
? 作者:韩信子@ShowMeAI
? Python3◉技能提升系列:https://www.showmeai.tech/tutorials/56
? 数据分析实战系列:https://www.showmeai.tech/tutorials/40
? 本文地址:https://www.showmeai.tech/article-detail/336
? 声明:版权所有,转载请联系平台与作者并注明出处
? 收藏ShowMeAI查看更多精彩内容

异常值是距离其他数据值太远的数据点,也被称为离群点。它可能是自然发生的,也可能是由于测量不准确、拼写错误或系统故障造成的。异常值也可能出现在倾斜数据中,这些类型的异常值被认为是自然异常值。

了解异常值检测与分析的基础知识,请查看 ShowMeAI](https://www.showmeai.tech/) 这篇文章:
异常值会影响数据的均值、标准差和四分位数值。如果我们在去除异常值之前和之后计算这些统计数据,可能会有比较大的差异。
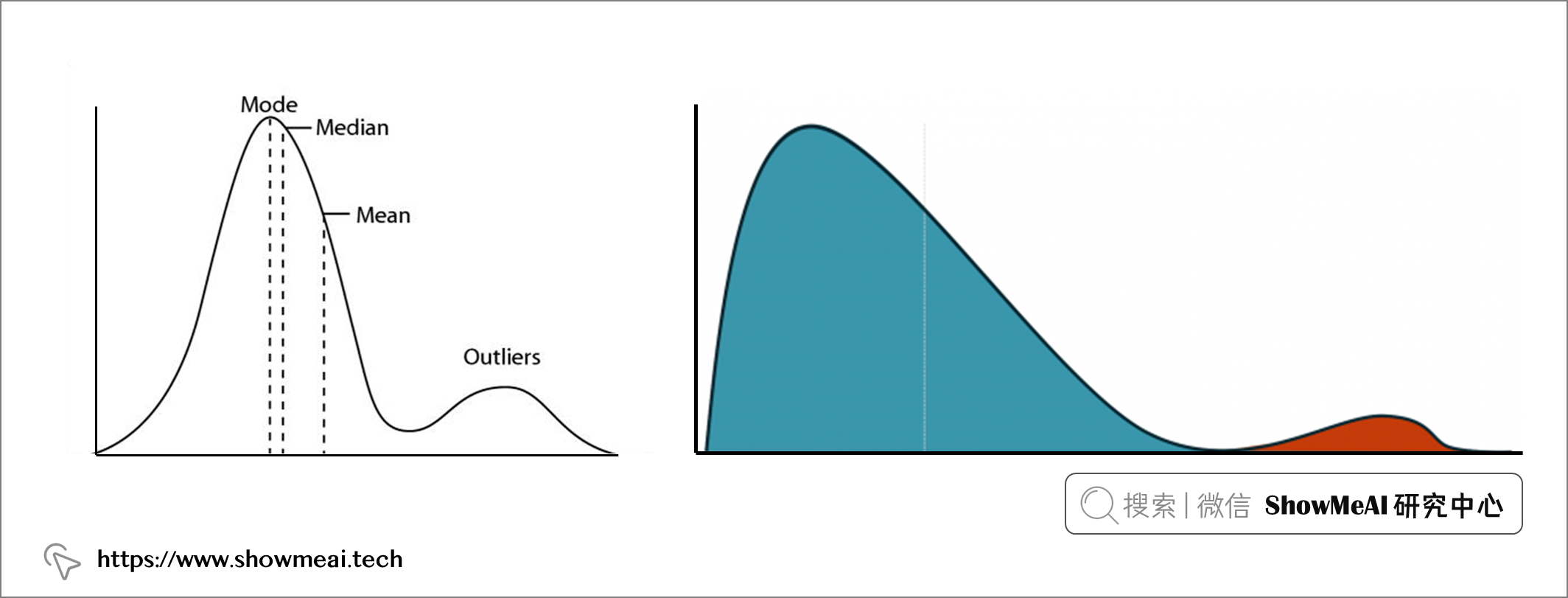
去除异常值会带来数据集规模的减小,而且模型的适用性也会限制在输入值的度量范围内,丢弃自然异常值也可能导致模型不准确。
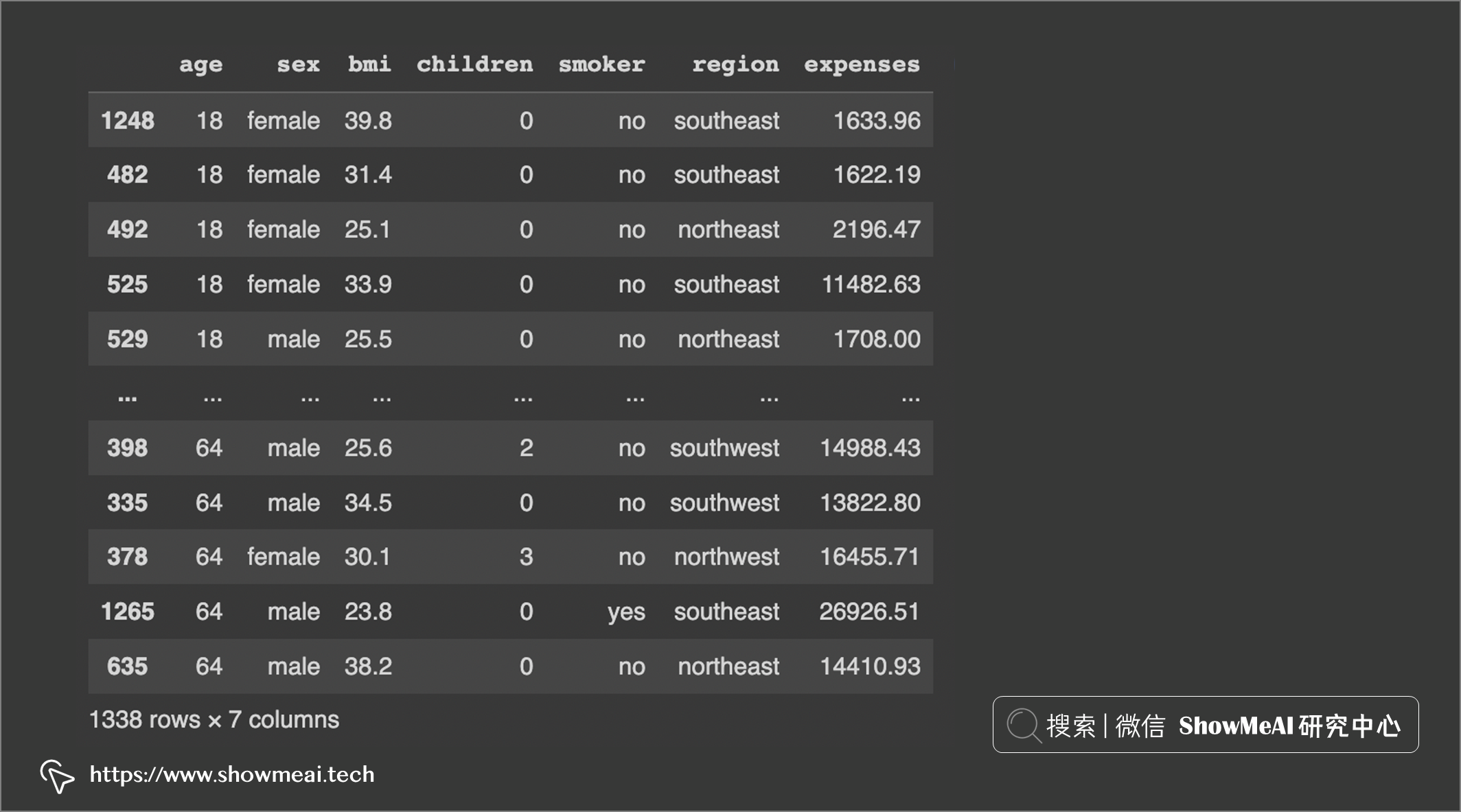
异常值不容易被『肉眼』检测到,但我们有一些可视化工具可以帮助完成这项任务。最常见的是箱线图和直方图。我们这里用 ?保险数据来做一个讲解:
? 实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [29]基于统计方法的异常值检测代码实战 『insurance数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
我们首先导入必要的库并加载数据集。
import numpy as np
import pandas as pd
import seaborn as sns
import statistics#Load dataset:
df = pd.read_csv('insurance.csv')
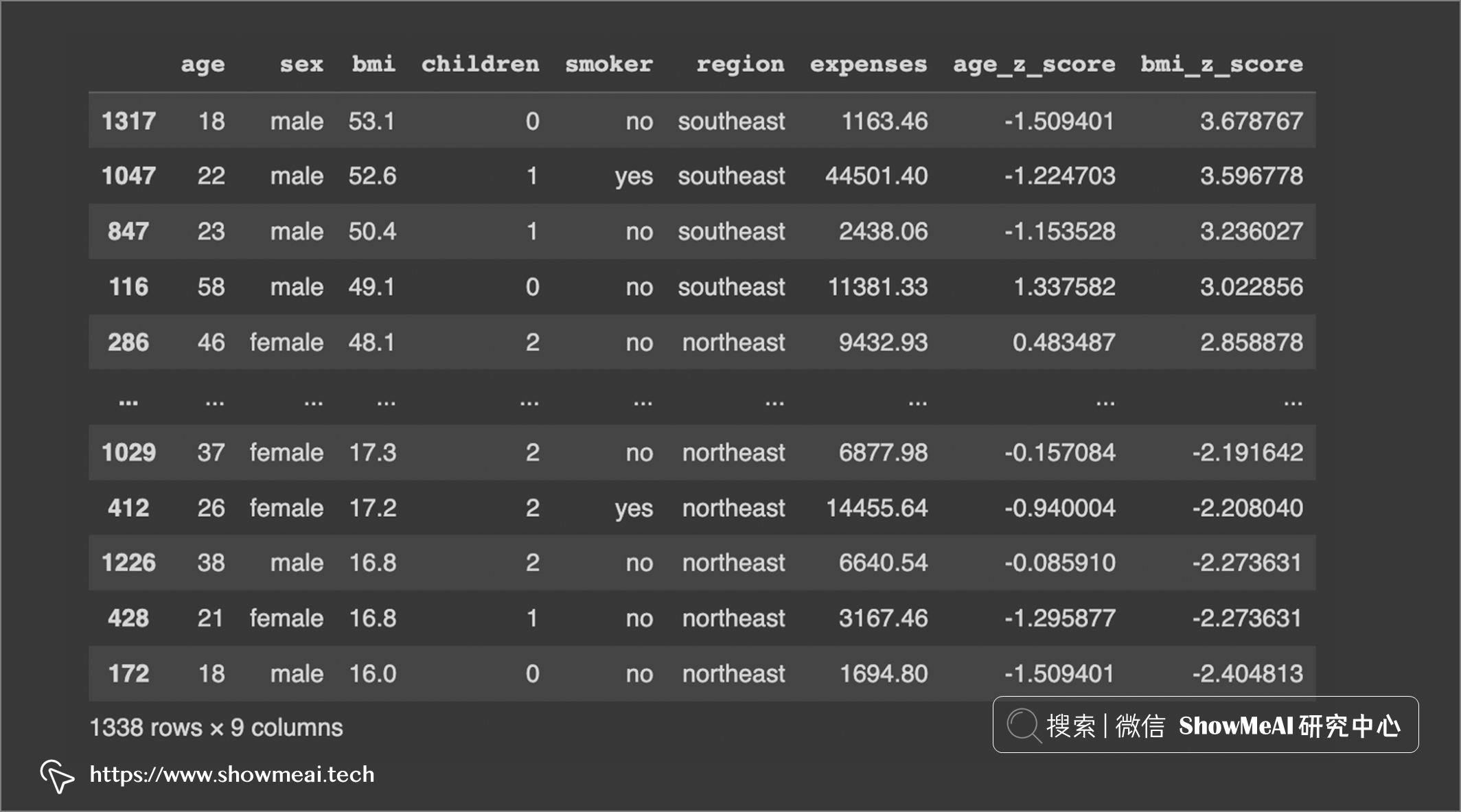
df
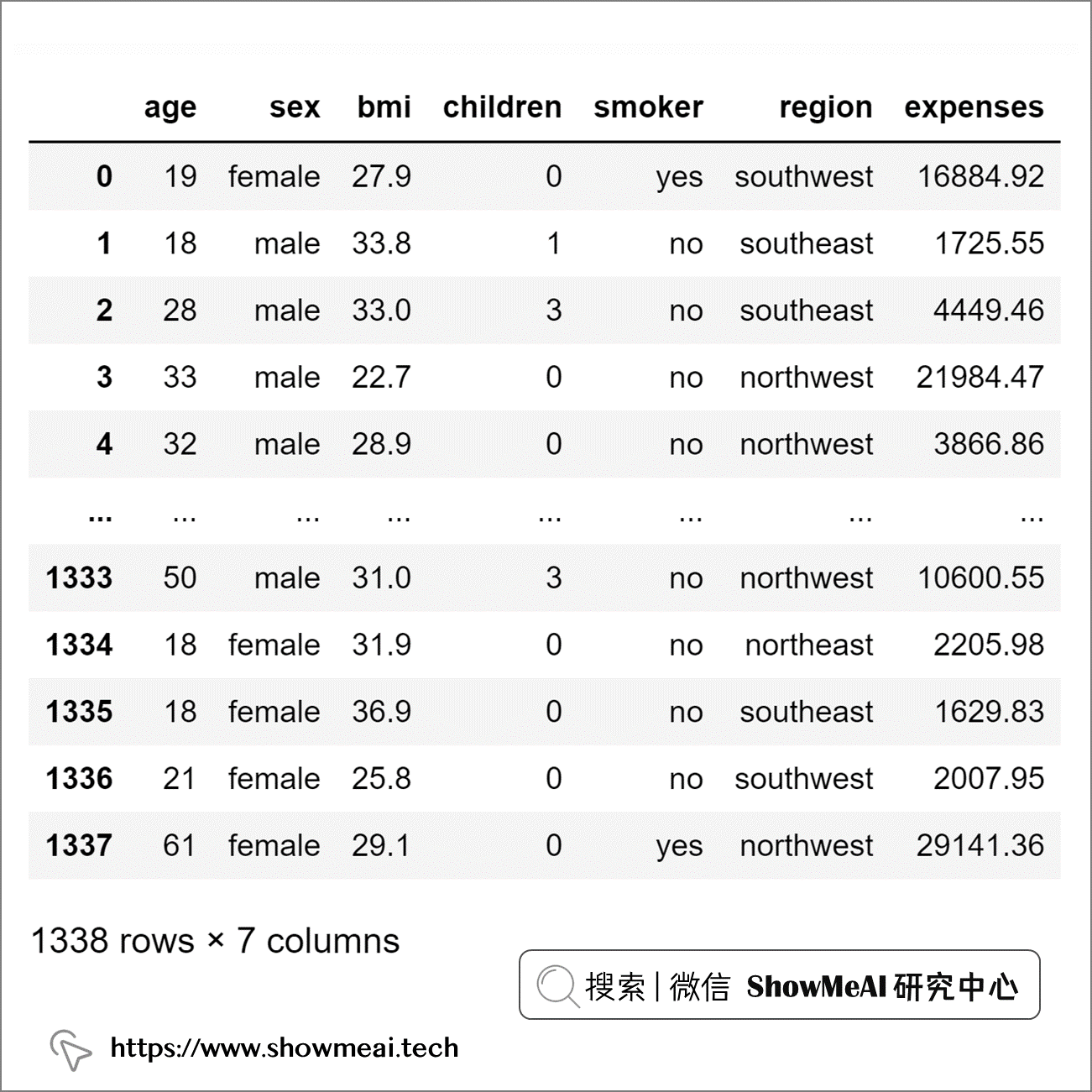
我们对变量『年龄』、『体重指数』和『费用』进行异常值检测分析。
第一种方法是使用箱线图 / Box-Plots 来绘制数据分布:
# age, bmi 和 expenses的箱线图绘图
sns.boxplot(y="age", data=df)
sns.boxplot(y="bmi", data=df)
sns.boxplot(y="expenses", data=df)
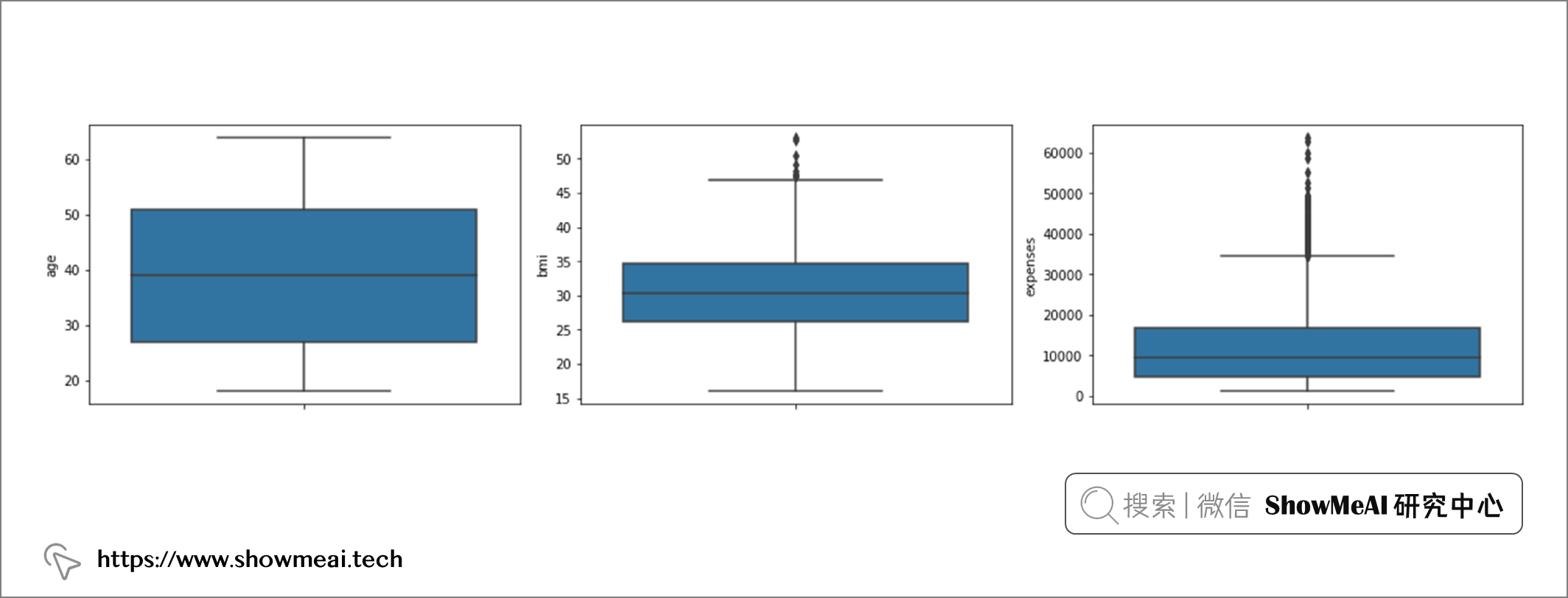
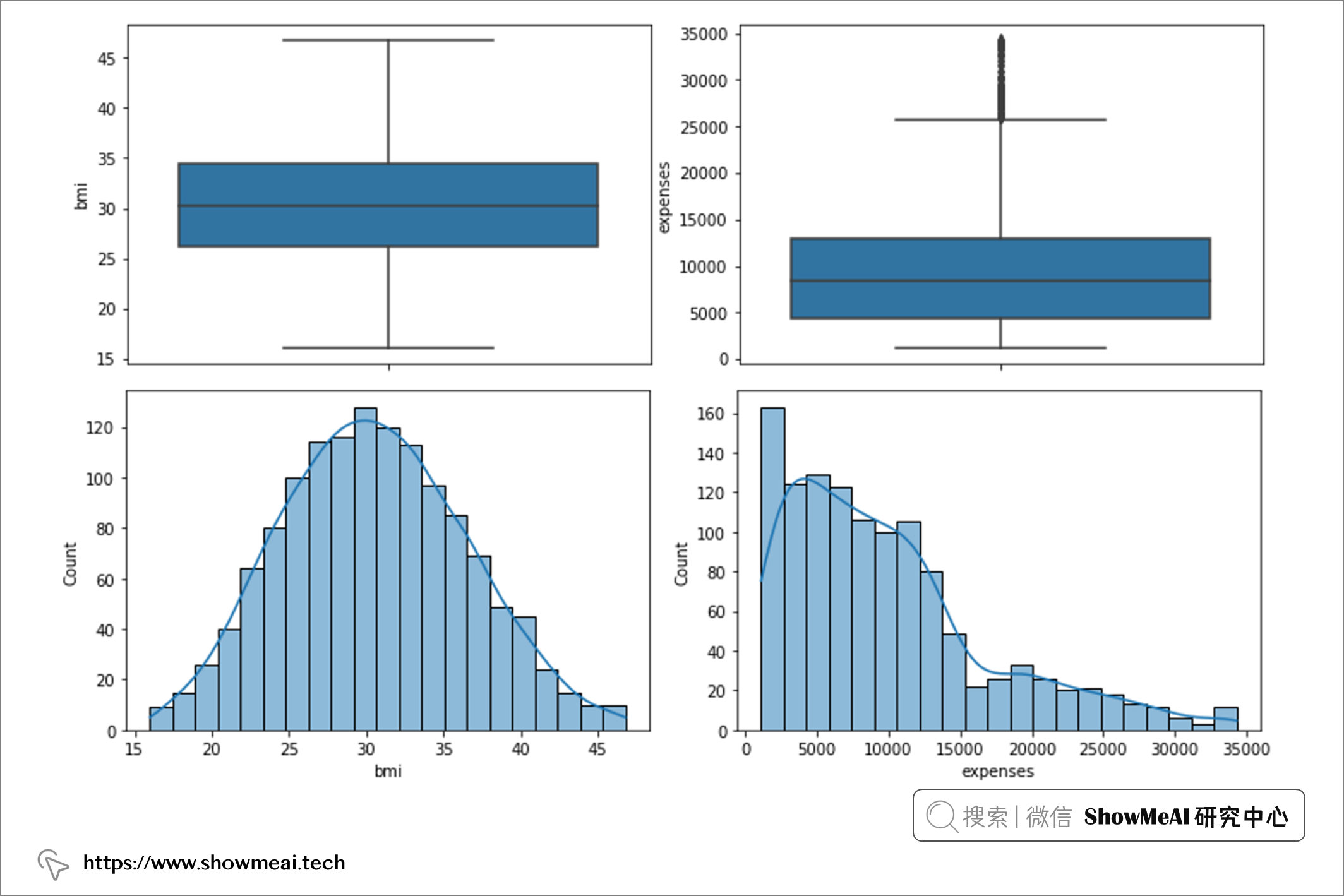
通过查看箱线图,我们可以看到变量 age 没有异常值,变量 bmi 在上限中有一些异常值,而变量 expense 在上限中有一系列异常值(表明存在偏态分布)。
为了检查偏态分布,我们再使用直方图绘图:
# age, bmi 和 expenses的直方图
sns.histplot(df, x="age", kde=True)
sns.histplot(df, x="bmi", kde=True)
sns.histplot(df, x="expenses", kde=True)
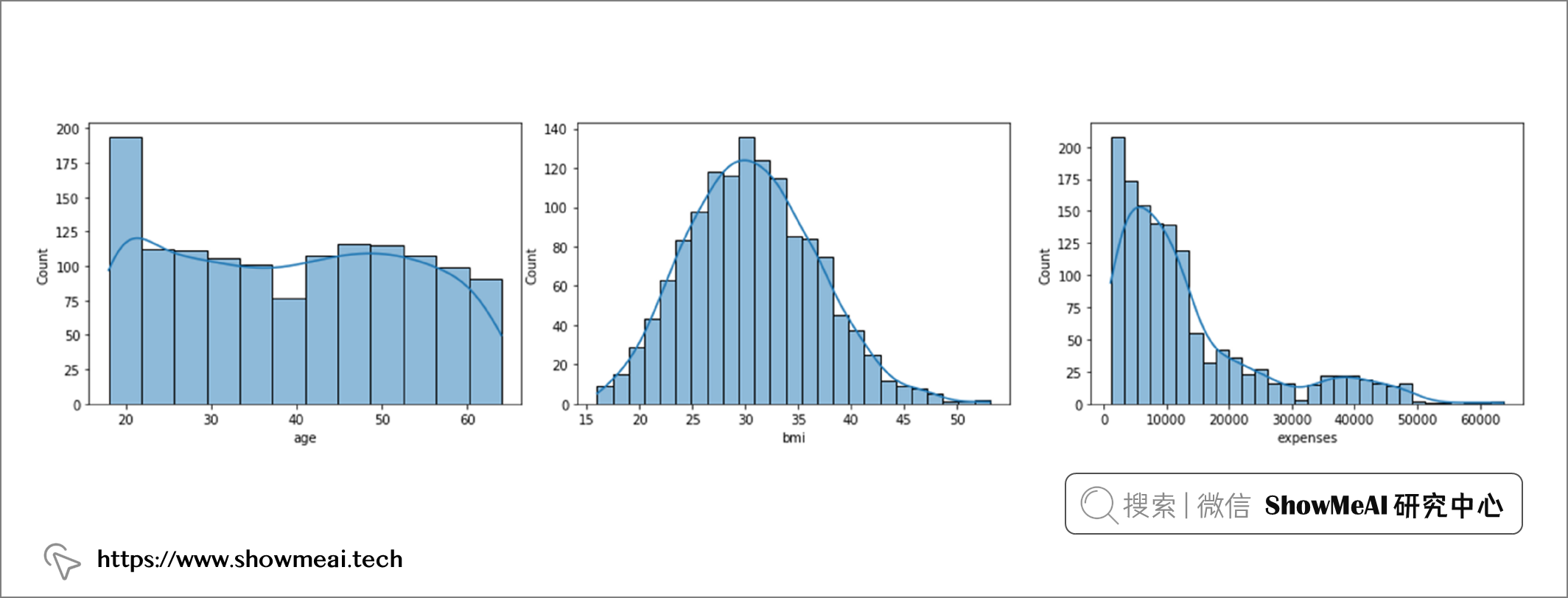
通过直方图,我们可以看到变量『age』是近似均匀分布,『bmi』接近正态分布,而『expense/费用』则呈偏态分布。
对于年龄,我们无需做异常值剔除;对于 bmi,我们将剔除高于 47 的值;对于费用,我们将剔除高于 50000 的值。
#bmi 和 expenses 的异常值处理
df.drop(df[df['bmi'] >= 47].index, inplace = True)
df.drop(df[df['expenses'] >= 50000].index, inplace = True)
现在,如果我们再次检查箱线图和直方图:
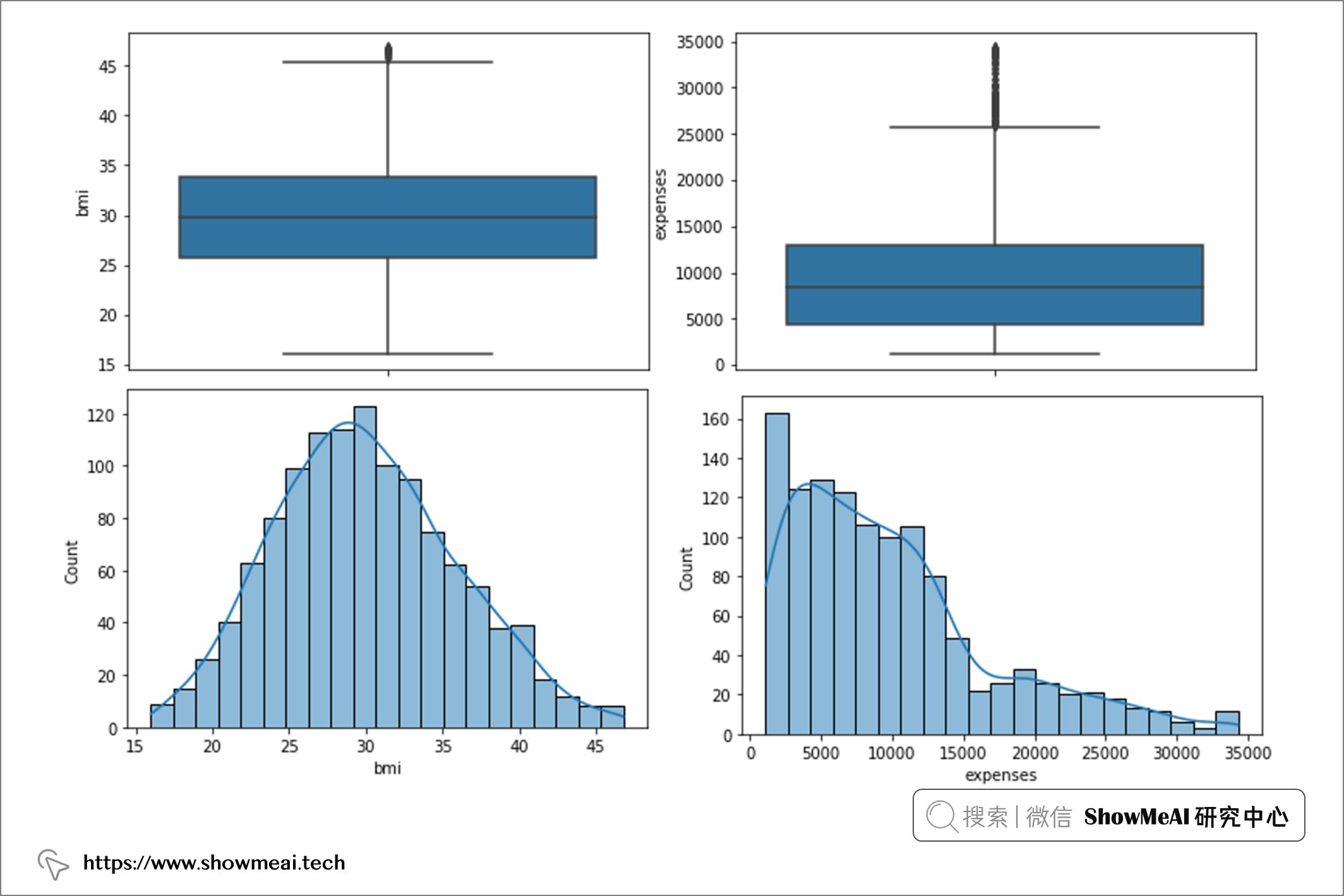
检测异常值有两种主要的统计方法:使用 z 分数和使用四分位距。
Z 分数是一种数学变换,它根据每个观测值与平均值的距离对其进行分类。z-score 的计算公示为:

我们定义异常检测标准:如果 z-score 小于 -3或 z-score 大于 3。
我们将重新加载数据集,因为我们在前面的示例中对其进行了更改,加载后的数据上我们会把变量转换为 z 分数:
# 重新加载数据
df = pd.read_csv('insurance.csv')
# 为age计算均值和标准差
mean_age = statistics.mean(df['age'])
stdev_age = statistics.stdev(df['age'])
# 计算z值
age_z_score = (df['age']-mean_age)/stdev_age
# 添加z结果到原dataframe
df['age_z_score'] = age_z_score.tolist()
现在我们将检查高于 3SD 或低于 -3SD 的值:
# 检测小于-3SD的值:
df.sort_values(by=['age_z_score'], ascending=True)
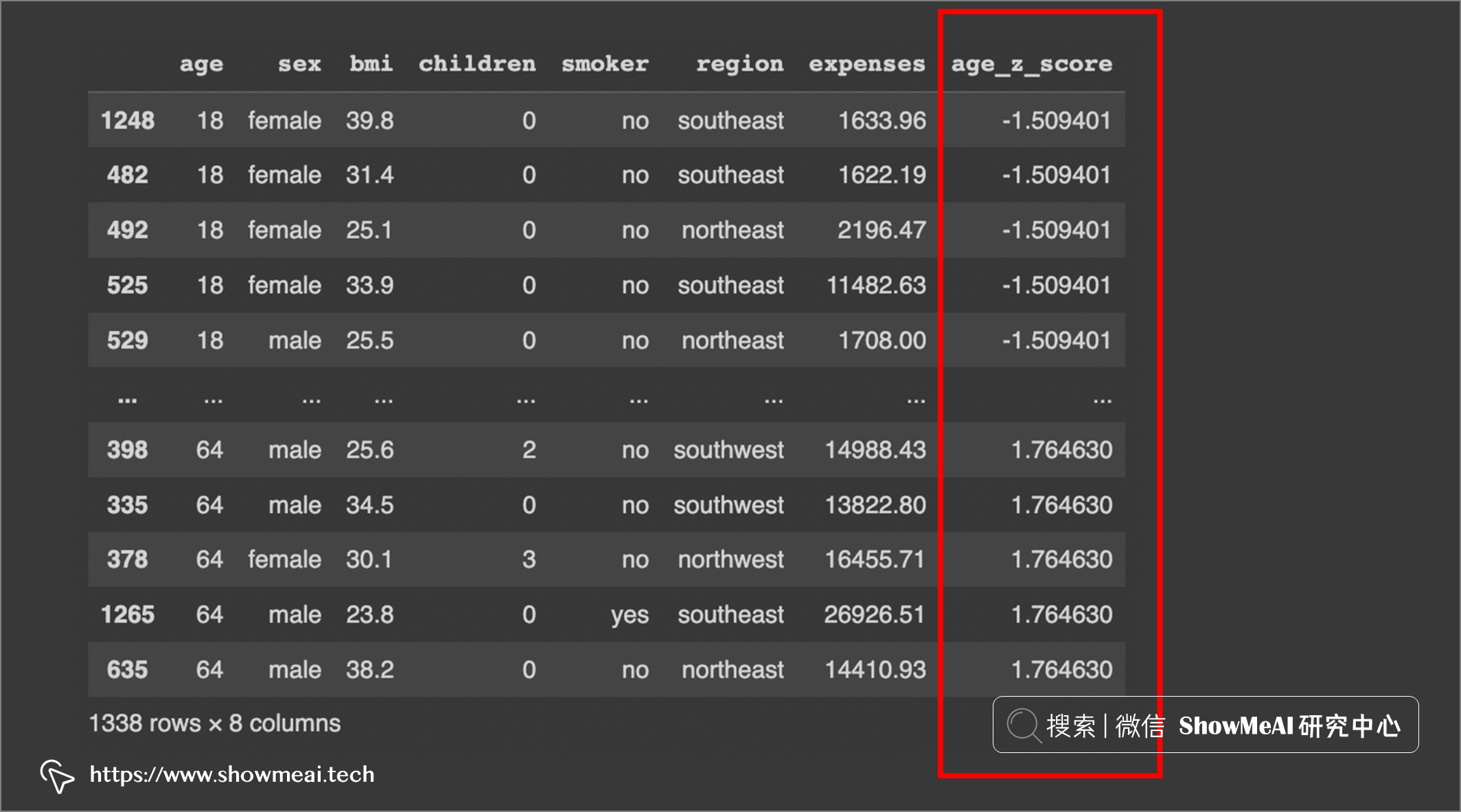
我们可以看到 -3SD 以下没有值。我们现在将检查 3SD 以上的值:
# 检测+3SD以上的值:
df.sort_values(by=['age_z_score'], ascending=False)
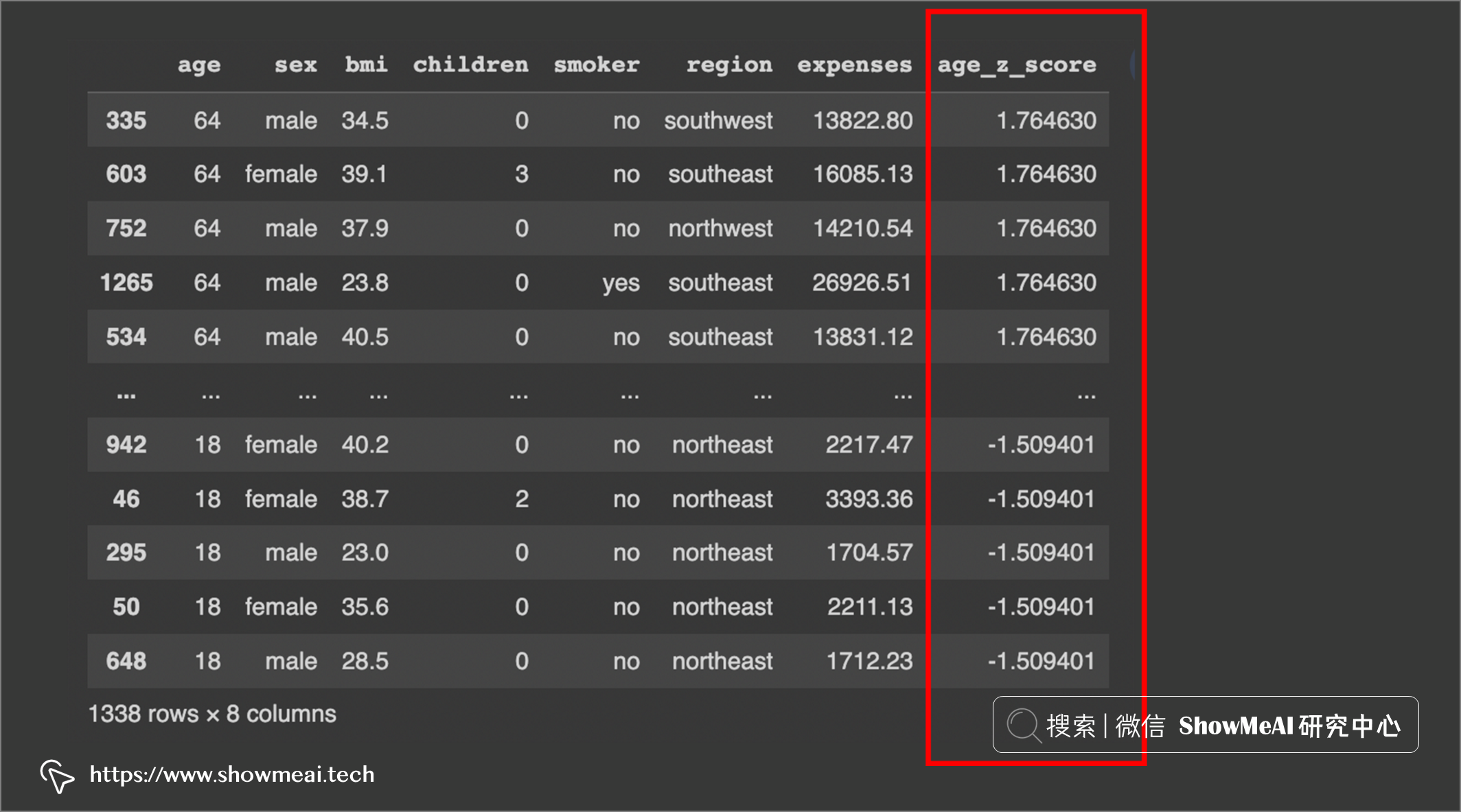
我们可以看到没有高于 3SD 的值。变量年龄没有异常值。
现在我们将对变量 bmi 执行相同的操作:
# 为bmi计算均值和标准差
mean_bmi = statistics.mean(df['bmi'])
stdev_bmi = statistics.stdev(df['bmi'])
# 为bmi计算z-score
bmi_z_score = (df['bmi']-mean_bmi)/stdev_bmi
# 添加到原始dataframe
df['bmi_z_score'] = bmi_z_score.tolist()
# 检查低于-3SD的值
df.sort_values(by=['bmi_z_score'], ascending=True)
# 检查大于3SD的值
df.sort_values(by=['bmi_z_score'], ascending=False)
这次我们会发现一些高于 3SD 的值:
我们对它进行剔除:
# 异常值处理
df.drop(df[df[‘bmi_z_score’] >= 3].index, inplace = True)
我们将对『expense/费用』应用相同的技术:
# 为expenses计算均值和标准差
mean_expenses = statistics.mean(df['expenses'])
stdev_expenses = statistics.stdev(df['expenses'])
# 计算z-score
expenses_z_score = (df['expenses']-mean_expenses)/stdev_expenses
# 添加到原始dataframe
df['expenses_z_score'] = expenses_z_score.tolist()
# 检查低于-3SD的值
df.sort_values(by=['expenses_z_score'], ascending=True)
# 检查高于3SD的值
df.sort_values(by=['expenses_z_score'], ascending=False)
# 异常值处理
df.drop(df[df[‘expenses_z_score’] >= 3].index, inplace = True)
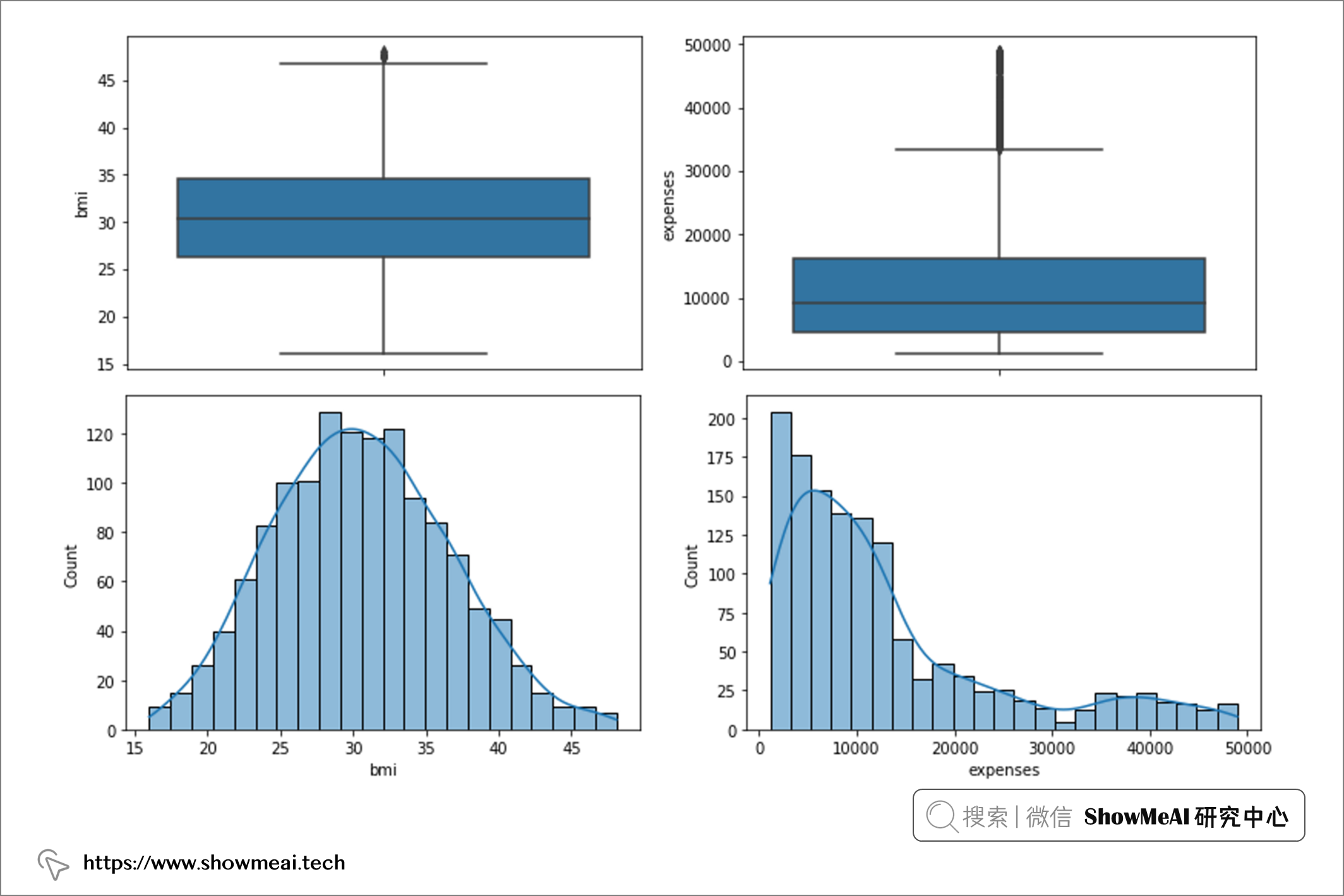
如果我们再次检查箱线图和直方图,我们将获得:
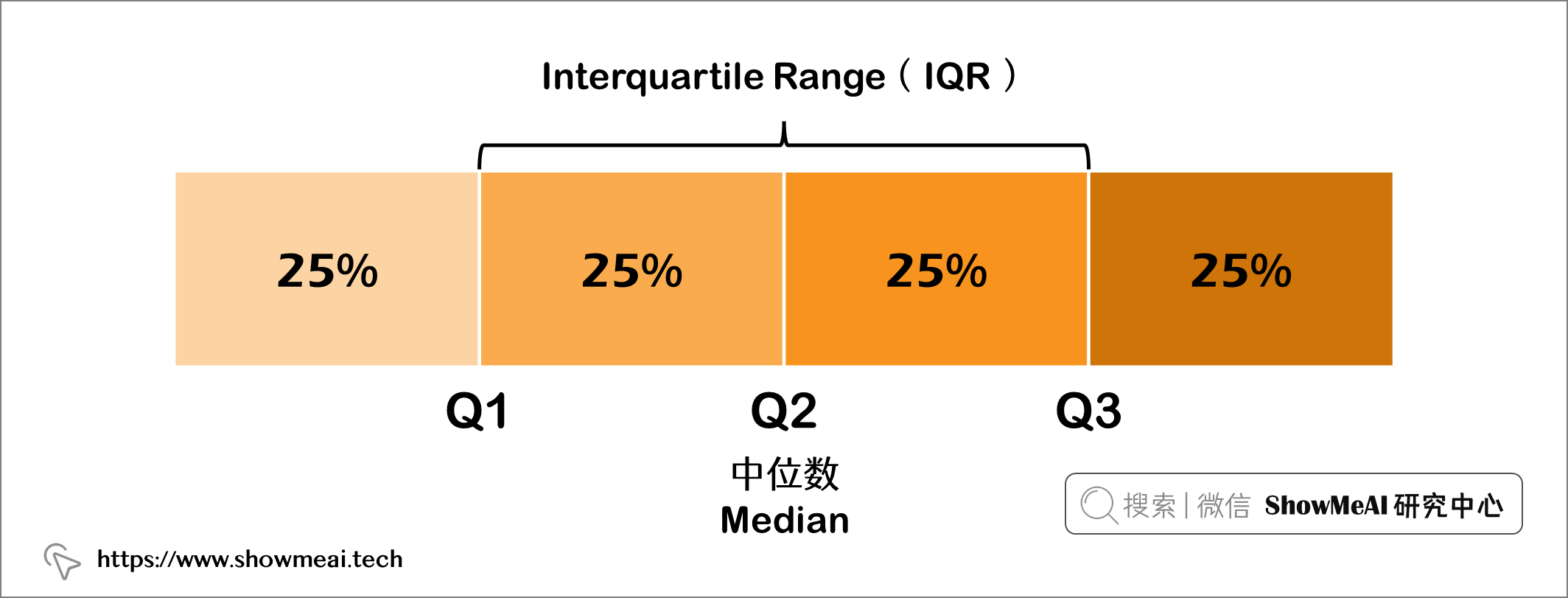
四分位间距将数据分为四个部分,从低到高排序,如下图所示,每个部分包含相同数量的样本。第一个四分位数(Q1)是边界中数据点的值。这同样适用于 Q2 和 Q3。 四分位距(IQR)是两个中间部分的数据点(代表 50% 的数据)。四分位距包含高于 Q1 和低于 Q3 的所有数据点。如果该点高于 Q3 + (1.5 x IQR),则存在较高的异常值,如果 Q1 - (1.5 x IQR),则存在较低的异常值。
代码实现如下:
# 重新加载数据
df = pd.read_csv('insurance.csv')
# 计算上下四分位数位置
q75_age, q25_age = np.percentile(df['age'], [75 ,25])
iqr_age = q75_age - q25_age
iqr_age
# 计算上下边界以用于异常检测
age_h_bound = q75_age+(1.5*iqr_age)
age_l_bound = q25_age-(1.5*iqr_age)
print(age_h_bound)
print(age_l_bound)
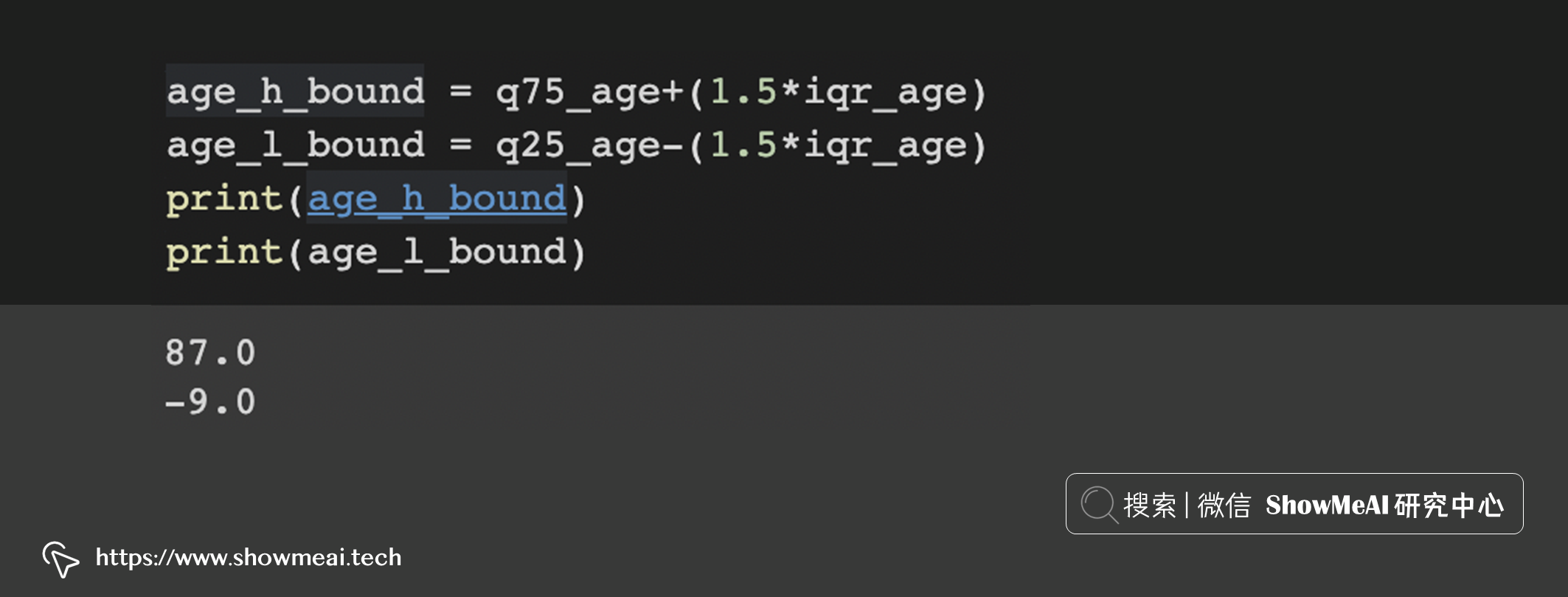
我们计算得到上边界 87 和下边界 -9:
# 排序
df.sort_values(by=['age'], ascending=True)
# 排序
df.sort_values(by=['age'], ascending=False)
我们看到没有异常值。
我们对变量 bmi 执行相同的操作:
# 计算上下四分位数位置
q75_bmi, q25_bmi = np.percentile(df['bmi'], [75 ,25])
iqr_bmi = q75_bmi - q25_bmi
iqr_bmi
# 计算上下边界以用于异常检测
bmi_h_bound = q75_bmi+(1.5*iqr_bmi)
bmi_l_bound = q25_bmi-(1.5*iqr_bmi)
print(bmi_h_bound)
print(bmi_l_bound)
# 排序
df.sort_values(by=['bmi'], ascending=True)
df.sort_values(by=['bmi'], ascending=False)
# 剔除异常值
df.drop(df[df['bmi'] >= 47.3].index, inplace = True)
df.drop(df[df['bmi'] <= 13.7].index, inplace = True)
我们只需要对可变费用做同样的事情,我们将获得以下箱线图和直方图:
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我想了解Ruby方法methods()是如何工作的。我尝试使用“ruby方法”在Google上搜索,但这不是我需要的。我也看过ruby-doc.org,但我没有找到这种方法。你能详细解释一下它是如何工作的或者给我一个链接吗?更新我用methods()方法做了实验,得到了这样的结果:'labrat'代码classFirstdeffirst_instance_mymethodenddefself.first_class_mymethodendendclassSecond使用类#returnsavailablemethodslistforclassandancestorsputsSeco
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer