一个别人创建的新远程仓库,只有master分支 ,分支上只readme文件。
我直接在hbuilder创建了项目,写了首版代码,然后通过 hbuilder的 easy-git源代码管理push了。完了一看是直接推到了远程main分支。
这不行,要想办法把它搞到master分支上。
那现在分支情况是:
远程两个分支 main 和 master , 都有各自的代码,相当于独立的两个分支了
本地一个分支 main , 和远程main分支一样的代码
操作如下:
切换到main分支
git checkout main
拉取最新
git pull
切换到master分支
git checkout master
把main代码合并到master上
git merge main
这时不正常了 报这个 fatal: refusing to merge unrelated histories
接着执行
git pull origin master –allow-unrelated-histories
报fatal: couldn't find remote ref –allow-unrelated-histories
接着执行
git merge master --allow-unrelated-histories

感觉离完成接近了一步
继续
git checkout master
git merge main

好多了
继续
git push
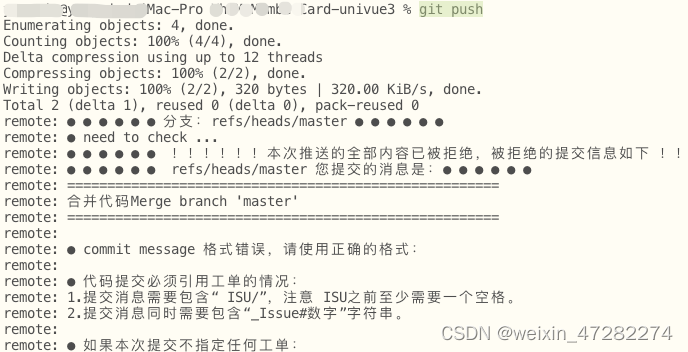
好更多了 如上图
但没推上去, 是因为公司提交代码需要引用工单,我着急忘了引,被拒绝了
那现在需要重新写一下提交注释
继续操作:
对之前最近的commit 提交进行修改,而且是没有push到远程的
git commit --amend
这里会进入 vim编辑器 嗯我记得就叫vim
这里需要按键盘 i 键,进入编辑模式,然后就可以输入注释,引用工单了,输入完按键盘 Esc ,推出编辑,然后在英文输入法下,打 :wq 就退出了。
git push
完成
我还想把远程main分支删了,只留master分支
查看所有分支
git branch -a

删除远程main分支
git push origin --delete main
完工
仅做记录,如有发现错误请指出哦,感谢
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
这是在Ruby中设置默认值的常用方法:classQuietByDefaultdefinitialize(opts={})@verbose=opts[:verbose]endend这是一个容易落入的陷阱:classVerboseNoMatterWhatdefinitialize(opts={})@verbose=opts[:verbose]||trueendend正确的做法是:classVerboseByDefaultdefinitialize(opts={})@verbose=opts.include?(:verbose)?opts[:verbose]:trueendend编写Verb
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru