
1.1 互联网身份危机
众所周知,目前我们使用的互联网是没有身份层设计的。有个比较经典的笑话:在网上聊天你不能确定对方是人还是狗!很多网络犯罪往往也是基于此来进行。微博在初期就有很多相似的账号进行冒充诈骗,后面平台引入大V等机制来进行人工身份识别,但这种方式是比较繁琐且难以复制的。
身份是社会关系的总和,同一个人在不同的场景下的身份是不同的。比如在家庭身份里面你可能是父亲,丈夫,在工作身份里面可能是裁判,同事。不同的场景仅仅只是需要你的一部分身份而已,但目前的互联网存在过度收集用户信息,在用户不知情的情况下收集用户信息等风险。
1.2 互联网身份简史
在Web1.0时代(中心化身份),每个网站都通过唯一的用户名来标识不同的用户身份信息,这些用户信息都存在于该网站的数据库里。这种身份体系弊病很多:用户需要注册比较多的账号和密码,复杂的管理系统对账号的安全性也是一个比较大的挑战。
Web1.0
在Web2.0时代(联邦制身份),数字身份以平台为中心,同一平台内的不同产品间通过账号系统打通。例如,腾讯的邮箱、游戏、金融等皆可使用同一账号;Google、Facebook 等互联网头部企业也均有自己的账号体系。这种身份体系相比于Web1.0存在减少用户注册,平台背书等优势,但弊病也广为人知:平台相互间的账号并不互通,用户无法控制自己的身份数据。
Web2.0
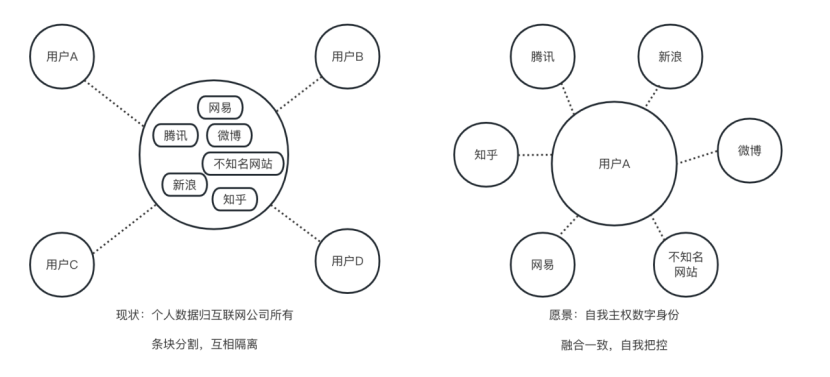
在Web3.0时代(自主权身份),身份标识变为了一个个的链上地址,在保证唯一性的前提下不需要用户手动去生成。用户身份数据不再存储于各大互联网公司数据库里而是在区块链上了,用户对自己的身份数据拥有绝对的控制权。

Web3.0
2.1去中心化身份(Decentralized Identity,DID)
我们出国需要护照,需要签证,需要各种繁琐且严格的审核。但互联网是全世界相通的,不可能说我访问一个国外的网站也需要类似的审核。所以一个通用的自主权身份就显得非常有必要。一个主体的身份,既不依赖于也不受制于中心化的组织或者国家。
但去中心化身份很容易产生下面的一些认知误区:
总的来说,DID是一个现实身份的有效补充,也是在不断发展更新的。
2.2 DID的标准和实现方式
目前DID标准主要分为两种:W3C标准和DIF标准。
W3C:用来标示人员、组织和事物,并保护安全和隐私。主要由“基础层DID规范”和“应用层可验证声明”组成。
DIF:最主要的作用是使用户掌握充分的所有权,从而可以建立一个开放的、去中心化身份的生态系统,并确保所有参与者之间的互操作性。
这里主要介绍W3C的DID标准和实现方式。其DID系统主要包括两个层次的要素,基础层和应用层。基础层——DID规范,包括DID标识与DID文档。
-- DID标识符
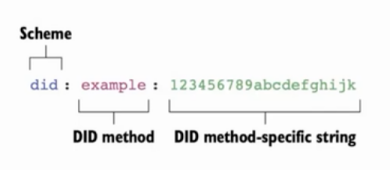
DID标识符是身份标识符的格式。DID的格式跟浏览器里面的URL非常相似。其中Scheme did相当于https协议。DID method相当于域名,里面会详情描述did的生成规则,并可以提交到W3C去校验和记录。最后面的一串数字就可以理解为path,生成规则是基于密码学来保证全局唯一性。整个DID只有一个作用就是作为一个索引去打开DID Document,就跟打开一个具体的网页一样。DID到Document的映射必须抗篡改,抗审查,且数据公开可见。
-- DID文档
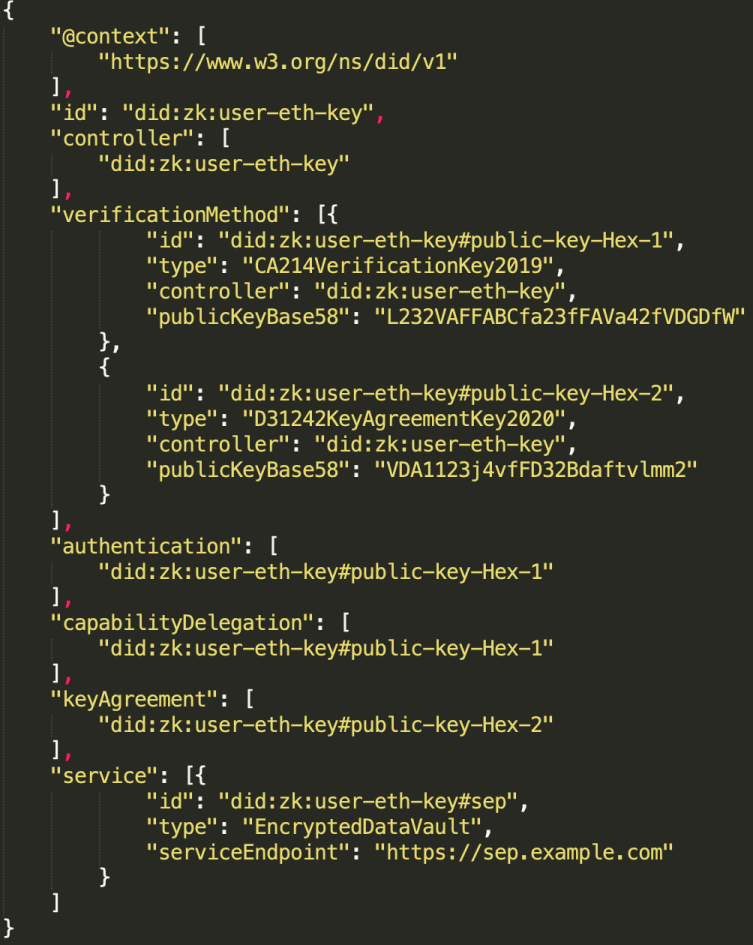
DID文档是身份信息的格式,是一个基于JSON格式的文档文件,其中包含很多有意义的键值对。
应用层——可验证声明(Verifiable Claims 或 Verifiable Credentials,简称VC)
隐私数据披露的方式,为数据授权(Authorization)提供了保障。下面是一个大致的运行机制图:
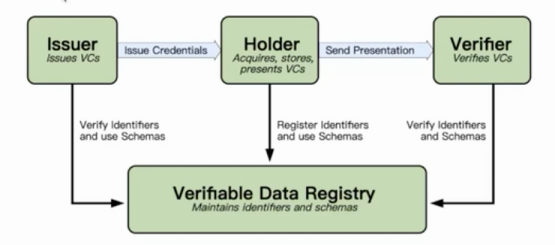
为了方便理解,我们以持有身份证去火车站坐高铁为例,整个流程跟我们目前的中心化的验证场景最大的区别在于:在中心化的场景里面Verifier的系统是需要跟Issuer联网的,而VC则不需要。一旦跟Issuer联网则意味着Verifier是有可能获取到你全部身份信息的,诸如婚姻状态等跟乘车毫不相关的信息。VC既可以减少系统冗余也可以保护用户隐私。在使用VC时用户可以根据不同的安全场景选择不同的使用方式:
1)全文出示;
2)选择性出示;
3)存在性证明;
其中“存在性证明”是保护隐私最好的一种方式,这里举例几个使用场景:
VC在验证的时候就会涉及到一个隐私计算的新领域——本地零知识证明计算。我们希望的是数据可证而不可见。在不出示计算输入数据和计算过程的情况下,以零知识证明的方式,证明计算的可信性,从而完成数据分析与计算的需要。
零知识证明其实在生活中也比较常见,比如你手机丢了,被人拾到放物业然后你去取。那物业如何判断手机是你的呢?通常我们的手机都会设置密码,只要你能通过面容或者密码解锁手机,那就可以判断手机就是你的,而你的其他隐私信息通通是不需要的。
目前已经有很多项目在使用零知识证明来构建基于Web3.0的自画像。首先将Web2.0的网站变为VC的签署方,使用零知识数字身份变为一个一个Tags,然后出示给Web3.0的网站。这里有个不同的是,Web2.0的网站其实也是对你打了很多Tags,但这是未经你允许的,你也无法编辑。而你提供给Web3.0的画像是你希望的,经过筛选的你愿意的,这才是真正的自画像。

人类生存几千年,早已形成一套依赖组织或国家成熟的身份系统,所以很多人会以为自主权身份离我们很远。但随着元宇宙的迅速发展,相信很多虚拟元素,无人设备(无人机,机器人...)将会更快的使用上自主权身份。相信在不久的将来,系统快速、准确地进行身份校验将会变成一个日常的基本需求。
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我需要在rail3中使用标准注册/登录/忘记密码功能进行身份验证。是否有大多数人为此使用的插件或其他东西? 最佳答案 我不确定最常用的方法是什么-但可以肯定的是,Plataformatec的“Devise”是一个非常流行的方法:http://github.com/plataformatec/devise我已经尝试了一些authgem,对我来说,它是最简单的设置和修改以满足我的需要。它内置了密码恢复、帐户确认(如果需要)和其他一些非常方便的功能。 关于ruby-on-rails-在Rail
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。11年前关闭。我是一位精通HTML
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke
我很难让它工作,所以我创建了一个hell世界的Rails应用程序来尝试让它工作。这是代码无效的代码库:https://github.com/pitosalas/shibtry这是我从一个空的Rails应用程序开始所做的:我在gem文件中添加了两个gem:gem'omniauth-shibboleth'gem'rack-saml'我从我大学的网站上获取了shibboleth元数据,并使用shib_conv.rb将其转换为相应的YAML:./config.yml我更新了路由,将get'/auth/:provider/callback',to:'sessions#create'我在Sessi