JUC全称为java.util.concurrent,其中,concurrent这个包里包含了很多和多线程并发相关的操作,同样也是面试中的高频考点,下面博主就带大家学习学习这部分内容吧!

JUC
下面我们来看一段代码实现两个线程分别对一个变量count累加操作:
public class Test {
static class Counter{
public int count=0;
public void increase(){
count++;
}
}
public static void main(String[] args) {
Counter counter=new Counter();
Thread t1 = new Thread() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
}
};
Thread t2 = new Thread() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
}
};
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter.count);
}
}
经过之前的学习,我们认为此方法打印count是线程不安全的,不会每次都很准确地打印10000:
第一次运行
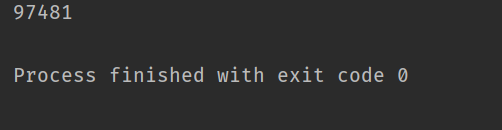
第二次运行
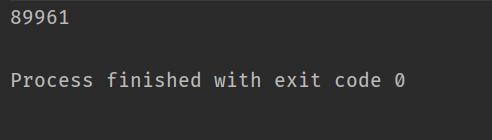
之前我们学过的解决方法是使用synchronized保证线程的安全性,代码如下:
static class Counter{
public int count=0;
synchronized public void increase(){
count++;
}
}
改动部分如上图所示(其他部分一样),打印结果如下: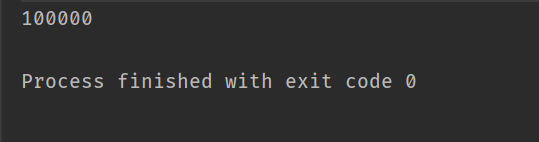
但此时我们可以通过创建ReentrantLock这一对象对其实现加锁,完整代码如下:
import java.util.concurrent.locks.ReentrantLock;
public class Test {
static class Counter {
public int count;
public ReentrantLock locker = new ReentrantLock();
public void increase() {
locker.lock();
count++;
locker.unlock();
}
}
public static void main(String[] args) {
Counter counter=new Counter();
Thread t1 = new Thread() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
}
};
Thread t2 = new Thread() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
}
};
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter.count);
}
}
打印结果如下:
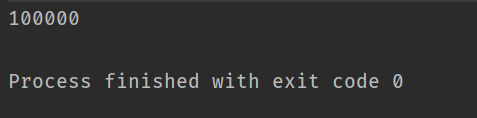
那么,与synchronized同样都能对其实现加锁功能,这两者有什么区别呢?
ReentrantLock把加锁和解锁拆成了两个方法,确实存在遗忘解锁的风险,但可以让代码变得更加灵活,可以把加锁和解锁的代码分别放到两个方法之中synchronized在申请锁失败时,代码会死等。而ReentrantLock 可以通过trylock这个方法等待一段时间就放弃,不会浪费时间synchronized是非公平锁,而ReentrantLock默认是非公平锁。但可以通过构造方法传入一个 true 开启公平锁模式ReentrantLock 有更强大的唤醒机制,synchronized 是通过 Object 的 wait / notify 方法实现等待唤醒过程的,每次唤醒的是一个随机等待的线程。而ReentrantLock搭配 Condition 类实现等待-唤醒,可以更精确控制唤醒某个指定的线程。synchronized就足够了ReentrantLock , 搭配 trylock 方法可以更灵活地控制加锁的行为,而不是死等。ReentrantLock保证线程安全不一定非得加锁,当然也可以用原子类,从java1.5开始,jdk提供了java.util.concurrent.atomic包,这个包内包含一系列的原子操作类,提供了一种用法简单,性能高效,线程安全的更新一个变量的方式。其内部通常以CAS方式实现,因此性能通常比加锁实现i++要高很多,具体使用方法如下(上述例子)
public AtomicInteger count = new AtomicInteger(0);
public void increase() {
count.getAndIncrement();
}
这里只展示改动后的代码,其打印结果如下:
以 AtomicInteger 举例,常见方法有
解决并发编程的方案一般是靠多进程的,但是进程开销的资源是非常大的,因此我们进一步地引入了多线程。虽然创建销毁线程比创建销毁进程看起来似乎更轻量了,但是在频繁创建毁线程的时还是会比较低效。线程池就是为了解决这个问题。如果某个线程不再使用了,并不是真正把线程释放,而是放到一个 "池子"中。当我们需要使用多线程的时候,直接从之前创建好的池子中取出一个就行了,当我们不用的时候,直接把这个线程放回池子中即可。
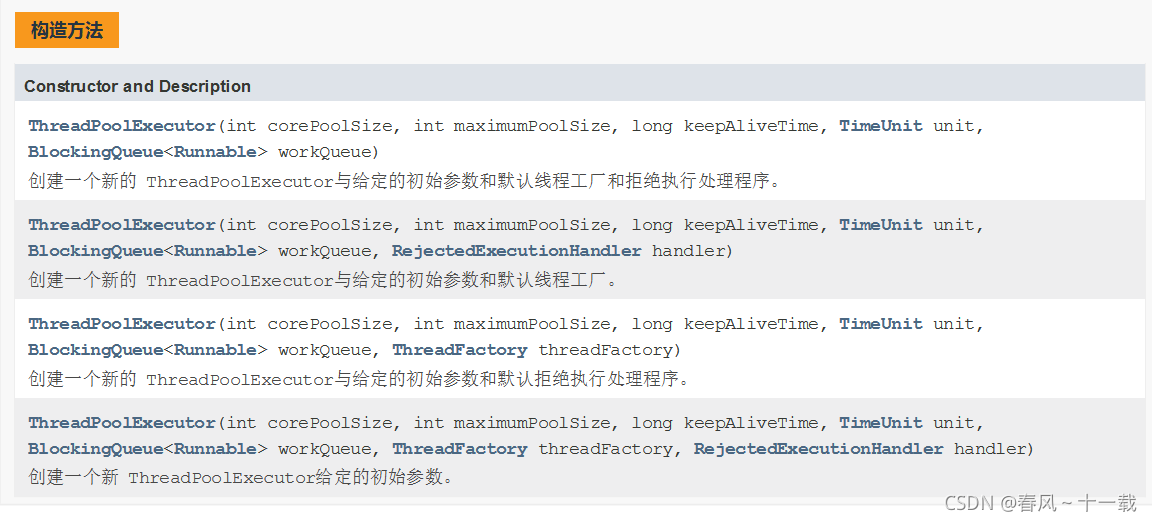
使用Java标准库中的ThreadPoolExecutor方式创建,但需注意里面各自的参数代表的含义,使用起来相对而言比较复杂。
构造方法
为了更好地理解每个参数的具体含义,大家可以利用空闲时间去jdk的官方文档学习学习,对自己是非常有帮助的: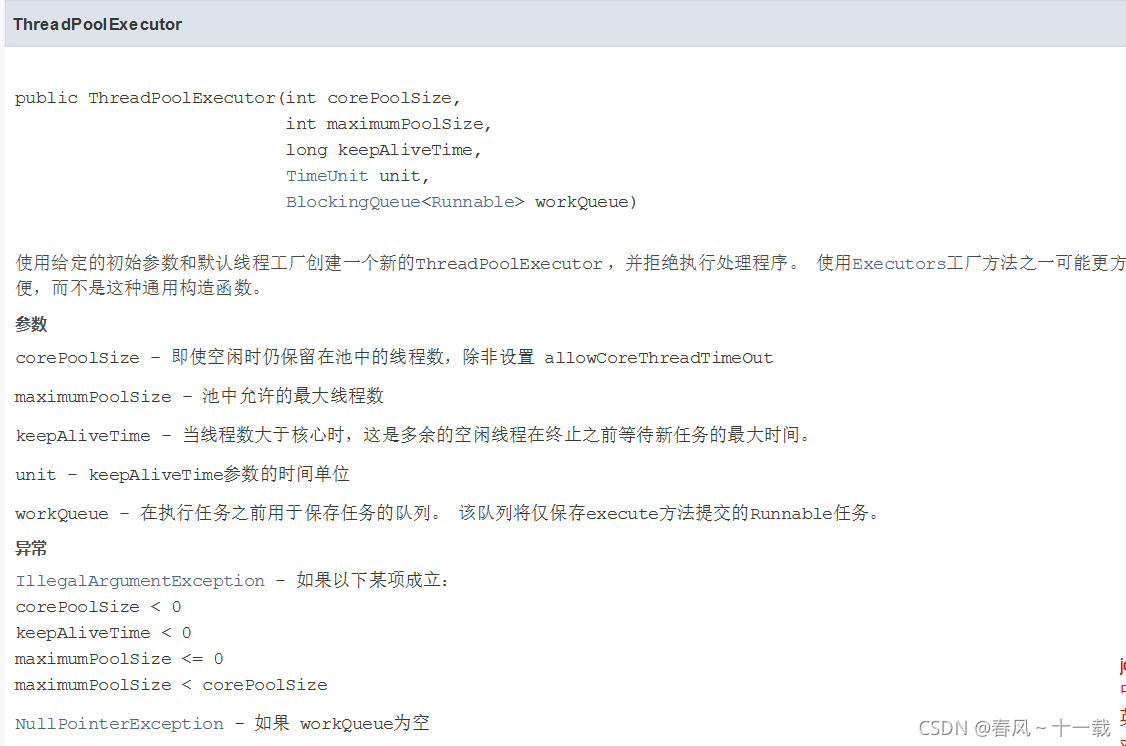
使用 Executors 这个类创建,这个类相当于一个工厂类,通过这个工厂类中的一些方法,就可以创建出不同风格的线程池实例了。
部分方法
用法示例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 20; i++) {
service.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
});
}
}
}
运行结果:

信号量Semaphore一般用来表示可用资源的个数,相当于一个计数器,可类比生活中停车场牌子上面显示的停车场剩余车位数量。
下面我们创建15个线程,给定初始资源量为3个,然后先尝试申请资源(acquire),申请完资源后再休眠1秒,然后释放资源(release):
mport java.util.concurrent.Semaphore;
public class Test {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("准备申请资源");
semaphore.acquire();
System.out.println("申请资源成功");
// 申请到资源之后休眠1秒
Thread.sleep(1000);
semaphore.release();
// 释放资源
System.out.println("释放资源完毕");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建15个线程,让这 15 个线程来分别去尝试申请资源
for (int i = 0; i < 15; i++) {
Thread t = new Thread(runnable);
t.start();
}
}
}
运行结果如下:
可以看到,由于资源数为3,所以前3个线程申请资源后很容易成功,而之后的线程就没有资源可以申请了,只能等到前3个线程把资源释放出来后再申请
信号量相当于是锁的升级版本,锁只能控制一个资源的有无,而信号量可以控制很多个资源的有无
用于同时等待N个任务结束,就好比百米赛跑一样,只有当所有选手都到位之后,哨声响了之后才能同时出发开始跑步,当所有选手都通过终点时才会公布成绩。
我们创建10个线程同时开始执行一个任务,每个任务执行完后记录一下,都调用 latch.countDown()方法。在CountDownLatch 内部的计数器同时自减。再创建一个主线程,其中使用 latch.await(); 阻塞等待至所有任务执行完毕(此时计数器为0)
用法示例
import java.util.concurrent.CountDownLatch;
public class Test {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(10);
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("任务开始");
try {
Thread.sleep((long) (Math.random() * 10000));//生成随机数
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown();
System.out.println("任务完成!");
}
};
for (int i = 0; i < 10; i++) {
Thread t = new Thread(runnable);
t.start();
}
latch.await();
System.out.println("所有任务结束");
}
}
打印结果如下:
首先,线程同步就是协同步调,按预定的先后次序进行运行,即靠哪个线程先获得到CUP的执行权谁就先执行
详见与synchronized区别部分(学会用自己的话总结)
详见信号量的定义部分(学会用自己的话总结)
详见上文中所涉及的jdk官方文档,这个参数虽然比较多,但大致上可以通过英文推测出其大意,此时就需要我们平常多记记了!
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg