Impala 直接针对存储在 HDFS、HBase或 Amazon Simple Storage Service (S3)中的 Apache Hadoop 数据提供快速的交互式 SQL 查询。Impala是一个基于Hive、分布式、大规模并行处理(MPP:Massively Parallel Processing)的数据库引擎。除了使用相同的统一存储平台外,Impala 还使用与 Apache Hive 相同的元数据、SQL 语法(Hive SQL)、ODBC 驱动程序和用户界面(Hue 中的 Impala 查询 UI)。关于Hive的介绍,可以看我之前的文章:大数据Hadoop之——数据仓库Hive。Impala官方文档
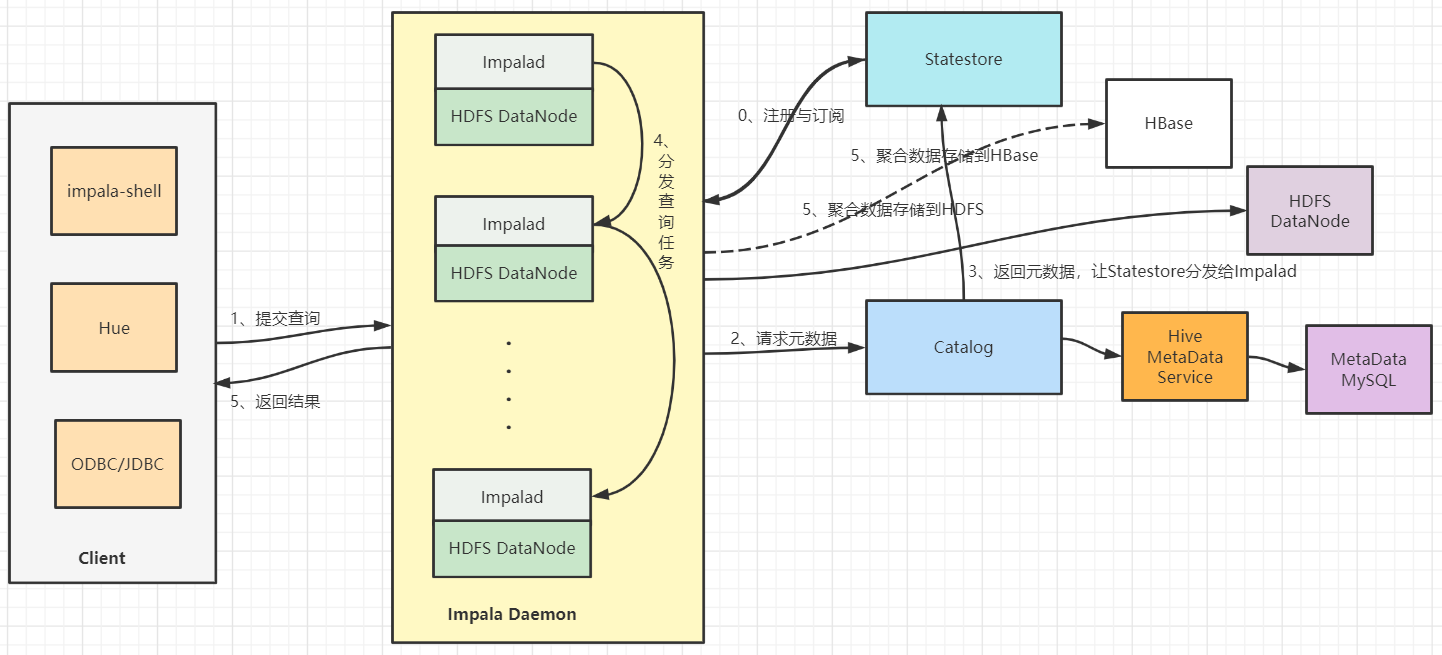
一张图带你了解全貌:
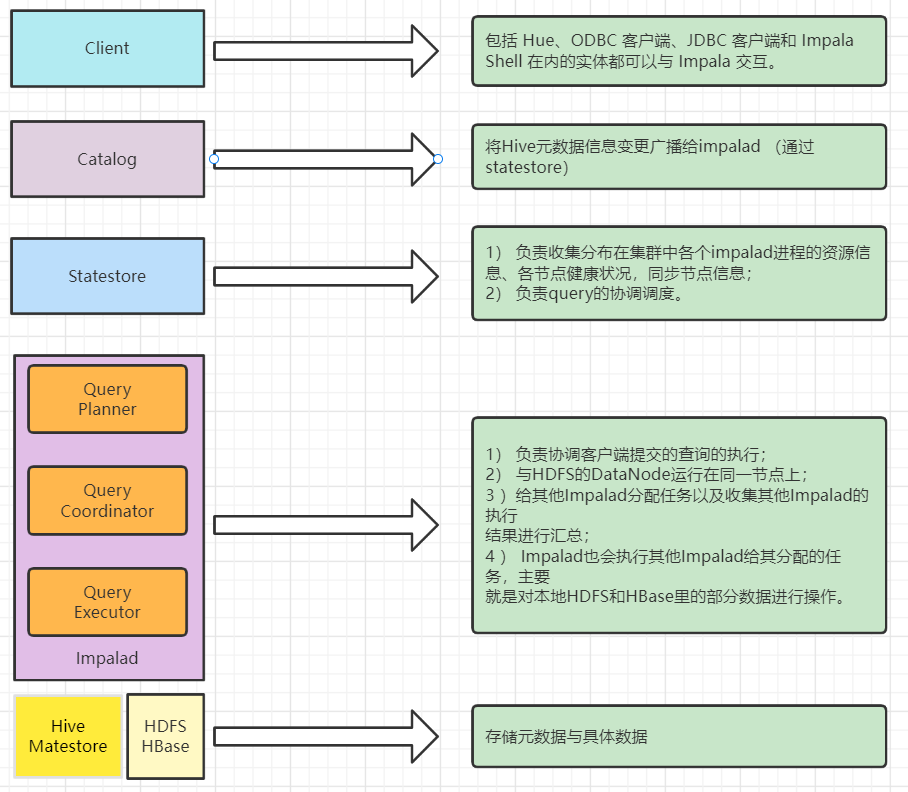
下面的概述更官方
客户端——包括 Hue、ODBC 客户端、JDBC 客户端和 Impala Shell 在内的实体都可以与 Impala 交互。这些接口通常用于发出查询或完成管理任务,例如连接到 Impala。
Impala的核心组件是Impala守护进程,它的物理代表是impalad进程。Impala守护进程的几个关键功能是:
【温馨提示】
Statestore服务主要负责metadata的广播,检查集群中所有Impala守护进程的健康状况,并不断地将其发现传递给每一个这些守护进程。它在物理上由一个名为stateststored的守护进程表示。该进程只需要在集群中的一台主机上运行。如果一个Impala守护进程由于硬件故障、网络错误、软件问题或其他原因而离线,StateStore会通知所有其他的Impala守护进程,这样以后的查询就可以避免向这个不可达的Impala守护进程发出请求。
Catalog 服务负责metadata的获取和DDL的执行,将Impala SQL语句的元数据更改传递给集群中的所有Impala守护进程。它在物理上由一个名为catalogd的守护进程表示。该进程只需要在集群中的一台主机上运行。因为请求是通过StateStore守护进程传递的,所以在同一主机上运行StateStore和Catalog服务是更好的。
当通过Impala发出的语句执行元数据更改时,catalog服务避免发出REFRESH和INVALIDATE METADATA语句。当你通过Hive创建表、加载数据等等时,在执行查询之前,你需要在Impala守护进程上发出REFRESH或INVALIDATE元数据。
- HBase或HDFS——用于存储要查询的数据。
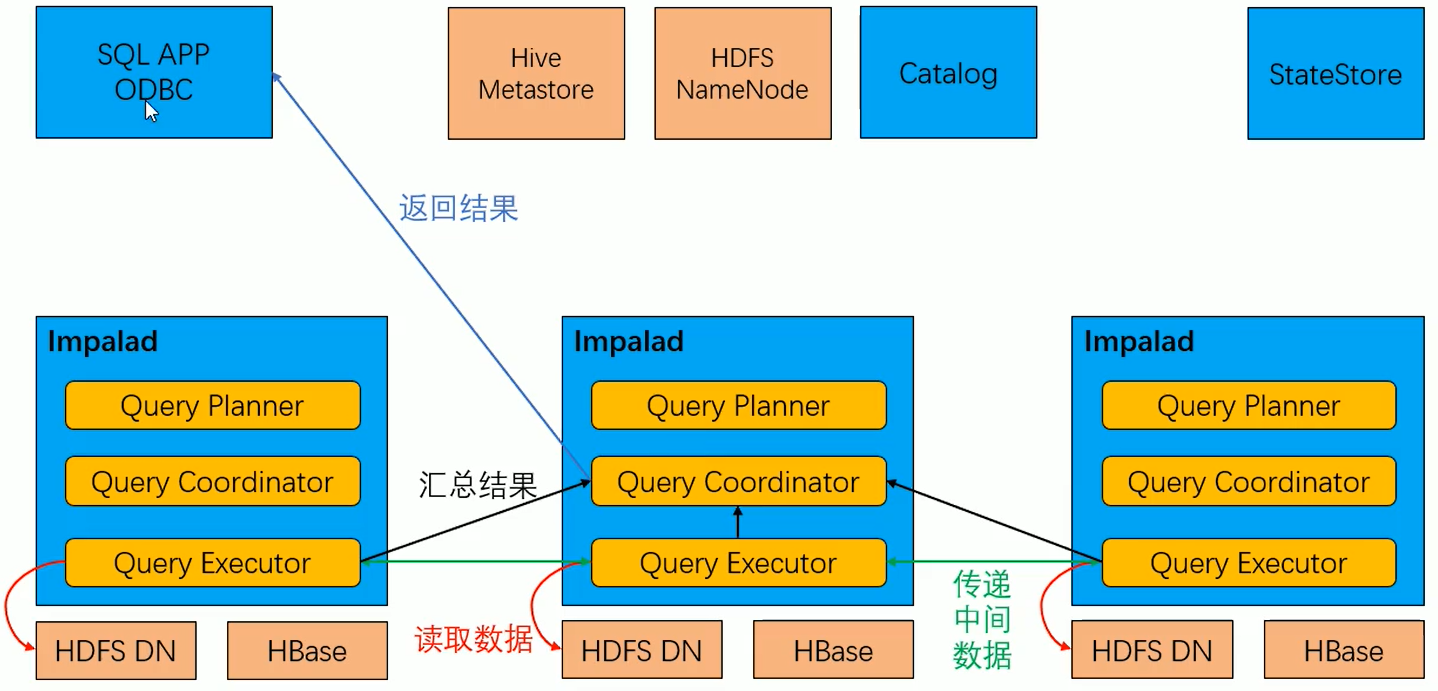
Impala的核心进程Impalad,部署在所有的数据节点上,接收客户端的查询请求,读写数据,并行执行来自集群中其他节点的查询请求,将中间结果返回给调度节点。调用节点将结果返回给客户端。Impalad进程通过持续与StateStore通信来确认自己所在的节点是否健康以及是否可以接受新的任务请求。



这里通过CM安装方式集成到CDH,方便管理,CDH的安装可以看我之前的文章:
大数据Hadoop之——Cloudera Hadoop(CM 6.3.1+CDH 6.3.2环境部署)

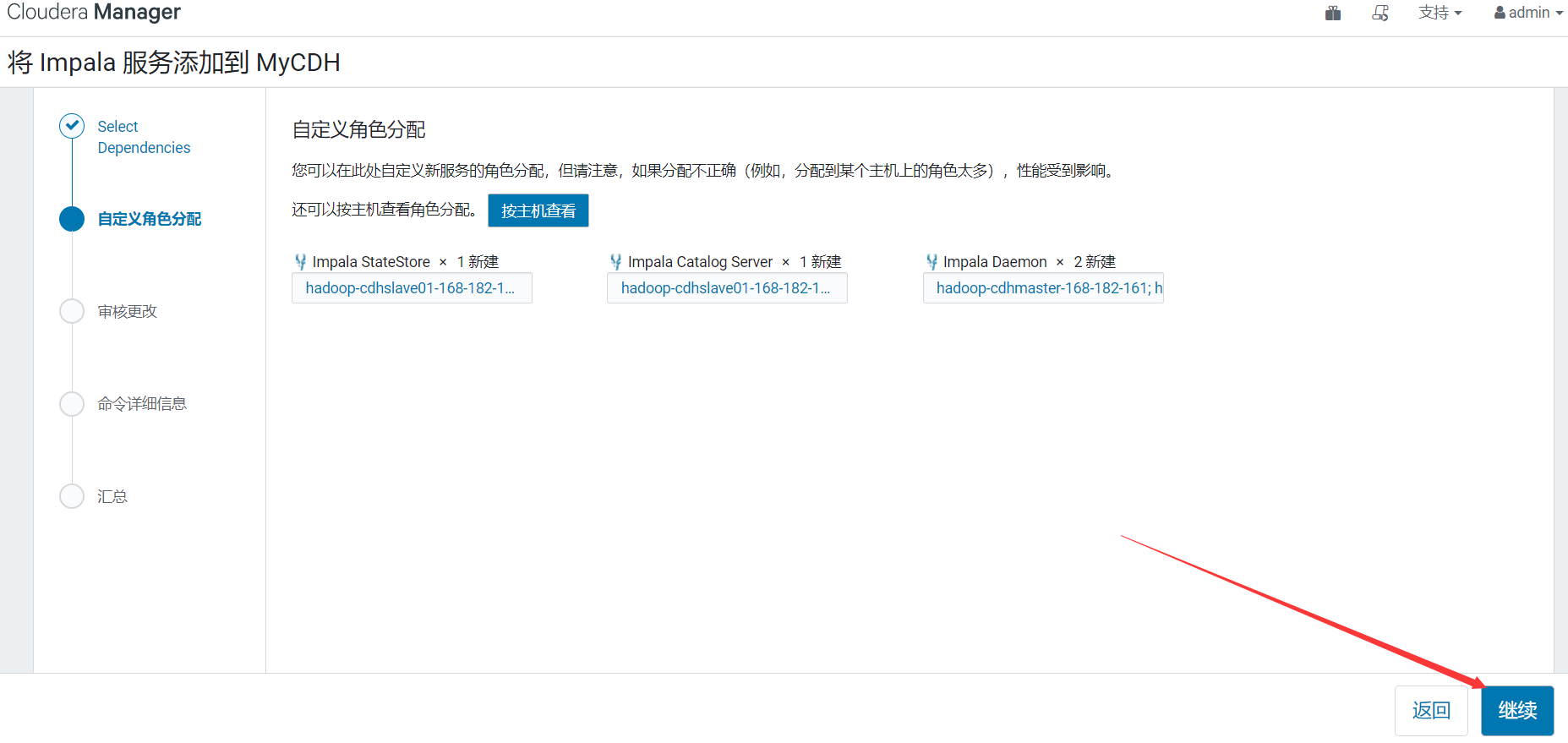

下一步就进入自动安装过程,时间有点久,耐心等待安装完即可
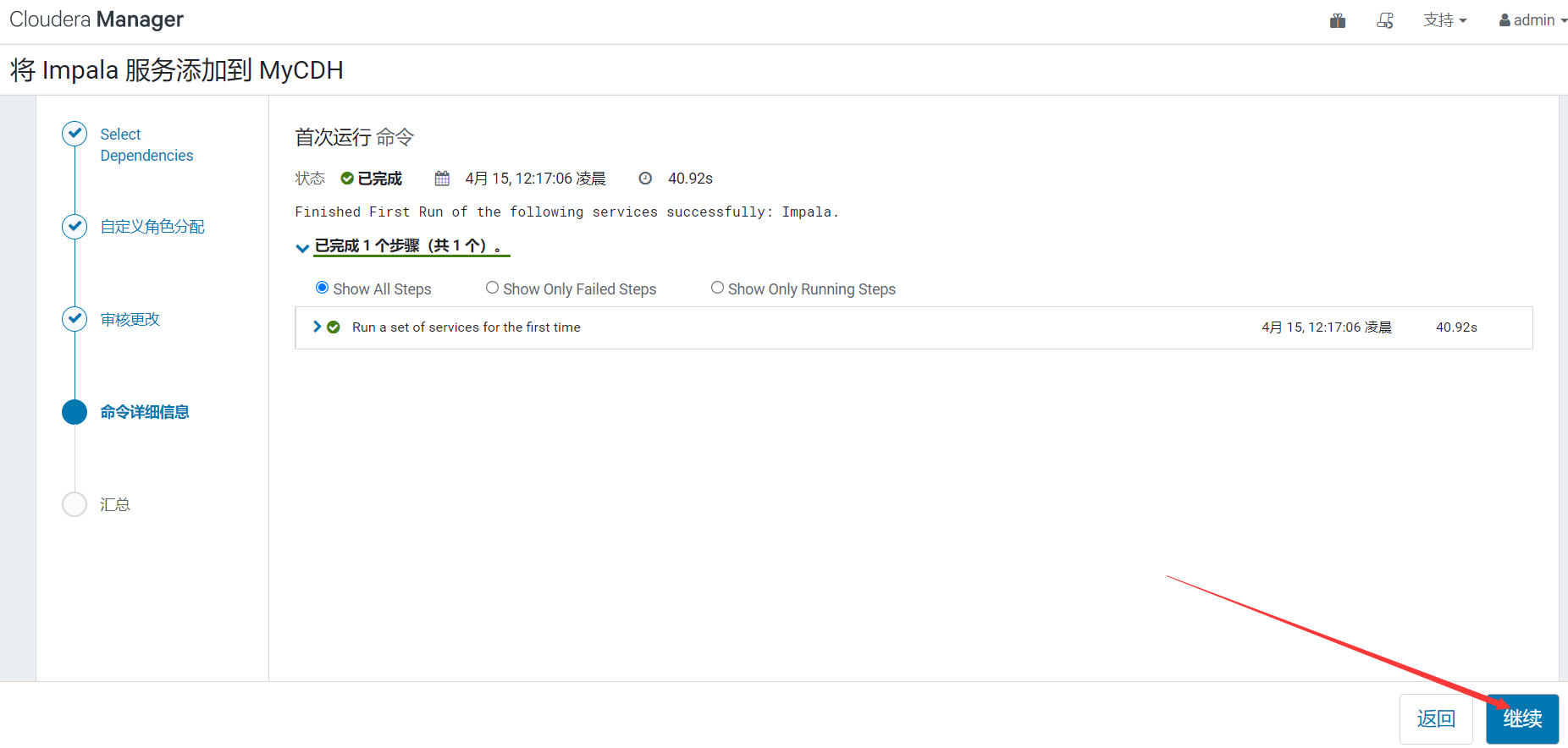

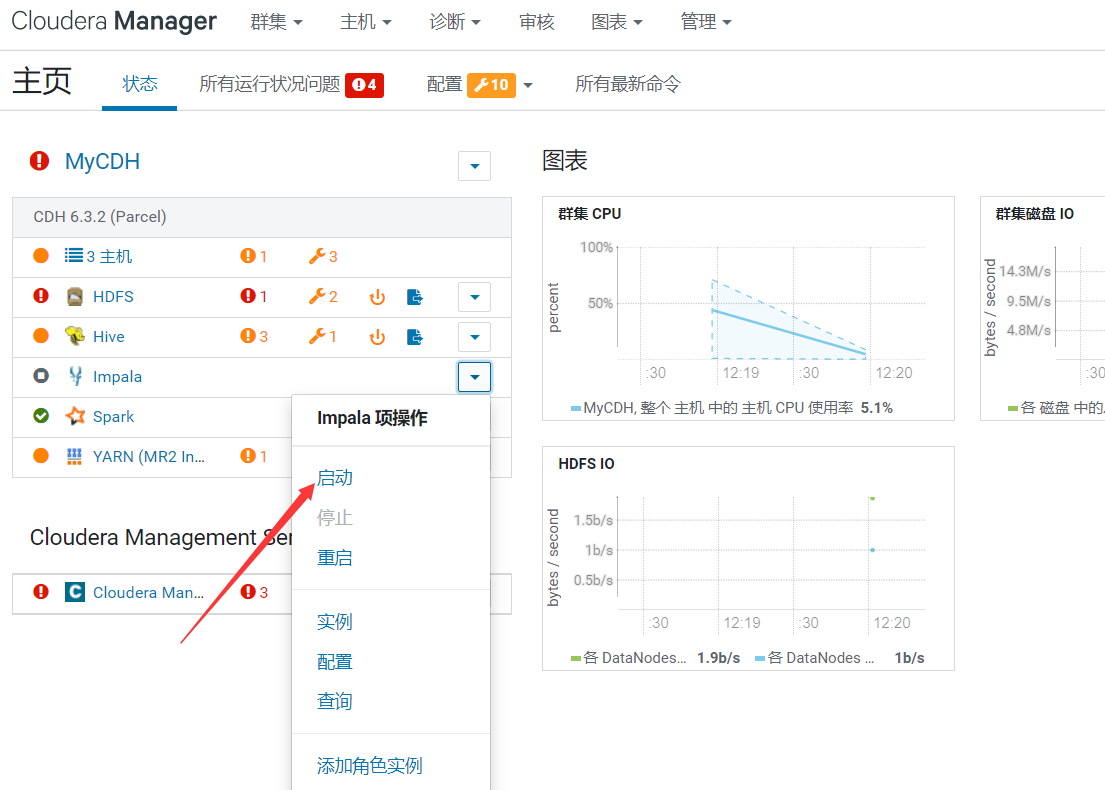

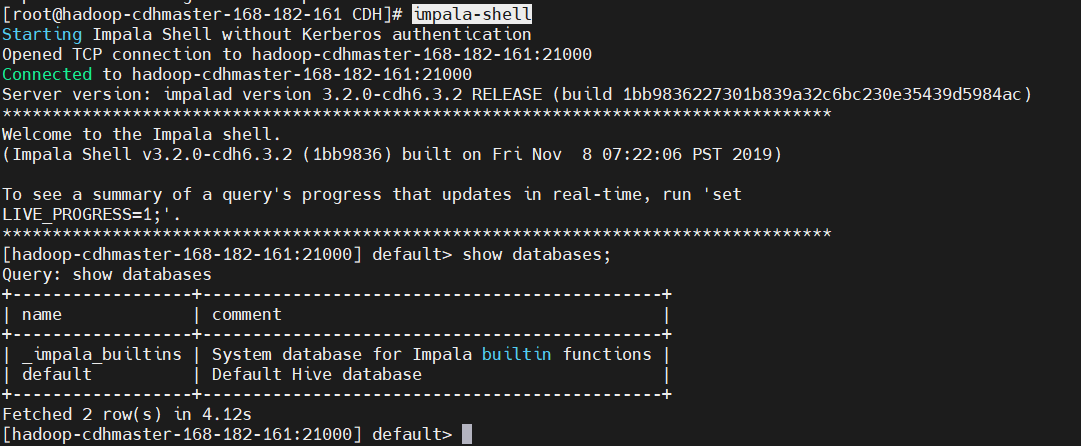
$ impala-shell
show databases
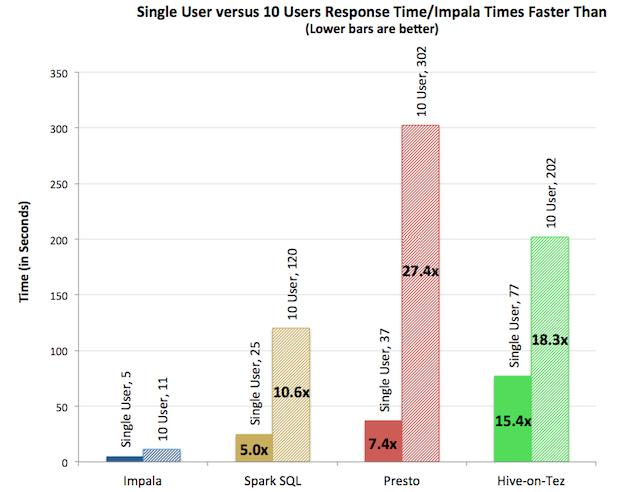
多用户如下图所示(引用自Apache Impala官网):
查询吞吐率如下图所示(引用自Apache Impala官网):
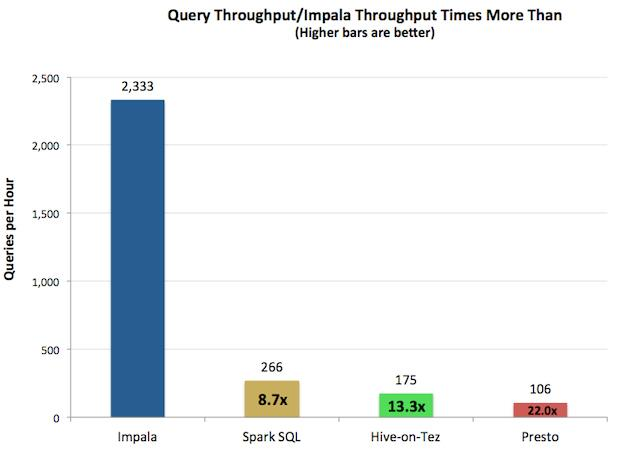
由上图测试结果可知,对于单用户查询,Impala比其它方案最多快13倍,平均快6.7倍。对于多用户查询,差距进一步拉大:Impala比其它方案最多快27.4倍,平均快18倍。
标红的就是常用的
| 选项 | 描述 |
|---|---|
| -h, --help | 显示帮助信息 |
| -v or --version | 显示版本信息 |
| -i hostname, impalad=hostname | 指定连接运行impalad守护进程的主机。默认端口是21000 |
-q query, --query=query |
从命令行中传递一个shell命令。执行完这一语句后 |
| shell会立即退出。非交互式 | |
-f query_file,--query_file=query_file |
传递一个文件中的SQL查询。文件内容必须以分号分隔 |
| -o filename or --output_file_filename | 保存所有查询结果到指定的文件。通常用于保存在命令行使用-q选项执行单个查询时的查询结果 |
| -c | 查询执行失败时继续执行 |
| -d default_db or --default_db=default_db | 指定启动后使用的数据库,与建立连接后使用use语句选择数据库作用相同,如果没有指定,那么使用default数据库d |
-p, --show_profiles |
对shell中执行的每一个查询,显示其查询执行计划 |
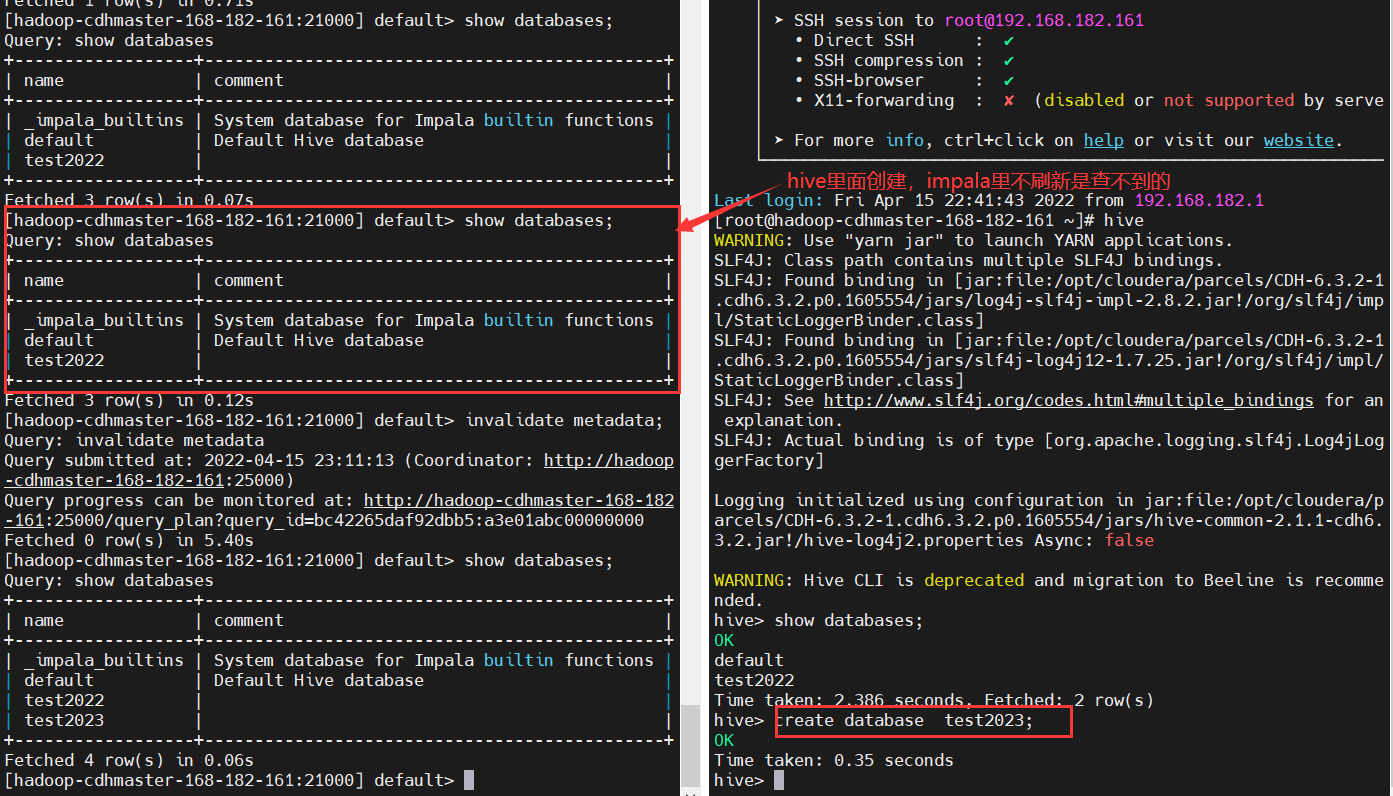
-r or --refresh_after_connect |
建立连接后刷新 Impala 元数据,新版已经没有这个参数了。换成这样刷新:impala-shell -q "invalidate metadata",不刷新的话,就看不到新创建的库表了。 |
| -B (--delimited) | 去格式化输出 |
| --output_delimiter=character | 指定分隔符 |
| --print_header | 打印列名 |
操作都是很简单,查看帮忙执行几个例子演示一下就行,这就不再演示了。主要是sql操作,sql的话,懂编程的人,应该对sql不陌生,也不是很难。
标红的就是常用的
| 选项 | 描述 |
|---|---|
| help | 查看帮助信息 |
| explain |
显示执行计划 |
| profile | (查询完成后执行)查询最近一次查询的底层信息 |
shell <shell> |
不退出impala-shell执行shell命令 |
| version | 显示版本信息(同于impala-shell -v) |
| connects | 连接 impalad 主机,默认端口 21000(同于 impala-shell -i) |
refresh <tablename> |
增量刷新元数据库 |
invalidate metadata |
全量刷新元数据库(慎用) |
| history | 查看历史命令 |
| Hive数据类型 | Impala数据类型 | 长度 |
|---|---|---|
| TINYINT | TINYINT | 1 byte有符言整数 |
| SMALINT | SMALINT | 2 byte有符号整数 |
| INT | INT | 4 byte有符号整数 |
| BIGINT | BIGINT | 8 byte有符号整数 |
| BOOLEAN | BOOLEAN | 布尔类型,true或者false |
| FLOAT | FLOAT | 单精度浮点数 |
| DOUBLE | DOUBLE | 双精度浮点数 |
| STRINGS | STRINGS | 字符系列。可以指定字符集。可以使用单引号或者双引号。 |
| TIMESTAMPS | TIMESTAMPS | 时间类型 |
| BINARY | 不支持 | 字节数组 |
【温馨提示】Impala虽然支持array, map, struct复杂数据类型,但是支持并不完全,一般处理方法,将复杂类型转化为基本类型,通过hive创建表。
都是一些很基础的操作
create database db_name
【温馨提示】Impala不支持WITH DBPROPERTIE...语法
show databases;
drop database db_name
【温馨提示】Impala不支持修改数据库(alter database )
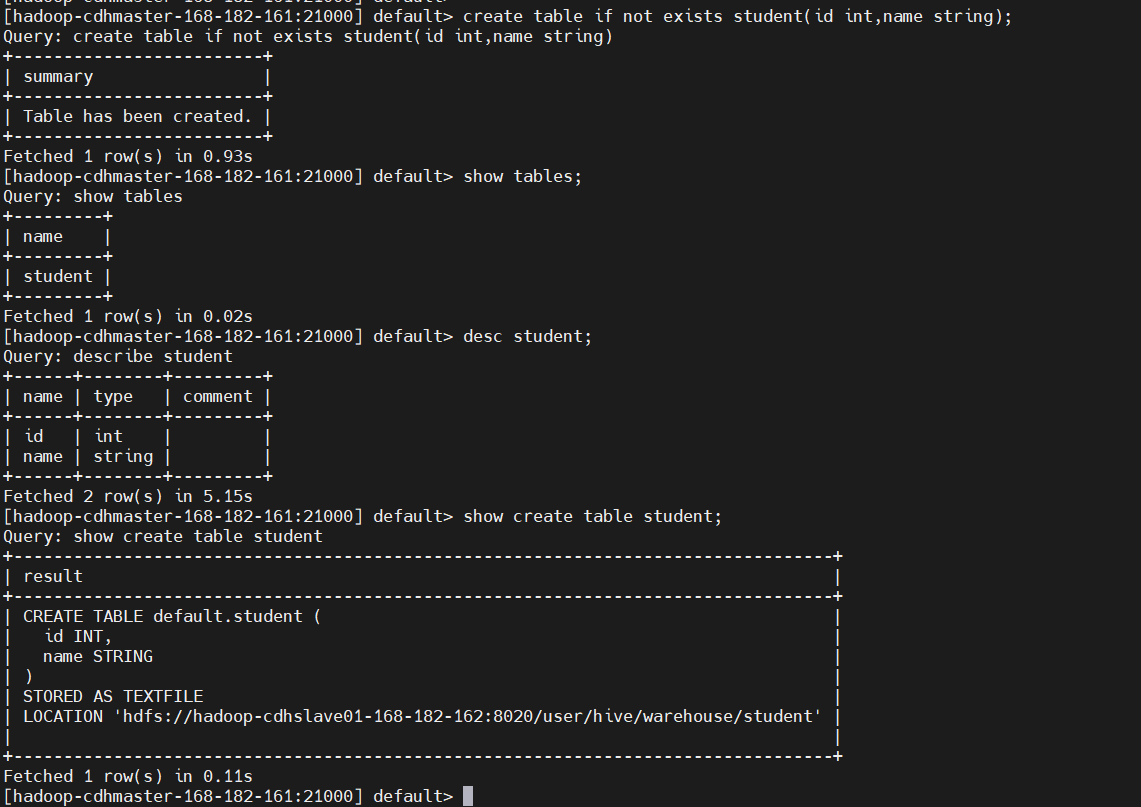
create table if not exists student(id int,name string);
show tables;
desc student;
show create table student;
create table stu_partion(id int,name string)
partitioned by (month string)
row format delimited
fields terminated by '\t'
show tables;
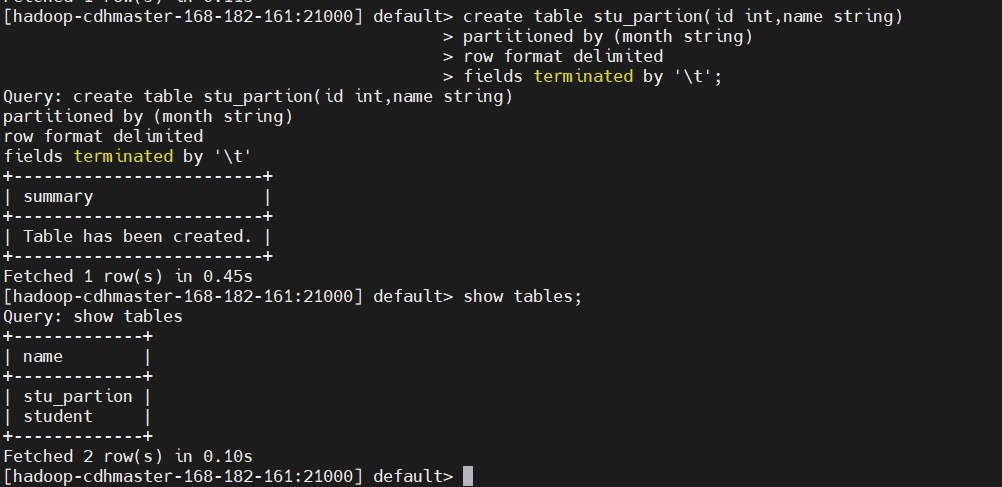
# 文件字段一tab分隔,上面创建表时定义了分隔符
$ cat > /tmp/student.txt << EOF
1 stu1
2 stu2
3 stu3
4 stu4
EOF
$ sudo -u hdfs hadoop fs -put /tmp/student.txt /tmp/
# 授权,要不然没有权限
$ sudo -u hdfs hadoop fs -chown impala:hive /tmp/student.txt
$ impala-shell
# 【温馨提示】hdfs集群上更改权限之后,一定要记住登录到impala-shell上使用invaladate metadata命令进行元数据更新,否则更改的权限在impala状态下是不生效的!!!,执行下面这句就行了。
invalidate metadata;
# 添加分区
alter table stu_partion add partition (month='20220415');
# 删除分区,这里不执行
alter table stu_partion drop partition (month='20220415');
# 加载数据,加载完,这个文件/tmp/student.txt会被删掉
load data inpath '/tmp/student.txt' into table stu_partion partition (month='20220415');
# 查看检查
select * from stu_partion;

【温馨提示】如果分区没有,load data 导入数据时,不能自动创建分区。还有就是不能到本地数据,只能到hdfs上的数据。
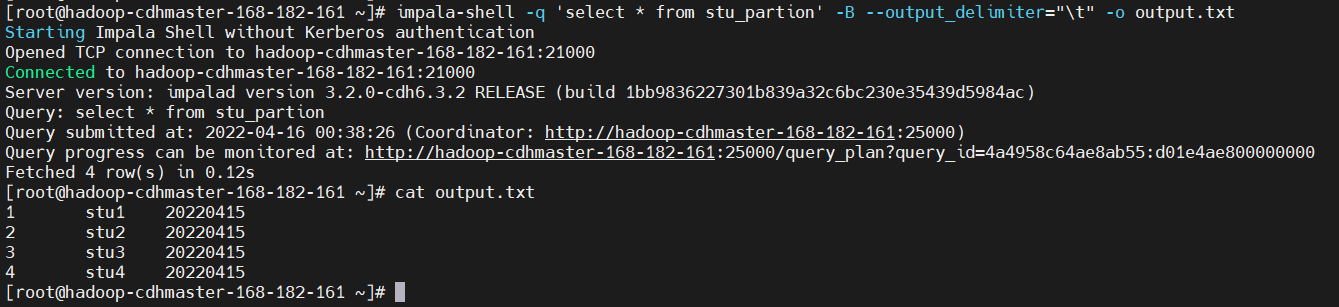
impala 数据导出一般使用impala -o
$ impala-shell -q 'select * from stu_partion' -B --output_delimiter="\t" -o output.txt
一般DML由hive来操作,impala负责查询。
因为查询sql跟mysql的一样,所以这里就不演示了。
跟hive和mysql函数差不多,像count、sum等内置函数,当然也支持自定义函数。有兴趣的小伙伴可以去练习一下,比较简单。
impala的简单使用就到这里了,有疑问的话,欢迎给我留言,后续会更新更多关于大数据的文章,请耐心等待~
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e