通过shell命令访问HDFS
HDFS shell大致可以分为操作命令、管理命令、其他命令三类。
注意:当命令以“$”开头时,当前用户为普通用户;以“#”开头时,当前用户为root用户。
操作命令是以“hdfs dfs”开头的命令,用户可以通过执行这些命令,完成对文件的查找、上传、删除等操作。
hdfs dfs -mkdir [-p] <paths>
[-p]:表示如果父目录不存在,先创建父目录
示例代码如下:
#新建文件夹/202012716/mydemo2
hdfs dfs -mkdir /202012716/mydemo2
#新建文件夹/202012716/mydemo/x/y/z
hdfs dfs -mkdir -p /202012716/mydemo/x/y/z
#在/202012716目录下新建文件夹mydemo3、mydemo4、mydemo5
hdfs dfs -mkdir /202012716/mydemo3 /202012716/mydemo4 /202012716/mydemo5
hdfs dfs -ls [-d] [-h] [-R] <paths>
[-d]:返回path。
[-h]:显示文件大小。
[-R]:级联显示paths下的文件
示例 列出HDFS文件下名为/202012716/mydemo的文件夹中的文件:
hdfs dfs -ls /202012716/mydemo
输出为:

hdfs dfs -put [-f] [-p] <localsrc> <dst>
hdfs dfs -copyFromLocal [-f] [-p] [-l] <localsrc> <dst>
put 或copyFromLocal 命令是将本地文件上传到HDFS。
localsre:表示本地文件路径。
dst:表示保存在HDFS上的路径。
示例 将本地文件上传到HDFS上:
#将本地目录txt1.txt文件上传到HDFS并重命名为hdfs1.txt
hdfs dfs -put txt1.txt /202012716/mydemo/hdfs1.txt
#将本地目录txt2.txt文件上传到HDFS并重命名为hdfs2.txt
hdfs dfs -copyFromLocal txt2.txt /202012716/mydemo/hdfs2.txt
hdfs dfs -get [-p] <src> <localdst>
hdfs dfs -copyToLocal [-p] [-ignoreCrc] [-crc] <src> <localdst>
get 或copyToLocal 命令是将把文件从分布式系统保存至本地。
示例 将hdfs中的文件保存到本地并重命名:
#将HDFS中的hdfs1.txt文件复制到本地系统并重命名为txt11.txt
hdfs dfs -get /202012716/mydemo/hdfs1.txt txt11.txt
#将HDFS中的hdfs3.txt文件复制到本地系统并重命名为txt3.txt
hdfs dfs -copyToLocal /202012716/mydemo/hdfs3.txt txt3.txt
hdfs dfs -cat/text [-ignoreCrc] <src>
hdfs dfs -tail [-f] <file>
-ignoreCrc:忽略循环检验失败的文件。
-f:动态更新显示数据。
示例 查看HDFS下/202012716/mydemo/hdfs2.txt文件中的内容:
hdfs dfs -cat /202012716/mydemo/hdfs2.txt
输出为:

hdfs dfs -rm [-f] [-r] <src>
-f:如果要删除的文件不存在,不显示错位信息。
-r/R:级联删除目录下所有文件和子目录下的文件。
示例 删除HDFS下名为hdfs3的文件:
#级联删除hdfs3.txt
hdfs dfs -rm -r /202012716/mydemo/hdfs3.txt
输出为:

这里是hdfs内部的文件移动和复制,与文件和从本地到分布式系统的移动不同。
hdfs dfs -cp [-f] [-p|-p[topax]] <src> <dst>
hdfs dfs -mv <src> <dst>
文件复制cp命令的参数:
-f:如果目标文件存在,将其强行覆盖。
-p:将保存文件的属性。
示例 将hdfs1.txt复制到hdfs3.txt中,将hdfs3.txt移动到hdfs4.txt中:
hdfs dfs -cp /202012716/mydemo/hdfs1.txt /202012716/mydemo/hdfs3.txt
hdfs dfs -mv /202012716/mydemo/hdfs3.txt /202012716/mydemo/hdfs4.txt
hdfs dfs -count [-p] [-h] <path>
count统计某个目录下的子目录与文件的个数及文件大小,统计结果包含目录数、文件数、文件大小。
示例如下:
先将/202012716/mydemo下的文件合并成一个文件merge.txt,并用命令查看merge.txt的内容。
#合并文件
hdfs dfs -getmerge /202012716/mydemo merge.txt
#查看merge.txt
cat merge.txt
merge.txt文件内容如下:

查看/202012716/mydemo的目录个数、文件个数、文件总计大小
hdfs dfs -count /202012716/mydemo
输出为:

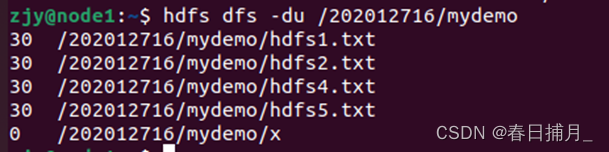
hdfs dfs -du [-s] [-h] <path>
按字节显示指定目录所占空间大小。
-s:显示目录下文件总的大小。
-h:表示按照人性化的单位显示文件大小。
示例 查看/202012716/mydemo目录下文件的大小:
hdfs dfs -du /202012716/mydemo
输出为:
管理命令是以“hdfs dfsadmin”开头的命令。
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。
查看用户是否处于安全模式:
hdfs dfsadmin -safemode get
进入安全模式:
hdfs dfsadmin -safemode enter
离开安全模式:
hdfs dfsadmin -safemode leave
快照功能为虚拟机保存了某个状态,若系统遭到某种破坏,可快速复原。
开启和禁用快照功能:
#开启/202012716/mydemo的快照功能
hdfs dfsadmin -allowSnapshot /202012716/mydemo
#关闭/202012716/mydemo2的快照功能
hdfs dfsadmin -disallowSnapshot /202012716/mydemo
创建、重命名和删除快照:
#为/202012716/mydemo创建快照s1
hdfs dfsadmin -createSnapshot /202012716/mydemo
#将/202012716/mydemo的快照改名为s2
hdfs dfsadmin -renameSnapshot /202012716/mydemo s1 s2
#删除快照s2
hdfs dfsadmin -deleteSnapshot /202012716/mydemo s2
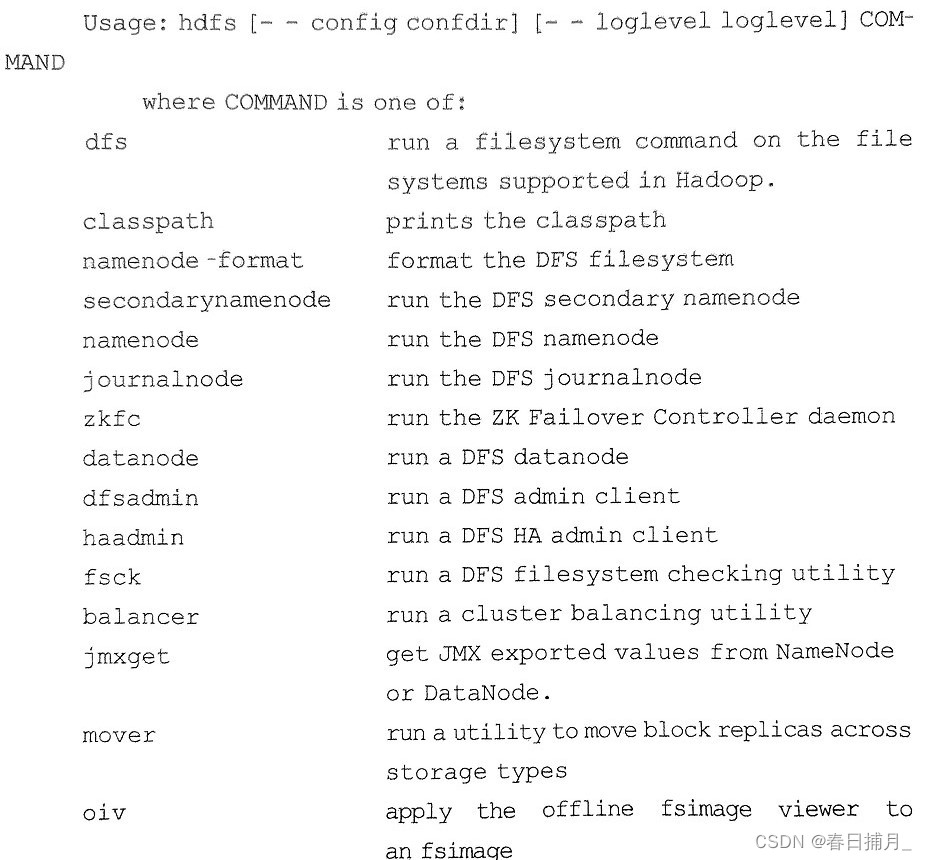
我们把操作命令"hdfs dfs"、管理命令"hdfs dfsadmin"之外的命令称为其他命令。
下面是输入“hdfs”后支持的所有子命令:

类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m