目录
对于调参,首先需要明白调参的核心问题是什么,然后理清思路,再进行调参。调参并非是一件容易的事情,很多大牛靠的是多年积累的经验和清晰的处理思路,那对于我们而言,也应对调参思路和方向有一个认识,然后就是不断地尝试。
1、调参的目的是什么?
2、模型在未知数据上的准确率受什么因素影响?
泛化误差:衡量模型在未知数据上的准确率(准确率越高,泛化误差越小),受模型复杂度的影响。
模型复杂度与准确率的关系,就像压力值与考试成绩的关系,压力越大或者没有压力成绩往往越低,只有压力适当时,成绩才会更高。同理,模型越复杂或越简单往往结果也会不尽人意,那我们的目标就清楚了,就是将模型不至于太复杂也不至于太简单。比如,当为模型增加复杂度时,准确率提升,泛化误差降低,那说明此时模型有些简单,反之,如果降低模型复杂度,反而准确率提升,那说明此时模型较为复杂,适当调整简单即可。
对于树模型或者树的集成模型,树的深度越深,枝叶越多,模型越复杂。往往树模型或者树的集成模型普遍较为复杂,我们需要做的就是降低复杂度,进而提升准确率。
降低复杂度,对复杂度影响巨大的参数挑选出来,研究他们的单调性,然后专注调整那些最大限度能让复杂度降低的参数,对于那些不单调的参数或者反而让复杂度升高的参数,视情况而定,大多时候甚至可以退避。(表中从上往下,建议调参的程度逐渐减小)

有些参数没有参照,很难说清楚范围,这种情况用学习曲线看趋势,从曲线跑出的结果中选取一个更小的区间,再跑曲线,以此类推(建议打印输出最大值及其取的值)。
#调参第一步:n_estimators
cross = []
for i in range(0,200,10):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,201,10),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print((cross.index(max(cross))*10)+1,max(cross))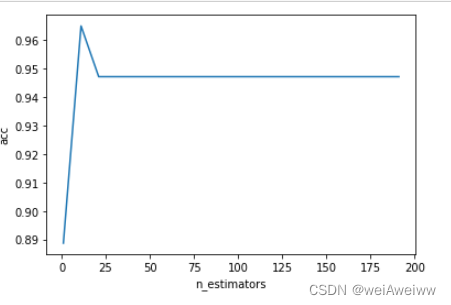
有一些参数有一定范围,或者我们知道他们的取值和随着他们的取值模型的准确率会如何变化。在这里值得说明的一点是,网格搜索,如果一次性在参数列表中写出多个参数及对应值,它不会抛弃任何一个我们设置的参数值,会尽力组合,而有时候效果可能不太好,且费时。那建议的操作是,可以一次设定一到两个参数及其值。
from sklearn.model_selection import GridSearchCV
#调整max_depth
param_grid = {'max_depth' : np.arange(1,20,1)}
#一般根据数据大小进行尝试,像该数据集 可从1-10 或1-20开始
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_ #最佳参数组合
GS.best_score_ #最佳得分代码建议在jupyter notebook分段运行,因为最起码能保证划分的测试集和训练集不会变化,这样调参才有意义。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
data = load_breast_cancer() #乳腺癌案例
print(data.data.shape)
xtrain,xtest,ytrain,ytest = train_test_split(data.data,data.target,test_size=0.3)
# GridSearchCV
rf = RandomForestClassifier(n_estimators=100,random_state=42)
rf.fit(xtrain,ytrain)
score = rf.score(xtest,ytest)
cross_s = cross_val_score(rf,xtest,ytest,cv=5).mean()
print('rf:',score)
print('cv:',cross_s)
#调参第一步:n_estimators
cross = []
for i in range(0,200,10):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,201,10),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print((cross.index(max(cross))*10)+1,max(cross))
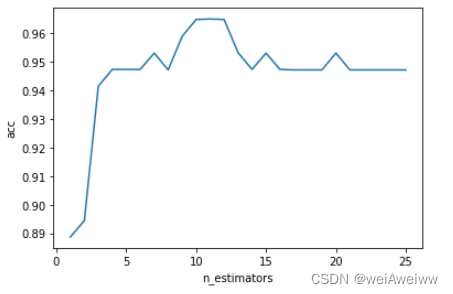
# n_estimators缩小范围
cross = []
for i in range(0,25):
rf = RandomForestClassifier(n_estimators=i+1, n_jobs=-1,random_state=42)
cross_score = cross_val_score(rf, xtest, ytest, cv=5).mean()
cross.append(cross_score)
plt.plot(range(1,26),cross)
plt.xlabel('n_estimators')
plt.ylabel('acc')
plt.show()
print(cross.index(max(cross))+1,max(cross))
#调整max_depth
param_grid = {'max_depth' : np.arange(1,20,1)}
#一般根据数据大小进行尝试,像该数据集 可从1-10 或1-20开始
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整max_features
param_grid = {'max_features' : np.arange(5,30,1)}
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整min_samples_leaf
param_grid = {'min_samples_leaf' : np.arange(1,1+10,1)}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整min_samples_split
param_grid = {'min_samples_split' : np.arange(2,2+20,1)}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
#调整criterion
param_grid = {'criterion' :['gini','entropy']}
#一般是从其最小值开始向上增加10或者20
# 面对高维度高样本数据,如果不放心,也可以直接+50,对于大型数据可能需要增加200-300
# 如果调整的时候发现准确率怎么都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rf = RandomForestClassifier(n_estimators=11,random_state=42)
GS = GridSearchCV(rf,param_grid,cv=5)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_希望大家有所收获,欢迎留言~
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源