文章目录
【动规:递归求解】
递推方程:
a[n - 1][y],这个就是问题的边界。d[i][j] = a[i][j] + max(a[i+1][j],a[i + 1][j + 1])既然有了上述的递推式,我们直到递归和递推其实是相互的,因此递推可以改写成递归的形式。
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 500 + 10;
int a[N][N];
int d[N][N];
int n;
int ans = -1e9;
// 求从点(x,y)开始,走到最后一层,经过数字的最大和。
int fun(int x, int y)
{
if(x == n) return a[x][y];// 最后一层的解就是自己
return a[x][y] + max(fun(x + 1, y), fun(x + 1, y + 1));// 如果不是最后一行就递归计算
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= i; j ++)
cin >> a[i][j];
cout << fun(1, 1);
return 0;
}
缺点:
效率太低了,并不是因为递归就效率低,而是因为存在了大量的重复计算。(类比递归式的斐波那契数列)
递归存在着大量不必要的重复计算,,递归的层数就越多,算的就越多,重复的计算更多!
【动规:记忆化搜索】
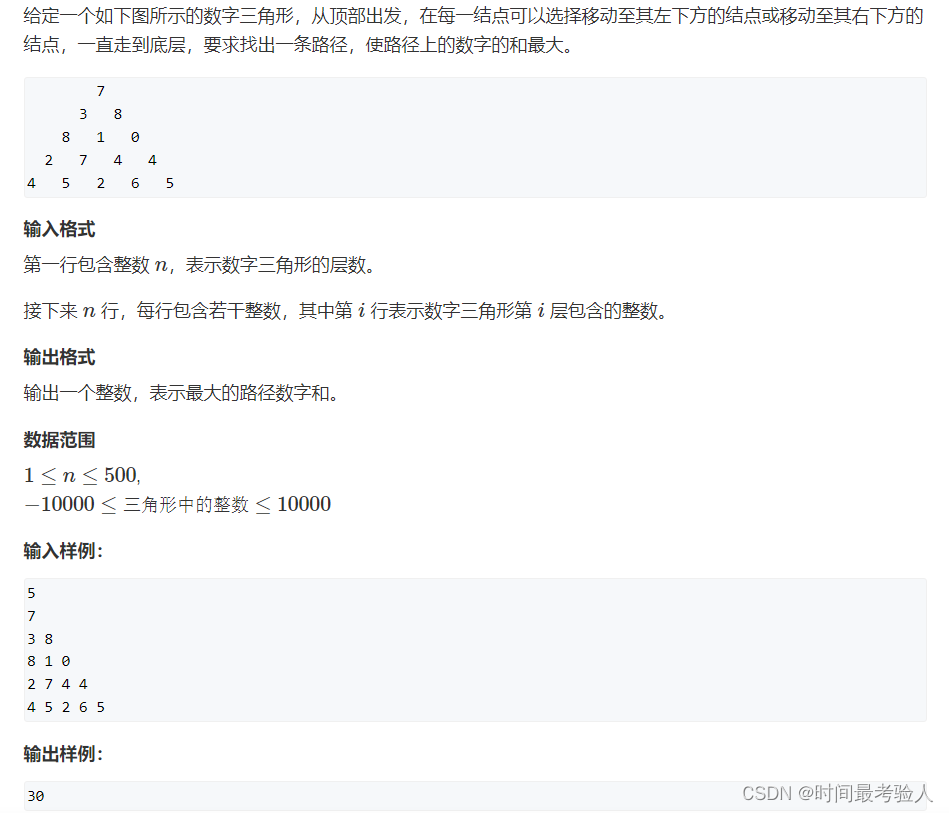
上述方法,存在着大量的重复计算,那我们如何在使用递归的情况下去优化,免去那些不必要的重复计算呢?
如上图,我们在求d[2][1]的时候就把d[3][2]计算过了,而我们再求d[2][2]的时候,又把d[3][2]再计算了一次,这就造成了重复计算?那如何解决呢?
在计算d[2][1]的时候就把d[3][2]计算过了,可以把d[3][2]用一个数组存下来,当再次需要d[3][2]时,就不需要再去递归求解了,直接用数组中备份过的数据就行——这就是记忆化搜索!
动规:记忆化搜索:
- 求解每一个点的值,先判断该点的值是否曾经求解过,如果曾经求解过,直接拿过来使用;如果没求解过,递归求解,并存储该解!
- 将计算过的值存储到一个数组中
- 如何判断是否求解过呢?——做标记判断
【代码实现】
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 500 + 10;
int a[N][N];
int d[N][N];
int n;
int ans = -1e9;
//动规,记忆化搜索:先将d数组初始化为-1,方便判断有没有求解过
int fun(int x, int y)
{
if(x == n) return a[x][y];// 最后一层的解就是自己
else
{
if(d[x][y] != -1) return d[x][y];// 曾经求解过
else
{
//求解(x,y)点走到底层经过的数字和的最大值,并存储
d[x][y] = a[x][y] + max(fun(x + 1, y), fun(x + 1, y + 1));
return d[x][y];
}
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= i; j ++)
cin >> a[i][j];
memset(d, -1, sizeof d);
cout << fun(1, 1);
return 0;
}
当然数塔问题也可以用递推还有dfs深搜(会爆炸)的方式来求解。

dfs深搜代码如下:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 310;
int h[N][N];
int n, m;
int ans = -1e9;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
int dfs(int x, int y, int len)
{
if(len > ans) ans = len;
for(int i = 0; i < 4; i ++)
{
int a = x + dx[i], b = y + dy[i];
if(a >= 0 && a < n && b >= 0 && b < m && h[x][y] > h[a][b])
{
dfs(a, b, len + 1);
}
}
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i ++ )
for (int j = 0; j < m; j ++ )
scanf("%d", &h[i][j]);
memset(dp, -1, sizeof dp);
for (int i = 0; i < n; i ++ )
for (int j = 0; j < m; j ++ )
{
int len = 0;
dfs(i, j, len);
}
printf("%d", ans + 1);
return 0;
}
dfs爆搜会超时!
本来是一个dfs的过程,遍历所有的位置,找到从当前位置往下走的最大路径,再取最大值,单纯递归深搜的缺点就在于:存在着大量的重复计算。因此我们可以用一个数组,将把遍历过的位置往下走的路径的最大值进行记录,再次遇到直接拿来使用即可,这就是记忆化搜索(空间换时间)。
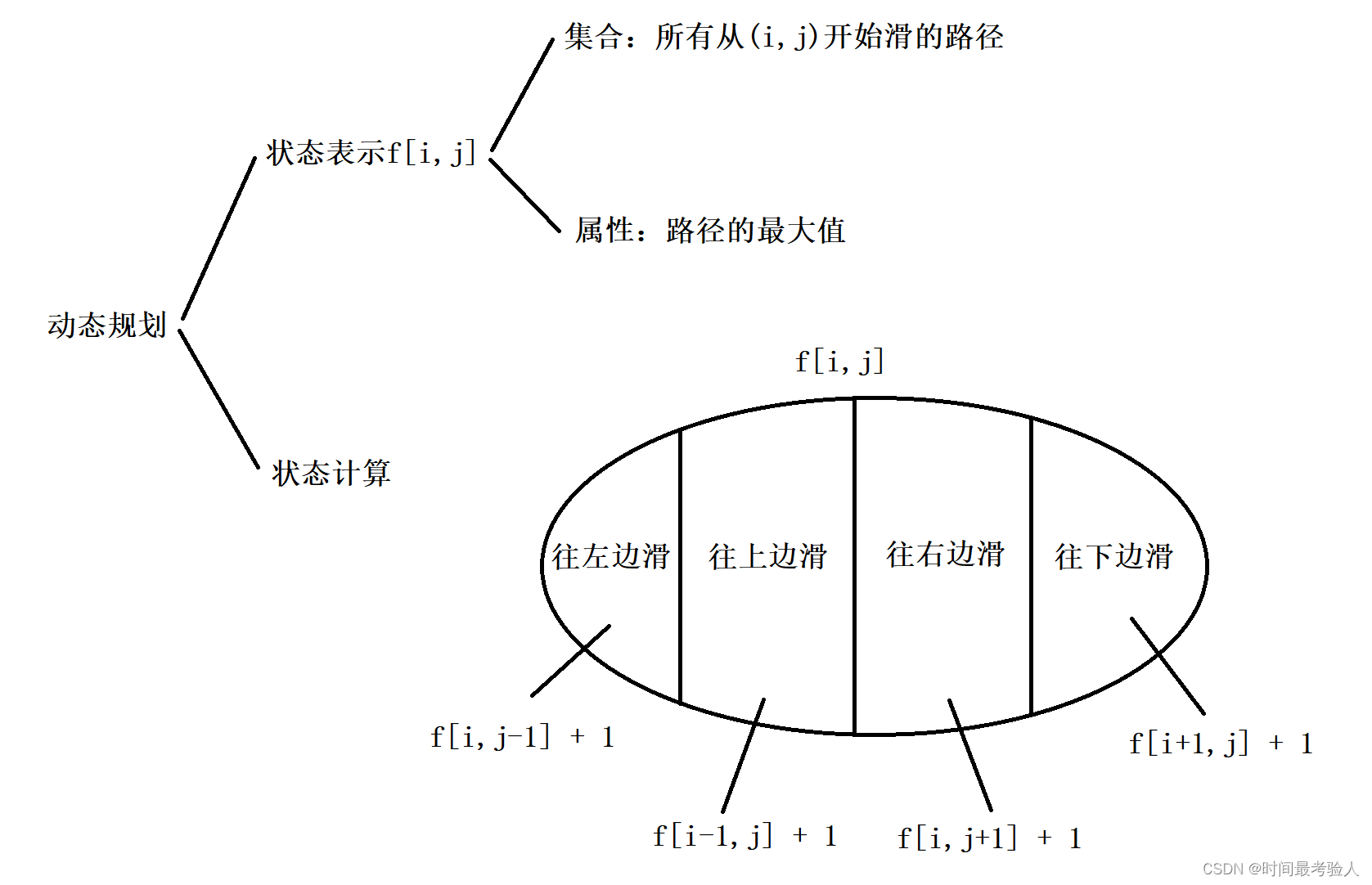
思路:dfs + 记忆化
遍历每个点作为起点
然后检测该点四周的点 如果可以滑动到其他的点
那么该点的最大滑动长度 就是其他可以滑到的点的滑动长度+1
【代码实现】
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 310;
int h[N][N];
int dp[N][N]; 记录从(x,y)点能滑雪的最长距离
int n, m;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
//递归 + 记录结果 == 记忆化搜索(DP的一种)
int dfs(int x, int y)
{
if(dp[x][y] != -1) return dp[x][y];// 被计算过了,直接拿,不用再次计算
dp[x][y] = 1;// 初始化
for(int i = 0; i < 4; i ++)
{
int a = x + dx[i], b = y + dy[i];
if(a >= 0 && a < n && b >= 0 && b < m && h[x][y] > h[a][b])
{
dp[x][y] = max(dp[x][y], dfs(a, b) + 1);
}
}
return dp[x][y];
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i ++ )
for (int j = 0; j < m; j ++ )
scanf("%d", &h[i][j]);
memset(dp, -1, sizeof dp);
int res = 0;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < m; j ++ )
res = max(res, dfs(i ,j));
printf("%d", res);
return 0;
}
记忆化深搜,其实就是对递归dfs暴力的一种优化,将计算过的记录下来,避免重复计算。记忆化深搜也属于DP的一种!
最常见的DP就是那种寻找状态转移方程(递推式)递推求解的了。
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是