(最近有读者朋友表示,希望能加一些示意图来描述分析过程中用到的原理知识。好的,之后我会注意,谢谢这位读者)
有位朋友找我,希望我能帮看一下他的一个service。从他的描述看,并没有资源方面的泄漏,程序目前也能正常工作。他是在用dotnet-counters moniter时发现gc2、也就是full gc触发的比较频繁,频率超过了他自己的预期,于是他心里不踏实,所以想找我看一下。
能在没发生资源或性能异常前自觉monitor .net metrics的人,我跟佩服,这是讲究人儿啊。那后面我就管这位朋友叫"精致大哥"了哈
其实对于这次没有明确内存泄漏迹象的问题,我没啥把握能给出明确问题点,甚至可能就是没问题。但,试试吧,拿出windbg准备。
既然是频繁full gc, 而且还都把内存降下来了,那么最先想到的是会不会在申请大量的大对象。
因为如果有很多小对象在申请内存,一般都会在gc0和gc1阶段搞定,而无需总劳烦gc2;或者申请很多小对象,而且还一直引用着,这样也能造成gc2,但那样的话内存应该也会泄漏才对。
带着这个猜想,先看一下大对象堆LOH的大小:
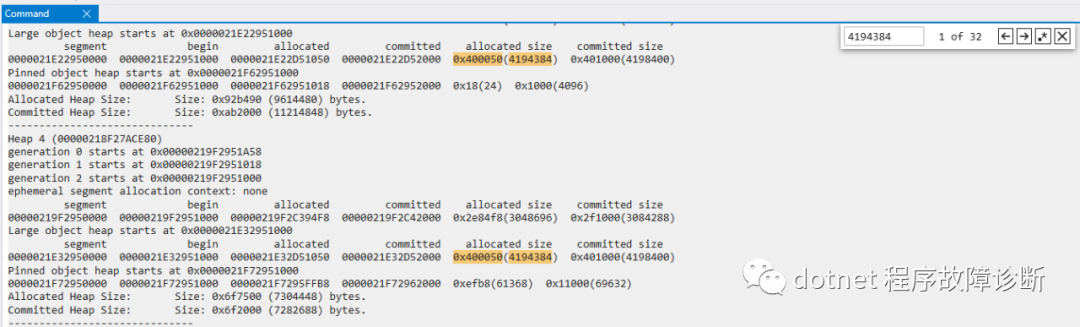
可以看到很多gc heap的LOH都被申请了4194384 byte大小。
然后去看看heap4里的LOH存的都是些什么。根据heap4的LOH segment的起始位置和allocation end 位置,用!dumpheap:

可以看出这里面只有一个byte array, 而且大小也是约4M。
尝试用!gcroot看一下这个大对象的引用关系:

这回gcroot无法给出想要的答案。这是因为引用它的引用链的head没有了引用根,画个示意图:

(这样一来,下次同代gc触发时,这个大对象的内存也就真的被释放了)
引用链找不到,线索断了。别急,既然sos不能帮助我们了,可以试试耐下心手动找引用链。我们知道一个对象的地址的值通常会存在某个对象所占用内存的"身上",如图所示:
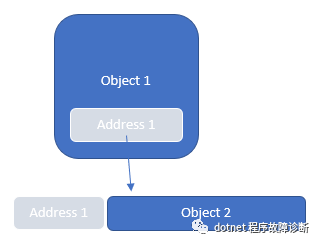
那么就可以先从当前gc heap的起始位置找一下这个大对象的地址值所在的内存位置。考虑到当前进程是小端模式,所以用如下命令:
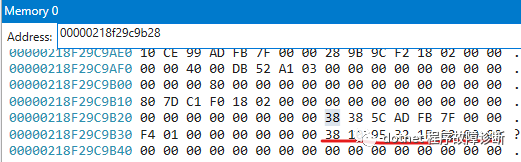
1 0:000> s -b 0000021000000000 L?2000000000 38 10 95 32 1e 02
2 00000218`f29c9b38 38 10 95 32 1e 02 00 00-00 00 00 00 00 00 00 00在内存位置218`f29c9b38找到了对象的地址值,接着找一下“包含”这个位置的对象:
1 Before: 00000218f29c9b28 4024 (0xfb8) System.Byte[][]
2 After: 00000218f29caae0 72 (0x48) System.Threading.Tasks.Task+DelayPromise看来我们已经到了一个System.Byte[][]对象的位置了。按上面的思路继续搜寻218f29c9b28这个值:
1 0:000> s -b 0000021000000000 L?2000000000 28 9b 9c f2 18 02
2 00000218`f29c9ae8 28 9b 9c f2 18 02 00 00-00 00 40 00 db 52 a1 03 (.........@..R..再找“包含”这个位置的对象:
1 Before: 00000218f29c9ae0 48 (0x30) System.Buffers.ConfigurableArrayPool`1+Bucket[[System.Byte, System.Private.CoreLib]]
2 After: 00000218f29c9b10 24 (0x18) Free以此类推,又经过一系列搜寻,最后找到了这个对象,它的地址值在这个进程空间中无法被找到了:
Before: 00000218f29b7af0 24 (0x18) System.Buffers.ConfigurableArrayPool`1[[System.Byte, System.Private.CoreLib]]于是认为已经找到了整个引用链的"临时"head。说它是"临时"的,是因为没有gc root引用着它。
有了这些数据,我们便可以用常规的sos指令进行一下正向的验证,从head 218f29b7af0 开始往下验证吧:

可以看到它确实引用着218f29b7b08 _buckets,

可以看到_buckets这个Bucket<byte>[]有19个元素,第18个元素确实就是上面推导的Bucket instance,继续看:
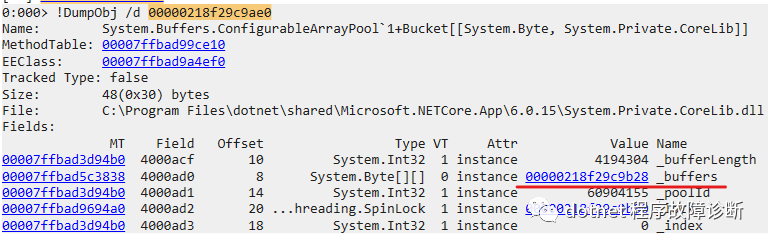
可以看到这个bucket instance(00000218f29c9ae0)确实hold着218f29c9b28 这个byte[][],而这个byte[][]里也确实包含了我们最初要找的那个大对象byte[]:
好了,现在可以画个逆向诊断的引用复原图:

如果大家看过ArrayPool的一些基本实现,就知道这个ConfigurableArrayPool`1其实是ArrayPool.Create(config)创建出来的,所以我们调研的那个大对象byte[]其实是ArrayPool里维护的buffer。
又看了一下,进程中当时有18个这样大小的大byte[]:

按上面类似的推导,随机看了其他几个byte[],其引用链的head都是不同的ConfigurableArrayPool`1 instances,所以对了一下ConfigurableArrayPool`1的数量,用!dumpheap:
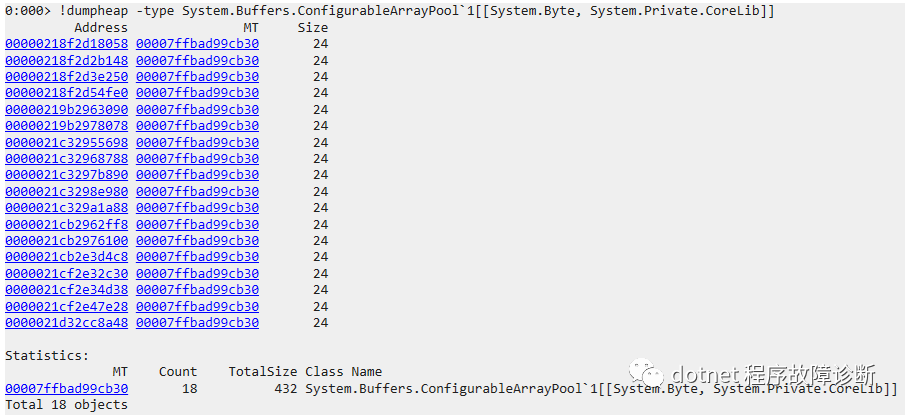
也是18个。所以说,貌似每个Pool只管理了1个byte[] ?? 这样就有问题了,因为这样的话相当于每个pool都不能reuse 已有的其他pool的buffers,pool没有起到pool的作用。所以每次需要用buffer时,只能不断申请新的大byte[],导致大对象数量增长。
把这个分析结果告诉了那位“精致大哥”后,“精致大哥”找到了创建pool的代码,简化后是这样的:
1 private DigestSummary CalculateDigestSummary(NotificationEvent notificationEvent)
2 {
3 var bytesPool = ArrayPool<byte>.Create(4 * 1024 * 1024, 500);
4 byte[] buf = bytesPool.Rent(4 * 1024 * 1024);
5
6 try
7 {
8 return CalculateWithBuffer(buf);
9 }
10 finally
11 {
12 bytesPool.Return(buf);
13 }
14 }看第3行,每次需要byte[]时,都先创建一个pool,下次又重新用新pool。于是效果就是没有pool啦。
应该在使用buffer的scope中尽量reuse pool instance, 或者也可以用
var bytesPool = ArrayPool<byte>.Shared;这次gc问题的诊断分析,需要脱离sos,手动找引用关系,从而获得了“这次大对象是ArrayPool挂着”这层信息,进而找出了ArrayPool instances与大byte[] instances一对一的不正常关系。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我很好奇.NET将如何影响Python和Ruby应用程序。用IronPython/IronRuby编写的应用程序是否会非常特定于.NET环境,以至于它们实际上将变得特定于平台?如果他们不使用任何.NET功能,那么IronPython/IronRuby相对于非.NET同类产品的优势是什么? 最佳答案 我不能说任何关于IronRuby的东西,但是大多数Python实现(如IronPython、Jython和PyPy)都试图尽可能忠实于CPython实现。不过,IronPython正在迅速成为这方面的佼佼者之一,并且在PlanetPyth
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc