小伙伴们大家好呀,今天笔者给大家带来了一篇关于python接口自动化测试的文章,这篇文章主要讲解Python接口自动化测试框架模型的搭建,主要介绍如何设计框架,以及基础的框架运行等,话不多说,让我们一起看看吧~

框架搭建前必定是以一个项目的形式存在的,故此我们需要新建一个项目,你可以通过Open打开原有项目的一个包,以此来独立成一个项目,也可以直接使用New Project来创建一个新项目。

在任何一个项目中,我们都可以看到README这个文件,README文件是一个项目的说明文档,其中会包括基础的文件说明、框架搭建及维护的作者,框架认知、框架体系、框架结构、框架作用、项目说明、代码使用规范和注意事项等内容,具体内容通常依据个人或项目需要进行文件说明,文件可以采用md形式,也可以采用txt形式,可以附上一些说明,例如:
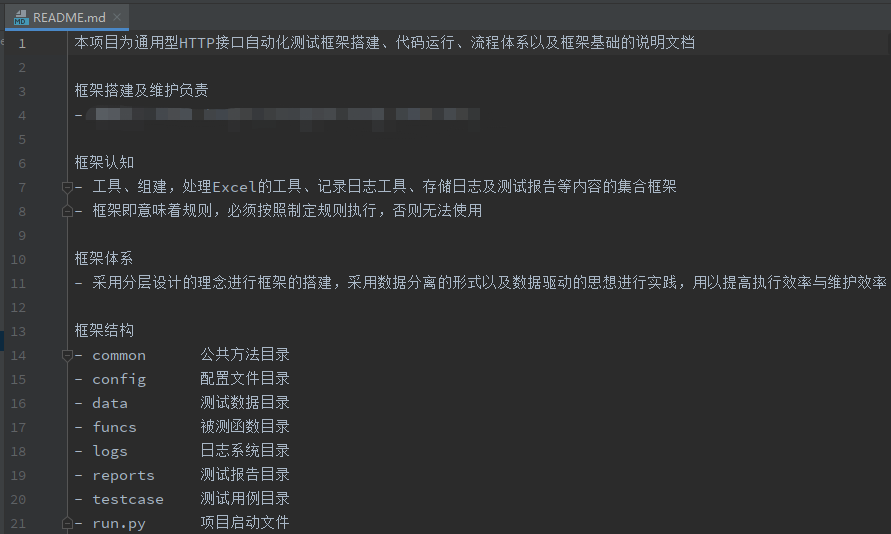
通常而言,我们项目中的代码需要进行版本控制,行业中常见的是svn与git,.gitignore文件用于git版本控制,而.gitignore文件的作用是:将特定的文件移除,不会进入至版本控制系统当中,不会进行上传。
比如代码运行所产生的缓存文件,这些缓存文件大多数会放入至__pycache__文件夹中,故此我们可以选择该文件夹,不纳入版本控制系统。还有项目创建所生成的,idea/文件夹,我们也可以不纳入版本控制。
在真实项目中需要特别注意,涉及到敏感数据,绝对不要放入至版本控制当中,例如测试账号、数据库地址等等,这样会暴露项目内容,严重会追究法律责任,如果你是在看本人文章的读者且正在使用公司项目实战,请务必小心!
不纳入版本控制的做法很简单,只需要在.gitignore文件中添加对应的文件夹或文件即可,添加一个后并换行可添加第二个,则代表该文件或文件夹不纳入版本控制,后续的具体内容有兴趣大家可以继续了解。
框架在生活中也能够比较常见,例如建造一座高楼大厦时,我们需要固定好这个大楼的外层结构,确保建造时大楼是笔直的,确保不会晃动,这就是高楼大厦的框架,而房屋的室内室外等均属于填充内容。
测试框架也是如此,我们需要搭建起一个自动化的测试框架,可重复设计和利用的内容,写的代码就是在进行框架填充,代码中会包括:
"""
工具、组件。-- 专门处理excel的工具、记录logger日志的工具、生成日志的工具等等
"""框架即意味着规则、规矩,任何人使用框架不能够违背,框架没有标准答案,只要你自己是框架的设计者,那么就是自己掌握话语权,好比我们在导入其他人所写的框架时,也必须遵守它们框架的语法、规则。
什么是分层设计?分层设计的概念是如何进行模块与包的划分,每一个目录就好比一个部门,各司其职,最后的结果就会接近于完美,而独立划分就是分层设计的思想与理念。
为什么需要进行分层设计?相信大家通过下图能够有基本概念,分层设计就是为了更好的进行框架整合、代码管理与维护,在某个"目录"出现异常时,我只需要对特定的"目录"进行管理即可有效解决问题,而不会对其他目录进行牵连。
"""
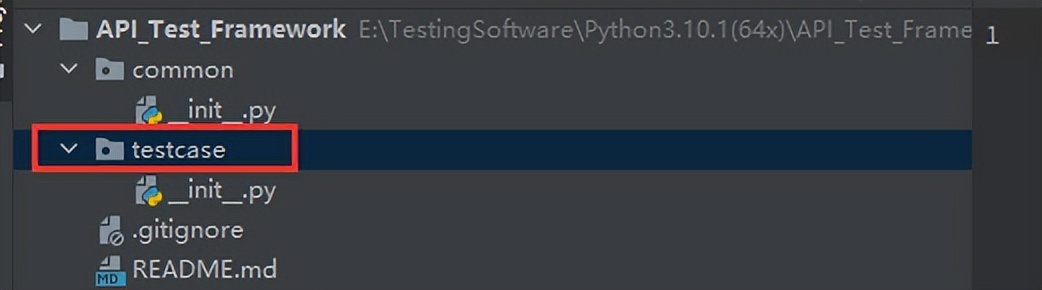
框架结构
- common 公共方法目录
- testcase 测试用例目录
- data 测试数据目录
- reports 测试报告目录
- config 配置文件目录
- logs 日志系统目录
- funcs 被测函数目录
- run.py 项目启动文件
"""新建一个Python package,命名为common,之所以我们要创建Python包而不是一个文件夹的主要原因是Python package中有__init__,如果没有这个文件,可能会在导入文件时失败。故此选择Python package。通常而言,如果这个文件夹里有Python文件,那么我们会使用Python package进行创建。
公用目录是通用的代码内容,可以理解成无论该框架如何进行移动、修改,公用目录内容均可以保持不变且在其他项目中,公用目录的内容可以完全复制过去进行使用。

testcase中存放的主要是自动化测试用例代码,里面包括各类的函数,因为存在py文件,故此我们需要Python package新建。
data中主要存放的是测试数据,数据可以是Excel的形式,也可以是Python模块的形式,故此我们这里的创建还是使用Python package。

测试报告的存放路径在reports,最终的测试报告不是Python模块,大多数是以html的方式存在的,在网页中可展示基础的数据信息和图表类信息,故此我们在创建时只需要建普通的文件夹即可,而不需要Python package。
配置文件目录为config,可能会包括数据库地址、用户名密码等常见内容,配置文件有可能会存在Python模块,我们仍然选用Python package。

日志存放目录会存放关于程序运行的日志内容,同样使用Python package创建。

被测函数目录主要是用于Python函数的代码存放,存放开发的Python函数文件,使用Python package创建。
在顶级目录创建Python文件,名为run,当执行run.py时则会执行所有的测试用例,主要起到程序运行作用。
在funcs下创建login.py,完成被测函数的填写,在testcase下创建test_login,补充一条测试用例:
"""login.py 被测函数"""
def login(username=None, password=None):
if username is None or password is None:
return {"code": 400, "msg": "用户名或密码为空" }
if username == "天天团" and password == "123456":
return {"code": 200, "msg": "登录成功" }
return {"code": 300, "msg": "用户名或密码错误" }""" test_login.py 测试用例"""
import unittest
from funcs.login import login
class TestLogin(unittest.TestCase):
def test_login_success(self):
username = "天天团"
password = "123456"
expected = {"code": 200, "msg": "登录成功" }
actual = login(username, password)
self.assertEqual(expected, actual)
如上图所示,执行结果为一条测试用例,耗时0.003s,测试通过。代表流程已经走通了。 2.8 执行文件
在run.py添加执行代码,并预备测试报告生成
import unittest
from unittestreport import TestRunner
from datetime import datetime
suite = unittest.defaultTestLoader.discover("testcase")
# 当前时间
data_str = str(datetime.now().strftime("%Y-%m-%d__%H-%M-%S"))
# 测试报告名称
reports_name = data_str + "项目框架演示测试报告.html"
runner = TestRunner(suite,
tester="天天团",
report_dir="reports",
filename=reports_name)
runner.run()
文件输出到了reports:
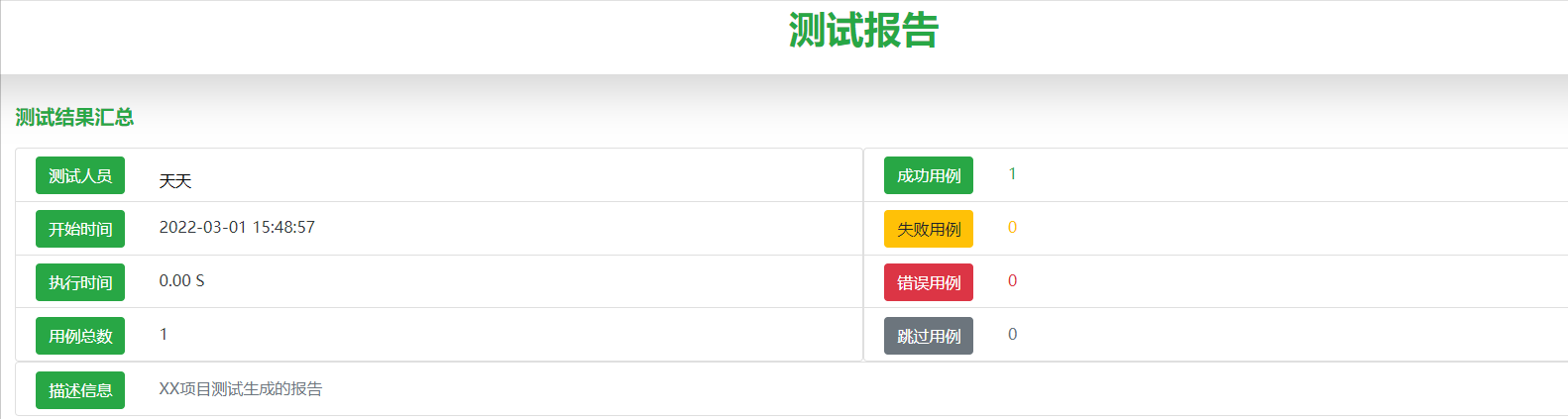
上半部分展示了一个基本的数据汇总,用例的总数、成功失败、错误等用例数量的具体数值,但这非实战阶段,故此测试用例只有1条演示的用例
中间的部分会有一个图表,图表的形式呈现上述的数据

最下层是详细信息,可以查看哪个类、哪个方法测试通过还是失败,可查看详情,也支持结果的筛选:

我们在项目中还需要使用到路径处理,有些时候我们需要读取对应的路径来获取我们想要的文件或数据,那么需要使用到os路径模块,此处不过多的解释,大家可以先行简单了解。
import os
# 获取当前文件路径
current_path = os.path.abspath(__file__)
# 获取config文件夹路径
config_dir = os.path.dirname(current_path)
# 项目根目录
root_dir = os.path.dirname(config_dir)
# data 目录
data_dir = os.path.join(root_dir, "data")
# xlsx文件目录
case_path = os.path.join(data_dir, "cases.xlsx")"""
框架执行:
第一步:框架设计、模块
第二步:在cases里面写自动化测试用例
第三步:在run.py收集测试用例,生成测试报告
后续实战阶段讲解:
第四步:封装通用的测试工具,公共代码
第五步:在用例当中调用log变量以增加日志
第六步:实现excel的数据驱动
"""这篇文章就分享到这里了哟,喜欢的小伙伴可以点赞收藏评论加关注哟,关注我每天给你带来不同的惊喜。

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/