本文目录
- elasticsearch 版本:7.11.1
- 客户端环境:kibana v7.11.1、Java8 应用程序模块。
其中 kibana 主要用于数据查询诊断和查阅日志,Java8 为主要的客户端,数据插入和查询都是由Java 实现的。
共有三个部署环境,一个是开发环境、一个是测试环境、一个是正式环境。
前提:APP的首页搜索功能(搜索设备列表和搜索智能列表)在开发环境和正式环境一切正常。
测试人员在测试APP的首页搜索功能(搜索设备列表和搜索智能列表),发现搜索智能列表功能正常,而搜索设备时,无数据。
使用 kibana 里的开发工具查询时单个汉字可以搜索出设备列表,而使用词语去搜索设备时一直搜索不到任何数据。
查询数据命令:命令 索引/_search
下图中的命令是查询该索引下的所有数据
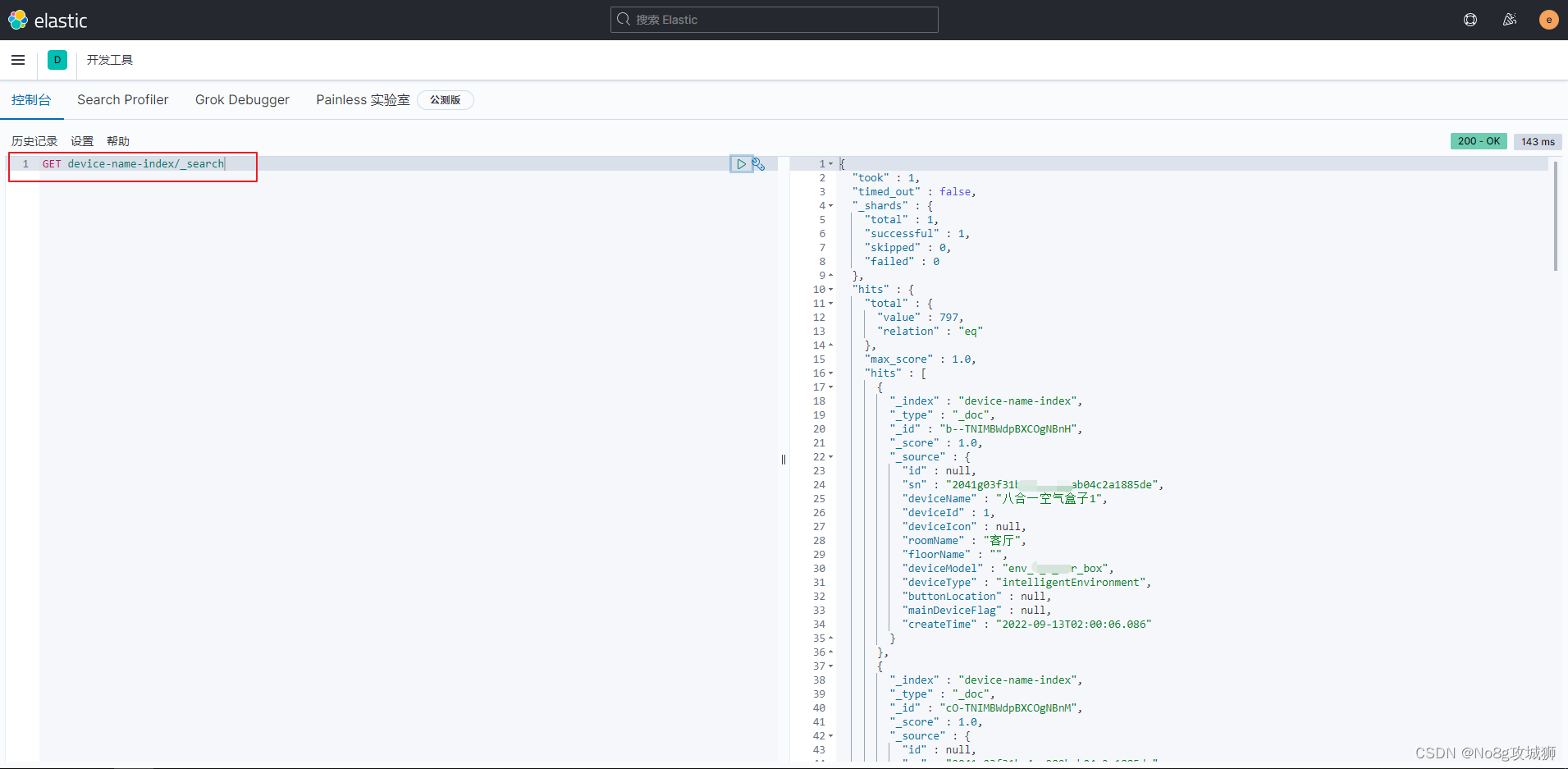
示例(根据某一字段查询)如下:
GET device-name-index/_search
{
"query": {
"bool": {
"must": [
{"term": {
"deviceName": {
"value": "开关"
}
}}
]
}
}
}搜索“开”字可以把设备名称中带有“开”字的设备搜索出来,但是搜索“开关”词语时,设备名称中带有“开关”词语的设备结果为空(ES中实际上有数据)。
使用 elasticsearch 存储设备列表的主要信息,document 内的 field,基本上是 integer 或 keyword,es 自动创建的索引 device-name-index 如下:
查询 mapping 信息,命令如下:
GET device-name-index/_mapping结果返回如下:
{
"device-name-index" : {
"mappings" : {
"properties" : {
"deviceId" : {
"type" : "integer"
},
"deviceModel" : {
"type" : "text"
},
"deviceName" : {
"type" : "text"
},
"deviceType" : {
"type" : "text"
},
"floorName" : {
"type" : "text"
},
"id" : {
"type" : "integer"
},
"roomName" : {
"type" : "text"
},
"sn" : {
"type" : "text"
}
}
}
}
}而部署在开发环境里的 es 索引里的字段类型如下:
{
"device-name-index" : {
"mappings" : {
"properties" : {
"deviceId" : {
"type" : "integer"
},
"deviceModel" : {
"type" : "keyword"
},
"deviceName" : {
"type" : "text",
"fields" : {
"ikmaxword" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"pinyin" : {
"type" : "text",
"analyzer" : "pinyin"
}
},
"analyzer" : "standard"
},
"deviceType" : {
"type" : "keyword"
},
"floorName" : {
"type" : "keyword"
},
"roomName" : {
"type" : "keyword"
},
"sn" : {
"type" : "keyword"
}
}
}
}
}以上字段,只需要关注 deviceName 即可。因为搜索是根据此字段检索数据的。
可以很清楚的看到 deviceName 字段使用了 ik分词器(ik_max_word)。
按照 mapping 返回结果来看,部署在测试环境的字段 deviceName 没有添加 ik 分词器,而 es 采取的策略是,如果没有添加自定义的分词器,那么便会使用 es 默认的标准分词器分词,这就是导致单个字搜索时可以检索出数据,而使用词语检索数据时无数据的原因。
命令如下:
DELETE device-name-index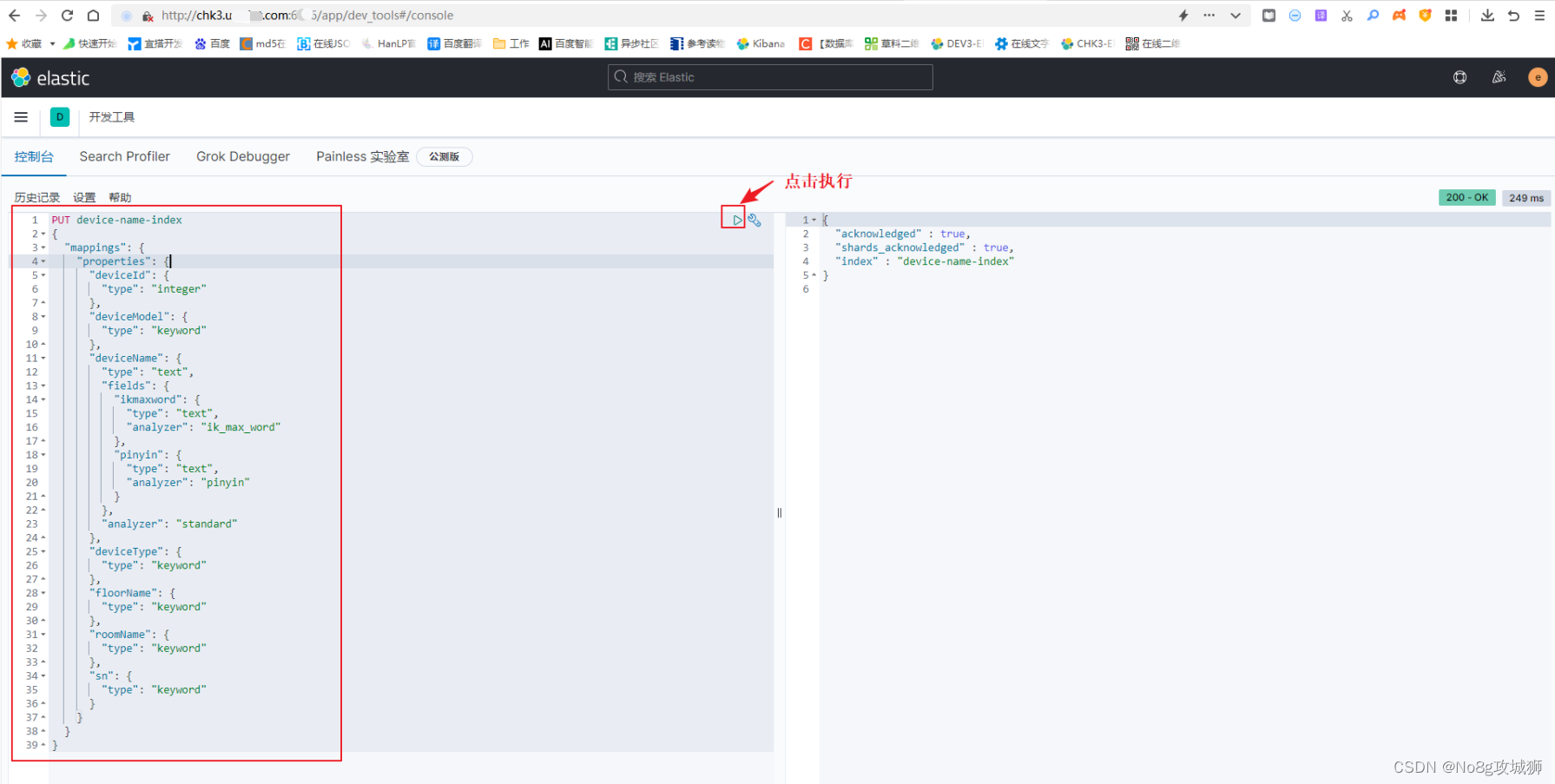
命令如下:
PUT device-name-index
{
"mappings": {
"properties": {
"deviceId": {
"type": "integer"
},
"deviceModel": {
"type": "keyword"
},
"deviceName": {
"type": "text",
"fields": {
"ikmaxword": {
"type": "text",
"analyzer": "ik_max_word"
},
"pinyin": {
"type": "text",
"analyzer": "pinyin"
}
},
"analyzer": "standard"
},
"deviceType": {
"type": "keyword"
},
"floorName": {
"type": "keyword"
},
"roomName": {
"type": "keyword"
},
"sn": {
"type": "keyword"
}
}
}
}在我的项目中只需要修改设备名称即可触发数据内容变更(全量删除并全量更新),再次在APP首页搜索设备名称,单个字和词语都可以检索出数据,问题搞定。
使用ik分词器后,查看分词结果情况,命令格式:
GET 索引/_doc/索引下某字段_id/_termvectors?fields=字段名称.ikmaxword
使用es默认的分词器查看分词结果情况,命令:
GET 索引/_doc/索引下某字段_id/_termvectors?fields=字段名称
示例如下:
GET device-name-index/_doc/cO-TNIMBWdpBXCOgNBnM/_termvectors?fields=deviceName.ikmaxword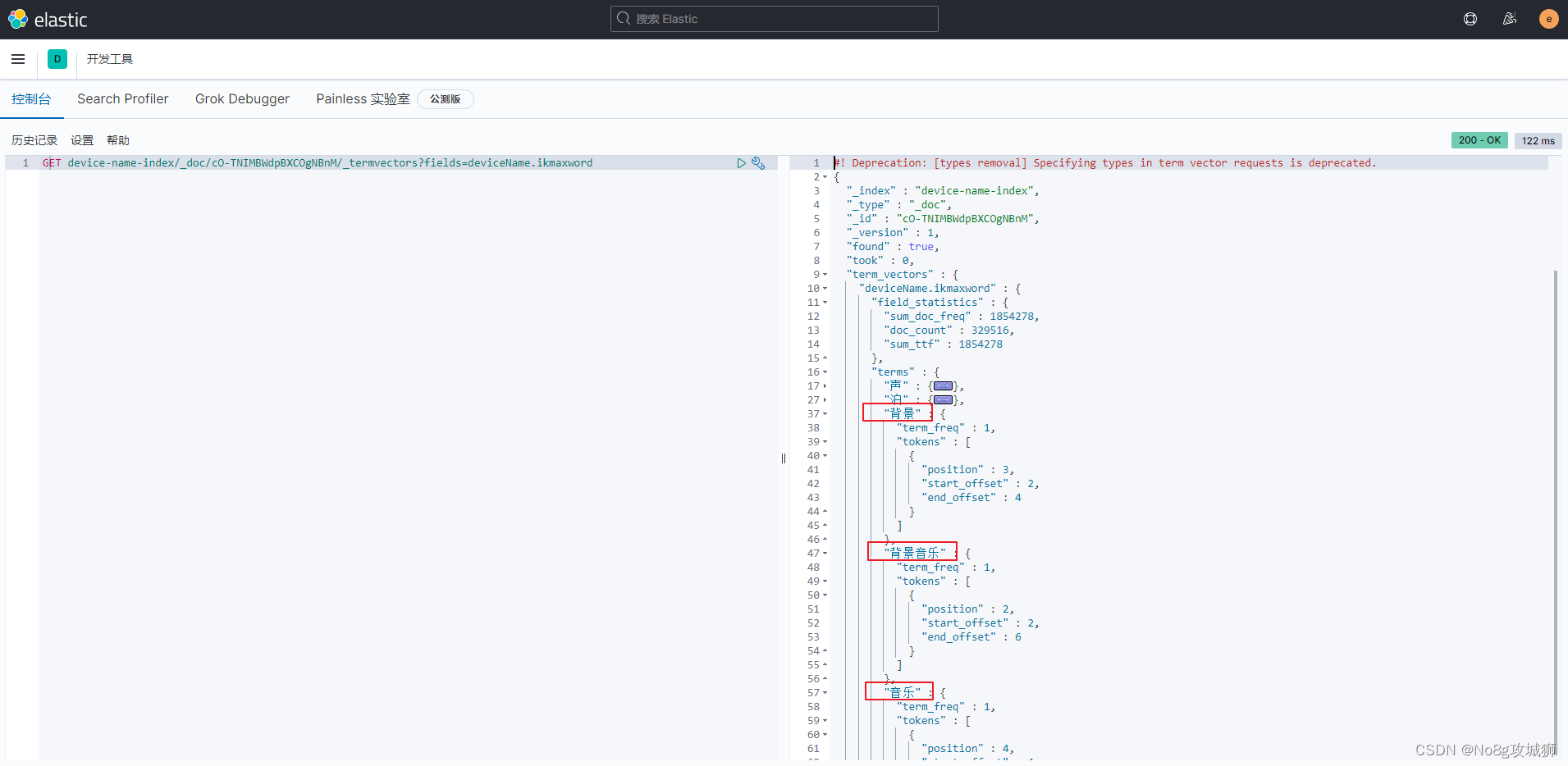
问题虽小,但一定要追溯源头,比如此次测试环境的不规范操作。后期如果有删除索引的操作,应该先手动建立索引后,再灌数据,而不是直接让其自动 mapping 建立索引,自动 mapping 建立的字段类型,可能不是我们期望的。
完结!
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法