 想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com网易传媒大数据实际业务中,存在着大量的准实时计算需求场景,业务方对于数据的实效性要求一般是分钟级;这种场景下,用传统的离线数仓方案不能满足用户在实效性方面的要求,而使用全链路的实时计算方案又会带来较高的资源占用。基于对开源数据湖方案的调研,我们注意到了网易数帆开源的基于 Apache Iceberg 构建的 Arctic 数据湖解决方案。Arctic 能相对较好地支持与服务于流批混用的场景,其开放的叠加式架构,可以帮助我们非常平滑地过渡与实现 Hive 到数据湖的升级改造,且由于传媒离线数仓已接入有数,通过 Arctic 来改造现有业务的成本较低,于是我们准备通过引入 Arctic ,尝试解决 push 业务场景下的痛点。
想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com网易传媒大数据实际业务中,存在着大量的准实时计算需求场景,业务方对于数据的实效性要求一般是分钟级;这种场景下,用传统的离线数仓方案不能满足用户在实效性方面的要求,而使用全链路的实时计算方案又会带来较高的资源占用。基于对开源数据湖方案的调研,我们注意到了网易数帆开源的基于 Apache Iceberg 构建的 Arctic 数据湖解决方案。Arctic 能相对较好地支持与服务于流批混用的场景,其开放的叠加式架构,可以帮助我们非常平滑地过渡与实现 Hive 到数据湖的升级改造,且由于传媒离线数仓已接入有数,通过 Arctic 来改造现有业务的成本较低,于是我们准备通过引入 Arctic ,尝试解决 push 业务场景下的痛点。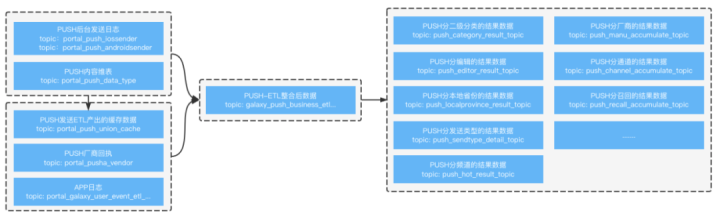 此前采用的全链路 Flink 实时计算方案中,主要遇到以下问题:
此前采用的全链路 Flink 实时计算方案中,主要遇到以下问题: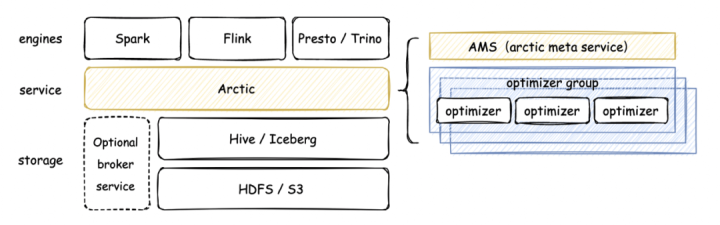 实现 push 业务场景下的数据湖改造,只需要使用 Arctic 提供的 Flink Connector,便可快速地实现 push 明细数据的实时入湖。此时需要我们关注的重点是,数据产出需要满足分钟级业务需求。数据产出延迟由两部分组成:
实现 push 业务场景下的数据湖改造,只需要使用 Arctic 提供的 Flink Connector,便可快速地实现 push 明细数据的实时入湖。此时需要我们关注的重点是,数据产出需要满足分钟级业务需求。数据产出延迟由两部分组成: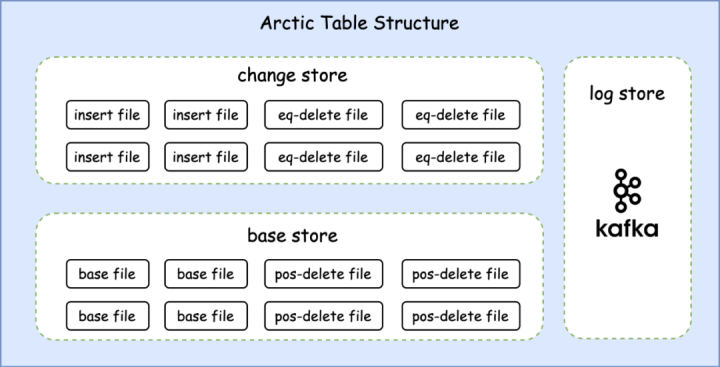 Arctic 表支持实时数据的流式写入,数据写入过程中为了保证数据的实效性,写入侧需要频繁的进行数据提交,但因此会产生大量的小文件,积压的小文件一方面会影响数据的查询性能,另一方面也会对文件系统带来压力。这方面,Arctic 支持基于主键的行级更新,提供了 Optimizer 来进行数据 Update 和自动的结构优化,以帮助用户解决数据湖常见的小文件、读放大、写放大等问题。以传媒 push 数仓场景为例,push 发送、送达、点击、展示等明细数据需要通过 Flink 作业实时写入到 Arctic 中。由于上游已经做了 ETL 清洗,此阶段只需要通过 FlinkSQL 即可方便地将上游数据写入 Changestore。Changestore 内包含了存储插入数据的 insert 文件和存储删除数据的 equality delete 文件,更新数据会被拆分为更新前项和更新后项分别存储在 delete 文件与 insert 文件中。具体的,对于有主键场景,insert/update_after 消息会写入 Changestore 的 insert 文件,delete/update_before 会写入 Arctic 的 delete 文件。当进行 Optimize 的时候,会先把 delete 文件读到内存中形成一个 delete map, map 的 key 是记录的主键,value 是 record_lsn。然后 再读取 Basestore 和 Changestore 中的 insert 文件, 对主键相同的 row 进行 record_lsn 的对比,如果 insert 记录中 record_lsn 比 deletemap 中相同主键的 record_lsn 小,则认为这条记录已经被删除了,不会再追加到 base 里;否则把数据写入到新文件里,最终实现了行级的更新。
Arctic 表支持实时数据的流式写入,数据写入过程中为了保证数据的实效性,写入侧需要频繁的进行数据提交,但因此会产生大量的小文件,积压的小文件一方面会影响数据的查询性能,另一方面也会对文件系统带来压力。这方面,Arctic 支持基于主键的行级更新,提供了 Optimizer 来进行数据 Update 和自动的结构优化,以帮助用户解决数据湖常见的小文件、读放大、写放大等问题。以传媒 push 数仓场景为例,push 发送、送达、点击、展示等明细数据需要通过 Flink 作业实时写入到 Arctic 中。由于上游已经做了 ETL 清洗,此阶段只需要通过 FlinkSQL 即可方便地将上游数据写入 Changestore。Changestore 内包含了存储插入数据的 insert 文件和存储删除数据的 equality delete 文件,更新数据会被拆分为更新前项和更新后项分别存储在 delete 文件与 insert 文件中。具体的,对于有主键场景,insert/update_after 消息会写入 Changestore 的 insert 文件,delete/update_before 会写入 Arctic 的 delete 文件。当进行 Optimize 的时候,会先把 delete 文件读到内存中形成一个 delete map, map 的 key 是记录的主键,value 是 record_lsn。然后 再读取 Basestore 和 Changestore 中的 insert 文件, 对主键相同的 row 进行 record_lsn 的对比,如果 insert 记录中 record_lsn 比 deletemap 中相同主键的 record_lsn 小,则认为这条记录已经被删除了,不会再追加到 base 里;否则把数据写入到新文件里,最终实现了行级的更新。
 Arctic 在开源发布会上发布了自己的 benchmark 数据,在数据库 CDC 持续流式摄取的场景下,对比各个数据湖 Format 的 OLAP benchmark 性能, 整体上带 Optimize 的 Arctic 的性能优于 Hudi,这主要得益于 Arctic 内部有一套高效的文件索引 Arctic Tree,在 MOR 场景下可以做到更细粒度、精确地 merge。详细的对比报告可以参考:https://arctic.netease.com/ch/benchmark/。
Arctic 在开源发布会上发布了自己的 benchmark 数据,在数据库 CDC 持续流式摄取的场景下,对比各个数据湖 Format 的 OLAP benchmark 性能, 整体上带 Optimize 的 Arctic 的性能优于 Hudi,这主要得益于 Arctic 内部有一套高效的文件索引 Arctic Tree,在 MOR 场景下可以做到更细粒度、精确地 merge。详细的对比报告可以参考:https://arctic.netease.com/ch/benchmark/。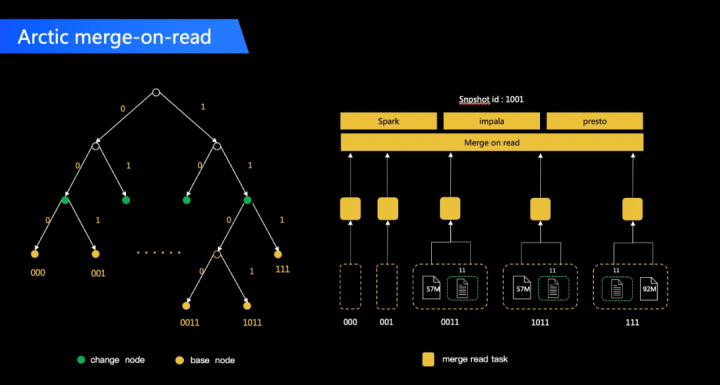


很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion