AlexNet由Hinton和他的学生Alex Krizhevsky设计,模型名字来源于论文第一作者的姓名Alex。该模型以很大的优势获得了2012年ISLVRC竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+,自那年之后,深度学习开始迅速发展。
ImageNet是一个在2009年创建的图像数据集,从2010年开始到2017年举办了七届的ImageNet 挑战赛——ImageNet Large Scale Visual Recognition ChallengeI (LSVRC),在这个挑战赛上诞生了AlexNet、ZFNet、OverFeat、VGG、Inception、ResNet、WideResNet、FractalNet、DenseNet、ResNeXt、DPN、SENet 等经典模型。
Alexnet模型为8层深度网络,由5个卷积层和3个全连接层构成,不计LRN层和池化层。AlexNet 跟 LeNet 结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集 ImageNet。它是浅层神经网络和深度神经网络的分界线,如下图所示:
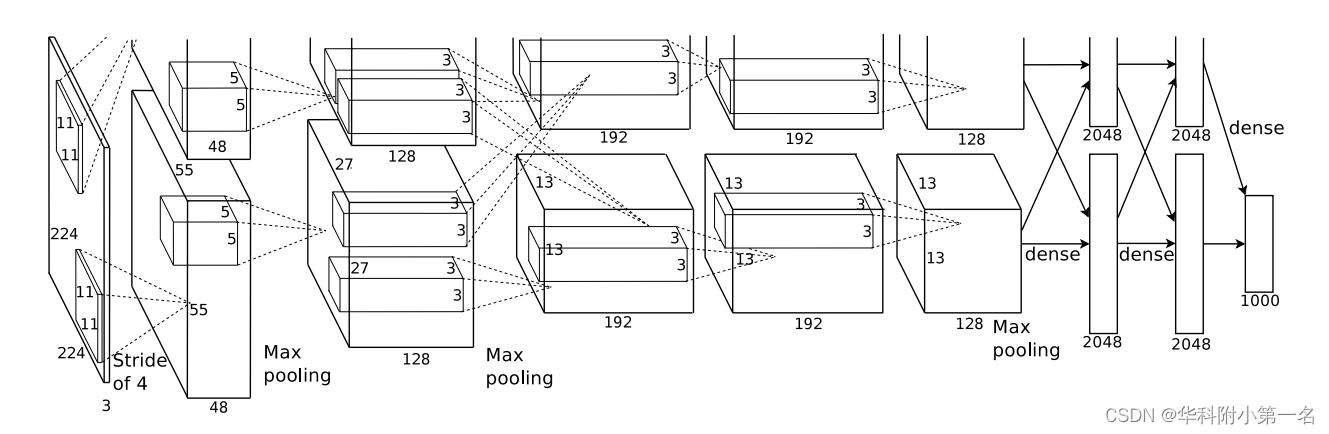
网络详解:AlexNet网络结构详解(含各层维度大小计算过程)与PyTorch实现
Dropout背后理念和集成模型很相似。在Drpout层,不同的神经元组合被关闭,这代表了一种不同的结构,所有这些不同的结构使用一个的子数据集并行地带权重训练,而权重总和为1。如果Dropout层有 n 个神经元,那么会形成 2n 个不同的子结构。在预测时,相当于集成这些模型并取均值。这种结构化的模型正则化技术有利于避免过拟合。Dropout有效的另外一个视点是:由于神经元是随机选择的,所以可以减少神经元之间的相互依赖,从而确保提取出相互独立的重要特征。
注意:代码实现没有还原两个小型GPU同时运算的设计特点,而是在一个模型中运行
# 导入pytorch库
import torch
# 导入torch.nn模块
from torch import nn
# nn.functional:(一般引入后改名为F)有各种功能组件的函数实现,如:F.conv2d
import torch.nn.functional as F
# 定义AlexNet网络模型
# MyLeNet5(子类)继承nn.Module(父类)
class MyAlexNet(nn.Module):
# 子类继承中重新定义Module类的__init__()和forward()函数
# init():进行初始化,申明模型中各层的定义
def __init__(self):
# super:引入父类的初始化方法给子类进行初始化
super(MyAlexNet, self).__init__()
# 卷积层,输入大小为224*224,输出大小为55*55,输入通道为3,输出为96,卷积核为11,步长为4
self.c1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2)
# 使用ReLU作为激活函数
self.ReLU = nn.ReLU()
# MaxPool2d:最大池化操作
# 最大池化层,输入大小为55*55,输出大小为27*27,输入通道为96,输出为96,池化核为3,步长为2
self.s1 = nn.MaxPool2d(kernel_size=3, stride=2)
# 卷积层,输入大小为27*27,输出大小为27*27,输入通道为96,输出为256,卷积核为5,扩充边缘为2,步长为1
self.c2 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
# 最大池化层,输入大小为27*27,输出大小为13*13,输入通道为256,输出为256,池化核为3,步长为2
self.s2 = nn.MaxPool2d(kernel_size=3, stride=2)
# 卷积层,输入大小为13*13,输出大小为13*13,输入通道为256,输出为384,卷积核为3,扩充边缘为1,步长为1
self.c3 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
# 卷积层,输入大小为13*13,输出大小为13*13,输入通道为384,输出为384,卷积核为3,扩充边缘为1,步长为1
self.c4 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
# 卷积层,输入大小为13*13,输出大小为13*13,输入通道为384,输出为256,卷积核为3,扩充边缘为1,步长为1
self.c5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
# 最大池化层,输入大小为13*13,输出大小为6*6,输入通道为256,输出为256,池化核为3,步长为2
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
# Flatten():将张量(多维数组)平坦化处理,神经网络中第0维表示的是batch_size,所以Flatten()默认从第二维开始平坦化
self.flatten = nn.Flatten()
# 全连接层
# Linear(in_features,out_features)
# in_features指的是[batch_size, size]中的size,即样本的大小
# out_features指的是[batch_size,output_size]中的output_size,样本输出的维度大小,也代表了该全连接层的神经元个数
self.f6 = nn.Linear(6*6*256, 4096)
self.f7 = nn.Linear(4096, 4096)
# 全连接层&softmax
self.f8 = nn.Linear(4096, 1000)
self.f9 = nn.Linear(1000, 2)
# forward():定义前向传播过程,描述了各层之间的连接关系
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s1(x)
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
# Dropout:随机地将输入中50%的神经元激活设为0,即去掉了一些神经节点,防止过拟合
# “失活的”神经元不再进行前向传播并且不参与反向传播,这个技术减少了复杂的神经元之间的相互影响
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
return x
# 每个python模块(python文件)都包含内置的变量 __name__,当该模块被直接执行的时候,__name__ 等于文件名(包含后缀 .py )
# 如果该模块 import 到其他模块中,则该模块的 __name__ 等于模块名称(不包含后缀.py)
# “__main__” 始终指当前执行模块的名称(包含后缀.py)
# if确保只有单独运行该模块时,此表达式才成立,才可以进入此判断语法,执行其中的测试代码,反之不行
if __name__ == '__main__':
# rand:返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数,此处为四维张量
x = torch.rand([1, 3, 224, 224])
# 模型实例化
model = MyAlexNet()
y = model(x)import torch
from torch import nn
from model import MyAlexNet
from torch.optim import lr_scheduler
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import os
import matplotlib.pyplot as plt
# 解决中文显示问题
# 运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['font.sans-serif'] = ['simHei']
# 运行配置参数总的轴(axes)正常显示正负号(minus)
plt.rcParams['axes.unicode_minus'] = False
ROOT_TRAIN = 'D:/pycharm/AlexNet/data/train'
ROOT_TEST = 'D:/pycharm/AlexNet/data/val'
# 将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# Compose():将多个transforms的操作整合在一起
train_transform = transforms.Compose([
# Resize():把给定的图像随机裁剪到指定尺寸
transforms.Resize((224, 224)),
# RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像
transforms.RandomVerticalFlip(),
# ToTensor():数据转化为Tensor格式
transforms.ToTensor(),
normalize])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize])
# 加载训练数据集
# ImageFolder:假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
# ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
# root:在root指定的路径下寻找图像,transform:对输入的图像进行的转换操作
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
# DataLoader:将读取的数据按照batch size大小封装给训练集
# dataset (Dataset):加载数据的数据集
# batch_size (int, optional):每个batch加载多少个样本(默认: 1)
# shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据(默认: False)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 加载训练数据集
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
# 如果有NVIDA显卡,可以转到GPU训练,否则用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 模型实例化,将模型转到device
model = MyAlexNet().to(device)
# 定义损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()
# 定义优化器(随机梯度下降法)
# params(iterable):要训练的参数,一般传入的是model.parameters()
# lr(float):learning_rate学习率,也就是步长
# momentum(float, 可选):动量因子(默认:0),矫正优化率
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 学习率每隔10轮变为原来的0.5
# StepLR:用于调整学习率,一般情况下会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果
# optimizer (Optimizer):更改学习率的优化器
# step_size(int):每训练step_size个epoch,更新一次参数
# gamma(float):更新lr的乘法因子
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
# dataloader: 传入数据(数据包括:训练数据和标签)
# enumerate():用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
# enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签)
# x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型)
for batch, (x, y) in enumerate(dataloader):
# 前向传播
image, y = x.to(device), y.to(device)
# 计算训练值
output = model(image)
# 计算观测值(label)与训练值的损失函数
cur_loss = loss_fn(output, y)
# torch.max(input, dim)函数
# input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出
# 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引
_, pred = torch.max(output, axis=1)
# 计算每批次的准确率
# output.shape[0]为该批次的多少,output的一维长度
# torch.sum()对输入的tensor数据的某一维度求和
cur_acc = torch.sum(y == pred)/output.shape[0]
# 反向传播
# 清空过往梯度
optimizer.zero_grad()
# 反向传播,计算当前梯度
cur_loss.backward()
# 根据梯度更新网络参数
optimizer.step()
# item():得到元素张量的元素值
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
train_loss = loss / n
train_acc = current / n
# 计算训练的错误率
print('train_loss==' + str(train_loss))
# 计算训练的准确率
print('train_acc' + str(train_acc))
return train_loss, train_acc
# 定义验证函数
def val(dataloader, model, loss_fn):
loss, current, n = 0.0, 0.0, 0
# eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值
model.eval()
with torch.no_grad():
for batch, (x, y) in enumerate(dataloader):
# 前向传播
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred)/output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n+1
val_loss = loss / n
val_acc = current / n
# 计算验证的错误率
print('val_loss=' + str(val_loss))
# 计算验证的准确率
print('val_acc=' + str(val_acc))
return val_loss, val_acc
# 定义画图函数
# 错误率
def matplot_loss(train_loss, val_loss):
# 参数label = ''传入字符串类型的值,也就是图例的名称
plt.plot(train_loss, label='train_loss')
plt.plot(val_loss, label='val_loss')
# loc代表了图例在整个坐标轴平面中的位置(一般选取'best'这个参数值)
plt.legend(loc='best')
plt.xlabel('loss')
plt.ylabel('epoch')
plt.title("训练集和验证集的loss值对比图")
plt.show()
# 准确率
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label = 'train_acc')
plt.plot(val_acc, label = 'val_acc')
plt.legend(loc = 'best')
plt.xlabel('acc')
plt.ylabel('epoch')
plt.title("训练集和验证集的acc值对比图")
plt.show()
#开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []
# 训练次数
epoch = 20
# 用于判断最佳模型
min_acc = 0
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t+1}\n----------")
# 训练模型
train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer)
# 验证模型
val_loss, val_acc = val(val_dataloader, model, loss_fn)
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)
# 保存最好的模型权重
if val_acc > min_acc:
folder = 'save_model'
# path.exists:判断括号里的文件是否存在的意思,括号内可以是文件路径,存在为True
if not os.path.exists(folder):
# os.mkdir() 方法用于以数字权限模式创建目录
os.mkdir('save_model')
min_acc = val_acc
print(f"save best model,第{t+1}轮")
# torch.save(state, dir):保存模型等相关参数,dir表示保存文件的路径+保存文件名
# model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数
torch.save(model.state_dict(), 'save_model/best_model.pth')
# 保存最后一轮权重
if t == epoch-1:
torch.save(model.state_dict(), 'save_model/best_model.pth')
matplot_loss(loss_train, loss_val)
matplot_acc(acc_train, acc_val)
print('done')import torch
from model import MyAlexNet
from torch.autograd import Variable
from torchvision import transforms
from torchvision.transforms import ToPILImage
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
ROOT_TRAIN = 'D:/pycharm/AlexNet/data/train'
ROOT_TEST = 'D:/pycharm/AlexNet/data/val'
# 将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
# 加载训练数据集
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 模型实例化,将模型转到device
model = MyAlexNet().to(device)
# 加载train.py里训练好的模型
model.load_state_dict(torch.load(r'D:\pycharm\AlexNet\save_model\best_model.pth'))
# 结果类型
classes = [
"cat",
"dog"
]
# 把Tensor转化为图片,方便可视化
show = ToPILImage()
# 进入验证阶段
model.eval()
for i in range(1):
x, y = val_dataset[i][0], val_dataset[i][1]
# show():显示图片
show(x).show()
# torch.unsqueeze(input, dim),input(Tensor):输入张量,dim (int):插入维度的索引,最终扩展张量维度为4维
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)
with torch.no_grad():
pred = model(x)
# argmax(input):返回指定维度最大值的序号
# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的那一类
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
# 输出预测值与真实值
print(f'predicted:"{predicted}", actual:"{actual}"')
import os
from shutil import copy
import random
# 如果file不存在,创建file
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
# 获取data文件夹下所有除.txt文件以外所有文件夹名(即需要分类的类名)
# os.listdir():用于返回指定的文件夹包含的文件或文件夹的名字的列表
file_path = 'D:/pycharm/AlexNet/data_name'
pet_class = [cla for cla in os.listdir(file_path) if ".txt" not in cla]
# 创建训练集train文件夹,并由类名在其目录下创建子目录
mkfile('data/train')
for cla in pet_class:
mkfile('data/train/' + cla)
# 创建验证集val文件夹,并由类名在其目录下创建子目录
mkfile('data/val')
for cla in pet_class:
mkfile('data/val/' + cla)
# 划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
# 遍历所有类别的图像并按比例分成训练集和验证集
for cla in pet_class:
# 某一类别的子目录
cla_path = file_path + '/' + cla + '/'
# iamges列表存储了该目录下所有图像的名称
images = os.listdir(cla_path)
num = len(images)
# 从images列表中随机抽取k个图像名称
# random.sample:用于截取列表的指定长度的随机数,返回列表
# eval_index保存验证集val的图像名称
eval_index = random.sample(images, k=int(num * split_rate))
for index, image in enumerate(images):
if image in eval_index:
image_path = cla_path + image
new_path = 'data/val/' + cla
# copy():将源文件的内容复制到目标文件或目录
copy(image_path, new_path)
# 其余图像保存在训练集train中
else:
image_path = cla_path + image
new_path = 'data/train/' + cla
copy(image_path, new_path)
# '\r' 回车,回到当前行的行首,而不会换到下一行,如果接着输出,本行以前的内容会被逐一覆盖
# <模板字符串>.format(<逗号分隔的参数>)
# end="":将print自带的换行用end中指定的str代替
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="")
print()
print("processing done!")
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs