

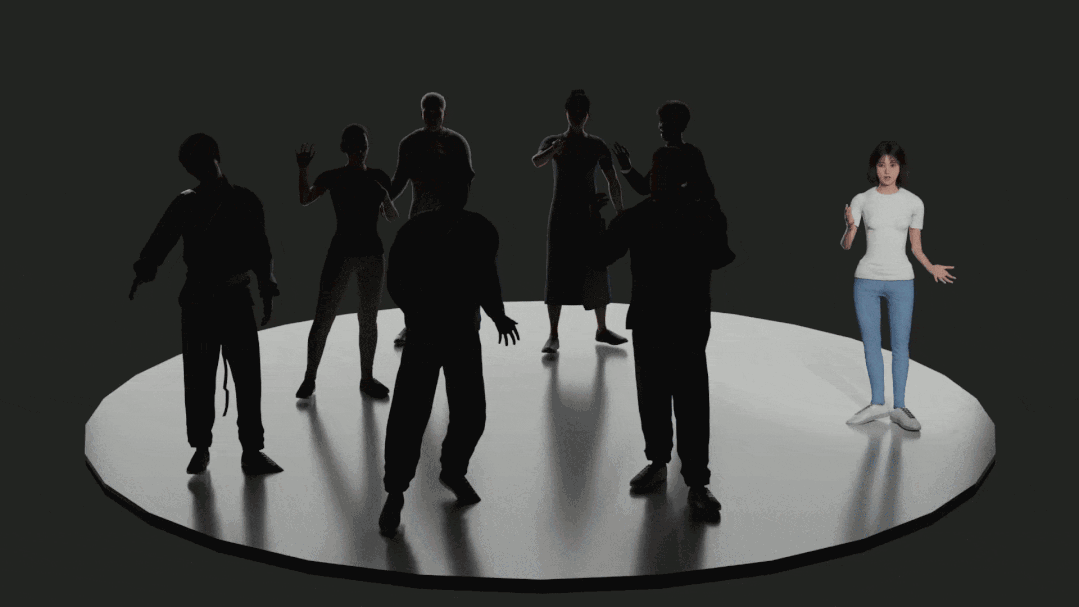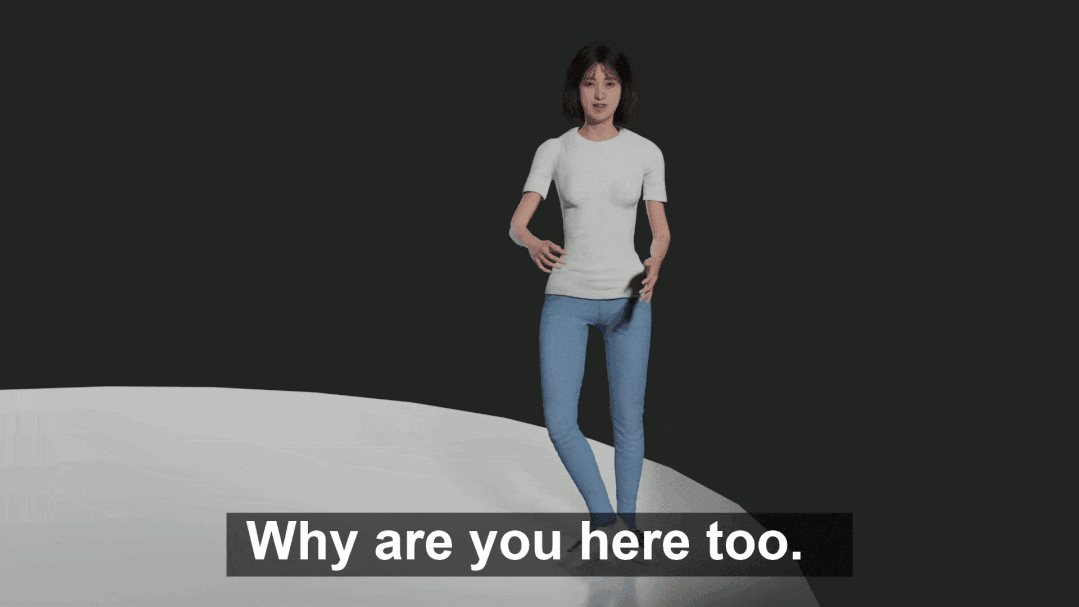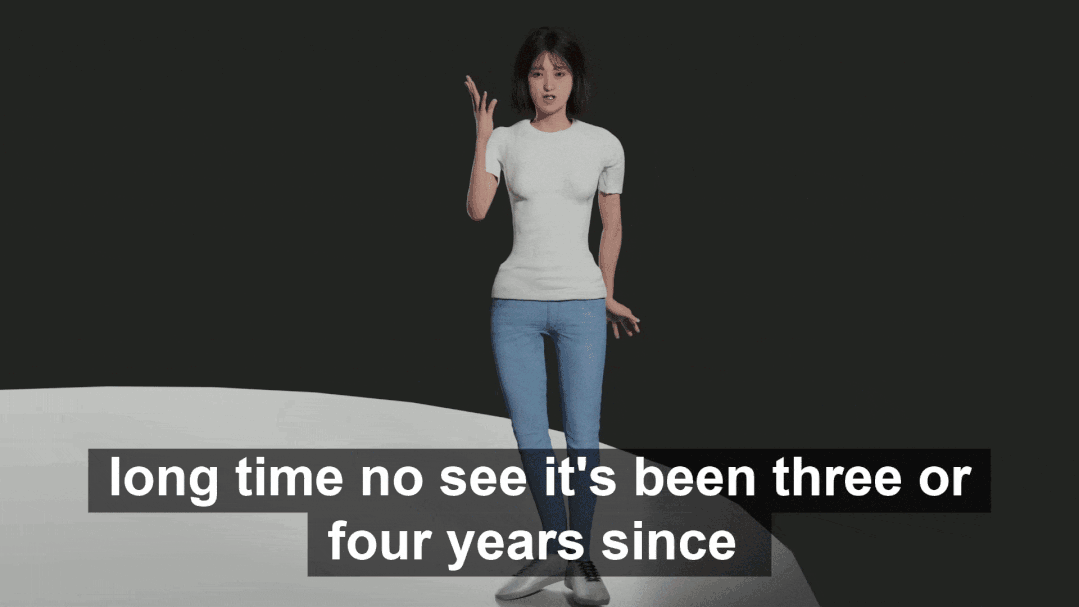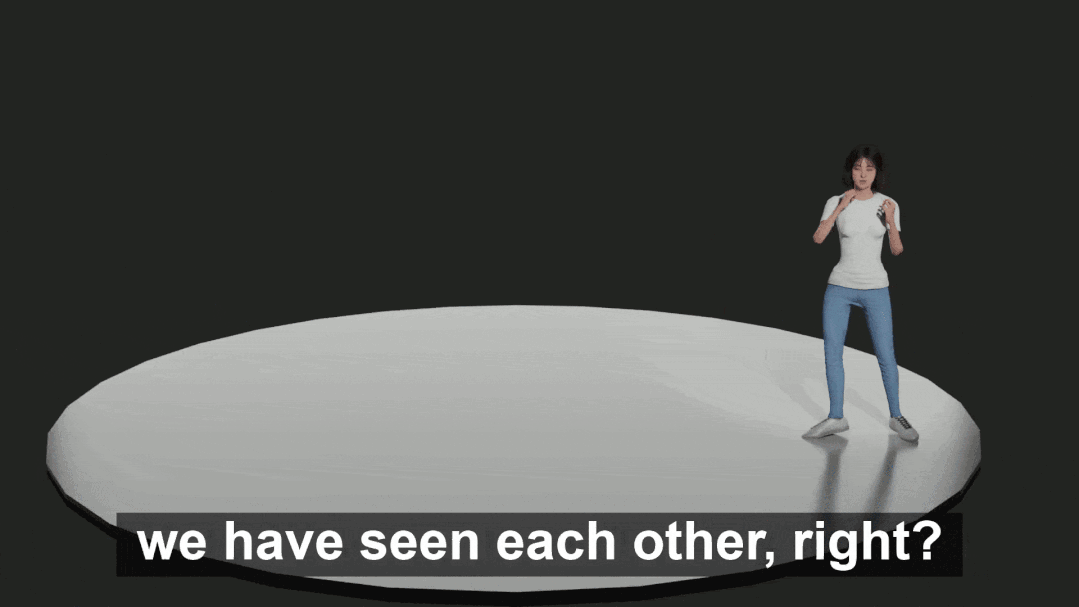
 渲染结果使用了 HumanGeneratorV3 产生的身体和脸部模型。
渲染结果使用了 HumanGeneratorV3 产生的身体和脸部模型。 数据规模及采集细节BEAT 采用了 ViCon,16 个摄像头的动作捕捉系统来记录演讲和对话数据,最终所有数据以 120FPS, 记载关节点旋转角的表示形式的 bvh 文件发布。对于面部数据,BEAT 采用 Iphone12Pro 录制谈话人的 52 维面部 blendsshape 权重,并不包括每个人的头部模型,推荐使用 Iphone 的中性脸做可视化。BEAT 采用 16KHZ 音频数据,并通过语音识别算法生成文本伪标签,并依此生成具有时间标注的 TextGrid 数据。BEAT 包含四种语言的数据:英语,中文,西班牙语,日语,数据量分别为 60,12,2,2 小时。由来自 10 个国家的 30 名演讲者进行录制。其中中文,西班牙语,日语的演讲者也同时录制了英语数据,用于分析不同语言下的动作差异。在演讲部分(数据集的 50%),30 个演讲者被要求读相同的大量文本,每段文本长度约 1 分钟,总计 120 段文本。目的是控制文本内容相同来研究不同演讲者之间的风格差异,来实现个性化的动作生成。谈话部分(50%)演讲者将和导演在给定话题下进行 10 分钟左右的讨论,但为了去除噪声,只有演讲者的数据被记录。下表还将 BEAT 与现有的数据集进行了比较,绿色高光表示最佳值,可以看出,BEAT 是现阶段包含多模态数据和标注的最大的运动捕捉数据集。
数据规模及采集细节BEAT 采用了 ViCon,16 个摄像头的动作捕捉系统来记录演讲和对话数据,最终所有数据以 120FPS, 记载关节点旋转角的表示形式的 bvh 文件发布。对于面部数据,BEAT 采用 Iphone12Pro 录制谈话人的 52 维面部 blendsshape 权重,并不包括每个人的头部模型,推荐使用 Iphone 的中性脸做可视化。BEAT 采用 16KHZ 音频数据,并通过语音识别算法生成文本伪标签,并依此生成具有时间标注的 TextGrid 数据。BEAT 包含四种语言的数据:英语,中文,西班牙语,日语,数据量分别为 60,12,2,2 小时。由来自 10 个国家的 30 名演讲者进行录制。其中中文,西班牙语,日语的演讲者也同时录制了英语数据,用于分析不同语言下的动作差异。在演讲部分(数据集的 50%),30 个演讲者被要求读相同的大量文本,每段文本长度约 1 分钟,总计 120 段文本。目的是控制文本内容相同来研究不同演讲者之间的风格差异,来实现个性化的动作生成。谈话部分(50%)演讲者将和导演在给定话题下进行 10 分钟左右的讨论,但为了去除噪声,只有演讲者的数据被记录。下表还将 BEAT 与现有的数据集进行了比较,绿色高光表示最佳值,可以看出,BEAT 是现阶段包含多模态数据和标注的最大的运动捕捉数据集。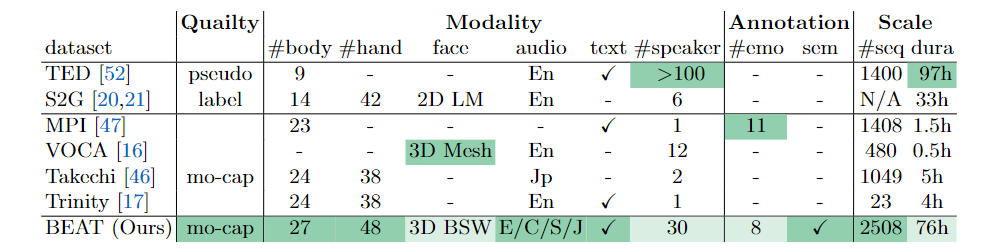
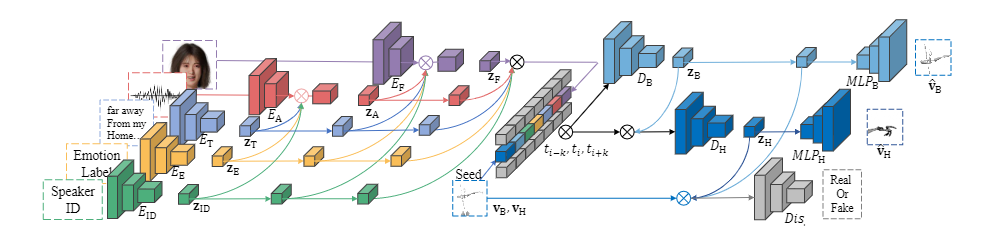 文本、语音和 Speaker-ID 编码器的网络选择是基于现有研究,并针对 BEAT 数据集在结构上进行了修改。对于面部 blendshape weight 数据,采用了基于残差网络的一维 TCN 结构。最终网络的损失函数来自语义标注权重和动作重建损失的组合:
文本、语音和 Speaker-ID 编码器的网络选择是基于现有研究,并针对 BEAT 数据集在结构上进行了修改。对于面部 blendshape weight 数据,采用了基于残差网络的一维 TCN 结构。最终网络的损失函数来自语义标注权重和动作重建损失的组合: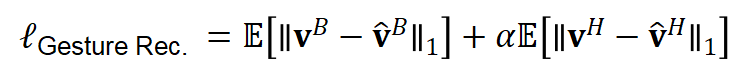 其中针对不同演讲者的数据,网络也采取了不同的对抗损失来辅助提升生成动作的多样性。
其中针对不同演讲者的数据,网络也采取了不同的对抗损失来辅助提升生成动作的多样性。
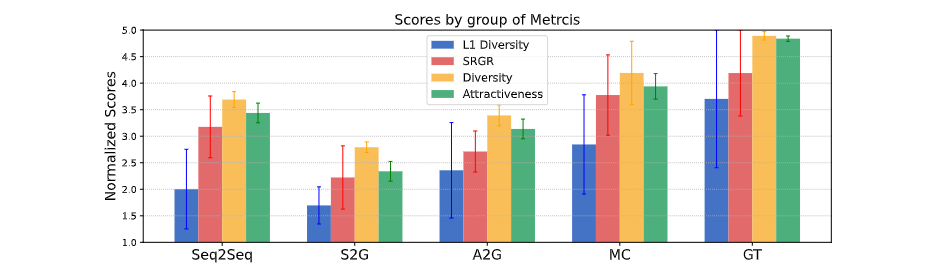 数据质量为了评估 BEAT 这一新型数据集的质量,研究者使用了现有研究中广泛使用的动捕数据集 Trinity 作为对比目标。每个数据集被分成 19:2:2 的比例,分别作为训练 / 验证 / 测试数据,并使用现有方法 S2G 和 audio2gestures 进行比较。评估主要针对不同数据集训练结果的正确性(身体动作的准确性)、手部正确性(手部动作的准确性)、多样性(动作的多样性)和同步性(动作和语音的同步性)。结果见下表。
数据质量为了评估 BEAT 这一新型数据集的质量,研究者使用了现有研究中广泛使用的动捕数据集 Trinity 作为对比目标。每个数据集被分成 19:2:2 的比例,分别作为训练 / 验证 / 测试数据,并使用现有方法 S2G 和 audio2gestures 进行比较。评估主要针对不同数据集训练结果的正确性(身体动作的准确性)、手部正确性(手部动作的准确性)、多样性(动作的多样性)和同步性(动作和语音的同步性)。结果见下表。
 表中显示,BEAT 在各方面的主管评分都很高,表明这个数据集远远优于 Trinity。同时在数据质量上也超过了现有的视频数据集 S2G-3D。对 Baseline 模型的评价为了验证本文提出的模型 CaMN 的性能,在以下条件下与现有方法 Seq2Seq,S2G,A2G 和 MultiContext 进行了比较验证。一些实验的细节如下:
表中显示,BEAT 在各方面的主管评分都很高,表明这个数据集远远优于 Trinity。同时在数据质量上也超过了现有的视频数据集 S2G-3D。对 Baseline 模型的评价为了验证本文提出的模型 CaMN 的性能,在以下条件下与现有方法 Seq2Seq,S2G,A2G 和 MultiContext 进行了比较验证。一些实验的细节如下: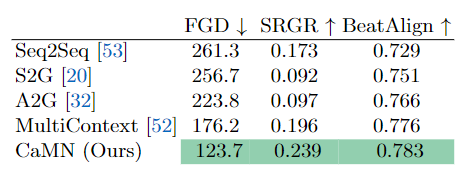 下面是一个由 CaMN 生成的手势的例子。
下面是一个由 CaMN 生成的手势的例子。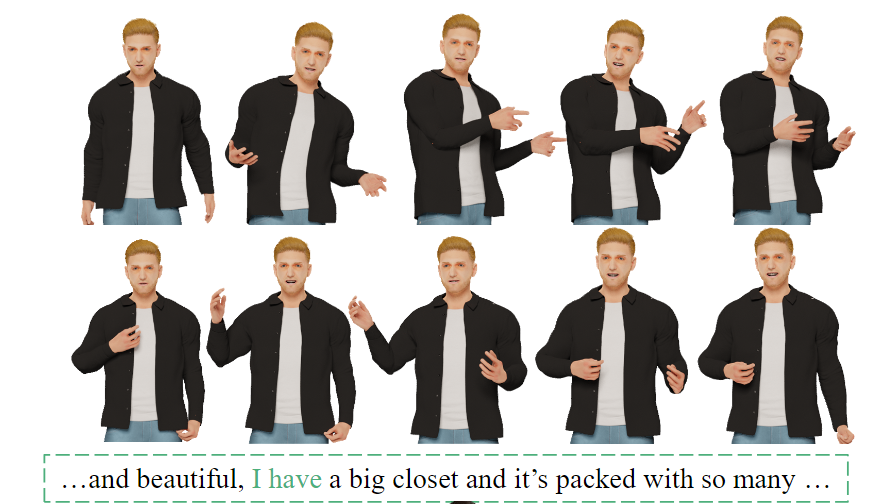 图中展示了一个真实数据样本(上)和一个 CaMN 生成的动作(下),生成的动作具备语义相关性。
图中展示了一个真实数据样本(上)和一个 CaMN 生成的动作(下),生成的动作具备语义相关性。我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
在我的应用程序中,我有一个文本字段,用户可以在其中输入类似这样的内容"1,2,3,4"存储到数据库中。现在,当我想使用内部数字时,我有两个选择:"1,2,3,4".split(',')或string.scan(/\d+/)do|x|a两种方式我都得到一个像这样的数组["1","2","3","4"]然后我可以通过在每个数字上调用to_i来使用这些数字。有没有更好的方法可以转换"1,2,3"to[1,2,3]andnot["1","2","3"] 最佳答案 str.split(",").map{|i|i.to_i}但是这个想法对你来说
我有一个随机大小的散列,它可能有类似"100"的值,我想将其转换为整数。我知道我可以使用value.to_iifvalue.to_i.to_s==value来做到这一点,但我不确定我将如何在我的散列中递归地做到这一点,考虑到一个值可以是一个字符串,或一个数组(哈希或字符串),或另一个哈希。 最佳答案 这是一个非常简单的递归实现(尽管必须同时处理数组和散列会增加一些技巧)。deffixnumifyobjifobj.respond_to?:to_i#IfwecancastittoaFixnum,doit.obj.to_ielsifobj
什么是测试格式验证的最佳方法让我们说一个用户名,使用字母数字的正则表达式,但不是纯数字?我一直在我的模型中使用以下验证validates:username,:format=>{:with=>/^[a-z0-9]+[-a-z0-9]*[a-z0-9]+$/i}数字用户名(例如“342”)通过了验证,这是我不想要的。 最佳答案 您想“向前看”一封信:/\A(?=.*[a-z])[a-z\d]+\Z/i 关于ruby-on-rails-Rails格式验证——字母数字,但不是纯数字,我们在Sta