作者:YAN左使
本文基于openGauss在VLDB2021上最新发表的论文《openGauss: An Autonomous Database System》,从学术的角度来探究openGauss如何基于各种AI技术构建一个智能的自治数据库系统。论文作者是清华大学李国良教授,他同时也是openGauss的总架构师。本文主要是对论文的阅读笔记和个人见解,如有错误,欢迎各位指正!
虽然近年来基于学习的数据库优化技术在学术界得到了广泛的研究,但很多技术还没有被广泛部署到商业数据库系统中。这篇论文的作者探讨如何将基于AI的数据库技术整合到openGauss中,从而构建一个自治数据库系统架构。这些基于AI的数据库技术主要包括四个方面:
要将基于AI的数据库技术整合到openGauss的架构中,构建基于学习的端到端数据库系统存在以下挑战:
为了应对这些挑战,论文构建了一个自治的数据库框架,并将其集成到openGauss中,主要包含5个组件,包括Learned Optimizers、Learned Database Advisors、Model Validation 、Model Management和Training Data Management,如下图所示。
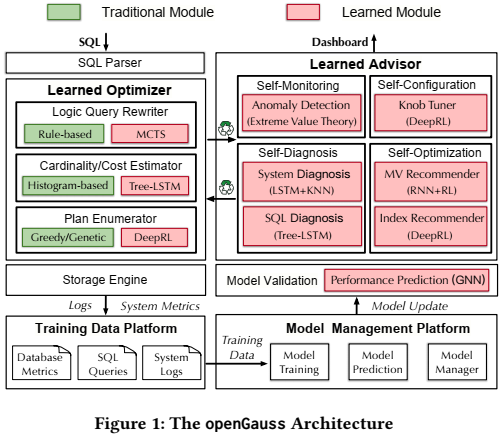
优化器是数据库最核心的组件之一,负责解析SQL语句生成高效的执行计划给执行引擎执行。基于学习的优化器主要包括三个重要的组件:基于MCTS的查询重写,基于Tree-LSTM的代价和基数估计器,以及基于DRL的查询计划生成器。
查询重写的目的是将一个速度较慢的SQL查询转换为具有更高性能的等价查询,这是查询优化中的一个基本问题。如果以适当的方式重写(例如,删除冗余操作符,交换两个操作符),缓慢的SQL查询(由于冗余或低效的操作)的性能可以提高几个数量级。
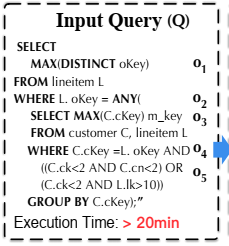
论文中给了一个例子,如下图所示。通过消除冗余聚合MAX(c_custkey)并且将ANY操作符里的子查询pull up到最外层的WHRER子句中,可以将查询Q重写为等效的查询Q’,查询重写后可以实现超过600倍的查询加速(查询执行时间从20多分钟降为1.941秒)。

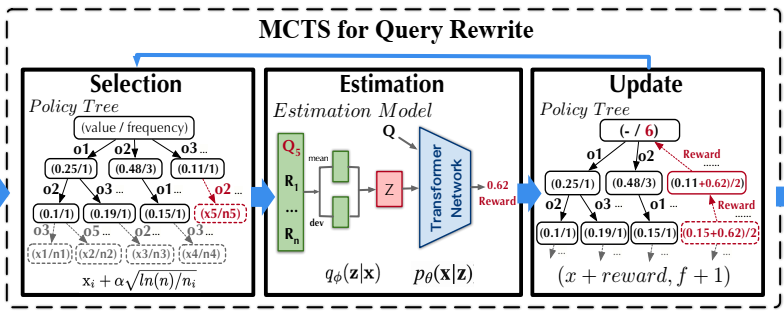
为了解决这个问题,论文采用蒙特卡洛树搜索(MCTS)来搜索最优的等价查询。整个查询重写模块由三部分组成,如上图所示。
更多具体的细节,可以参考论文《A Learned Query Rewrite System using Monte Carlo Tree Search》。
传统的基数估计方法存在很大的误差,特别是当涉及多个列的时候,这是因为传统方法很难捕捉不同列之间的相关性。例如,基于直方图的方法只捕获单个列的分布;对于高维数据,基于采样的方法存在0元组问题。基数估计的误差会传递到代价估计中,因为代价模型除了和代价因子有关以外还受到基数估计的影响,比如PsotgreSQL中的代价模型是基数估计值和各种代价常数因子的线性组合,如下所示:
cost = Cs * Ns + Cr * Nr + Ct * Nt + Ci * Ni + Co * No
其中Cs,Cr,Ct,Ci,Co表示各种操作的代价因子,而Ns,Nr,Nt,Ni,No则表示相应的基数值大小。
这些代价因子都是常数值,比如Cs=1.0,Cr=4.0,暗含的意思是随机读取一个page的IO代价是顺序读取的4倍。注意:PostgreSQL的官方文档建议不要随意修改这些常数的代价因子。

所以,从上面的例子可以看出,一个查询计划的代价的估计是由两个因素共同决定的:基数估计值和相应的常数代价因子。相比代价因子,基数估计值对于代价估计的影响更大,基数估计错误可能会导致生成的查询计划不是最优的(因为更优的查询计划可能被错误的估计了一个更大的代价值而被舍弃了)。
为了解决上面的这些问题,论文采用了一种树状结构的LSTM模型来同时估计查询的基数和代价。同时估计出基数和代价是这个模型最大的创新点,因为很多其他的基于AI的论文都只能估计基数或者代价。
论文采用的Tree-LSTM模型主要包括3个layer:embedding layer, representation layer和estimation layer,如下图所示。
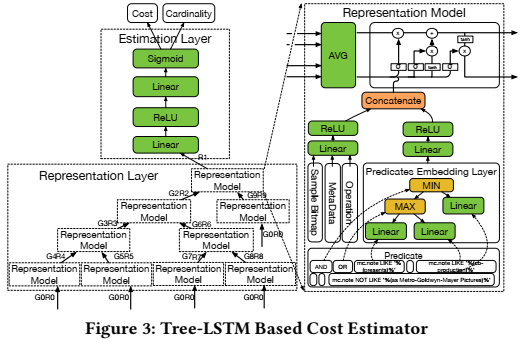
更多具体的细节,可以参考论文《An End-to-End Learning-based Cost Estimator》。
查询计划生成中最重要的是join oder和physical operation的选择。传统的方法是在代价估计模型的基础上,通过搜索解空间来寻找合适的查询计划方案,比如动态规划和启发式算法。动态规划通过枚举解空间来找到最佳的查询计划,但其时间复杂度为指数级。启发式方法通过剪枝解空间的方式来加快搜索速度,但由于剪枝操作通常很难找到最优的查询计划。
将查询计划的生成过程建模为马尔可夫决策过程(MDP)后,就可以应用深度强化学习(DRL)来生成查询计划。但是,很多DRL方法采用固定长度来表示join tree,如果shcema有更新或者查询中存在表别名,这些方法就会失效。为了解决这些问题,论文提出了一种基于学习的查询计划枚举器,可以生成执行时间最短的查询计划,而且可以handle schema update。使用的深度强化学习模型是一个DQN+Tree-LSTM,如下图所示。
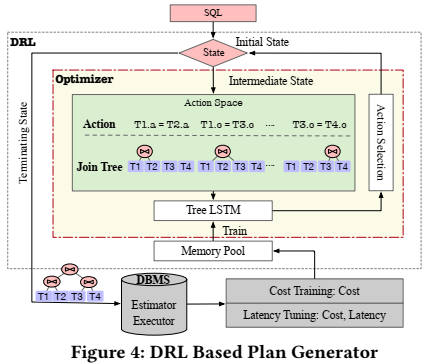
其工作流程如下:
更多具体的细节,可以参考论文《Reinforcement Learning with Tree-LSTM for Join Order Selection》。
在数据库的运行中检测异常是非常重要,如果不能及时检测出异常并采取措施,那么这些异常(比如slow SQL)可能会占用大量的系统资源,影响数据库的整体性能。靠人工来完成显然是非常困难的,因此需要一个自监控模块来实时监测数据库状态并主动发现异常。
通过检测数据库和操作系统的指标来检测异常,可以监视指标包括响应时间、CPU使用情况、内存使用情况、磁盘使用空间、缓存命中率等500多个metrics。如果这些指标存在异常则说明数据库出现了异常,这时自监控模块需要进一步找出root cause,才能采取相应的措施来修复异常。
由于要实时监控,所以监测数据形成了连续的时间序列数据(Time-Series Data)。传统的基于统计的异常检测算法是针对一维数据设计的,这些方法忽略了时间序列数据之间的相关性,无法获得较高的精度。基于深度学习的算法虽然能获取数据间的相关性,但需要对数据进行标记。
为了解决这些问题,论文采用一种基于重构的算法来检测异常,因为正常的时间序列数据总是表现出有规律的patterns,如果出现了异常模式patterns,则有很大的概率是数据库出现了异常。论文采用的是一个LSTM-based auto-encoder with an attention layer(包含一个注意力层的基于LSTM的自动编码器),如下图所示。
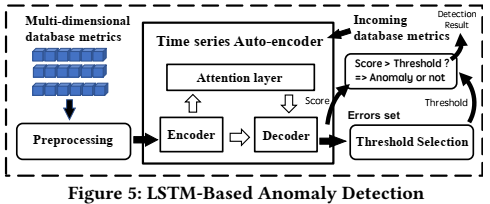
原始的多维时间序列数据通过预处理后会被Encoder编码成low-dimensiaonal representation,然后Decoder会解析表示并试图恢复原始的时间序列数据。如果能正确地重构出原始数据则说明没有异常,反之如果无法重构原始数据(重构误差超过一定地阈值),则说明数据库出现了异常。
如何确定一个合理的阈值是非常关键的,因为如果阈值太低则可能会经常报异常(类似于雷达检测中的虚警,即本来没有目标却认为有目标),阈值太高则可能漏检很多异常。因此论文采用了一种称为Extreme Value Theory的统计学方法来确定动态阈值。当用户指定系统灵敏度(1%或5%)后,系统会根据历史数据计算出相应的阈值。
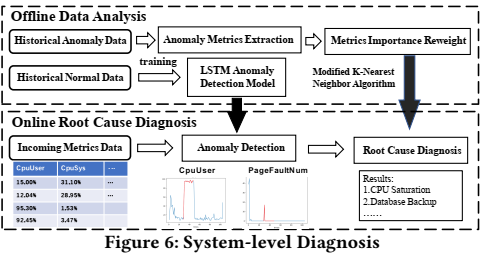
Root-cause diagnosis对于自治数据库来说是至关重要的,需要同时考虑系统级诊断和SQL级诊断。前者分析系统异常的根本原因,比如IO争用、网络拥塞、磁盘空间不足等;后者分析慢SQL的根本原因,比如锁冲突或者缺少索引。
在系统级诊断框架中,将诊断视为一个classification problem,并通过使用metric data中的特征来查找root cause。这个诊断模型是轻量级的,不会对数据库性能产生影响。通过对历史数据的分析,可以对诊断模型进行优化,这样只需对少数异常cases进行标注即可。系统级自诊断框架由offline和online两个部分组成,如下图所示。
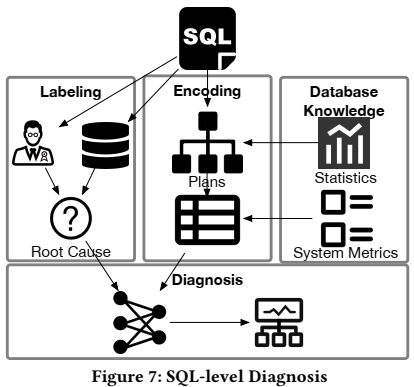
SQL级诊断的目的是在没有实际运行SQL的情况下找到SQL语句中特别耗时的operator。
SQL级的诊断存在以下挑战:
下图显示了SQL级的诊断框架,其工作流程包含两个阶段:
数据库一般都有数百个tunable knobs(例如,openGauss中有超过400个knobs),DBA需要为这些knobs设置适当的值来保证数据库的性能,比如内存管理、日志记录、并发控制。然而,手动调节knobs非常耗时,其他自动调节方法(如启发式采样或机器学习方法)不能有效地调节knobs。例如,有些ML方法在小数据集上训练,如果想要迁移到大数据集则需要重新训练。
为了解决这些问题,论文提出了一个混合调优模块如下图所示,该模块由四个部分组成:

什么是物化视图(Materialized Views)?
物化视图的创建通常由DBA来完成,但是即使是有经验的DBA也不能完成具有数百万实例和数百万用户的云数据库的视图推荐工作。关于MV推荐的研究有两个挑战:
为了应对这些挑战,论文采用基于学习的MV推荐方法,如下图所示:
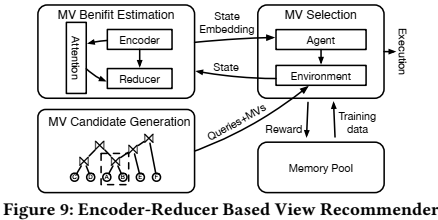
该方法主要包括三个部分:
索引对于数据库系统实现高性能至关重要,使用合适的索引可以显著加快查询的执行速度。然而,索引推荐是一个复杂而具有挑战性的问题:
为了解决这些问题,论文提出了一种基于学习的索引推荐方法,如下图所示。
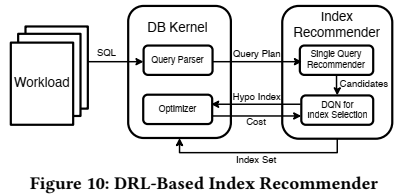
该方法主要分为三个步骤:
文中提到的这些论文解决的其实都是如何利用AI去改进甚至替代传统数据库的组件和模型,比如优化器中的查询重写和代价估计模型,然后作者想将这些都用于openGauss中构建一个自治数据库,我个人有以下几点思考:
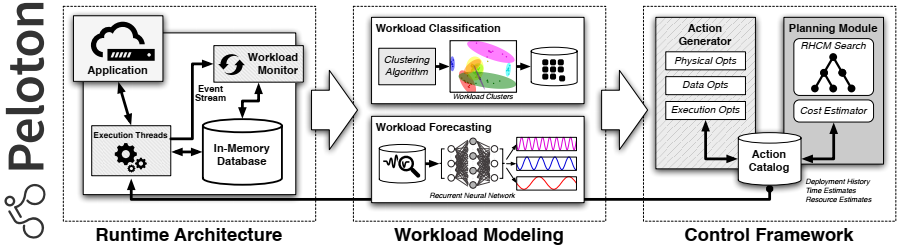
Peloton系统框架图
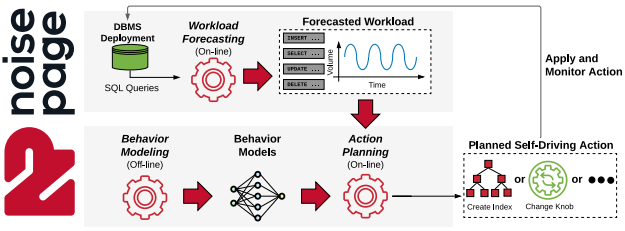
NoisePage系统框架图
参考文献:
[1] Li, G., Zhou, X., Sun, J., Yu, X., Han, Y., Jin, L., … & Li, S. (2021). openGauss: An Autonomous Database System. Proceedings of the VLDB Endowment, 14(12), 3028-3042.
[2] Zhou, X., Jin, L., Sun, J., Zhao, X., Yu, X., Feng, J., … & Liu, L. (2021). DBMind: A Self-Driving Platform in openGauss. Proceedings of the VLDB Endowment, 14(12), 2743-2746.
[3] Pavlo, A., Angulo, G., Arulraj, J., Lin, H., Lin, J., Ma, L., … & Zhang, T. (2017). Self-Driving Database Management Systems. In CIDR.
[4] Pavlo, A., Butrovich, M., Ma, L., Menon, P., Lim, W. S., Van Aken, D., & Zhang, W. (2021). Make Your Database System Dream of Electric Sheep: Towards Self-Driving Operation. Proceedings of the VLDB Endowment, 14(12), 3211-3221.
[5] Zhou, X., Li, G., Chai, C., & Feng, J. A Learned Query Rewrite System using Monte Carlo Tree Search.
[6] Sun, J., & Li, G. (2019) An End-to-End Learning-Based Cost Estimator. Proceedings of the VLDB Endowment, 13(3), 307–319.
[7] Yu, X., Li, G., Chai, C., & Tang, N. (2020, April). Reinforcement Learning with Tree-LSTM for Join Order Selection. In 2020 IEEE 36th International Conference on Data Engineering (ICDE) (pp. 1297-1308). IEEE.
[8] Zhou, X., Sun, J., Li, G., & Feng, J. (2020). Query Performance Prediction for Concurrent Queries using Graph Embedding. Proceedings of the VLDB Endowment, 13(9), 1416-1428.
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
我正在使用Watir进行自动化,它会创建一封我需要检查的电子邮件。有人指出电子邮件gem是执行此操作的最简单方法。我添加了以下代码,并且能够从我的收件箱中收到第一封电子邮件。require'mail'require'openssl'Mail.defaultsdoretriever_method:pop3,:address=>"email.someemail.com",:port=>995,:user_name=>'domain/username',:password=>'pwd',:enable_ssl=>trueendputsMail.first我是这个论坛的新手,有以下问题:如何获
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat
注意http://techcrunch.com/2010/04/04/he-even-makes-coldplay-sound-fun/顶部的那些按钮在社交网络上分享网址?我想为我正在构建的网站做一些非常相似的事情。ShareThis提供了一个可以做同样事情的小部件,但它是品牌化的和外部的。我正在寻找纯Ruby解决方案。包含可包含在RailsApplicationHelper类中的模块的gem将是完美的。在我重新发明轮子之前,感谢您的建议!想象一下: 最佳答案 我能找到的最好的是:http://www.addthis.com/这里有