在日常的开发过程中,经常会使用到excel工作簿进行数据的保存,那么在java中,通常会使用第三方提供的技术来进行excel文件的解析,比如:Apache POI、JXL、Alibaba EasyExcel。本文则使用的是Apache POI和Alibaba EasyExcel。
目前Apache POI用的比较广泛的实现类是XSSFWorkbook(),主要因为当前版本的excel文件大多数都是以“.xlsx”结尾的,XSSFWorkbook()能识别的就是这种文件。当然Apache POI也提供了HSSFWorkbook()实现类,主要适用于以“.xls”结尾的excel文件,但是由于这种文件只能存储65535行数据,所以HSSFWorkbook()已经不常用了。

1.创建WorkBook,一个WorkBook代表一个Excel文件
2.以输出流的形式创建出Excel文件
3.调用createSheet(0)创建工作簿
4.调用createRow(0)创建行
5.调用createCell(0)创建单元格
6.调用setCellValue()完成对单元格内容的写入
7.调用write()方法,将Workbook对象中包含的数据,通过输出流,写入至Excel文件
package com.fulian.Demo;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.LocalDateTime;
import java.util.UUID;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class Demo03 {
public static void main(String[] args) {
try (Workbook workbook = new XSSFWorkbook();
FileOutputStream out = new FileOutputStream("d:\\test\\demo.xlsx")) {
// 创建工作簿sheet
Sheet sheet0 = workbook.createSheet("2020数据列表");
Sheet sheet1 = workbook.createSheet("2021数据列表");
Sheet sheet2 = workbook.createSheet("2022数据列表");
//创建数据行Row
Row row0 = sheet0.createRow(0);
Row row = sheet0.createRow(1);
// 创建单元格
Cell cell00 = row0.createCell(0);
cell00.setCellValue("UUID值");
Cell cell0 = row.createCell(0);
cell0.setCellValue(UUID.randomUUID().toString());
Cell cell01 = row0.createCell(1);
cell01.setCellValue("Math随机值");
Cell cell1 = row.createCell(1);
cell1.setCellValue(Math.random()*1000);
Cell cell02 = row0.createCell(2);
cell02.setCellValue("当前时间");
Cell cell2 = row.createCell(2);
cell2.setCellValue(LocalDateTime.now());
// 将Workbook对象中包含的数据,通过输出流,写入至Excel文件
workbook.write(out);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
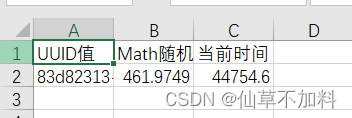
}当前新写入 excel文件内容如下
1.以输入流的形式获取到excel文件
2.创建WorkBook,传入该输入流
3.调用getSheetAt(0),获取到工作簿
4.调用getRow()获取到行
5.getCell()获取到单元格
6.调用getStringCellValue()获取到String的类型的值,调用getNumericCellValue()获取到double类型的值
package com.fulian.Demo;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class Demo07 {
public static void main(String[] args) {
try (Workbook workbook = new XSSFWorkbook(new FileInputStream("d:\\test\\demo.xlsx"))) {
// 获取工作簿
Sheet sheet = workbook.getSheetAt(0);
for(int i = 1 ; i <= sheet.getLastRowNum();i++) {
Row row = sheet.getRow(i);
// 按照下标获取当前行的单元格
Cell cell0 = row.getCell(0); // UUID
Cell cell1 = row.getCell(1); // Math
Cell cell2 = row.getCell(2); // 日期
System.out.println("UUID值:" + cell0.getStringCellValue());
System.out.println("Math随机值:" + cell1.getNumericCellValue());
System.out.println("当前时间:" + cell2.getNumericCellValue());
}
}catch (IOException e) {
e.printStackTrace();
}
}
}
// 运行结果
UUID值:83d82313-cade-42bf-8aae-193ce655ea56
Math随机值:461.97493844727467
当前时间:44754.60497915509
在上面的案例中,我们不难发现:当传入一个日期类型的字段值,excel文件中显示的是数字,因此就必须要设置单元格样式了。
首先调用workbook的createCellStyle()方法创建单元格格式对象CellStyle,然后调用workbook的createDataFormat()方法,获取到DataFormat类型的对象,通过DataFormat.getFormat(),设置单元格的格式,获取到该格式编码并作为参数传入CellStyle.setDataFormat()方法,在单元格需要设置格式时,调用setCellStyle()方法,传入一个cellStyle对象,最后,调用setCellValue(new Date()),传入一个Date对象,完成对单元格日期格式的设置。
package com.fulian.Demo;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.LocalDateTime;
import java.util.Date;
import java.util.UUID;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellStyle;
import org.apache.poi.ss.usermodel.DataFormat;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class Demo03 {
public static void main(String[] args) {
try (Workbook workbook = new XSSFWorkbook();
FileOutputStream out = new FileOutputStream("d:\\test\\demo.xlsx")) {
// 创建单元格格式
// 获取格式编码
DataFormat dataFormat = workbook.createDataFormat();
short formatCode = dataFormat.getFormat("yyyy-MM-dd HH:mm:ss");
// 创建CellStyle单元格格式对象
CellStyle cellStyle = workbook.createCellStyle();
cellStyle.setDataFormat(formatCode); // 设置单元格格式编码
// 创建工作簿sheet
Sheet sheet0 = workbook.createSheet("2020数据列表");
Sheet sheet1 = workbook.createSheet("2021数据列表");
Sheet sheet2 = workbook.createSheet("2022数据列表");
// 创建数据行Row
Row row0 = sheet0.createRow(0);
Row row = sheet0.createRow(1);
// 创建单元格
Cell cell00 = row0.createCell(0);
cell00.setCellValue("UUID值");
Cell cell0 = row.createCell(0);
cell0.setCellValue(UUID.randomUUID().toString());
Cell cell01 = row0.createCell(1);
cell01.setCellValue("Math随机值");
Cell cell1 = row.createCell(1);
cell1.setCellValue(Math.random() * 1000);
Cell cell02 = row0.createCell(2);
cell02.setCellValue("当前时间");
Cell cell2 = row.createCell(2);
cell2.setCellStyle(cellStyle); // 设置单元格格式
cell2.setCellValue(new Date());
// 将Workbook对象中包含的数据,通过输出流,写入至Excel文件
workbook.write(out);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
修改后demo文件内容即可正常显示日期类型:

EasyExcel是一个基于Java的简单、省内存的读写Excel的开源项目。在尽可能节约内存的情况下支持读写百M的Excel。
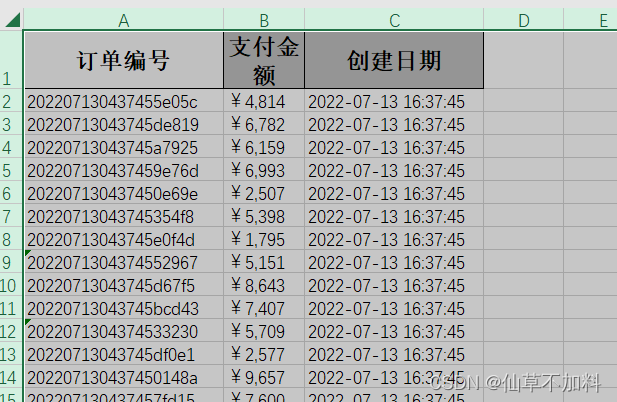
创建文本文件主要使用write()方法,需要的参数是Excel文件的地址,和要写入内容的类型,这里提前准备了一个Order类,在Order类中,注解@ExcelProperty()代表列头单元格的内容,注解@NumberFormat()代表单元格格式,但是如果数据单元格是一个LocalDateTime类型的对象,程序会识别不到,需要定义一个converter转换器对象,官方文档给出了LocalDateTimeConverter实现类,这里就需要手动创建并导入。代码如下:
package com.fulian.demo;
import java.util.ArrayList;
import java.util.List;
import com.alibaba.excel.EasyExcel;
import com.fulian.entity.Order;
public class Demo01 {
public static void main(String[] args) {
// 写入100w
EasyExcel.write("d:\\test\\easy100w.xlsx", Order.class)
.sheet("订单列表")
.doWrite(data());
}
// 创建100w条订单数据
private static List<Order> data() {
List<Order> list = new ArrayList<Order>();
for (int i = 0; i < 1000000; i++) {
list.add(new Order());
}
return list;
}
}Order类
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.UUID;
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.annotation.format.NumberFormat;
public class Order {
@ExcelProperty("订单编号")
private String orderId; // 订单编号
@ExcelProperty("支付金额")
@NumberFormat("¥#,###")
private Double payment; // 支付金额
@ExcelProperty(value = "创建日期",converter = LocalDateTimeConverter.class)
private LocalDateTime creationTime; // 创建时间
public Order() {
this.orderId = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddhhmmss"))
+ UUID.randomUUID().toString().substring(0, 5);
this.payment = Math.random() * 10000;
this.creationTime = LocalDateTime.now();
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Double getPayment() {
return payment;
}
public void setPayment(Double payment) {
this.payment = payment;
}
public LocalDateTime getCreationTime() {
return creationTime;
}
public void setCreationTime(LocalDateTime creationTime) {
this.creationTime = creationTime;
}
@Override
public String toString() {
return "Order [orderId=" + orderId + ", payment=" + payment + ", creationTime=" + creationTime + "]";
}
}LocalDateTimeConverter实现类
package com.fulian.entity;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import com.alibaba.excel.converters.Converter;
import com.alibaba.excel.enums.CellDataTypeEnum;
import com.alibaba.excel.metadata.CellData;
import com.alibaba.excel.metadata.GlobalConfiguration;
import com.alibaba.excel.metadata.property.ExcelContentProperty;
public class LocalDateTimeConverter implements Converter<LocalDateTime> {
@Override
public Class<LocalDateTime> supportJavaTypeKey() {
return LocalDateTime.class;
}
@Override
public CellDataTypeEnum supportExcelTypeKey() {
return CellDataTypeEnum.STRING;
}
@Override
public LocalDateTime convertToJavaData(CellData cellData, ExcelContentProperty contentProperty,
GlobalConfiguration globalConfiguration) {
return LocalDateTime.parse(cellData.getStringValue(), DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
@Override
public CellData<String> convertToExcelData(LocalDateTime value, ExcelContentProperty contentProperty,
GlobalConfiguration globalConfiguration) {
return new CellData<>(value.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
}
}
运行结果
读取数据需要调用read()方法,参数包括:文件地址,读取内容的类型以及监听器对象,而这里使用的是AnalysisEventListener的一个匿名子类,只重写了3个方法:invoke()方法表示监听器在获取到每行的数据时需要执行的操作;incokeHeadMap()方法表示把列头中的单元格内容存到一个map集合中,后续需要列头时只需要调用map集合即可;doAfterAllAnalysed()方法表示所有数据读完后的操作。代码如下:
package com.fulian.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.fulian.entity.Order;
public class Demo02 {
public static void main(String[] args) {
List<Order> orderList = new ArrayList<Order>();
EasyExcel.read("d:\\test\\easy100w.xlsx", Order.class,new AnalysisEventListener<Order>() {
@Override
public void invoke(Order order, AnalysisContext arg1) {
// 读取每条数据
orderList.add(order);
}
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
// 读取到列头
System.out.println(headMap);
super.invokeHeadMap(headMap, context);
}
@Override
public void doAfterAllAnalysed(AnalysisContext arg0) {
// 读取完毕
System.out.println("END");
}
}).sheet().doRead();
for(Order order : orderList) {
System.out.println(order);
}
}
}
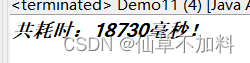
比如说要写入100万条数据,如果我们使用XSSFWorkbook()实现类,那么写入的过程中需要占据大量的cpu和内存,耗费时间较慢,代码如下
package com.fulian.Demo;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class Demo11 {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
try (Workbook workbook = new XSSFWorkbook();
FileOutputStream out = new FileOutputStream("d:\\test\\demo\\XSSF100w.xlsx")) {
Sheet sheet = workbook.createSheet();
for (int i = 0; i < 1000000; i++) {
Row row = sheet.createRow(i);
Cell cell = row.createCell(0);
cell.setCellValue(i);
}
workbook.write(out);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - begin) + "毫秒!");
}
}
结果:
使用SXSSFWorkbook()实现类,可以通过设置构造方法中的参数,当内存中的行数达到这个参数值时,会立即释放内存,把数据存储到磁盘中,大大减缓了cpu和内存空间的使用,提高了运行速度。代码如下:
package com.fulian.Demo;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
public class Demo12 {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
try (Workbook workbook = new SXSSFWorkbook(100);
FileOutputStream out = new FileOutputStream("d:\\test\\demo\\SXSSF100w.xlsx")) {
Sheet sheet = workbook.createSheet();
for (int i = 0; i < 1000000; i++) {
Row row = sheet.createRow(i);
Cell cell = row.createCell(0);
cell.setCellValue(i);
}
workbook.write(out);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - begin) + "毫秒!");
}
}
结果:

package com.fulian.demo;
import java.util.ArrayList;
import java.util.List;
import com.alibaba.excel.EasyExcel;
public class Demo03 {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
// 写入100w
EasyExcel.write("d:\\test\\demo\\easy100w.xlsx", Integer.class).sheet().doWrite(data());
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - begin) + "毫秒!");
}
// 创建100w条数据
private static List<Integer> data() {
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 1000000; i++) {
list.add(i);
}
return list;
}
}
结果:

读取数据需要调用read()方法,参数包括:文件地址,读取内容的类型以及监听器对象,而这里使用的是AnalysisEventListener的一个匿名子类,只重写了3个方法:invoke()方法表示监听器在获取到每行的数据时需要执行的操作;incokeHeadMap()方法表示把列头中的单元格内容存到一个map集合中,后续需要列头时只需要调用map集合即可;doAfterAllAnalysed()方法表示所有数据读完后的操作。代码如下:
package com.fulian.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
public class Demo04 {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
List<Integer> list = new ArrayList<Integer>();
EasyExcel.read("d:\\test\\demo\\easy100w.xlsx", Integer.class,new AnalysisEventListener<Integer>() {
@Override
public void invoke(Integer i, AnalysisContext arg1) {
// 读取每条数据
list.add(i);
}
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
// 读取到列头
System.out.println(headMap);
super.invokeHeadMap(headMap, context);
}
@Override
public void doAfterAllAnalysed(AnalysisContext arg0) {
// 读取完毕
System.out.println("END");
}
}).sheet().doRead();
long end = System.currentTimeMillis();
System.out.println("共耗时:" + (end - begin) + "毫秒!");
}
}
结果:

EasyExcel技术在读写超大Excel文件时相比POI读写超大Excel文件上读写速度、性能、内存占用等优势较为明显,而且在是实体类上通过注解的形式,更加明显的表示出excel文件的列名以及单元格的形式,兼容性更强,上手更加容易、灵活。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i