本文以一段代码为例,简单介绍一下tensorflow与pytorch的相互转换(主要是tensorflow转pytorch),可能介绍的没有那么详细,仅供参考。
由于本人只熟悉pytorch,而对tensorflow一知半解,而代码经常遇到tensorflow,而我希望使用pytorch,因此简单介绍一下tensorflow转pytorch,可能存在诸多错误,希望轻喷~
目录
在TensorFlow的世界里,变量的定义和初始化是分开的。
tensorflow中一般都是在开头预定义变量,声明其数据类型、形状等,在执行的时候再赋具体的值,如下图所示,而pytorch用到时才会定义,定义和变量初始化是合在一起的。
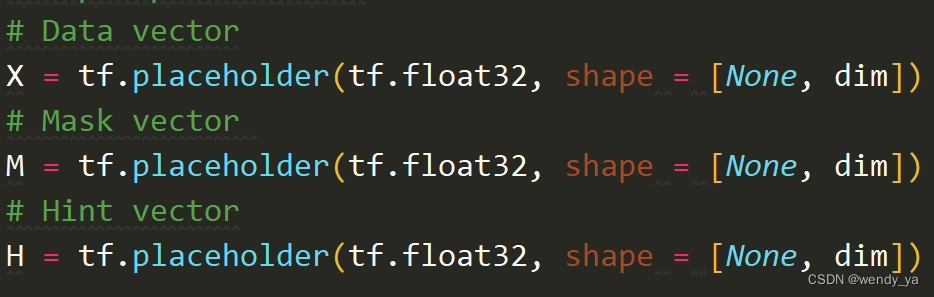
tensorflow中利用tf.Variable创建变量并进行初始化,而pytorch中使用torch.tensor创建变量并进行初始化,如下图所示。
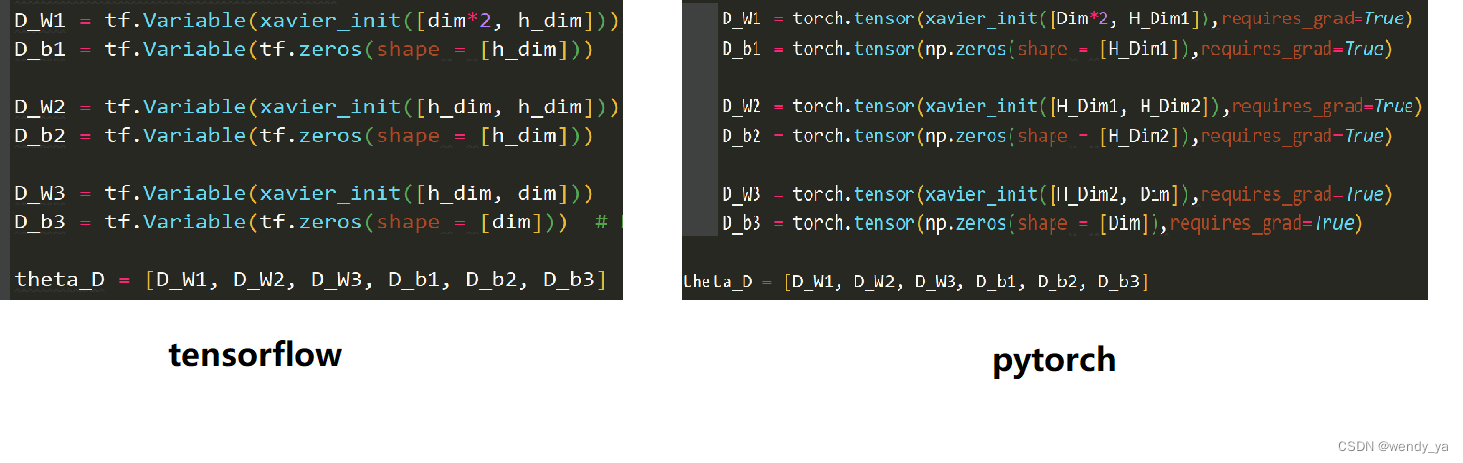
在TensorFlow的世界里,变量的定义和初始化是分开的,所有关于图变量的赋值和计算都要通过tf.Session的run来进行。
sess.run([G_solver, G_loss_temp, MSE_loss],
feed_dict = {X: X_mb, M: M_mb, H: H_mb})
而在pytorch中,并不需要通过run进行,赋值完了直接计算即可。
pytorch运算时要创建完的numpy数组转为tensor,如下:
if use_gpu is True:
X_mb = torch.tensor(X_mb, device="cuda")
M_mb = torch.tensor(M_mb, device="cuda")
H_mb = torch.tensor(H_mb, device="cuda")
else:
X_mb = torch.tensor(X_mb)
M_mb = torch.tensor(M_mb)
H_mb = torch.tensor(H_mb)
最后运行完还要将tensor数据类型转换回numpy数组:
if use_gpu is True:
imputed_data=imputed_data.cpu().detach().numpy()
else:
imputed_data=imputed_data.detach().numpy()
而tensorflow中不需要这种操作。
在tensorflow中包含诸多函数是pytorch中没有的,但是都可以在其他库中找到类似,具体如下表所示。
| tensorflow中函数 | pytorch中对应的函数 | 参数区别 |
|---|---|---|
| tf.sqrt | torch.sqrt | 完全相同 |
| tf.random_normal | np.random.normal(numpy) | tf.random_normal(shape = size, stddev = xavier_stddev) np.random.normal(size = size, scale = xavier_stddev) |
| tf.concat | torch.cat | inputs = tf.concat(values = [x, m], axis = 1) inputs = torch.cat(dim=1, tensors=[x, m]) |
| tf.nn.relu | F.relu(torch.nn.functional) | 完全相同 |
| tf.nn.sigmoid | torch.sigmoid(torch) | 完全相同 |
| tf.matmul | torch.matmul(torch) | 完全相同 |
| tf.reduce_mean | torch.mean(torch) | 完全相同 |
| tf.log | torch.log(torch) | 完全相同 |
| tf.zeros | torch.zeros | 完全相同 |
| tf.train.AdamOptimizer | torch.optim.Adam(torch) | optimizer_D = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D) optimizer_D = torch.optim.Adam(params=theta_D) |
【说明】:本文的介绍仅供参考,实际转换请多查阅相关资料,如果有能力,建议这两种深度学习框架都进行掌握~
参考:1. https://blog.csdn.net/dou3516/article/details/109181203
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。