课件获取:关注公众号 “数栈研习社”,后台私信 “Taier” 获得直播课件
视频回放:点击这里
ChunJun 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
在分享之前,先为大家介绍一下任务和实例的关系。任务指的是我们在任务开发界面上去创建的任务,比如Spark任务、SparkSQL任务、数据同步任务等,这些任务在开发过程中是静态的脚本,当被提交到计算节点去执行时,被执行的过程我们把它抽象成实例。举一个简单的例子来说明:比如我们写完一个Java的类然后把它打包成Jar包,其实这个Jar包就是一个静态类,当我们执行Jar包时,这个过程我们会把它抽象成一个实例,这就是任务与实例的关系。
首先我们来看一下Taier实例的类型,在Taier中实例主要有3种类型:
周期实例:T+1生成,完整依赖
补数据实例:立即生成,局部依赖
临时运行实例:立即生成,无依赖
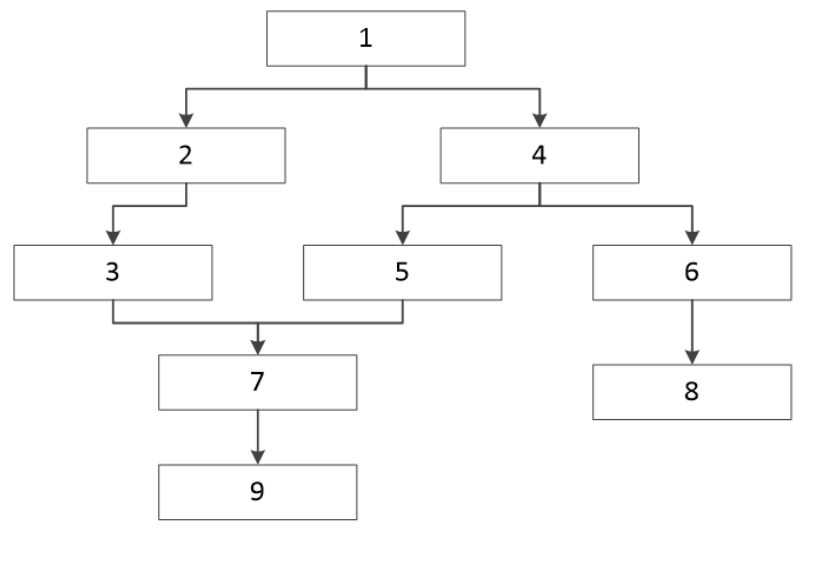
周期实例是指在前一天生成的当天实例(T+1),拥有一个完整独立的实例依赖体系,也就是任务和任务之间形成的完整的DAG图。周期实例实际上指的是离线任务,因为实时任务并无上游依赖关系。
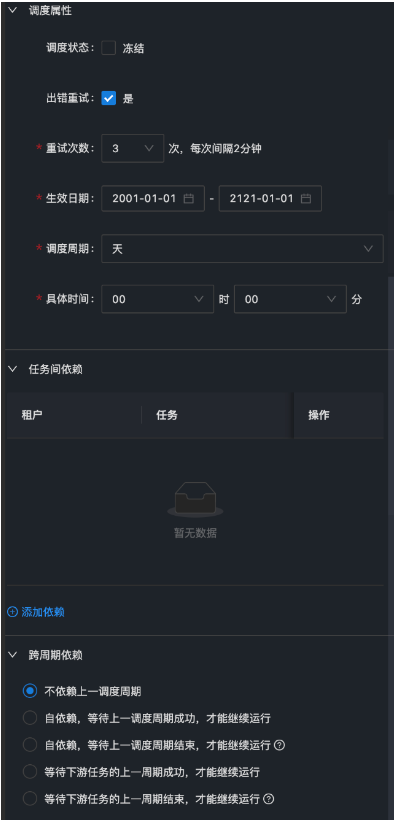
上图就是配置任务之间依赖的地方,任务和任务之间会形成一个完整DAG(Direct Acyclic Graph)图,中文名叫有向无环图,从图中任意一个节点出发,根据方向无法回到原节点的图就叫做有向无环图。
注意: 提交任务的时候回判断是否成环。
而实例依赖可分为两种:父子依赖关系和自依赖关系。
● 父子依赖关系
父子关系可以理解为不同的任务依赖:例如任务A运行需要任务B的运行结果,这个时候任务A就需要依赖任务B,那么B任务就是A任务父任务。
● 自依赖关系
自依赖关系可以理解为相同任务的不同周期依赖:例如 任务A是一个小时任务,0点开始执行,10点结束,每小时运行一次,那么任务A在0点合10点这个时间段上需要执行10次,如果说任务A每次执行都需要上一个周期执行结束,那么任务A就是一个自依赖任务。
除了上述两种依赖任务,还有跨周期依赖,不同周期任务的父子依赖关系:子任务会找到父任务最近的执行的一个周期实例依赖。
补数据实例是用户通过页面或者调用接口触发生成实例,仅有局部的依赖关系且和周期实例的依赖关系相互独立互不影响,实例依赖关系和周期实例一致。
注意:补数据是生成局部的DAG图,例如 1、2、3任务关系是 1->2->3,在页面上选择1和3任务进行补数据,那么1,2,3任务都会生成,但是最终结果只会运行1和3任务,2任务不运行。
临时运行实例可以分成两种离线和实时。
离线任务:用户可以直接运行任务生成实例,实例没有依赖关系。
实时任务:实时任务没有周期,上下游依赖这一概念,所以所以的实时实例都是临时运行的。
接下来我们来看一下Taier周期实例的生成。
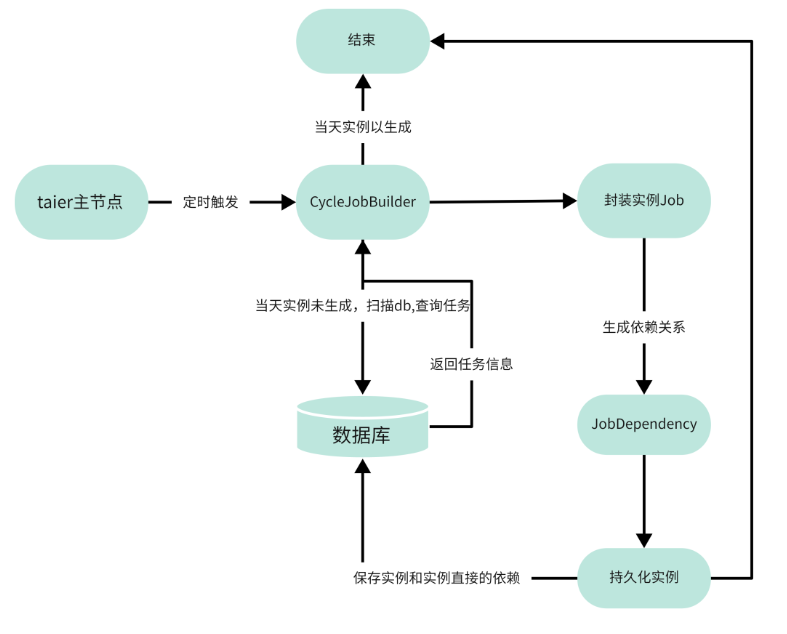
上图为Taier实例的整体生成图,Taier主节点在启动的时候会开启一个定时器,定时器会不停的去判断当日的实例是否已经生成,如果没有生成就会触发事件给CycleJobBuilder生成实例,再通过JobDependency封装实例之间的依赖关系。
其中CycleJobBuilder是指用于生成周期实例,扫描数据
库任务表并且获取zk上所有的taier节点,把封装后的实
例分配到每一台Taier节点上;JobDependency是用于生成job之间的依赖关系。
接下来为大家介绍下Taier的主从选举。
在application.properties文件中配置zk:
nodeZkAddress=${ZK_HOST}:${ZK_PORT}/taier
● Taier服务注册
每一台Taier服务都会去把自己的地址注册到zk上/taier/brokers下,在生成实例的时候,主节点就是从/taier/brokers获取所有注册在zk的Taier节点信息。
每一台Taier服务和zk会维持一个心跳,并保存在/taier/brokers/ip:port/heart节点下。

● 主节点选举
Taier的主从选举是基于LeaderLatch来实现的,在启动Taier后,Taier会尝试去抢占/taier/masterLatchLock这边锁,抢到锁的节点就是主节点,没有抢到锁的节点就是从节点。

接下来为大家介绍下Taier实例调度,首先为大家介绍下调度流程。
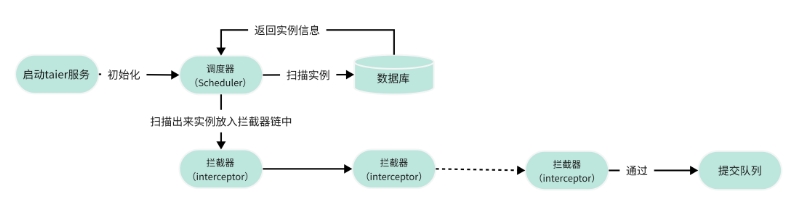
上图就是Taier实例调度的整体流程,在启动Taier服务时,会启动配置的所有调度器,并且开始扫描实例,并提交。
● 调度器
由于实例类型的不同,我们需要的调度器也会不同,但是他们都有一个父类(Scheduler)。
例如CycleJobScheduler专门负责周期实例的调度,而FillDataJobScheduler是负责补数据实例的调度。
不同的调度器,提交的条件也不一定,例如CycleJobScheduler只会扫描2天内的周期实例,而RestartJobScheduler是没有时间限制的,而且每一个调度器的拦截器链也会不一样。
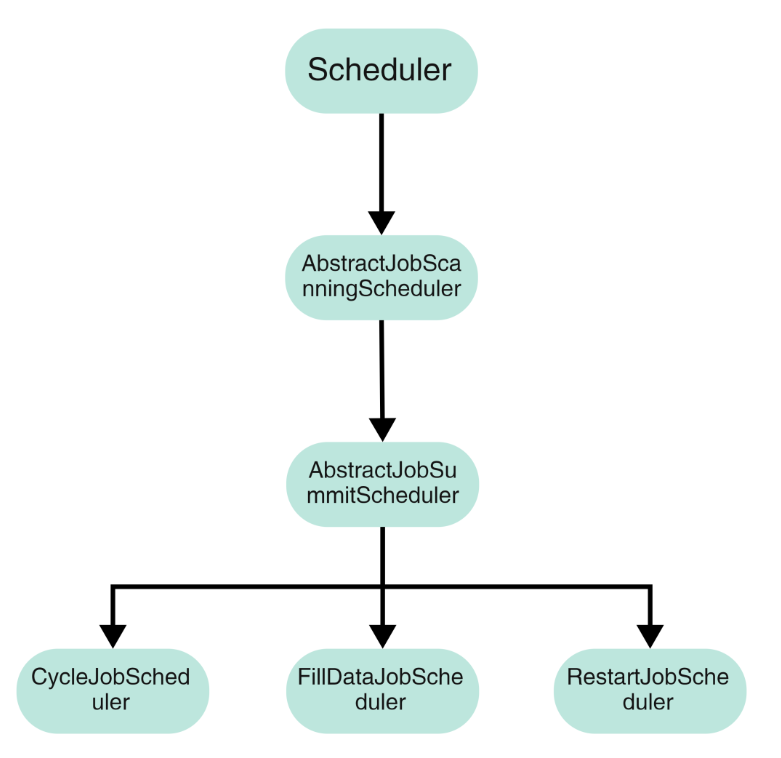
● 拦截器
拦截器是用于负责检查实例是否到达提交条件,多个拦截器会形成拦截器链。当实例通过拦截器链时,说明实例到达提交状态,所以实例会被放入到提交队列中,等待提交。
默认提供的拦截器:
1.JobStatusSubmitInterceptor:用于判断实例状态。
2.JobUpStreamSubmitInterceptor:用于判断实例上游是否运行完成。注意,该上游实例不仅仅是上游任务实例,还有可能是自依赖实例。
3.TaskStatusSubmitInterceptor:用于判断任务状态是否正常。
每个调度器内装载的拦截器可以不同。
最后为大家介绍下Taier实例的提交,因为任务类型的不同,所以实例提交置计算节点的逻辑也不同,为了能有更好的扩展性,Taier实现类插件化的处理。

我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
我正在写一篇关于在Ruby中几乎一切都是对象的博客文章,我试图通过以下示例来展示这一点:classCoolBeansattr_accessor:beansdefinitialize@bean=[]enddefcount_beans@beans.countendend所以从类中我们可以看出它有4个方法(当然,除非我错了):它可以在创建新实例时初始化一个默认的空bean数组它可以计算它有多少个bean它可以读取它有多少个bean(通过attr_accessor)它可以向空数组写入(或添加)更多bean(也通过attr_accessor)但是,当我询问类本身它有哪些实例方法时,我没有看到默认
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我知道还有其他相同的问题,但他们没有解决我的问题。我不断收到错误:Aws::Errors::MissingRegionErrorinBooksController#create,缺少区域;使用:region选项或将区域名称导出到ENV['AWS_REGION']。但是,这是我的配置开发.rb:config.paperclip_defaults={storage::s3,s3_host_name:"s3-us-west-2.amazonaws.com",s3_credentials:{bucket:ENV['AWS_BUCKET'],access_key_id:ENV['AWS_ACCE