现概率很难计算,这里就直接消掉了,反正最后效果很好,神奇而玄学吧😂😂。
我们把要优化的目标的函数成为,
是其中要优化的参数

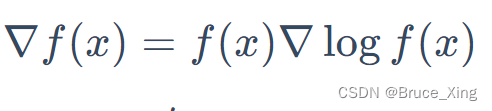
再根据链式法带入,则得到最后的目标函数。(终于得到可以用的目标的函数了🤪🤪,是不是很easy)
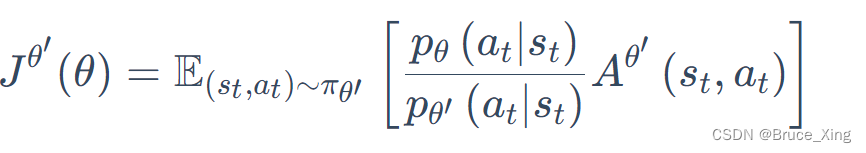
还记得开始的时候我们写的重要性采样原理吗?里面有很重要的一条的就是θ,θ′ 两个采样样本差异要小,这里就用KL散度(KL divergence)来衡量这个差异,如果你不知道KL散度是什么,可以看这篇。但是,这里我们只要记得KL散度就是用来衡量θ,θ′的差异大小。
初学机器学习:直观解读KL散度的数学概念 - 知乎选自 http://thushv.com,作者:Thushan Ganegedara,机器之心编译。机器学习是当前最重要的技术发展方向之一。近日,悉尼大学博士生 Thushan Ganegedara 开始撰写一个系列博客文章,旨在为机器学习初学者介绍一些…![]() https://zhuanlan.zhihu.com/p/37452654
https://zhuanlan.zhihu.com/p/37452654
PPO的公式就是在上面策略梯度的基础上加上一个KL散度的限制
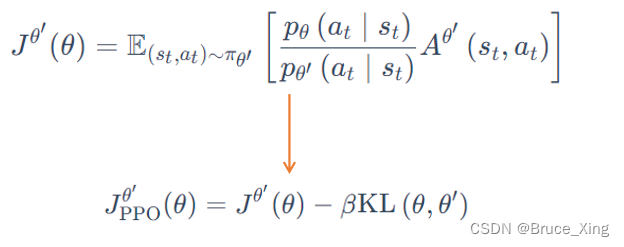
这里KL可以当做一个函数,注意这里θ 与 θ′ 的距离并不是参数上的距离,而是输出动作上的差异。
PPO 有一个前身:信任区域策略优化(trust region policy optimization,TRPO)。TRPO 可表示为如下:
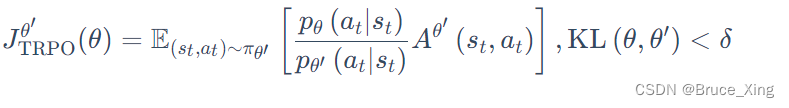
RPO 是很难处理的,因为它把 KL 散度约束当作一个额外的约束,没有放在目标(objective)里面,所以它很难计算。因此我们一般就使用 PPO,而不使用 TRPO 。PPO 与 TRPO 的性能差不多,但 PPO 在实现上比 TRPO 容易得多。
PPO 算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip)。
PPO1 是近端策略优化惩罚(PPO-penalty),在 PPO 的论文里面还有一个自适应KL散度(adaptive KL divergence)。这里会遇到一个问题就,即β 要设置为多少?这里easy-rl解释的非常清楚了,我就直接引用了
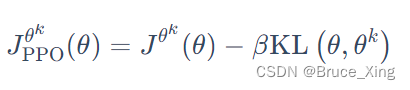
KL 散度的值太大,这就代表后面惩罚的项βKL(,
) 没有发挥作用,我们就把β 增大。另外,我们设一个 KL 散度的最小值。如果优化上式以后,KL 散度比最小值还要小,就代表后面这一项的效果太强了,我们怕他只优化后一项,使
与
一样,这不是我们想要的,所以我们要减小 β。β 是可以动态调整的,因此我们称之为自适应KL惩罚(adaptive KL penalty)。我们可以总结一下自适应KL惩罚:
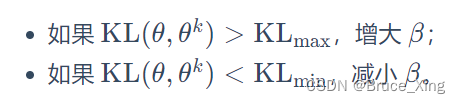
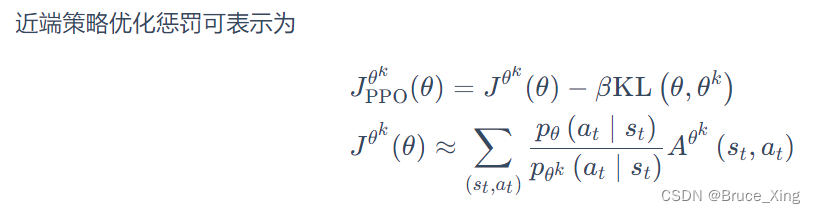
具体不再延伸,因为实际问题我们基本都会用PPO2而不是PPO1。本文的代码也是PPO2,所以向更具体了解的童鞋们可以再去看相关的论文。
PPO2可以说是简单粗暴,为什么这么说呢,看公式

计算KL散度太复杂,我干脆直接限定输出动作概率分布比值的最大最小值,就用min,和clip中的这一串,整个式子中:
就是这么简单粗暴,但是,实际效果却非常好!对于clip函数,再放一张图让大家便于理解:
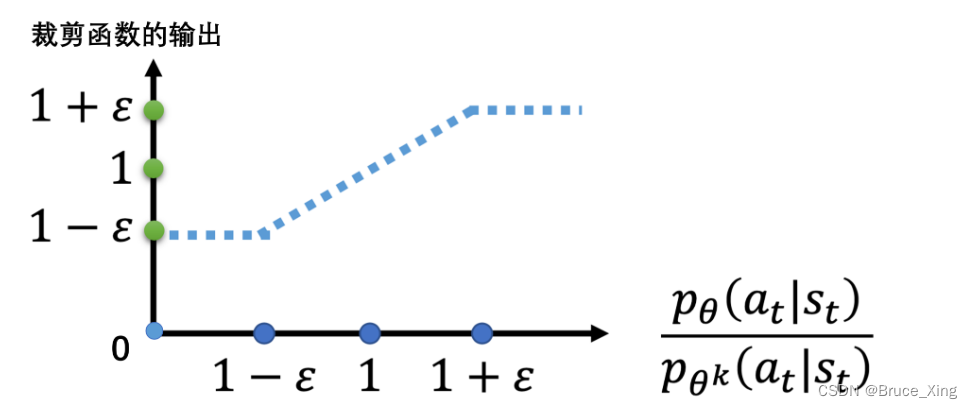
那么A是如何影响结果的呢,直接放图:
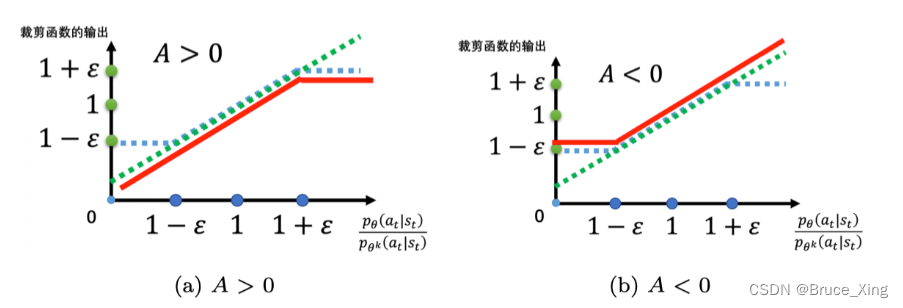
PPO2用了min,用了clip其实还是不想让 和
,差距过大,那么PPO2是怎么做到的?
这样和
差距就不会太大。
这一章节我们分析了PPO1,PPO2,基本上所用到的理论都覆盖到了,下一章我们将一步步的写PPO2的代码。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总