建立aws账户,进入到S3界面
 点击 "Create bucket"
点击 "Create bucket"
一系列操作之后——这里给bucket命名为csfyp

python需要先:
pip install loguru
pip install boto3这两个包含一些连接python和s3 连接的api
然后直接上代码
import os
import boto3
from loguru import logger
BUCKET_NAME = "csfyp" # 存储桶名称
# aws_access_key_id和aws_secret_access_key
CN_S3_AKI = ''
CN_S3_SAK = ''
CN_REGION_NAME = 'us-west-2' # 区域
# s3 实例
s3 = boto3.client('s3', region_name=CN_REGION_NAME,
aws_access_key_id=CN_S3_AKI, aws_secret_access_key=CN_S3_SAK
)
def upload_files(path_local, path_s3):
"""
上传(重复上传会覆盖同名文件)
:param path_local: 本地路径
:param path_s3: s3路径
"""
logger.info(f'Start upload files.')
if not upload_single_file(path_local, path_s3):
logger.error(f'Upload files failed.')
logger.info(f'Upload files successful.')
def upload_single_file(src_local_path, dest_s3_path):
"""
上传单个文件
:param src_local_path:
:param dest_s3_path:
:return:
"""
try:
with open(src_local_path, 'rb') as f:
s3.upload_fileobj(f, BUCKET_NAME, dest_s3_path)
except Exception as e:
logger.error(f'Upload data failed. | src: {src_local_path} | dest: {dest_s3_path} | Exception: {e}')
return False
logger.info(f'Uploading file successful. | src: {src_local_path} | dest: {dest_s3_path}')
return True
def download_zip(path_s3, path_local):
"""
下载
:param path_s3:
:param path_local:
:return:
"""
retry = 0
while retry < 3: # 下载异常尝试3次
logger.info(f'Start downloading files. | path_s3: {path_s3} | path_local: {path_local}')
try:
s3.download_file(BUCKET_NAME, path_s3, path_local)
file_size = os.path.getsize(path_local)
logger.info(f'Downloading completed. | size: {round(file_size / 1048576, 2)} MB')
break # 下载完成后退出重试
except Exception as e:
logger.error(f'Download zip failed. | Exception: {e}')
retry += 1
if retry >= 3:
logger.error(f'Download zip failed after max retry.')
def delete_s3_zip(path_s3, file_name=''):
"""
删除
:param path_s3:
:param file_name:
:return:
"""
try:
# copy
# copy_source = {'Bucket': BUCKET_NAME, 'Key': path_s3}
# s3.copy_object(CopySource=copy_source, Bucket=BUCKET_NAME, Key='is-zips-cache/' + file_name)
s3.delete_object(Bucket=BUCKET_NAME, Key=path_s3)
except Exception as e:
logger.error(f'Delete s3 file failed. | Exception: {e}')
logger.info(f'Delete s3 file Successful. | path_s3 = {path_s3}')
def batch_delete_s3(delete_key_list):
"""
批量删除
:param delete_key_list: [
{'Key': "test-01/虎式03的副本.jpeg"},
{'Key': "test-01/tank001.png"},
]
:return:
"""
try:
res = s3.delete_objects(
Bucket=BUCKET_NAME,
Delete={'Objects': delete_key_list}
)
except Exception as e:
logger.error(f"Batch delete file failed. | Excepthon: {e}")
logger.info(f"Batch delete file success. ")
def get_files_list(Prefix=None):
"""
查询
:param start_after:
:return:
"""
logger.info(f'Start getting files from s3.')
try:
if Prefix is not None:
all_obj = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix=Prefix)
# 获取某个对象的head信息
# obj = s3.head_object(Bucket=BUCKET_NAME, Key=Prefix)
# logger.info(f"obj = {obj}")
else:
all_obj = s3.list_objects_v2(Bucket=BUCKET_NAME)
except Exception as e:
logger.error(f'Get files list failed. | Exception: {e}')
return
contents = all_obj.get('Contents')
logger.info(f"--- contents = {contents}")
if not contents:
return
file_name_list = []
for zip_obj in contents:
# logger.info(f"zip_obj = {zip_obj}")
file_size = round(zip_obj['Size'] / 1024 / 1024, 3) # 大小
# logger.info(f"file_path = {zip_obj['Key']}")
# logger.info(f"LastModified = {zip_obj['LastModified']}")
# logger.info(f"file_size = {file_size} Mb")
# zip_name = zip_obj['Key'][len(start_after):]
zip_name = zip_obj['Key']
file_name_list.append(zip_name)
logger.info(f'Get file list successful.')
return file_name_list
if __name__ == "__main__":
pass
# TODO test 查询/上传/下载
# 查询
file_name_list = get_files_list()
logger.info(f"file_name_list = {file_name_list}")
path_local = './rootkey.csv'
path_s3 = 'rootkey.csv' # s3路径不存在则自动创建
upload_files(path_local, path_s3)
# 下载
# path_s3 = './rootkey.csv'
# path_local = '' #自定义下载到本地的位置
# download_zip(path_s3, path_local)
这里参考了https://blog.csdn.net/xuezhangjun0121/article/details/116025732的代码
那如何查询我们的
CN_S3_AKI = 'your_aws_access_key_id'
CN_S3_SAK = 'your_aws_secret_access_key'
在aws中:
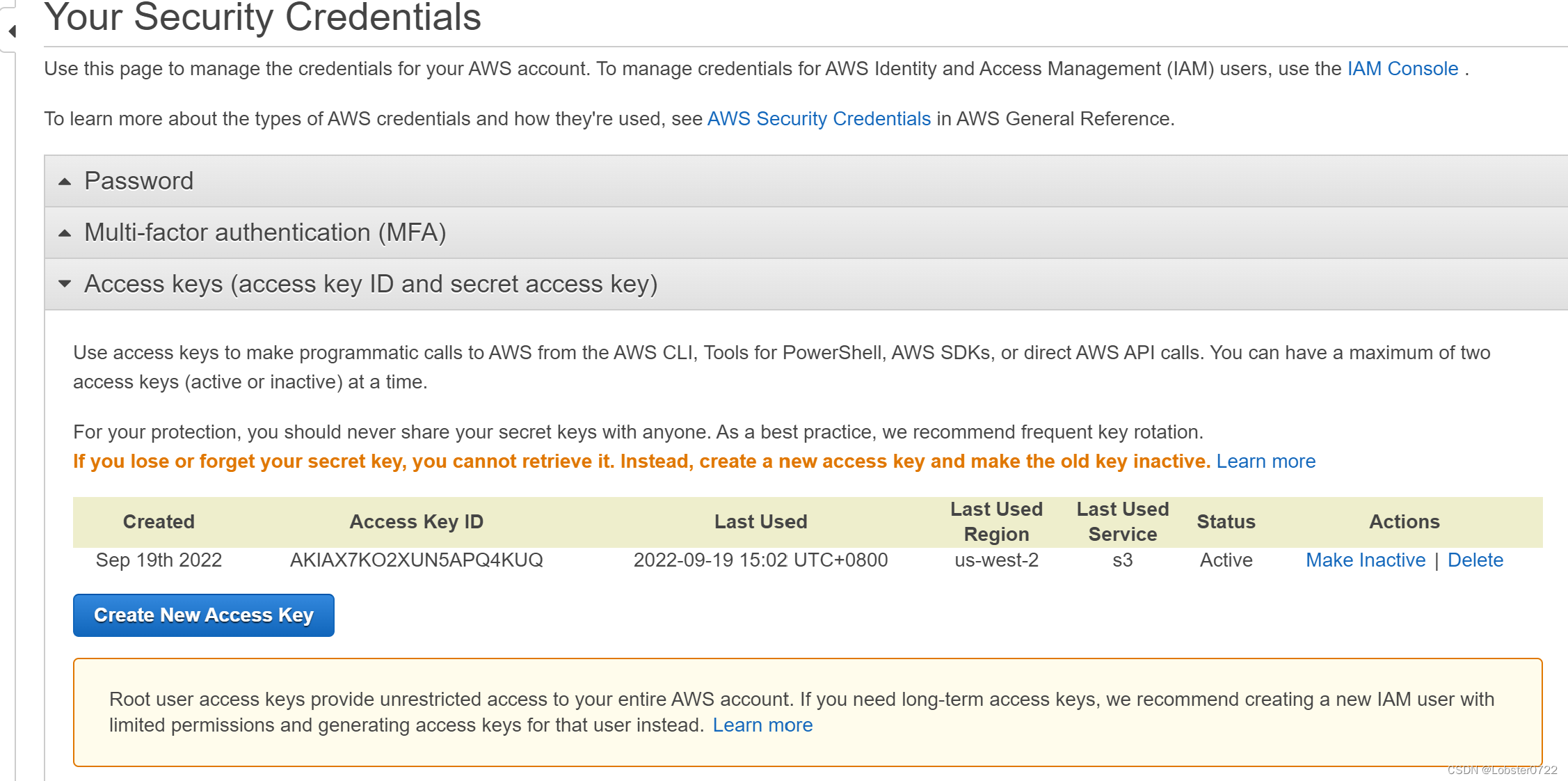 创建一个新的key,下载得到一个csv文件就是了
创建一个新的key,下载得到一个csv文件就是了
然后就是bucket的名字和区域在s3上都有,可以直接复制粘贴
最终输出就是这样

在AWS上面就可以看到上传的文件啦!
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex