🔥🔥 欢迎来到小林的博客!!
🛰️博客主页:✈️小林爱敲代码
🛰️博客专栏:✈️Linux之路
🛰️社区 :✈️ 进步学堂
🛰️欢迎关注:👍点赞🙌收藏✍️留言
文章目录
大部分课本上都说:程序的一个执行实例,正在执行的程序等。
但是我认为:担当分配系统资源(CPU时间,内存)的实体。
为什么这么认为呢?且听我慢慢道来。
我在冯诺依曼那篇文里面引入了一个重要的概念。
那就是操作系统的管理方法: 先描述,再组织
而操作系统管理进程,也是一样的道理,先描述进程,再组织进程
描述进程,就是把进程的数据封装成一个结构体,而这个结构体被称为进程块。简称为PCB(process control block)。而Linux下的PCB是:task_struct。
task_struct-PCB的一种
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。
现在我们知道task_struct是存储进程数据的结构体了,那存储的内容有哪些呢?
task_ struct内容分类
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
那我们来依次讲解上面列出的内容。
标识符,顾名思义,就是这个进程的唯一标识。也叫pid,简单理解,就是给这个进程做一个记号,你想结束它时可以直接结束。
那么此时,我们就来看看一个进程的标识符。
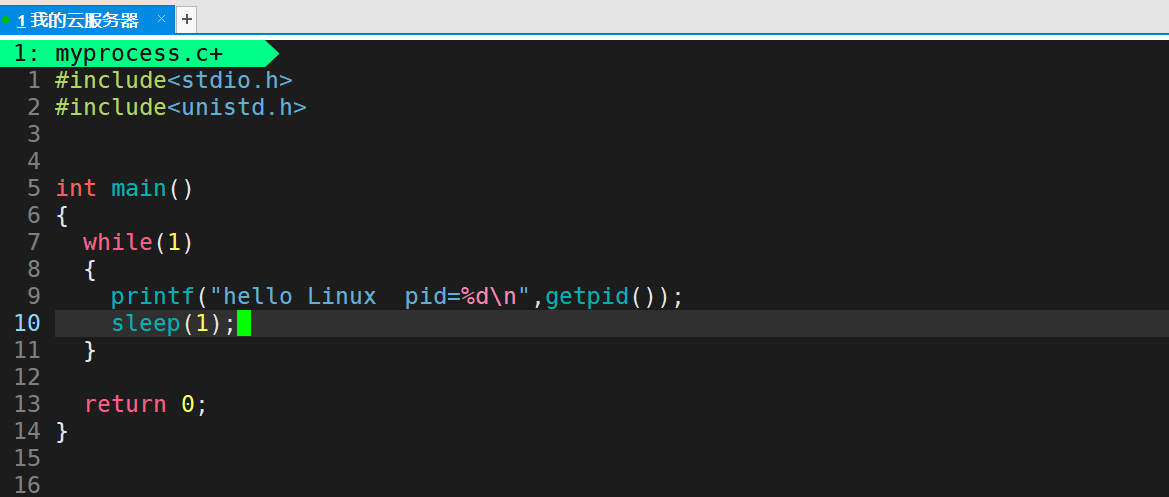
在此之前,我们需要先编写一个一直循环的C语言程序
对应的makefile文件
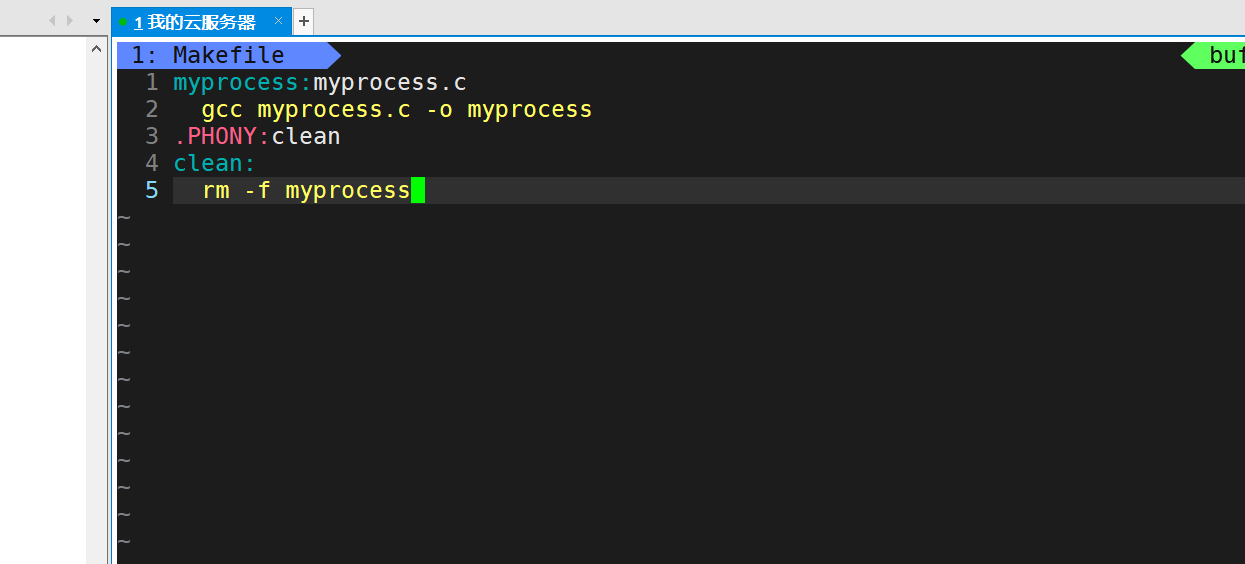
然后我们make编译文件,再执行myprocess
然后就会一直输出hello Linux

然后我们另起一个界面,输入 ps ajx | head -1 && ps axj | grep "myprocess"来查看系统进程
然后就会看到我们这个进程的PID,也就是3604
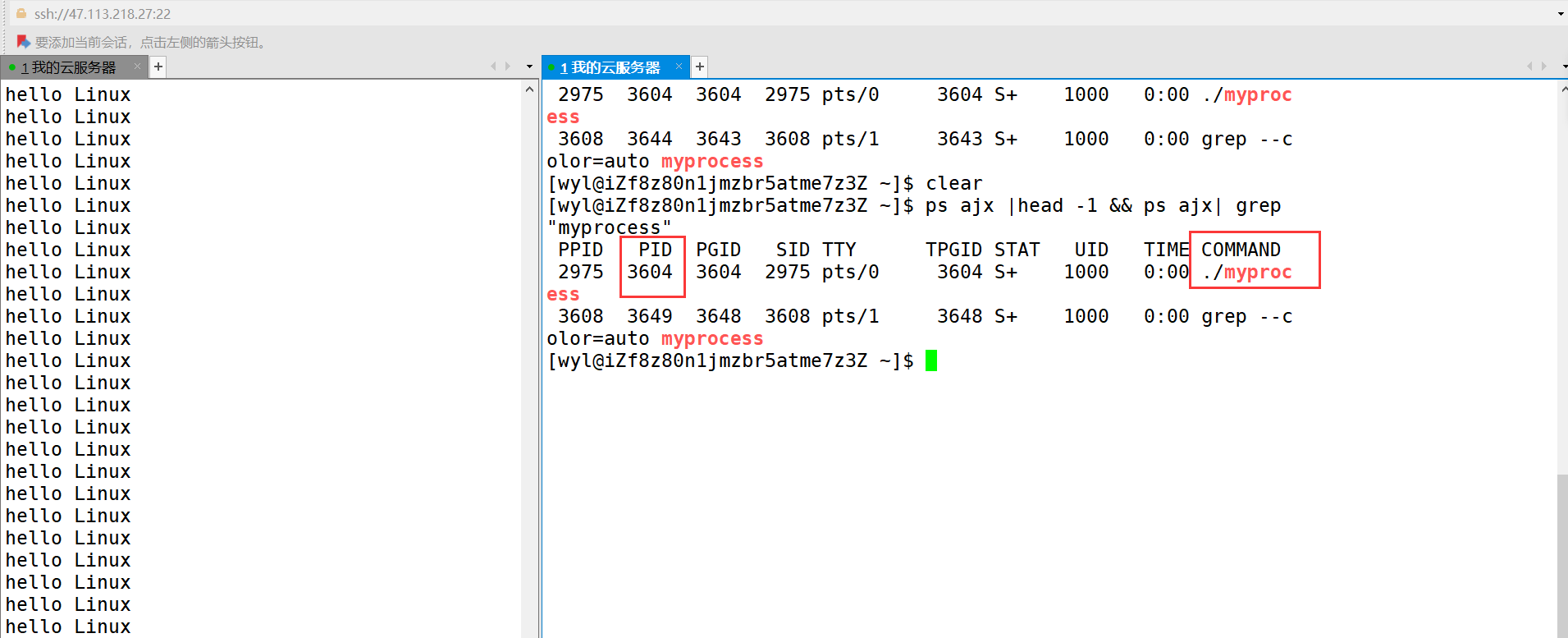
也就是说我们当前执行的 myprocess的PID是3604,那么我们可以用 kill -9 3604,来强制结束进制。
显示Killed,就说明进程被终止了。
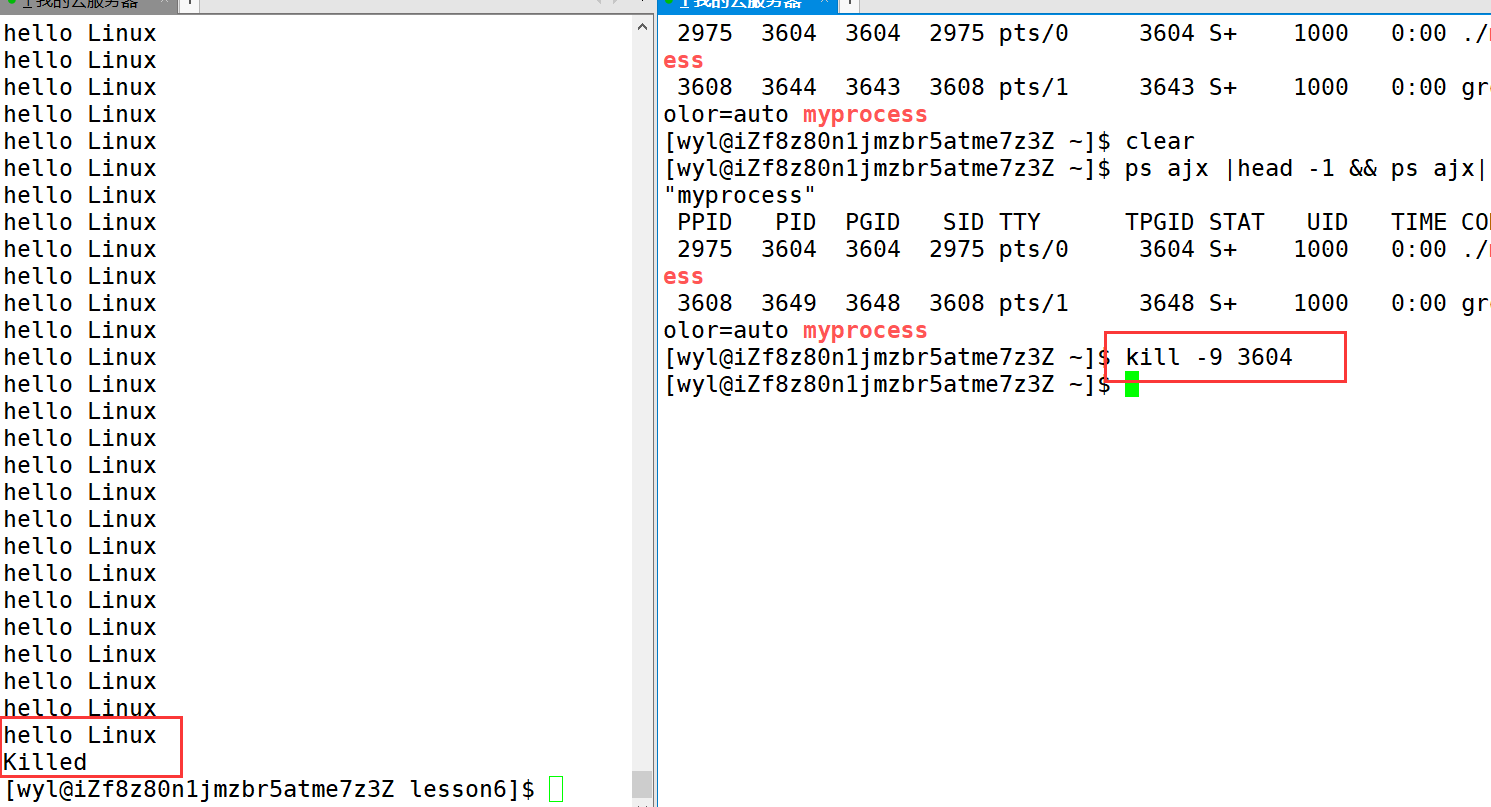
这个操作就类似你在windows系统中打开任务管理器,来结束进程。
我们在写C语言代码的时候,main函数最后都要return一下0。但是很多人不明白为什么要return0.这是因为main函数其实也是被调用的。而返回的值是一个退出码。
我们来把刚刚那个程序的return 0 改成return 100试试。
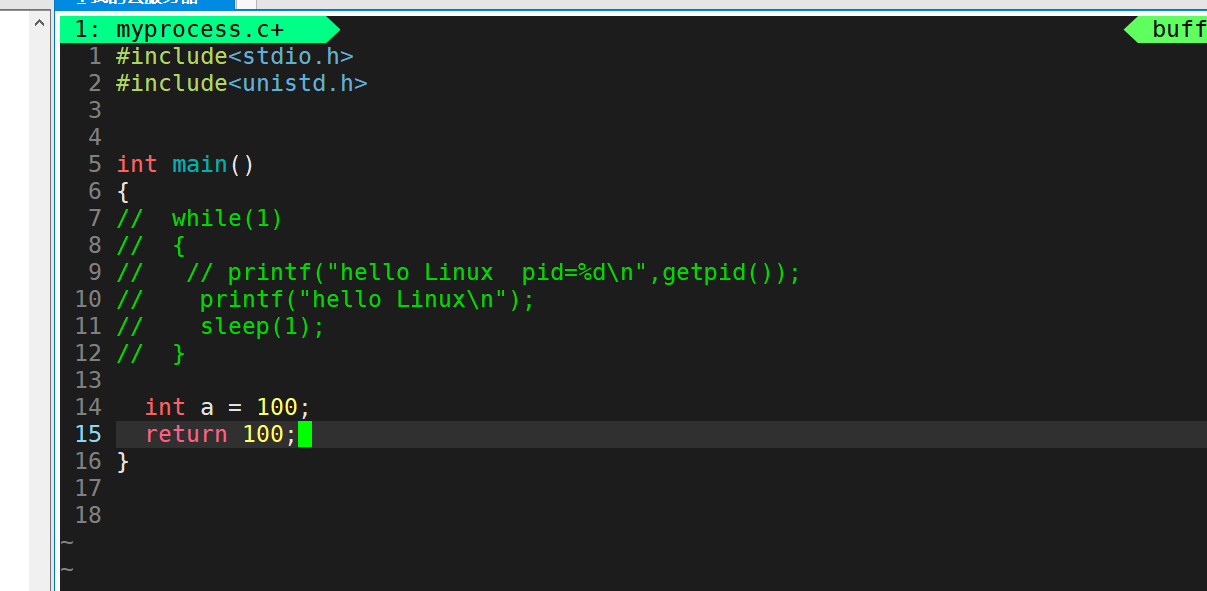
然后重新编译,执行。
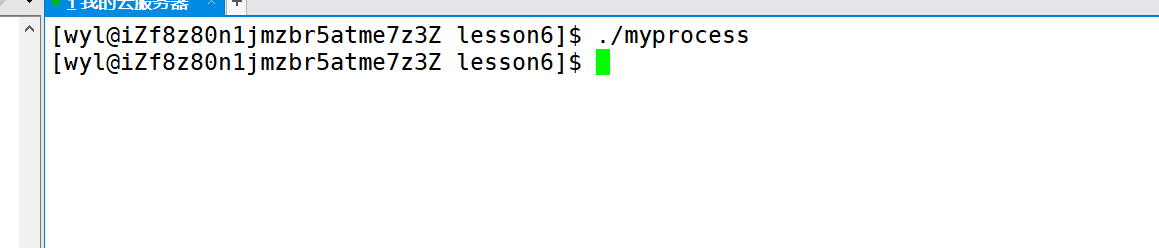
然后我们输入命令:echo $? 可以查看最近返回的退出码。
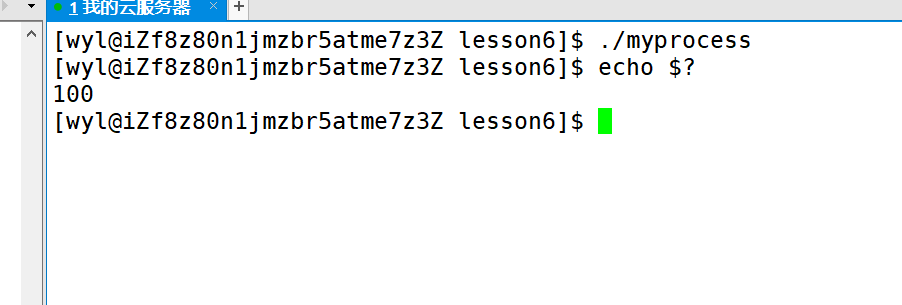
这个100,正是我们执行myprocess返回的。那么我们再执行一次其他命令,再看看它的退出码。
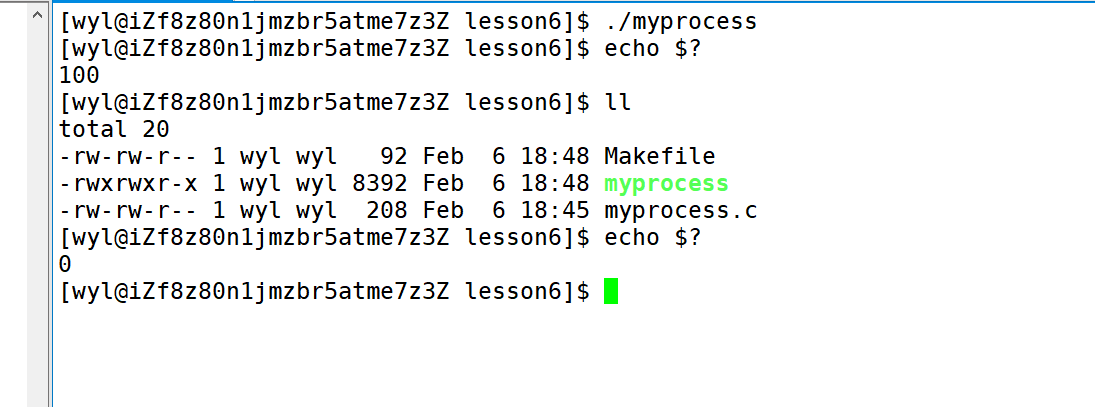
我们可以看到ll执行完后返回的退出码是0。当然,更具体的进程状态,我们会另开一篇文章讲解,因为内容有点多。
之前的篇章讲解过权限。权限是能与不能。而优先级是你已经能了,但是谁先谁后呢?
举个例子:比如说你要进入你学校的食堂买饭,而你可以进入食堂,外校人无法进入食堂。这是你的权限,所以这里能否进入食堂是权限。但是你能进入食堂了,你买饭也要排队。而你排在前面还是后面,这是你的优先级。所以权限和优先级的关系就是,只有有权限之后,才会存在优先级。
程序计数器其实就是存储程序下一条被执行指令的地址。我们都知道C语言顺序结构是从上往下执行的,那为什么它可以从上往下执行?这是因为每次执行,程序计数器都会保存下一条被执行指令的地址。这样才可以执行到下一条指令,到了下一条指令后又会保存它下一条指令的下一条指令…一直循环。
内存指针就是存储了程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。因为操作系统作为管理者,是管理被管理者的数据。那就肯定要知道程序代码和进程的内存地址,所以内存指针就会存储这些地址。
要了解上下文数据这个东西,那我们必须要知道CPU的运行规则。如果是单核CPU,那么每次其实只能运行1个程序。那么这时候大家就有疑问了,我的电脑明明可以同时运行很多数据啊,为什么说CPU一次只能运行一条数据?
原因很简单,CPU会有一个特定的时间片来控制每次进程的执行时间。假如说时间片是10毫秒,那么进程A把数据交给CPU运行。10毫秒结束后就换成进程B,进程B也交给CPU执行10毫秒。然后交给进程C…这样一直循环,在循环过程中如果程序结束,则会被踢出队列。
而用户之所以感觉进程都是同时执行的,是因为10毫太快了,因为用户的操作根本无法达到10毫秒,比如有一个按钮,你移动鼠标到按钮上,都不止10毫秒了。所以才会让大家产生错觉,进程都是同时执行的。当然以上说的CPU都是单核CPU,如果是双核CPU,那么两个CPU同时执行,就可以同时执行两个进程。
假设我们的进程被一个队列连接起来。那么系统中的进程是这样运行的:

但是在这个过程中,有一个非常重要的点。那就是进程交给CPU处理后,进程的一些寄存器会发生变化。比如进程A这一次被CPU处理后,执行到了第1000行代码的位置。那么如何保证CPU下一次处理进程A的时候,还能让代码从第1000行开始运行?所以这个时候,就有了上下文数据。CPU在处理一个进程时,会先读取它的上下文数据。然后从上下文数据记录的位置开始执行,这一次执行完毕之后,把处理过的上下文数据返回给进程自己保存。这样就可以保证CPU每次更换执行进程不会产生数据丢失。
所以CPU执行进程应该是这样的:
1.读取进程的上下文数据
2.根据上下文数据执行进程
3.执行结束(单次执行结束,不代表进程结束),把执行后的上下文数据返回给进程保存
4.执行下一个进程
如果在这个过程中,有进程执行结束或者被强制终止了,那么这个进程会被踢出队列。不会被再次执行。
简单来说就是记录一些信息的,比如上面说到,CPU每隔一段时间就会换下一个进程执行。那么CPU如何判断这个进程已经到时间了?那是因为有记账信息一直记着呢。
包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。具体的下次会开一篇博客来详解。
上面我们说了,操作系统会被一个进程封装成一个结构体来描述它。所以 进程的本质就是:进程 = 结构体 + 数据代码段。
我们可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
进程的信息可以通过 /proc 系统文件夹查看。
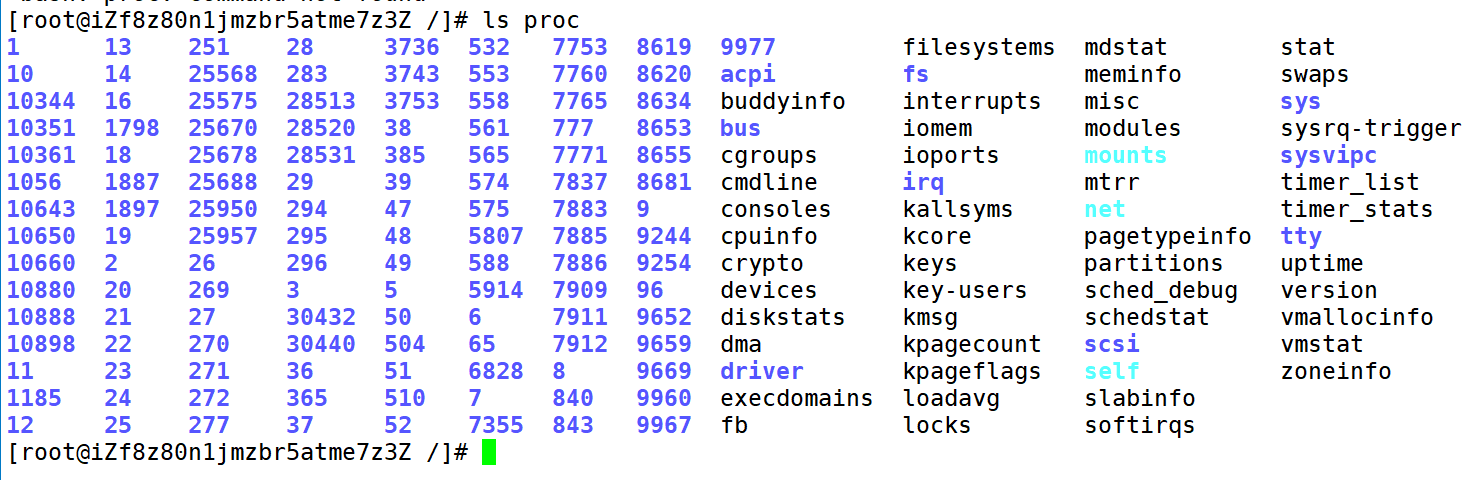
我们可以发现,这些pid都是一个一个目录。
假如要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。
我们可以看到,里面有很多的文件。
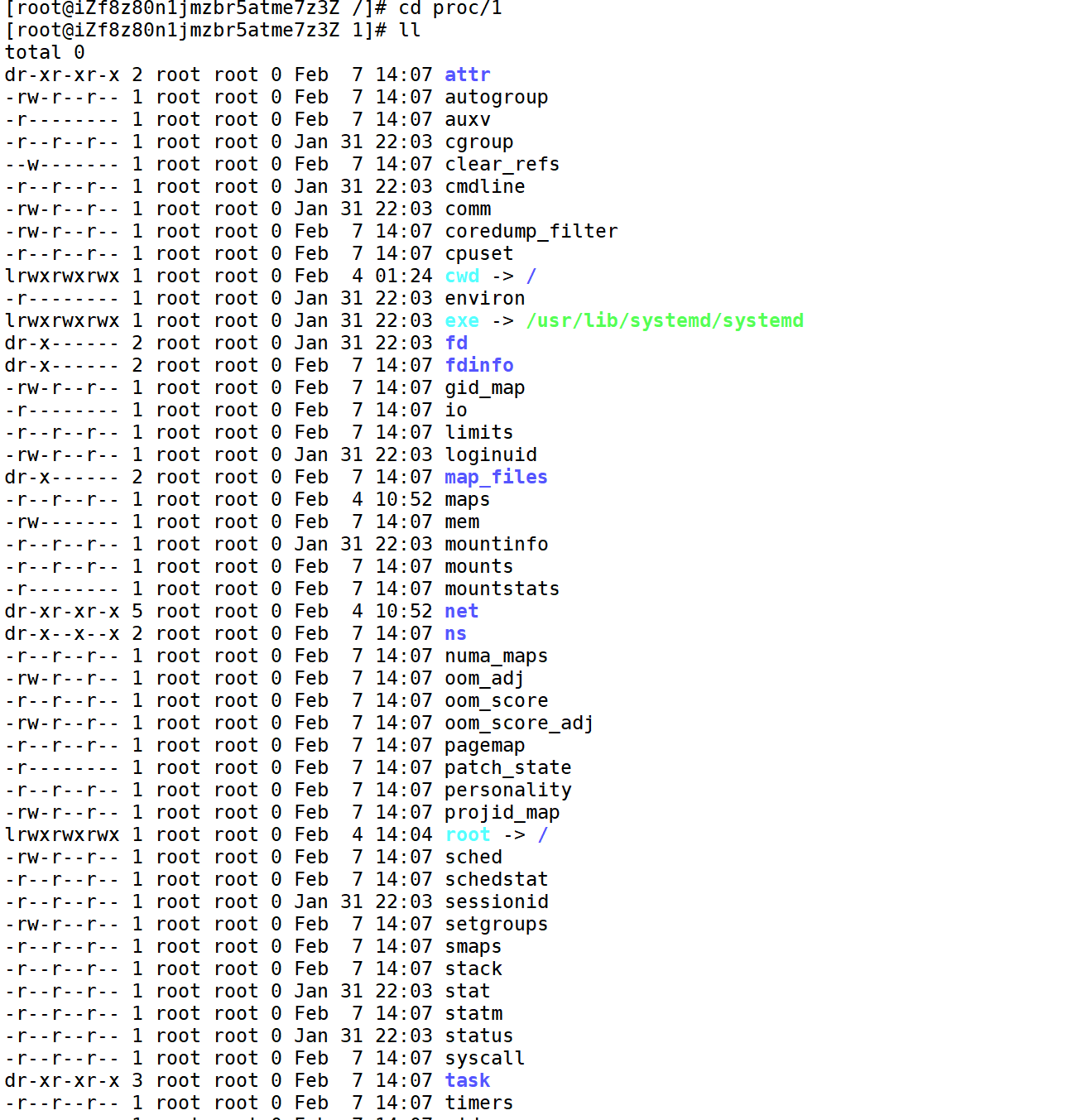
其中的cwd是存储了该执行文件的目录。这也就是在C语言中文件输出,如果不输入路径,就会自动输出文件到当前路径的原因。因为有cwd记录地址。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
在尝试实现应用auto_orient的过程之后!对于我的图片,我收到此错误:ArgumentError(noimagesinthisimagelist):app/uploaders/image_uploader.rb:36:in`fix_exif_rotation'app/controllers/posts_controller.rb:12:in`create'Carrierwave在没有进程的情况下工作正常,但在添加进程后尝试上传图像时抛出错误。流程如下:process:fix_exif_rotationdeffix_exif_rotationmanipulate!do|image|
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
已检查ActiveRecord、DataMapper、Sequel:有些使用全局变量(静态变量)有些需要在使用模型加载源文件之前打开数据库连接。在使用不同数据库的sinatra应用程序中使用哪种ORM更好。 最佳答案 DataMapper专为多数据库使用而设计。你可以通过像DataMapper.setup(:repository_one,"mysql://localhost/my_db_name")这样的方式设置多个存储库。DataMapper随后会跟踪所有已在哈希中设置的存储库,您可以引用该哈希并将其用于范围界定:DataMapp