步骤:
启动metastore
启动hiveserver2
使用beeline进行连接测试,查看地址等是否能够成功连接(确认无误可以跳过)
使用python连接hive
(粗暴的文件配置以及完整操作见文末)
一.启动hiveserver2
1.配置mode为http,端口为10001(默认)
<property>
<name>hive.server2.transport.mode</name>
<value>http</value>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
</property>
<property>
<name>hive.server2.thrift.http.path</name>
<value>cliservice</value>
</property>2.启动
启动metastore
nohup hive --service metastore &启动hiveserver2
nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 --hiveconf hive.root.logger=INFO,console &
3.查看hiveserver2所在的端口
未修改hive-site的默认情况下mode为TCP,HiveServer2 在端口 10000上运行,如果想更改端口,可以通过更改hive-site.xml文件中的hive.server2.thrift.port 属性值来实现。使用hive命令进入hive命令行后使用以下命令来查看hive-site中的各种配置(格式为set 属性名),例如:
set hive.server2.thrift.port
(如果设置为http协议,即文章开头的操作,则默认端口为10001,踩过坑之后把mode设置成了http,在我的电脑上tcp连接不上)
netstat -anp | grep 1000
4.使用jps命令来查看 HiveServer2 是否正在运行(RunJar服务)
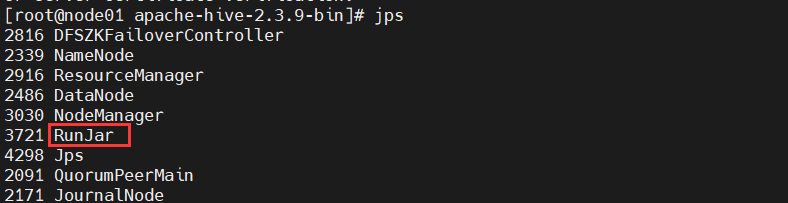
5.浏览器查看
HiveServer2 还在端口 10002 (默认)上启动一个 Jetty Http 服务器,提供 Web UI。在hive连接出错时可以多看看日志中的hive日志。
如果没有在配置文件中设置启动地址的话,直接用hive所在的地址(虚拟机的地址)+10002即可访问,例如我的访问地址就是http://192.168.121.130:10002/(注意:这里很多教程直接用的localhost之类的,是因为他们的hive部署在本地)
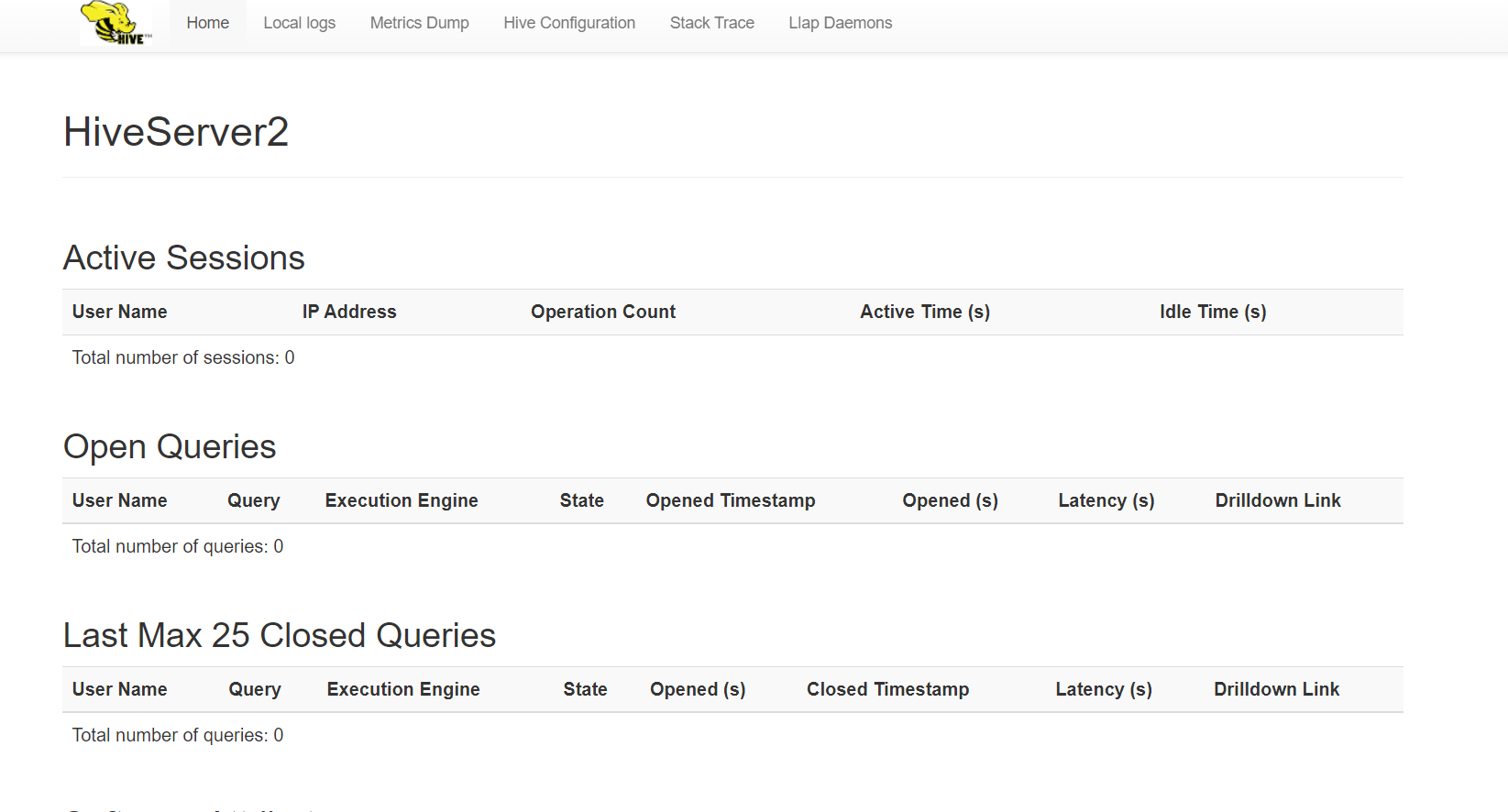
假如修改地址配置,在hive-site中添加如下配置,则访问地址为http://node01:10002/(但是使用ip+端口号的形式也可以正常访问)
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>二.beeline测试连接Hive
1.启动beeline
$HIVE_HOME/bin/beeline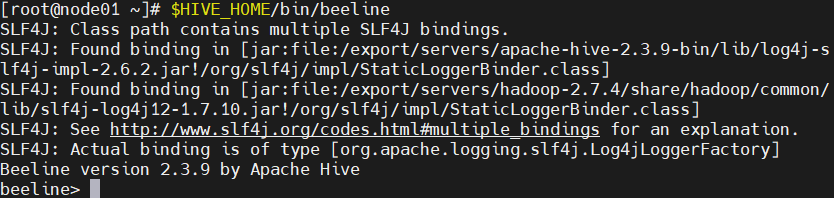
2.连接hive
(1)使用地址连接
连接地址直接把浏览器访问地址的10002改成10001即可,注意后面要加上hive的数据库,例如default,这里使用了之前创建好的study数据库。后面的一大串字符也是必要的,在python连接时都要加入(对于我的操作来说)
!connect jdbc:hive2://192.168.121.130:10001/study;transportMode=http;httpPath=cliservice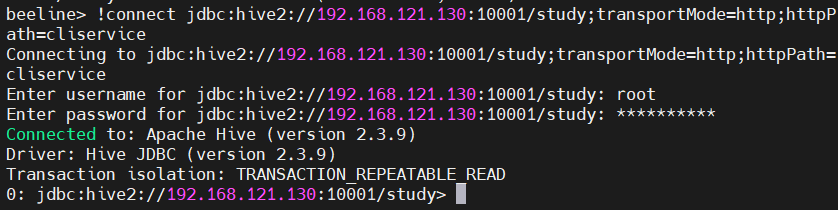
会提示user not allowed to XXX,这个是权限设置什么什么的,具体的感兴趣可以自行搜索报错,这里直接给出解决方案:在每台虚拟机的hadoop的配置文件/etc/hadoop/core-site.xml中增加如下配置,三台都要重启生效
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>(2)直接默认连接
在不清楚连接的Hive地址时,通过以下命令连接,然后按照提示输入用户名和密码即可(连接的用户名和密码在hive的hive-site.xml文件中设置,见Hive部署这篇文章),这里因为没有在配置文件中设置metastore的位置,因此会有警告。
!connect jdbc:hive2://
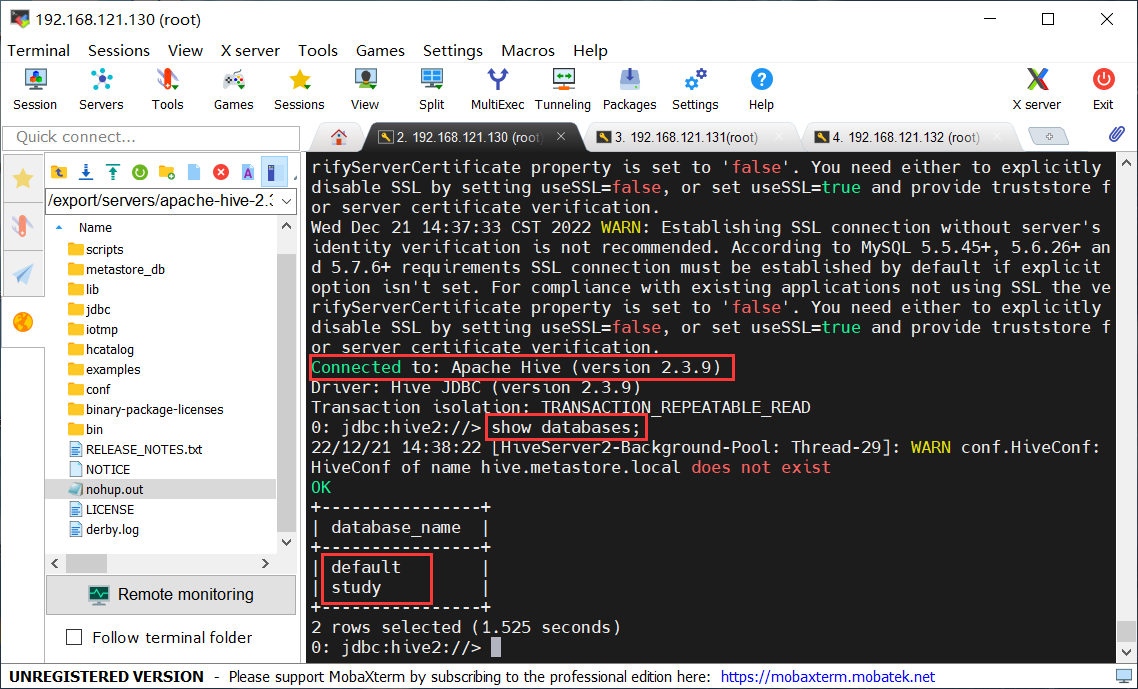
添加metastore配置
在hive的hive-site.xml中添加以下内容,(属性值为空,则表示是 metastore 在本地,否则就是远程),这里设置为虚拟机的地址以及默认的9083端口,注意修改完成后要重启。
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.121.130:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>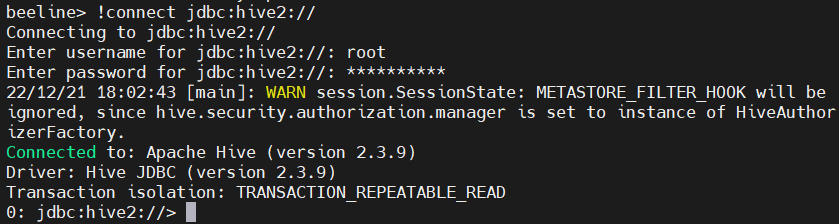
三.python连接hive
1.安装包
安装 pure-sasl
pip install pure-sasl
安装 thrift_sasl
pip install thrift_sasl==0.2.1 --no-deps
安装thrift
pip install thrift_sasl==0.2.1 --no-deps
安装最终的:impyla
pip install impyla
pip install thriftpy2.python
输出study数据库中的所有表
from impala.dbapi import connect
conn = connect(host='192.168.121.130', port=10001, auth_mechanism='PLAIN', user='用户名',
password='密码', database='study', use_http_transport='http', http_path='cliservice')
cursor = conn.cursor()
cursor.execute('show tables')
for row in cursor:
print(row)
四.快速完成配置与连接
1.配置文件
(1)hive-site.xml(node01上修改)
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_local/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp_local/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&usessL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MySQL@2022</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>
<property>
<name>hive.server2.use.SSL</name>
<value>false</value>
</property>
<property>
<name>hive.server2.transport.mode</name>
<value>http</value>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
</property>
<property>
<name>hive.server2.thrift.http.path</name>
<value>cliservice</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.121.130:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
</configuration>(2)core-site.xml(node01,02,03上修改)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>2.连接测试
启动hiveserver2服务,在beeline上进行测试是否可以连接
#node01,02,03分别依次执行
zkServer.sh start
zkServer.sh status
hadoop-daemon.sh start journalnode
#node01执行
start-dfs.sh
start-yarn.sh
nohup hive --service metastore &
nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 --hiveconf hive.root.logger=INFO,console &
netstat -anp | grep 1000
$HIVE_HOME/bin/beeline
!connect jdbc:hive2://192.168.121.130:10001/study;transportMode=http;httpPath=cliservice3.测试无误后执行三中的python即可
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o