问题:
互联网应用中,随着站点对硬件性能,响应速度、服务稳定性、数据可靠性等要求越来越高,单台服务器已经无法满足负载均衡及高可用的要求
解决方法:
• 使用价格昂贵的小型机、大型机
• 使用多台相对廉价的普通服务器构建服务群集
在企业中常用的一种群集技术–LVS(Linux virtual server,linux虚拟服务器)
注:通过整合多台服务器,使用LVS来达到服务器的高可用和负载均衡,并以同一个IP地址对外提供相同的服务
例如 “故障切换” “双机热备” 等
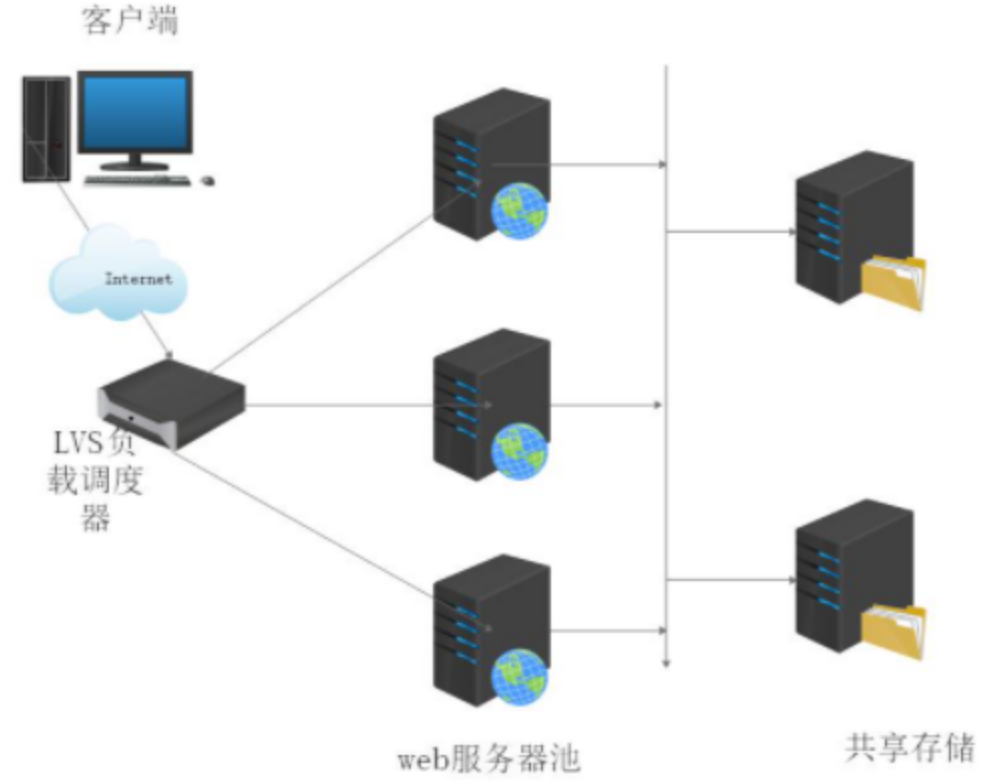
负载均衡群集是目前企业用的最多的群集类型
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP)。真实服务器响应完请求后,查看默认路由,把响应后的数据包发送给负载均衡器,负载均衡器在接收到响应包后,把包的源地址改成虚拟地址(VIP)然后发送回给客户端
优点:集群中的服务器可以使用任何支持TCP/IP的操作系统,只要负载均衡器有一个合法的IP地址
缺点:扩展性有限,当服务器节点增长过多时,由于所有的请求和应答都需要经过负载均衡器,因此负载均衡器将成为整个系统的瓶颈
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求报文封装一层IP隧道(T-IP)转发到真实服务器(RS)。真实服务器响应完请求后,查看默认路由,把响应后的数据包直接发送给客户端,不需要经过负载均衡器
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,也能处理很巨大的请求量
缺点:隧道模式的RS节点需要合法IP,这种方式需要所有的服务器支持“IP Tunneling”
原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后负载均衡器就把客户端发送的请求数据包的目标MAC地址改成后端真实服务器的MAC地址(R-MAC)。真实服务器响应完请求后,查看默认路由,把响应后的数据包直接发送给客户端,不需要经过负载均衡器
优点:负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,也能处理很巨大的请求量
缺点:需要负载均衡器与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境
Linux Virtual Server 是针对 Linux 内核开发的一个负载均衡项目,LVS 实际 上相当于基于 IP 地址的虚拟化应用,为基于 IP 地址和内容请求分发的负载均衡提出了一种 高效的解决方法。
LVS 现在已成为 Linux 内核的一部分,默认编译为 ip_vs 模块,必要时能够自动调用。 在 CentOS 7 系统中,以下操作可以手动加载 ip_vs 模块,并查看当前系统中 ip_vs 模块的 版本信息。
modprobe ip_vs #手动加载ip_vs模块
cat /proc/net/ip_vs #查看当前ip_vs模块版本信息将收到的访问请求按照顺序轮流分配给群集中的各节点(真实服务器),均等地对待每一台服务器,而不是服务器实际的连接数和系统负载
根据调度设置的权重值来分发请求,权重值高的节点优先获得任务,分配的请求数越多,保证性能强的服务器承担更多的访问流量
根据真实服务器已建立的连接进行分配,将收到的访问请求优先分配给连接数最少的节点
在服务器节点的性能差异较大时,可以为真实服务器自动调整权重,性能较高的节点承担更大比例的活动连接负载
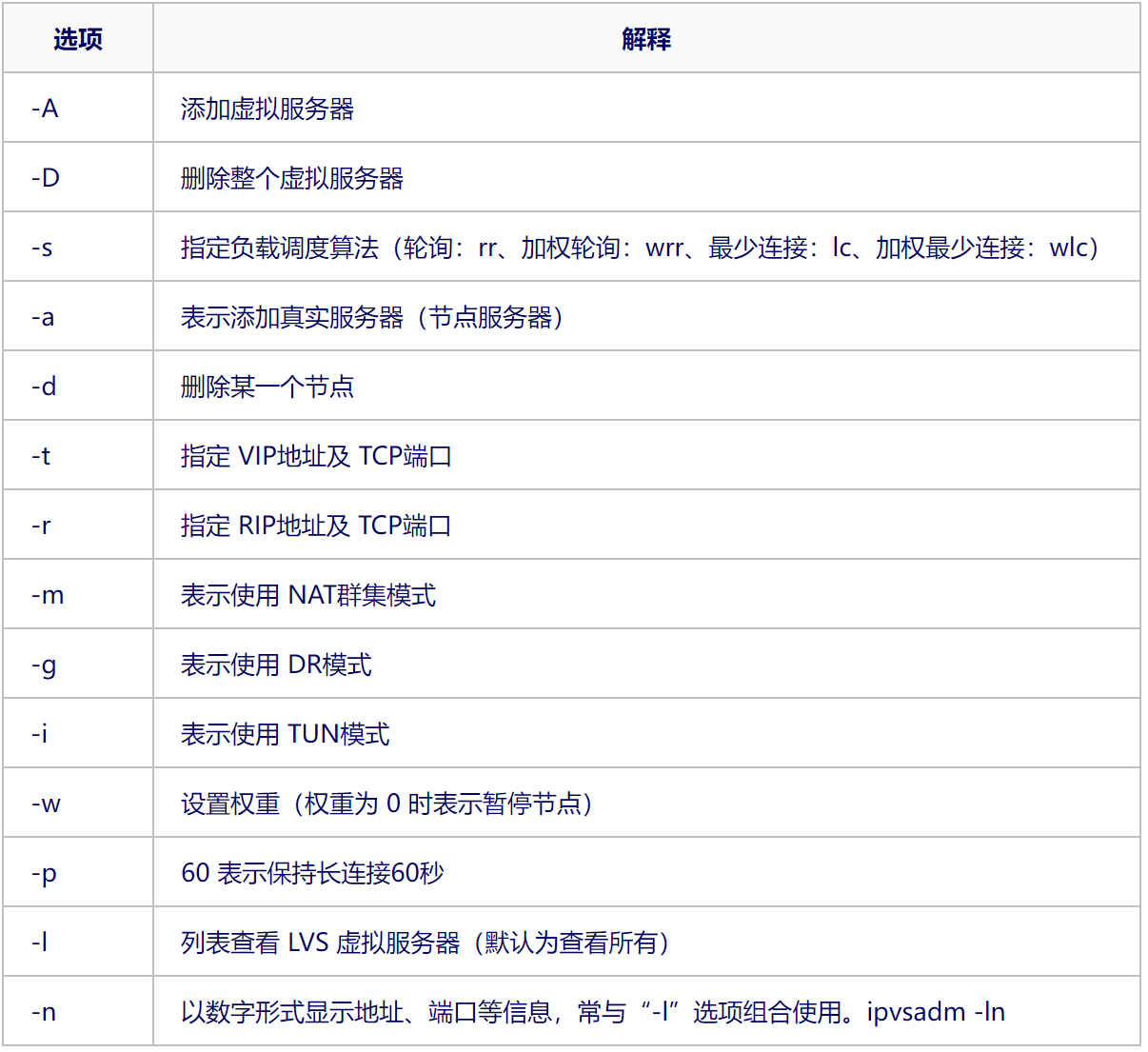
ipvsadm 工具选项说明:
常用术语解释:
CIP:Client IP,表示的是客户端 IP 地址。
VIP:Virtual IP,表示负载均衡对外提供访问的 IP 地址,一般负载均衡 IP 都会通过 Virtual IP 实现高可用。
RIP:RealServer IP,表示负载均衡后端的真实服务器 IP 地址。
DIP:Director IP,表示负载均衡与后端服务器通信的 IP 地址。
CMAC:客户端的 MAC 地址,准确的应该是 LVS 连接的路由器的 MAC 地址。
VMAC:负载均衡 LVS 的 VIP 对应的 MAC 地址。
DMAC:负载均衡 LVS 的 DIP 对应的 MAC 地址。
RMAC:后端真实服务器的 RIP 地址对应的 MAC 地址。
实验环境准备:
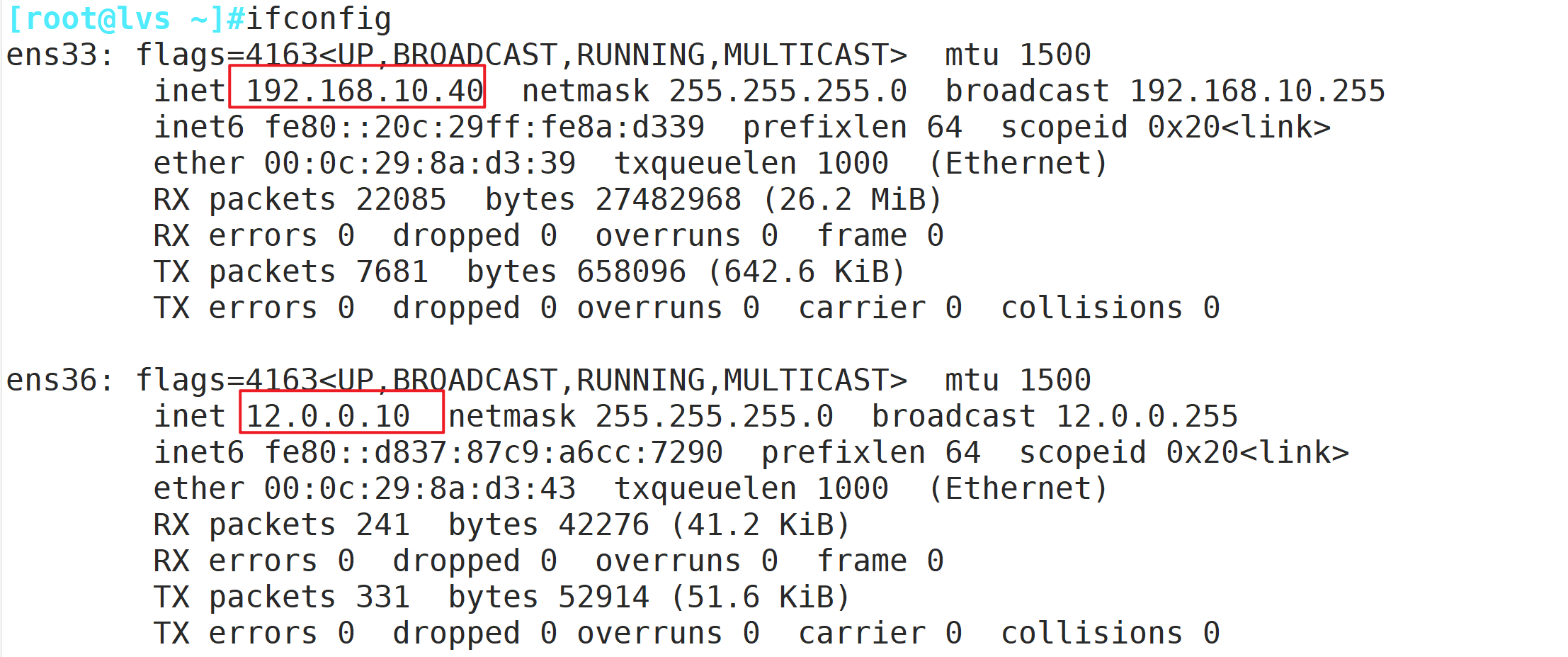
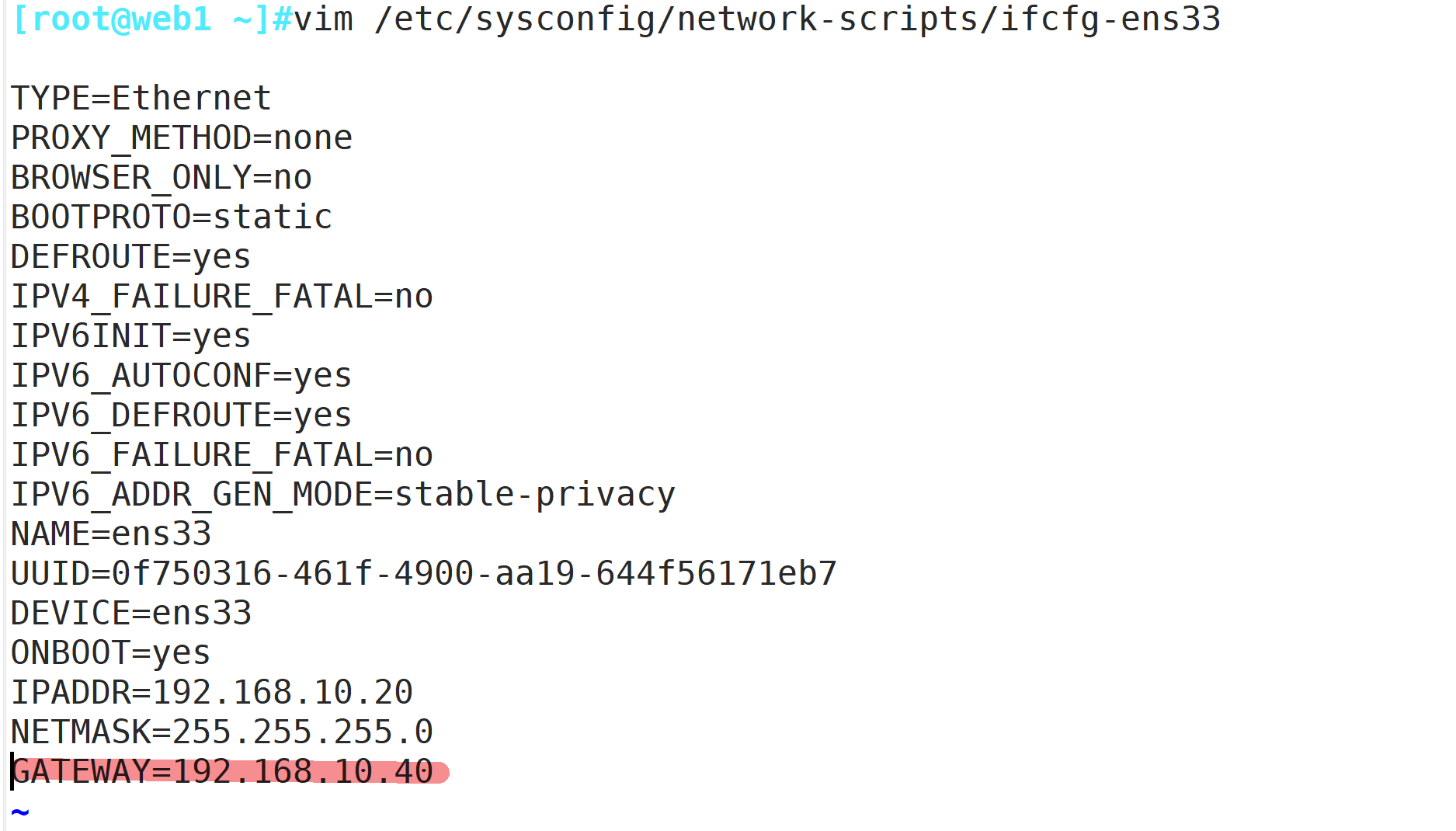
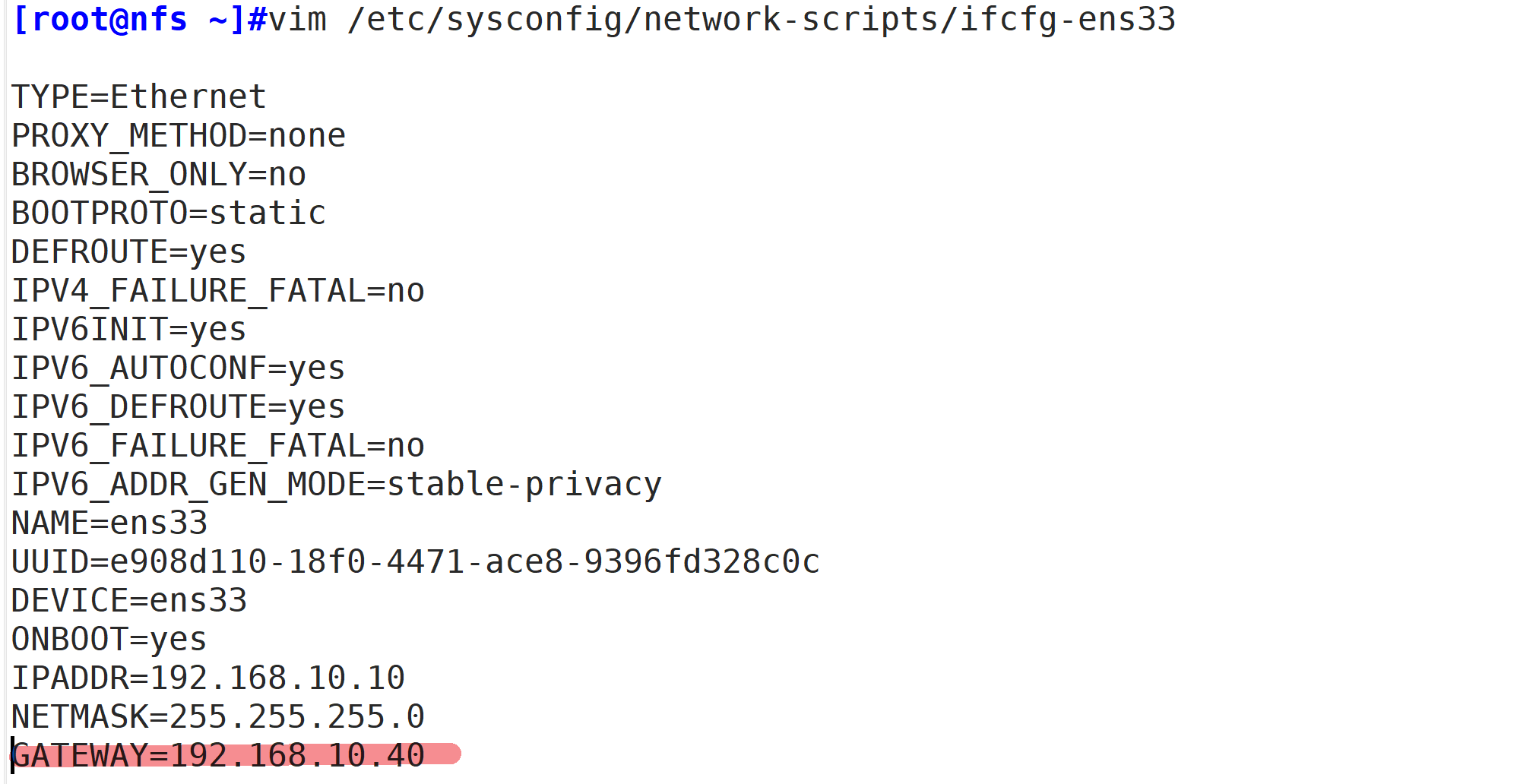
负载调度器:内网关 ens33:192.168.10.40,外网关 ens37:12.0.0.1
Web节点服务器1:192.168.10.20
Web节点服务器2:192.168.10.30
NFS服务器:192.168.10.10
客户端:12.0.0.10
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
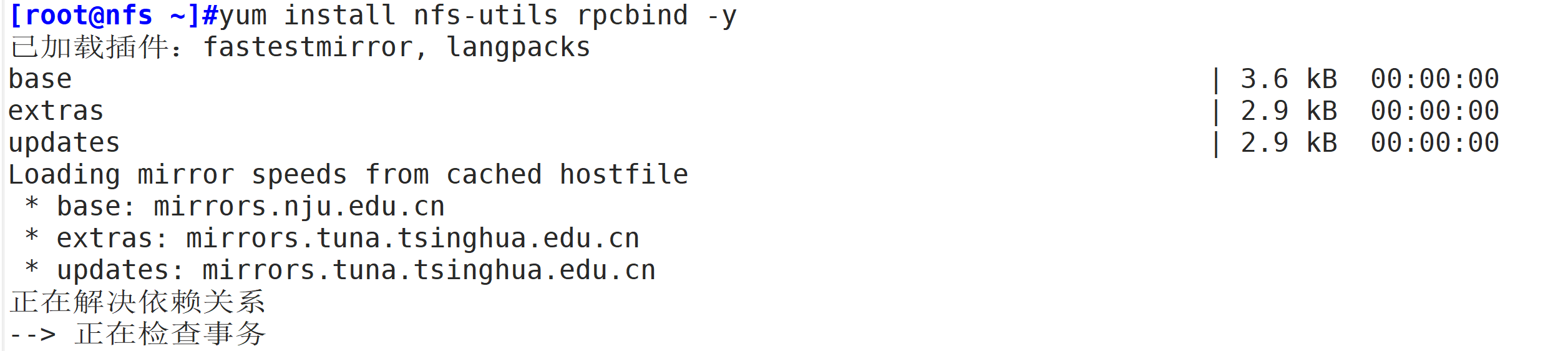
yum install nfs-utils rpcbind -y
systemctl start rpcbind.service
systemctl start nfs.service
systemctl enable rpcbind.service
systemctl enable nfs.service
mkdir /opt/fzr /opt/zzj
chmod 777 /opt/fzr /opt/zzj
echo 'this is fzr web!' > /opt/fzr/index.html
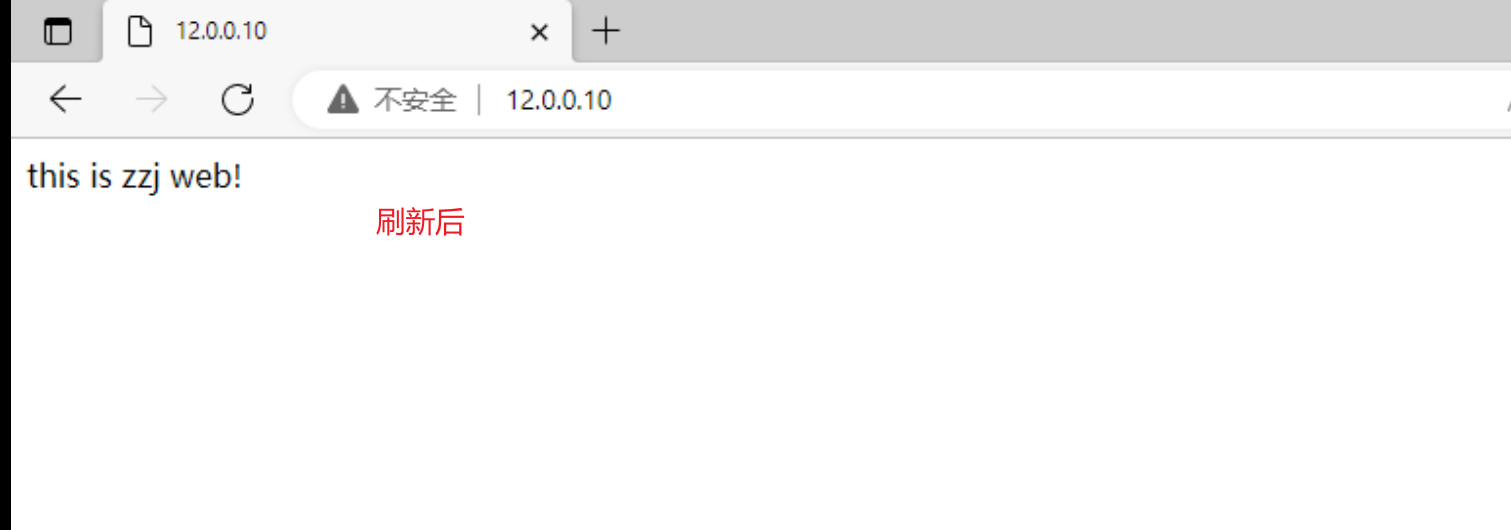
echo 'this is zzj web!' > /opt/zzj/index.html
vim /etc/exports
/opt/fzr 192.168.10.0/24(rw,sync)
/opt/zzj 192.168.10.0/24(rw,sync)
--发布共享---
exportfs -rvsystemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
yum install httpd -y
systemctl start httpd.service
systemctl enable httpd.service
yum install nfs-utils rpcbind -y
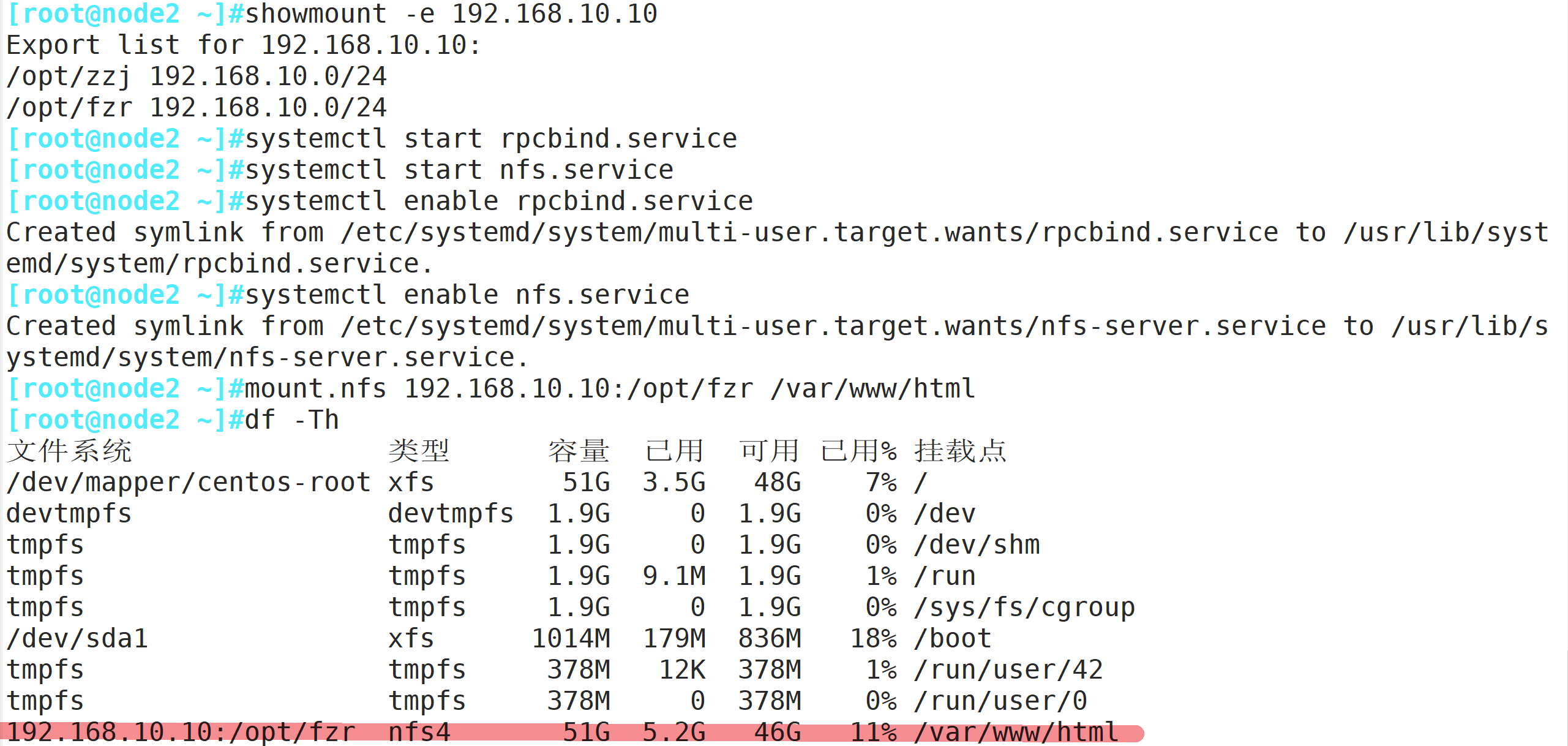
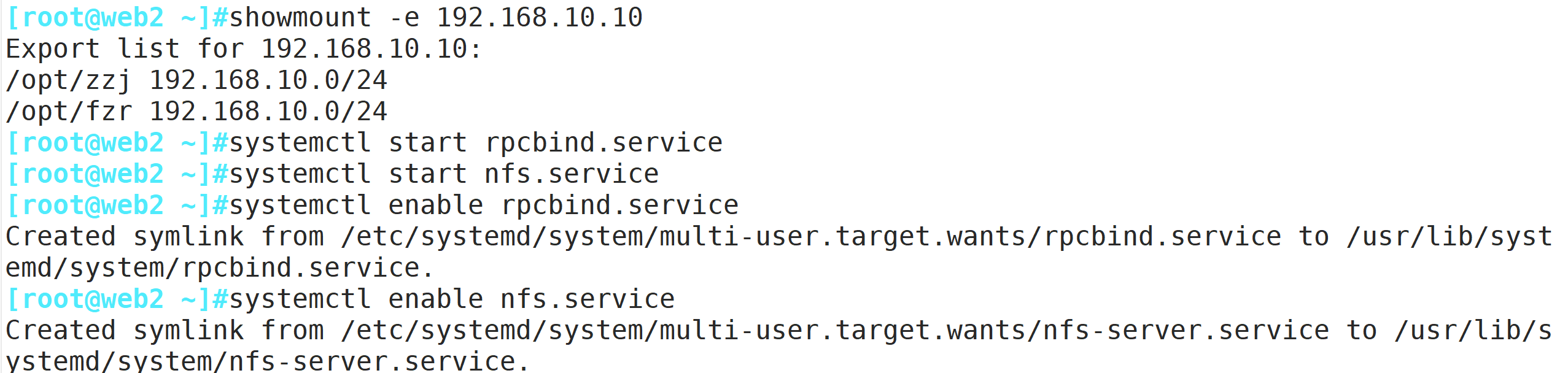
showmount -e 192.168.10.10
systemctl start rpcbind.service
systemctl start nfs.service
systemctl enable rpcbind.service
systemctl enable nfs.service
--192.168.10.20---
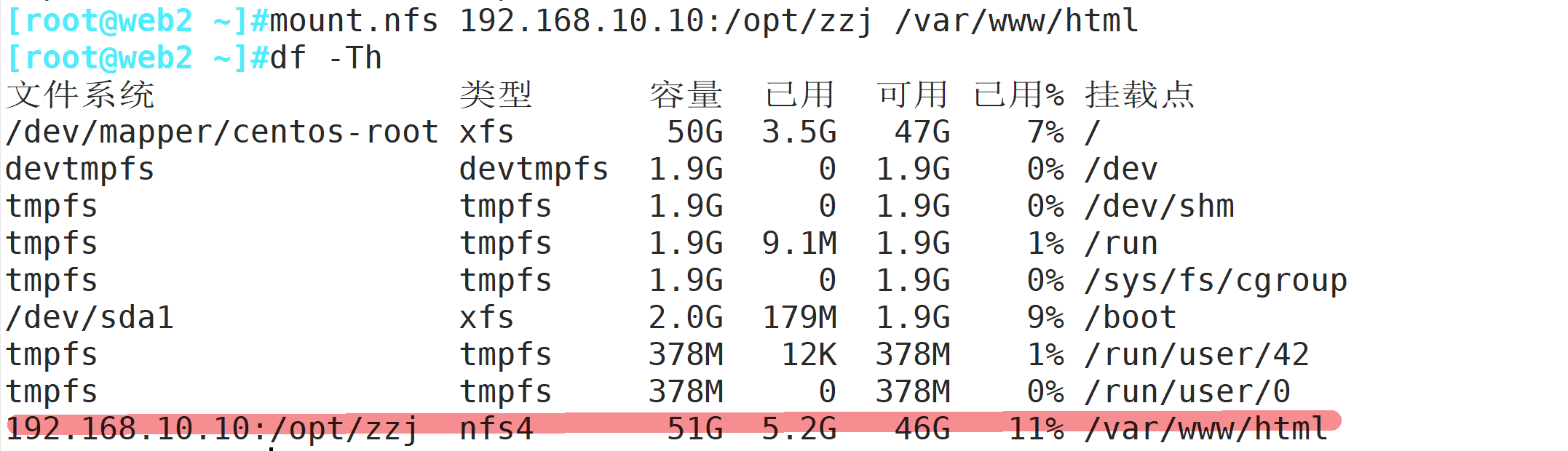
mount.nfs 192.168.10.10:/opt/fzr /var/www/html
另一台节点服务器挂载如下:
--192.168.10.30---
mount.nfs 192.168.10.10:/opt/zzj /var/www/html
systemctl stop firewalld.service
systemctl disable firewalld.service
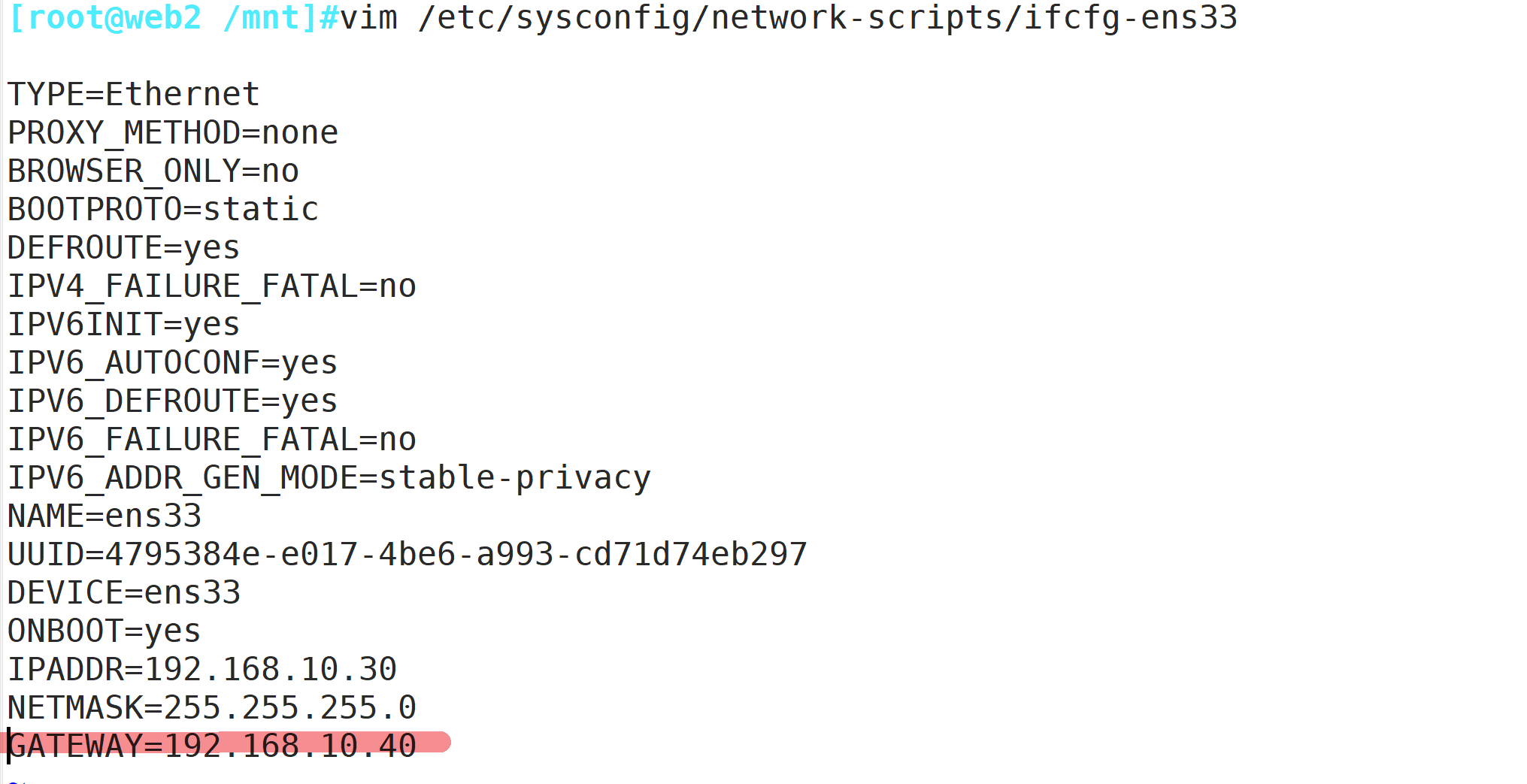
setenforce 0vim /etc/sysctl.conf
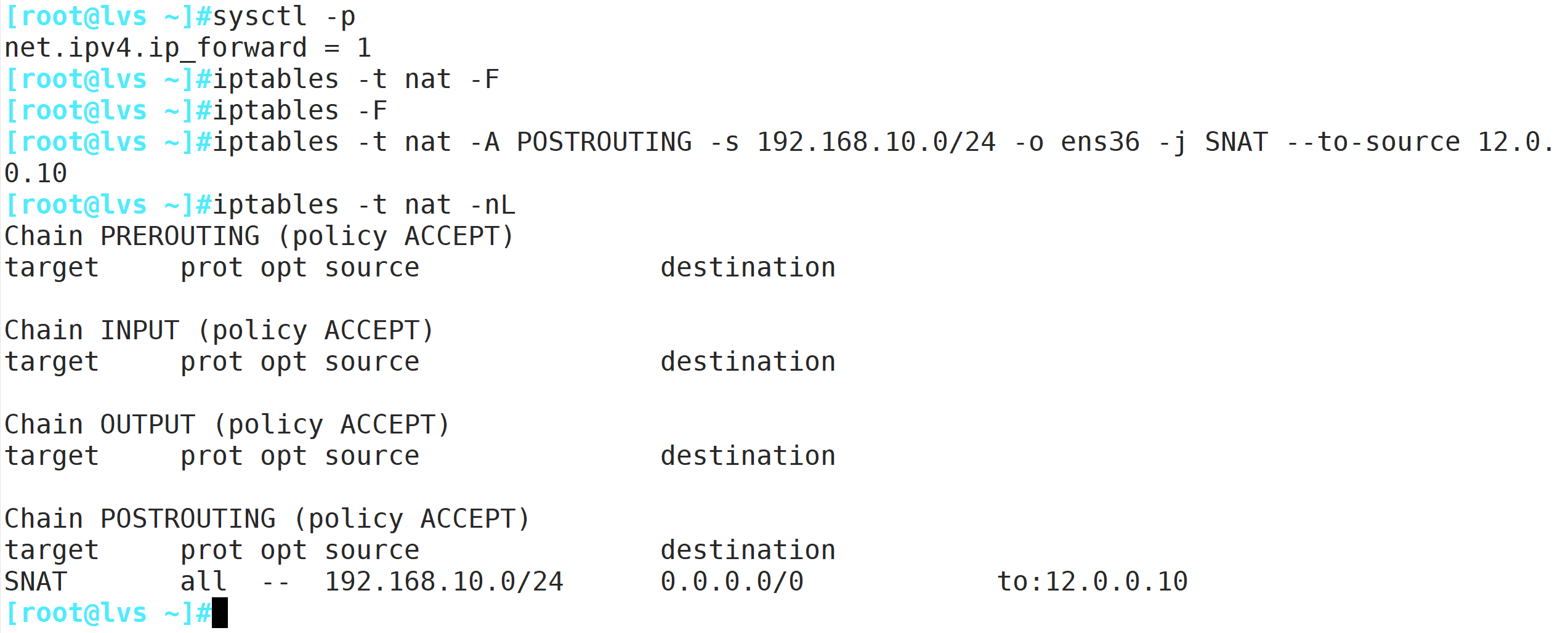
net.ipv4.ip_forward = 1 #添加ip路由转发
或 echo '1' > /proc/sys/net/ipv4/ip_forward
sysctl -p
iptables -t nat -F
iptables -F
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -o ens36 -j SNAT --to-source 12.0.0.10modprobe ip_vs #加载 ip_vs模块
cat /proc/net/ip_vs #查看 ip_vs版本信息
##加载全部模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F
filename $i >/dev/null 2>&1 && /sbin/modprobe $i;doneyum -y install ipvsadm
--启动服务前须保存负载分配策略---
ipvsadm-save > /etc/sysconfig/ipvsadm
或者 ipvsadm --save > /etc/sysconfig/ipvsadm
systemctl start ipvsadm.serviceipvsadm -C #清除原有策略
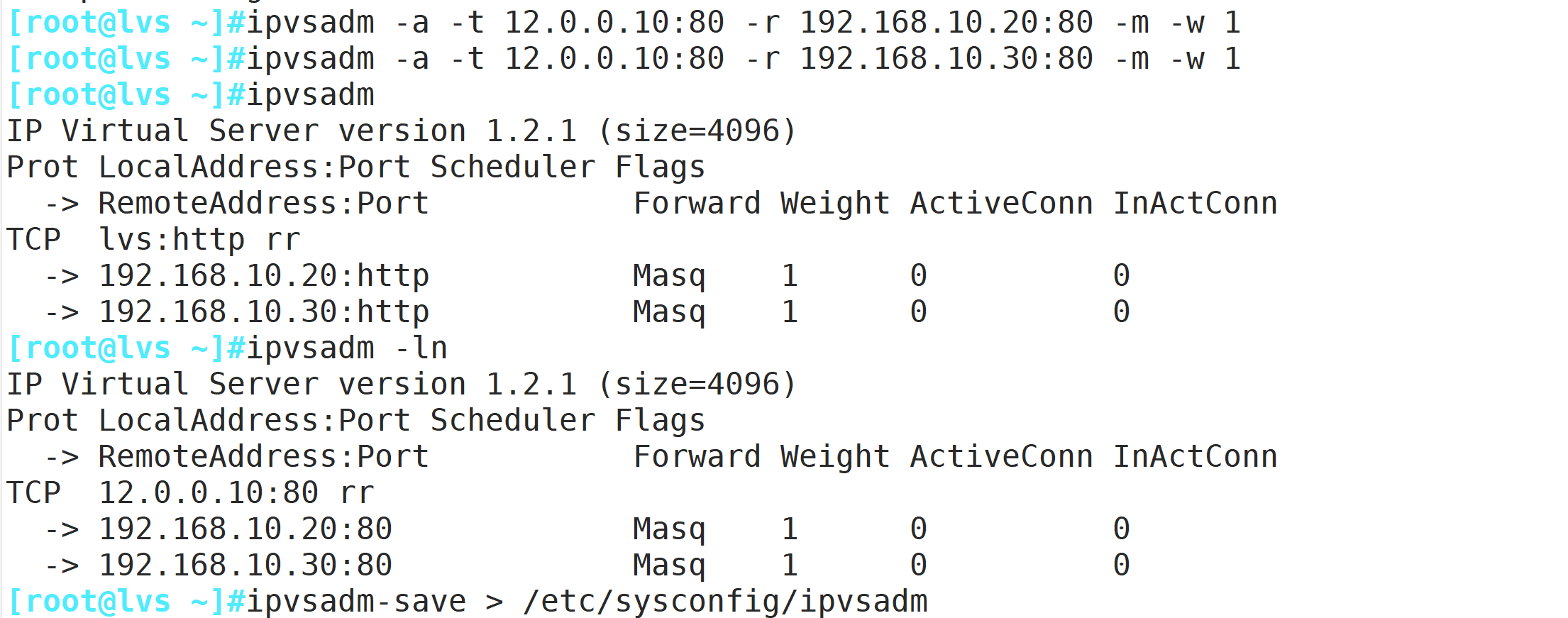
ipvsadm -A -t 12.0.0.10:80 -s rr
ipvsadm -a -t 12.0.0.10:80 -r 192.168.10.20:80 -m [-w 1] #添加真实ip
ipvsadm -a -t 12.0.0.10:80 -r 192.168.10.30:80 -m [-w 1] #添加真实ip
ipvsadm #启用策略
ipvsadm -ln #查看节点状态,Masq代表 NAT模式
ipvsadm-save > /etc/sysconfig/ipvsadm #保存策略
ipvsadm -d -t 12.0.0.1:80 -r 192.168.10.20:80 -m [-w 1] #删除群集中某一节点服务器
ipvsadm -D -t 12.0.0.1:80 #删除整个虚拟服务器
systemctl stop ipvsadm #停止服务(清除策略)
systemctl start ipvsadm #启动服务(重建规则)
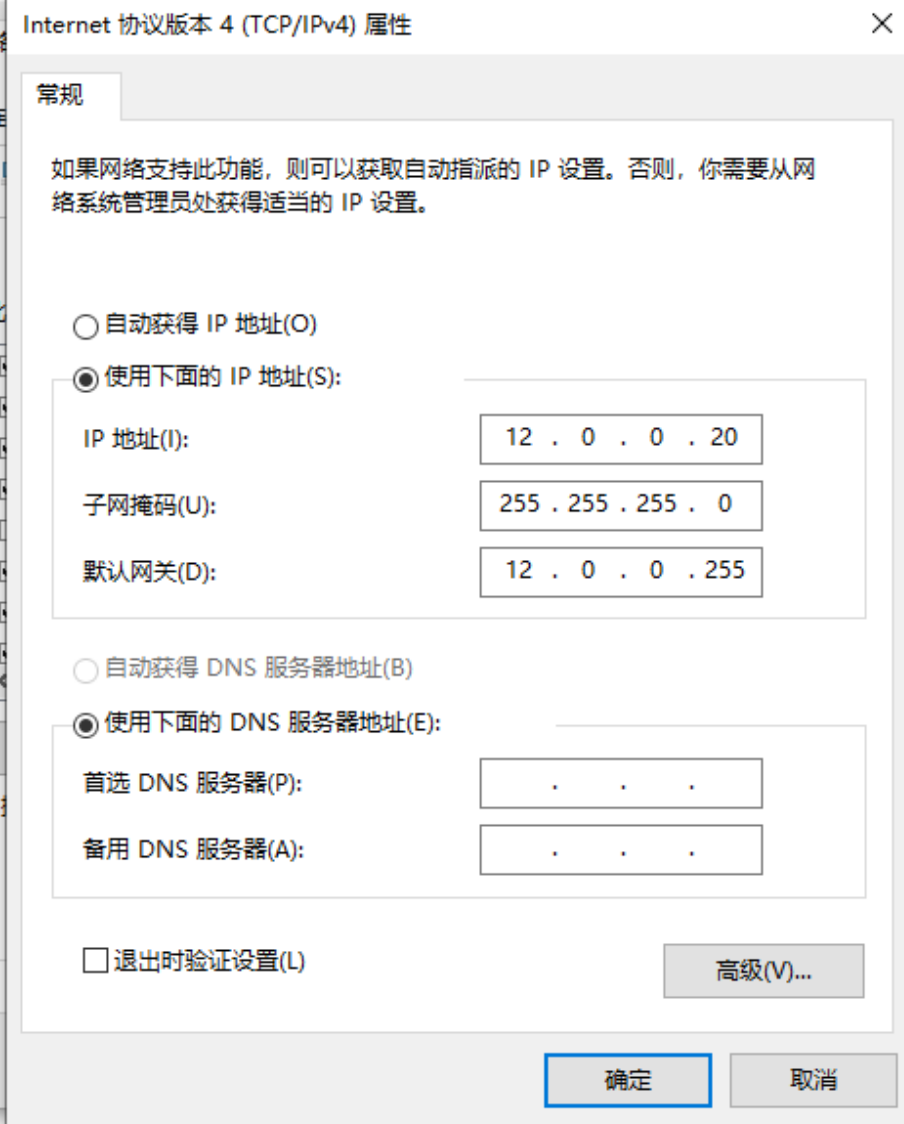
ipvsadm-restore < /etc/sysconfig/ipvsadm #恢复LVS 策略网络设置里面网关需要设置为网关服务器
在一台IP为12.0.0.10的客户机使用浏览器访问 http://12.0.0.10/ ,不断刷新浏览器测试负载均衡效果,刷新间隔需长点。
Web节点服务器1:192.168.10.20
Web节点服务器2:192.168.10.30
NFS服务器:192.168.10.10











我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
如何使用Capistrano将Rails应用程序部署到无法访问外部网络或存储库的生产或暂存服务器?我已经设法完成部署的一半,并意识到Capistrano没有在我的本地机器上下载gitrepo,但它首先连接到远程服务器并尝试在那里下载Git存储库。我希望有一个类似Javaee的构建系统,其中创建可交付成果并将该可交付成果发送到服务器。就像您构建.ear文件并将其部署到您想要的任何服务器上一样。显然在RoR中,你被迫(据我所知)在该服务器上构建应用程序,在那里创建一个gem存储库,在那里克隆最新的分支等等。有什么方法可以将准备运行的包发送到远程服务器吗? 最佳答
我有一个EC2实例正在运行。我有一个负载均衡器,它与EC2实例相关联。PingTarget:HTTP:3001/healthCheckTimeout:5secondsInterval:24secondsUnhealthythreshold:2Healthythreshold:10现在该实例显示为OutofService。我什至尝试更改监听端口等等。一切正常,直到重新启动我的EC2实例。任何帮助将不胜感激。仅供引用:我有一个在端口3001上运行的Rails应用程序,我有一个用于HTTP:80(loadbalancer)到HTTP:3001的监听器。我还在终端中通过ssh检查了正在运行的应
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用