摘要:本文将盘点处理CSV数据时我遇到的一些坑。
本文分享自华为云社区《CSV—简单格式下隐藏的那些坑》,作者:aKi。
CSV(Comma-Separated Values),是一种通用的、相对简单的文件格式。其文件以纯文本形式存储表格数据,文件可由任意数目的记录组成,记录间以换行符分隔,每条记录由字段组成,字段间的分隔符是特定字符或字符串,最常见的是以逗号作为分隔符。
例如:下面是一个含有三行内容的csv文件。

CSV格式广泛应用于程序之间转移表格数据,这些程序在格式上是不兼容的,在没有高效的数据迁移工具时,CSV就成为最好的中间格式之一,因此大部分程序也都支持CSV数据的导入和导出。例如,从A程序导出CSV文件,再将该文件导入至B程序。这一过程看似简单,但其中也存在着不少隐含的坑,下面我们就来盘点一下常见的三种坑。
前文中我们提到过CSV文件中每条记录是通过换行符分隔的,常用逗号作为分隔符。但在实际处理数据时会遇到字段中也存在换行和逗号的情况,如果A程序没有处理好对应的数据,在导入B程序时就会产生错误的数据或记录。
例如:下面CSV文件中第二行的记录中第四个字段中包含逗号和换行。

我们可以使用Excel工具来查看该文件文解析后的样子:

正确的数据处理方式是将包含逗号和换行的字段用双引号包围起来:

对应文件被解析后:

拓展一下,字段中的若本身就存在双引号,需要在字段自身的双引号前再加一个双引号。
比如我们在Airplane前加一个双引号表示字段本身的数据:

该文件使用本文工具打开以后是这样的:

很多时候CSV文件的编码格式都是较为常见UTF-8格式,UTF-8格式存在BOM头的问题,这种问题大部分原因是在Windows下编辑CSV文件时被自动加上了BOM头。如果程序B没有处理好BOM头,会导致将BOM头也被当做字段的一部分,而且这种错误无法通过直接观察CSV文件来发现。
例如这里是两个内容完全相同的文件:

当一个包含BOM头,另一个不包含时,其二进制表达是不一样的:

包含BOM头的文件在文件开始位置多了3个字节数据。处理方式也很简单,将文件以无BOM的形式保存就行。
CSV注入其实是一个安全漏洞,当CSV文件被Excel工具打开时,其字段数据被Excel解析,从而支持了Excel提供的所有动态功能。
下面我们来看一个例子:

我们将其中一个字段写成了=1+1,此时用Excel工具打开该文件:

=1+1被解析成了2
同理,利用此漏洞还可以执行任意程序。

用Execl打开时会出现如下提示:

点击是后便会运行计算器程序
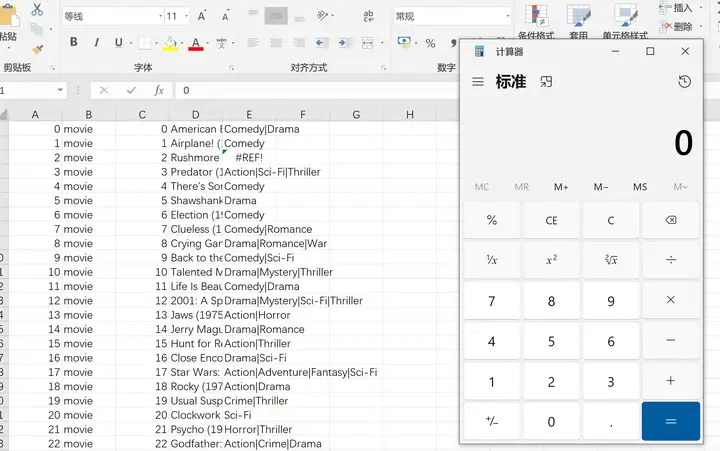
当然,该漏洞在较新版本的Excel中都被默认禁止了。在文件->选项->信任中心中外部内容设置中默认都是不勾选“启用动态数据交换服务器启动”。
以上就是我在处理csv数据时遇到过的坑,希望读者们在遇到类似问题时能第一时间想到原因和解决方案,避免在坑里徘徊太久。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最