反向迭代器的适配只用于双向迭代器,对于单链表实现的单向迭代器是不能通过适配构造一个反向迭代器的,为什么要说反向迭代器适配器呢?因为我们只需要实现一个反向迭代器模板就可以用所有的双向迭代器的正向实现其反向迭代器。
提示:以下是本篇文章正文内容,下面案例可供参考
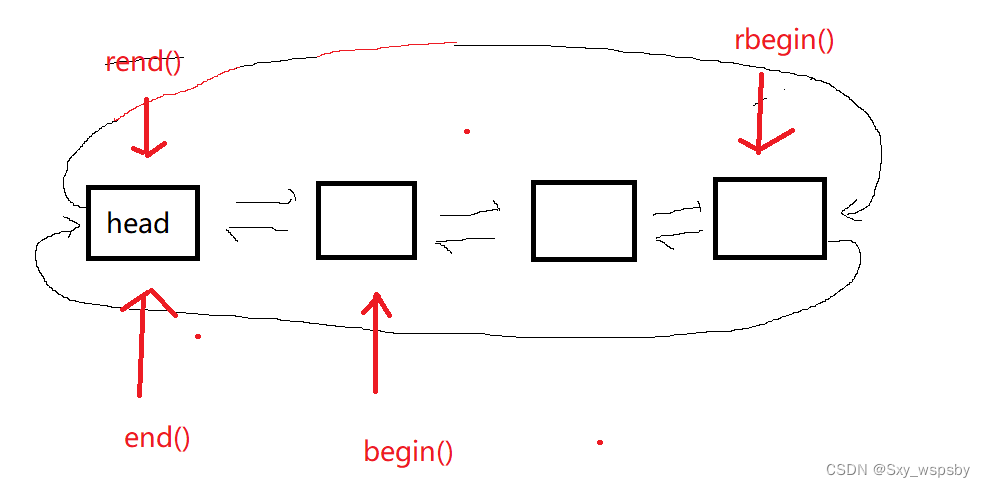
对于list而言,我们想要倒着遍历该如何实现呢?其实实现过正向迭代器的朋友们都知道,list的迭代器的++是指向链表的下一个节点,也就是node = node->next,那么要实现反向我们只需要将++实现为将node = node->prev即可,如下图所示:
//反向迭代器
template<class T, class Ref, class Ptr>
struct list_reverse_iterator
{
typedef list_node<T> node;
typedef list_reverse_iterator<T, Ref, Ptr> self;
node* _node;
list_reverse_iterator(node* n)
:_node(n)
{
}
Ref operator*()
{
return _node->_data;
}
self& operator++()
{
_node = _node->_prev;
return *this;
}
self operator++(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
self& operator--()
{
_node = _node->_next;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const self& it)
{
return _node != it._node;
}
bool operator==(const self& it)
{
return _node == it._node;
}
};可以看到我们上述代码对于反向迭代器确实只是将++变成了原先的--,--变成了原先的++。现在我们再写一下rbegin(),rbegin().
class list
{
public:
typedef list_node<T> node;
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
typedef list_reverse_iterator<T, T&, T*> reverse_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
reverse_iterator rbegin()
{
return reverse_iterator(_head->_prev);
}
reverse_iterator rend()
{
return reverse_iterator(_head);
}我们先将反向迭代器重命名为reverse_list,然后让rbegin()变成链表的尾节点,rend()还是链表的哨兵位头结点不变,下面我们来验证一下看是否正确:
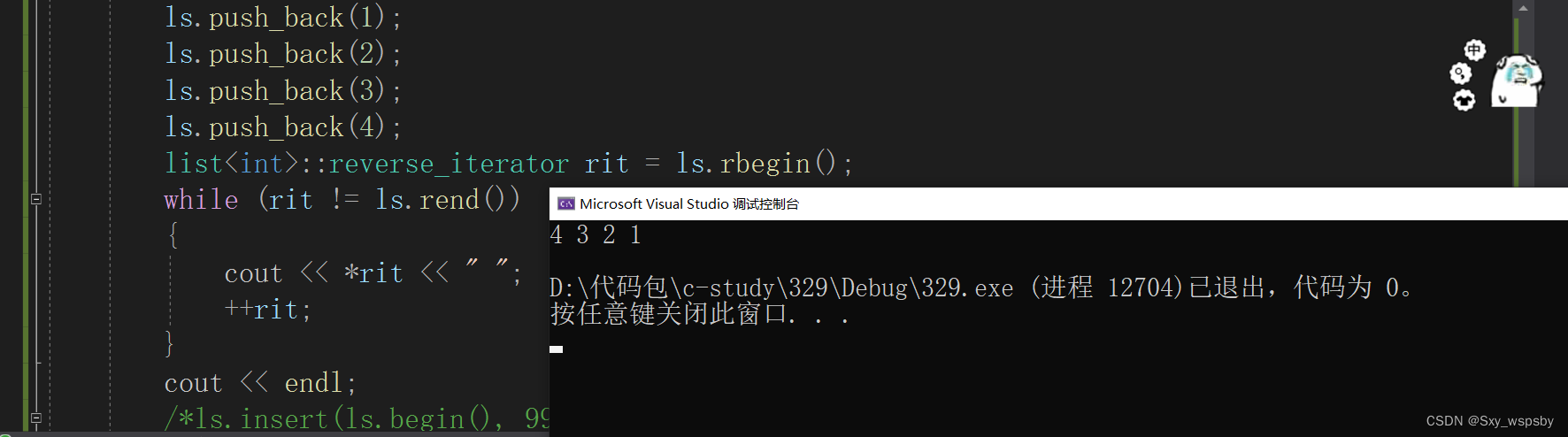
通过验证我们发现确实可以实现反向迭代,那么现在问题来了,我们刚开始说了反向迭代器是一个适配器,如果我们用这个链表的反向迭代器去实现vector的反向迭代器可以实现吗?答案肯定是不行,因为vector又不是节点怎么返回节点的前一个后一个呢?所以我们实现的这个迭代器只能list使用,下面我们看看大佬是如何实现反向迭代器的:
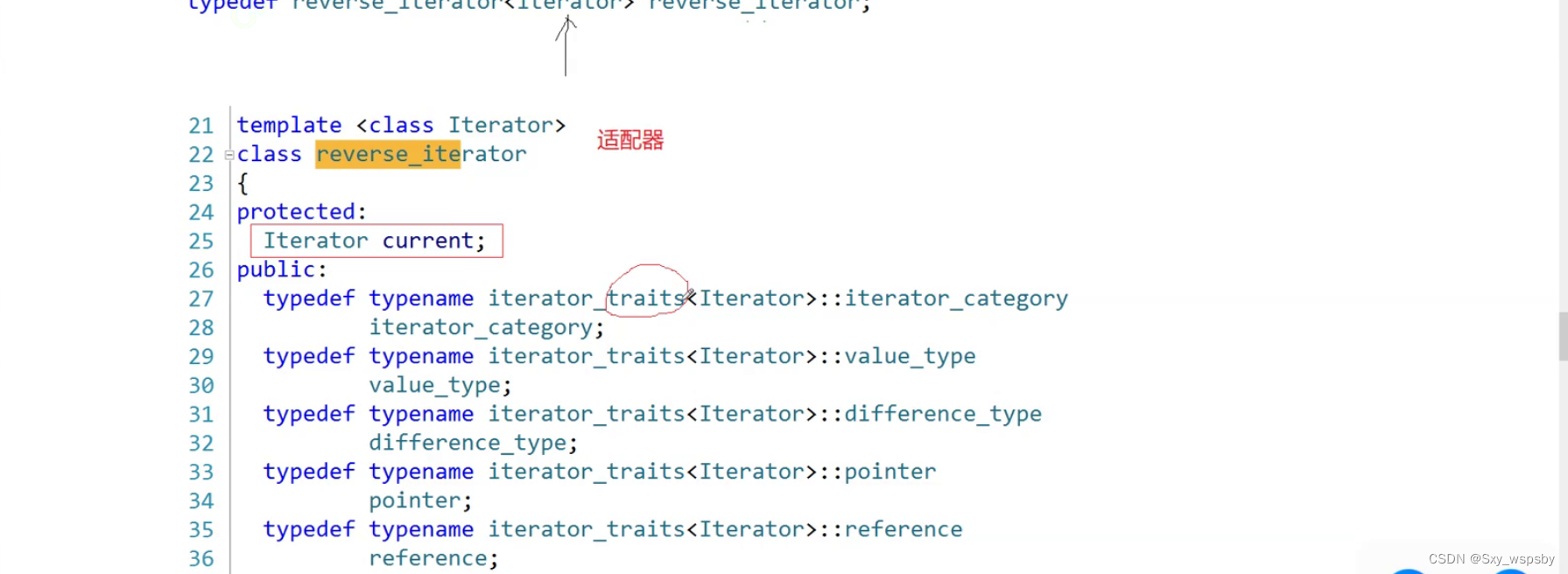
我们圈出来的current是什么呢?current是一个正向迭代器
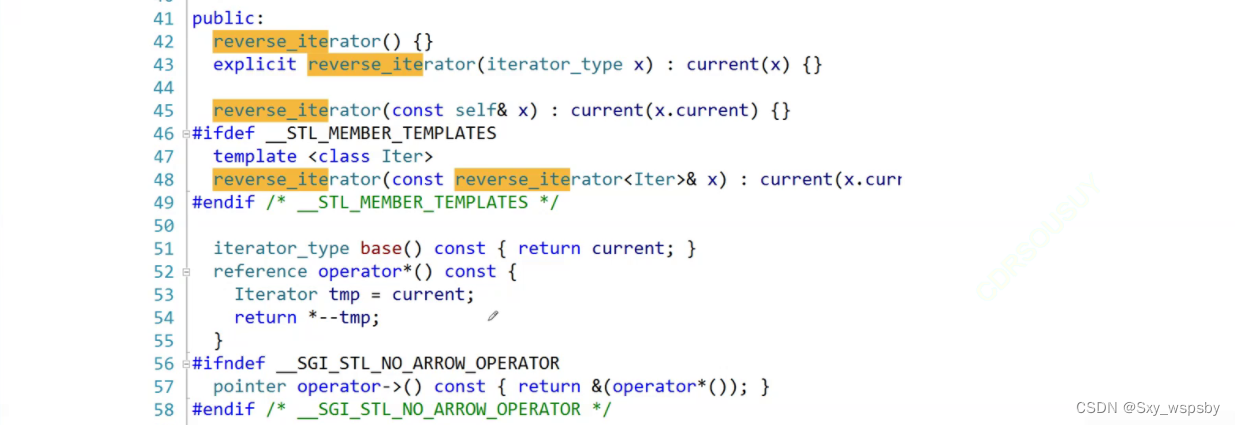 那么为什么operator*变成了--迭代器然后解引用呢?再往下看:
那么为什么operator*变成了--迭代器然后解引用呢?再往下看:

反向迭代器的++是正向迭代器的--,反向迭代器的--是正向迭代器的++。

我们发现rbegin()是迭代器的end(),rend()是迭代器的begin(),下面我们画个图来验证一下:
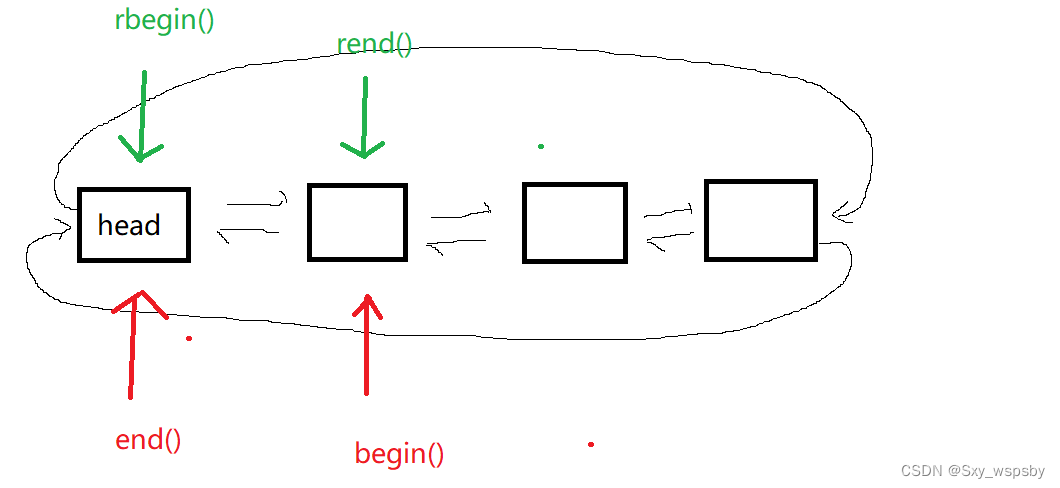
这个时候我们终于理解了为什么operator*是--iterator的解引用,因为rbegin()是指向哨兵位的头结点的,这个时候是不能对头结点解引用的,所以我们应该对头结点的prev也就是最后一个节点解引用,这样一来就能依次从后往前访问到链表的每个元素,当rbegin()==rend()的时候将所有元素遍历完成。
下面我们就来实现一下:
namespace sxy
{
template<class iterator,class Ref,class Ptr>
struct ReverseIterator
{
typedef ReverseIterator<iterator, Ref, Ptr> self;
iterator _cur;
ReverseIterator(iterator it)
:_cur(it)
{
}
};
}首先我们创建一个iterator.h文件,然后写一个模板这个模板第一个参数是任意类型的迭代器,第二个参数是迭代器中解引用的返回值Ref,第三个参数是在重载->符号的返回值Ptr。然后我们用正向迭代器创建一个变量_cur,构造函数初始化的时候直接用正向迭代器初始化_cur.
然后我们先实现++,--:
self& operator++()
{
--_cur;
return *this;
}
self operator++(int)
{
iterator tmp = _cur;
--_cur;
return tmp;
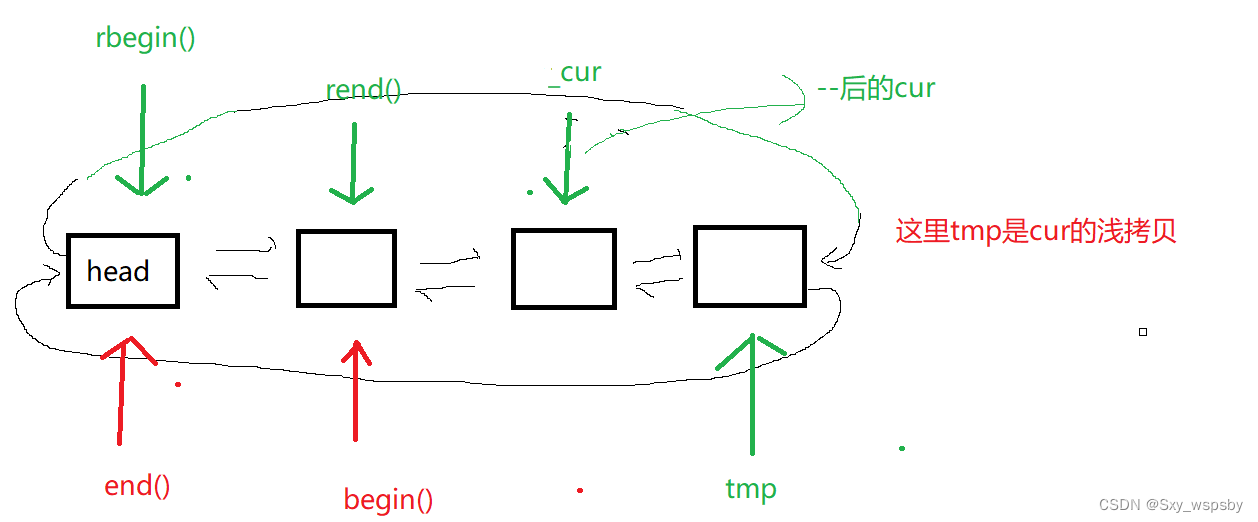
}对于前置++和后置++的区别在于后置++要返回--前的那个值,所以我们直接用拷贝构造一个tmp,这里我们是没有实现迭代器的拷贝构造的,那么使用默认的拷贝构造可以吗?答案是可以,因为我们要的就是浅拷贝,我们就是要tmp指向cur位置,如下图:
我们再看一下深拷贝变成了什么:
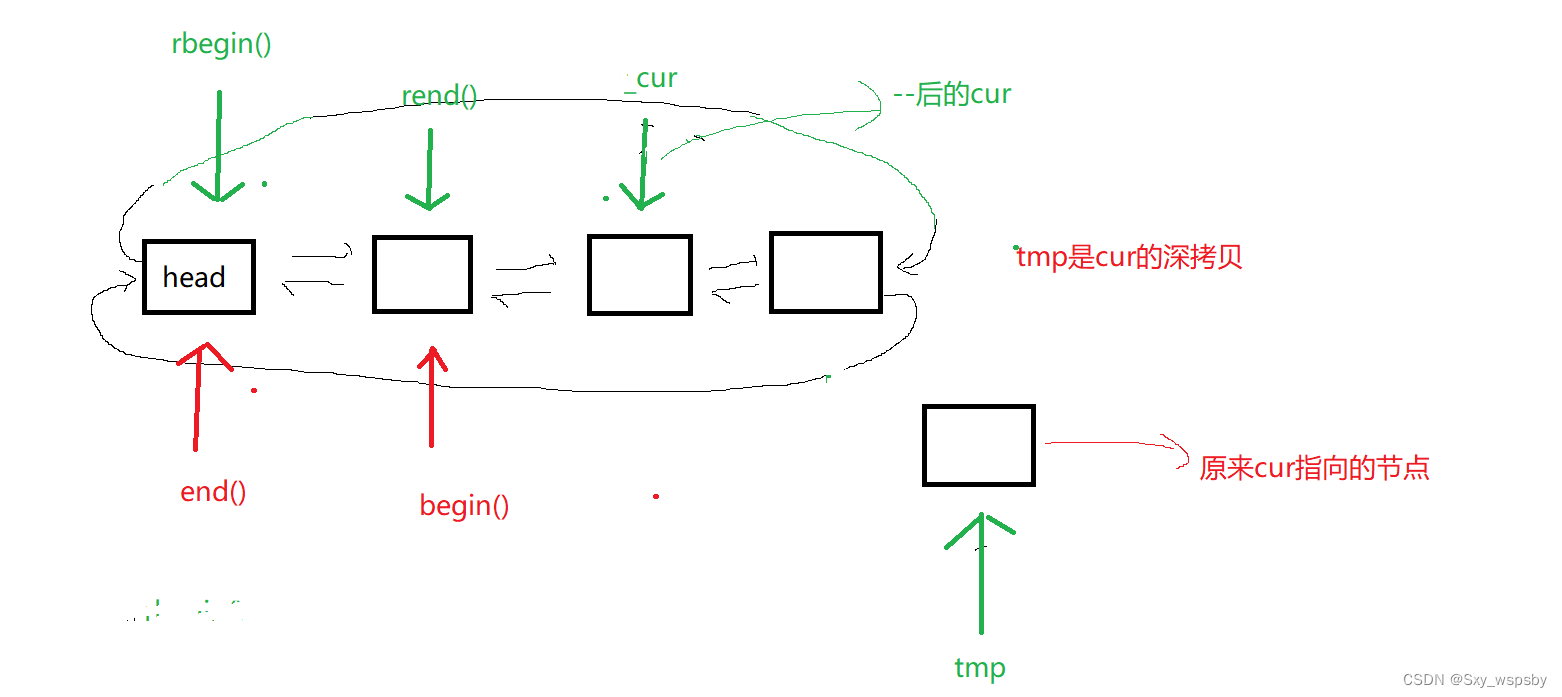
通过上图我们应该理解了为什么我们直接使用默认的构造函数就能解决问题。
self& operator--()
{
++_cur;
return *this;
}
self operator--(int)
{
iterator tmp = _cur;
++_cur;
return tmp;
}对于--的实现是和++一样的,只不过--变成了正向迭代器的++。
下面我们再实现一下迭代器要使用的==和!=符号:
bool operator!=(const self& s)
{
return _cur != s._cur;
}
bool operator==(const self& s)
{
return _cur == s._cur;
}对于反向迭代器的判断我们只需要判断两个反向迭代器的节点是否相等即可。
下面我们实现反向迭代器的解引用:
Ref operator*()
{
iterator tmp = _cur;
--tmp;
return *tmp;
}对于反向迭代器的解引用我们说过,由于rbegin()是在end()的位置所以我们是不能直接解引用的,正确的操作是解引用此位置的前一个节点(为什么是前一个呢?因为是反向迭代器!)。所以我们用_cur拷贝构造一个tmp,然后--tmp就是前一个节点,然后再返回解引用的值即可。返回值的实现与正向迭代器一样具体可以去看我的list模拟实现那篇文章看看为什么要多一个模板参数Ref做返回值。
下面我们在list中定义一下反向迭代器:
首先包含一下头文件,然后typedef一下反向迭代器和反向迭代器的const版本:
typedef ReverseIterator<iterator,T&,T*> reverse_iterator;
typedef ReverseIterator<iterator, const T&, const T*> const_reverse_iterator;
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
const_reverse_iterator rbegin() const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend() const
{
return const_reverse_iterator(begin());
}接下来我们看看是否能成功反向输出呢?
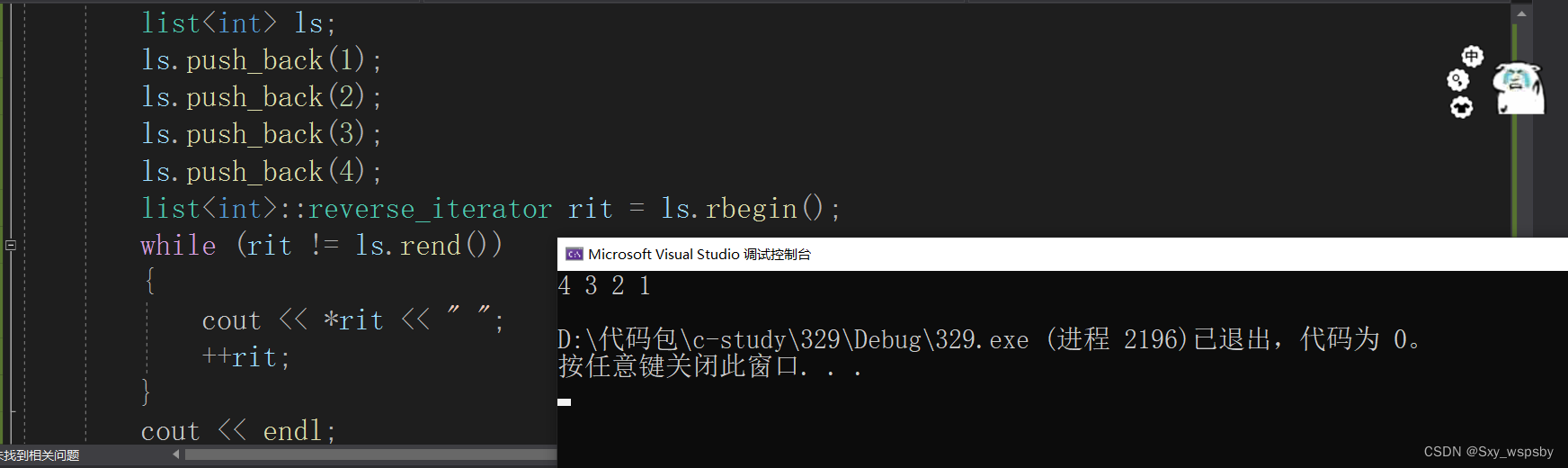
看来我们是成功了,那么回到我们一开始的问题,可以用这个迭代器去适配vector的反向迭代器吗?我们画个图看看:
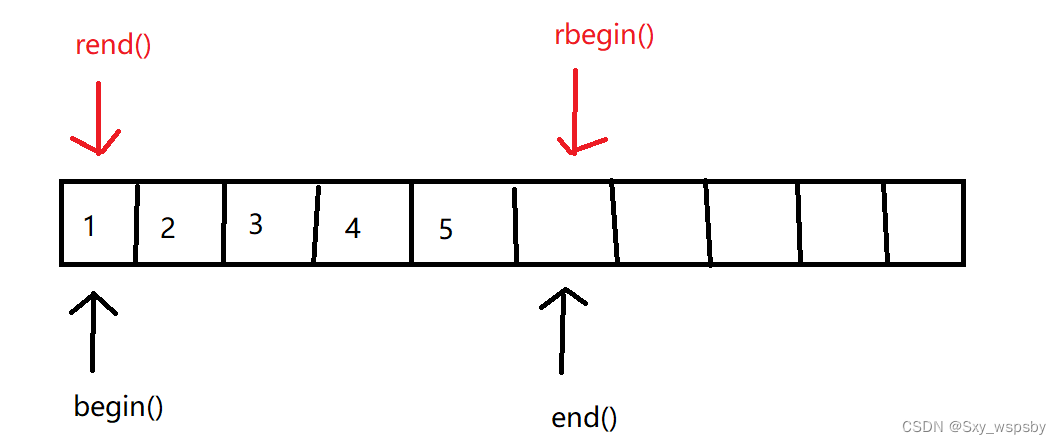 当反向迭代器++的时候是正向迭代器的--,然后从vector的尾部开始向头部移动。同时我们发现,operator*的实现也是满足的,因为rbegin()的位置是vector存放最后一个有效数据的位置的下一个,这个位置是没有数据的,只有让迭代器--一下在解引用才是正确的值,由于是每次位置的前一个所以当rbegin()==rend()的时候将反向遍历完所有数据,下面我们就演示一下vector的反向迭代器:
当反向迭代器++的时候是正向迭代器的--,然后从vector的尾部开始向头部移动。同时我们发现,operator*的实现也是满足的,因为rbegin()的位置是vector存放最后一个有效数据的位置的下一个,这个位置是没有数据的,只有让迭代器--一下在解引用才是正确的值,由于是每次位置的前一个所以当rbegin()==rend()的时候将反向遍历完所有数据,下面我们就演示一下vector的反向迭代器:
首先在vector.h的头文件中包含iterator.h的头文件:

然后在vector中typedef一下反向迭代器:
typedef ReverseIterator<iterator, T&, T*> reverse_iterator;
typedef ReverseIterator<iterator, const T&, const T*> const_reverse_iterator;
reverse_iterator rbegin()
{
return reverse_iterator(end());
}
reverse_iterator rend()
{
return reverse_iterator(begin());
}
const_reverse_iterator rbegin() const
{
return const_reverse_iterator(end());
}
const_reverse_iterator rend() const
{
return const_reverse_iterator(begin());
}然后我们运行一下程序看是否能成功:
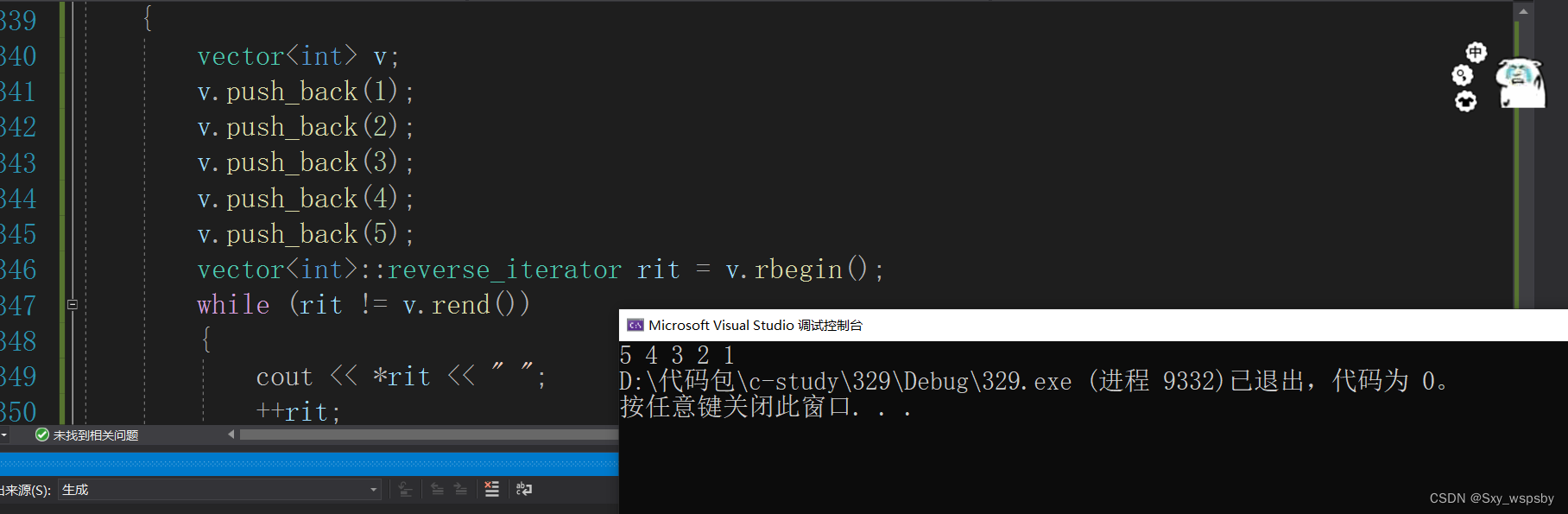
答案我们也看到了确实可以,这也就证明了我们一开始所说的大佬思想。当我们想实现list的反向迭代器的时候只实现出针对list的反向迭代器,而大佬却用一个反向迭代器适配其他的反向迭代器。
对于迭代器的适配器最重要的是实现的思想,比如我们如何控制对迭代器进行解引用,++--等等,想要有如同大佬一般的思想我们必须多看优秀的代码,只有去看别人写的优秀的代码我们才能进步。
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
我最近开始编写Ruby代码,但我对block参数有误解。以下面的代码为例:h={#Ahashthatmapsnumbernamestodigits:one=>1,#The"arrows"showmappings:key=>value:two=>2#ThecolonsindicateSymbolliterals}h[:one]#=>1.Accessavaluebykeyh[:three]=3#Addanewkey/valuepairtothehashh.eachdo|key,value|#Iteratethroughthekey/valuepairsprint"#{value}:#{ke
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我正在用ruby遍历一个数组。有没有一种简单的方法可以在不返回for循环的情况下获取迭代次数或数组索引? 最佳答案 啊,知道了。each_with_index哇!编辑:糟糕! 关于ruby-如何使用每个迭代器获取数组索引或迭代次数?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/706115/
我在阅读有关.each迭代器的Ruby问题,有人说如果更高阶的迭代器更适合该任务,则使用.each可能会产生代码味道。Ruby中的高阶迭代器是什么?编辑:我提到的StackOverflow答案的作者JörgWMittag提到他是要编写更高级别的迭代器,但他还解释了下面的内容。 最佳答案 哎呀。我的意思是更高级别的迭代器,而不是更高阶的迭代器。当然,每个迭代器都是高阶的。基本上,迭代是一个非常低级的概念。编程的目的是与团队中的其他利益相关者交流意图。“初始化一个空数组,然后遍历另一个数组,并将该数组的当前元素添加到第一个数组中(如果该
一些我找到的选项是ActiveCouchCouchRESTCouchPotatoRelaxDBcouch_foo我更喜欢GitHub上的项目,因为这让我更容易fork和推送修复。所有这些都符合该要求。我习惯了Rails,所以我喜欢像ActiveRecord模型一样工作的东西。另一方面,我也不希望我和Couch之间太多--毕竟我使用它作为我的数据库是有原因的。最后,它们似乎都得到了相当积极的维护(couch_foo可能是个异常(exception))。所以我想这归结为(不可否认和不幸的)主观:有没有人对他们有过好的或坏的经历? 最佳答案
我有一个正在开发的命令行Ruby应用程序,我想允许它的用户提供将在部分过程中作为过滤器运行的代码。基本上,应用程序是这样做的:读入一些数据如果指定了过滤器,则使用它来过滤数据处理数据我希望过滤过程(第2步)尽可能灵活。我的想法是,用户可以提供一个Ruby文件,该文件设置一个已知常量以指向实现我定义的接口(interface)的对象,例如:#user'sfilterclassMyFilterdefdo_filter(array_to_filter)filtered_array=Array.new#domyfilteringonarray_to_filterfiltered_arrayen
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
给定一个最小整数和最大整数,我想创建一个数组,它从最小值到最大值以二为单位计数,然后倒退(再次以二为单位,重复最大数)。例如,如果最小数是1,最大数是9,我想要[1,3,5,7,9,9,7,5,3,1].我试图尽可能简洁,这就是我使用单行代码的原因。在Python中,我会这样做:range(1,10,2)+range(9,0,-2)在我刚刚开始学习的Ruby中,到目前为止我所想到的是:(1..9).inject([]){|r,num|num%2==1?r这行得通,但我知道必须有更好的方法。这是什么? 最佳答案 (1..9).step