目录
4.1决策树、SVM、逻辑回归、KNN模型的基本训练,并展示模型函数;
4.3模型的调优调参,寻找最优模型,并列表对比参数的变化过程及对应结果;
面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
一种基本的分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。
一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。
中文名为支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
可以根据混淆矩阵。得到其Accuracy准确率以及F1 score是精确率和召回率的调和平均值,F1的结果当精确率接近0,或者召回率接近0时,都会得到一个很低的F值。当精确率为1,召回率也为1时,F值为1。因此F值可以用来为我们选择一个较好的临界值。
通过pd.read_csv()读取数据集
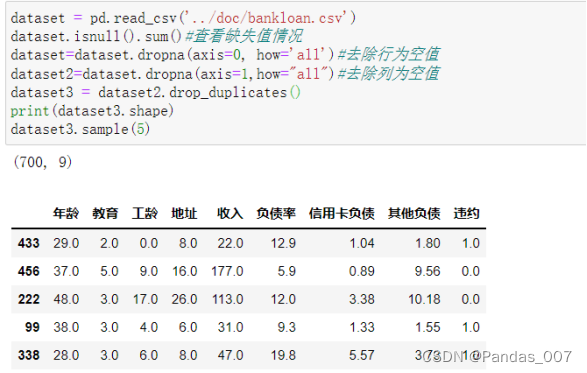
dataset = pd.read_csv('../doc/bankloan.csv')
dataset.isnull().sum()#查看缺失值情况
dataset=dataset.dropna(axis=0, how='all')#去除行为空值
dataset2=dataset.dropna(axis=1,how="all")#去除列为空值
dataset3 = dataset2.drop_duplicates()
print(dataset3.shape)
dataset3.sample(5)#随机抽取5列进行展示进行缺失值处理,重复值删除之后数据的大小为(700,9)
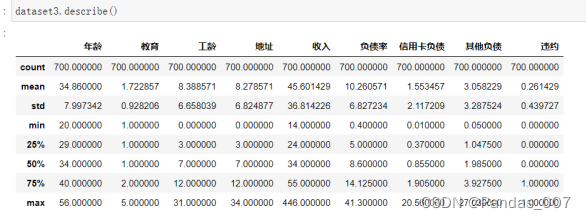
describe()查看数据情况

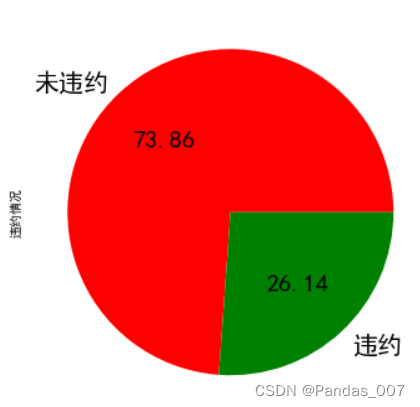
weiyue=dataset3.groupby('违约').size()
series = pd.Series([weiyue[0],weiyue[1]], index=["未违约", "违约"], name="违约情况")
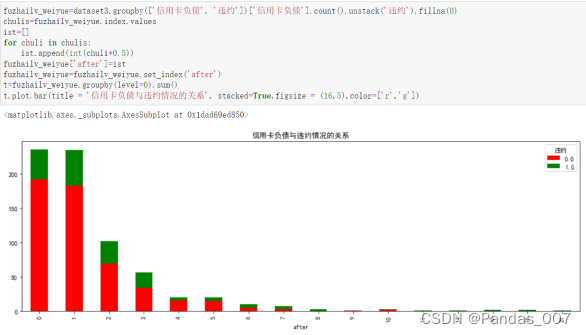
series.plot.pie(figsize=(6, 6),autopct="%.2f",fontsize=20,labels=["未违约", "违约"],colors=["r", "g"])由图可知,本次贷款违数据集中,占了超过4分之3的客户是未违约客户,违约客户占了4分之1,需要进一步分析其违约情况与其具体关系
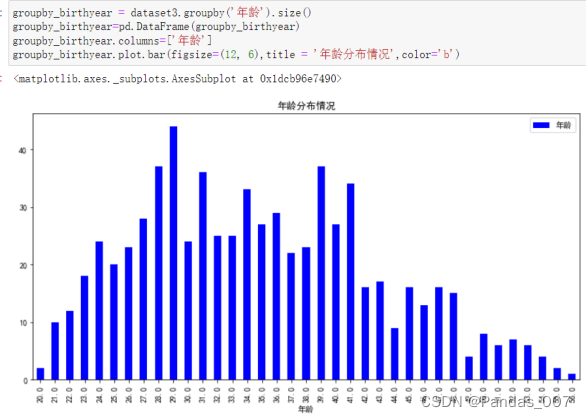
groupby_birthyear = dataset3.groupby('年龄').size()
groupby_birthyear=pd.DataFrame(groupby_birthyear)
groupby_birthyear.columns=['年龄']
groupby_birthyear.plot.bar(figsize=(12, 6),title = '年龄分布情况',color='b')从图可知大多数客户的年龄集中在24-41之间
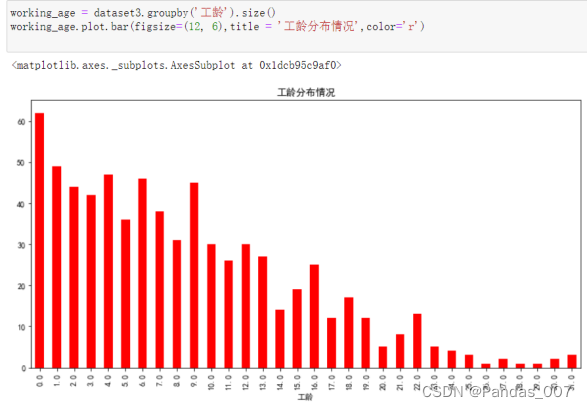
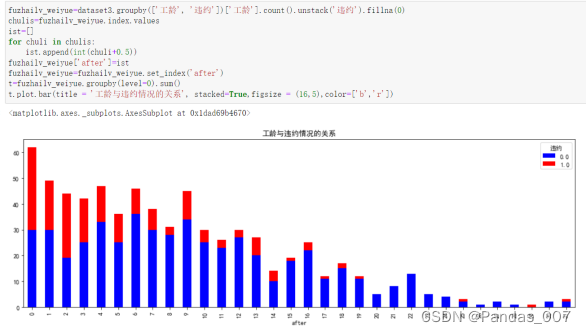
working_age = dataset3.groupby('工龄').size()
working_age.plot.bar(figsize=(12, 6),title = '工龄分布情况',color='r')
从图可知,大多数客户的工龄集中在13年以下,说明长期客户很不够多
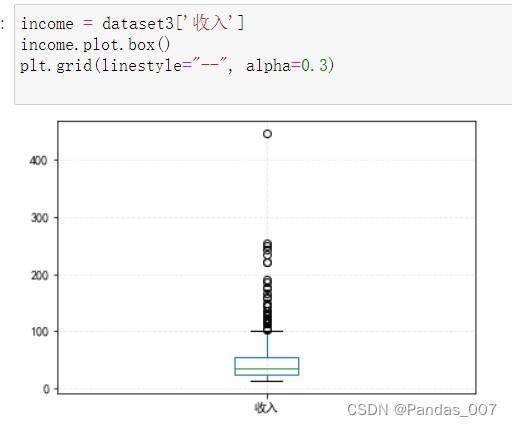
由箱型图可以明显的观察到,大多数客户的收入集中在20-50w之间,有极少数大于100w的收入。
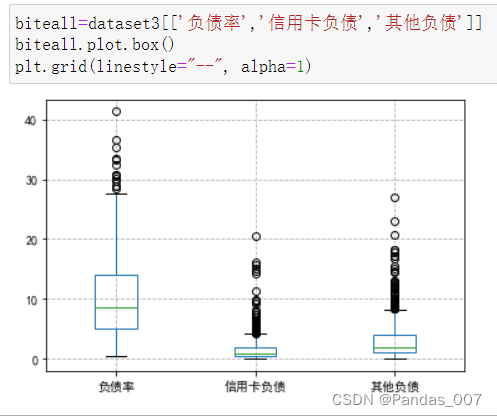
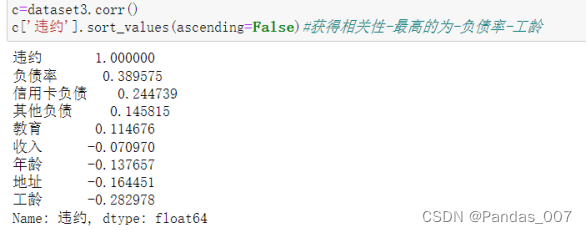
绘制热力图进行展示
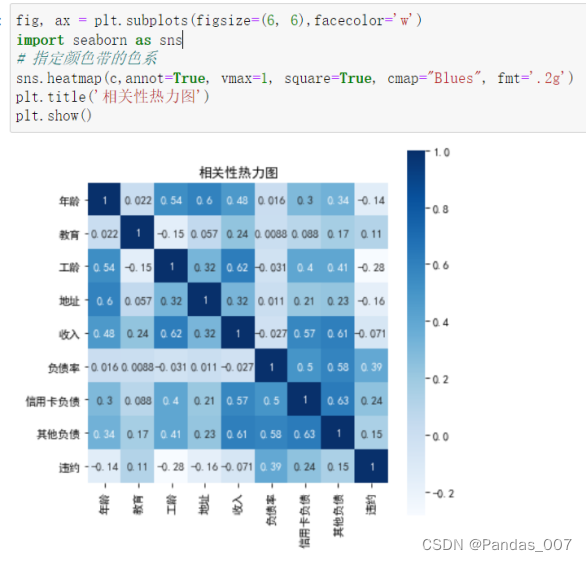
由图可知,负债率、信用卡负债、工龄这3类均达到了0.20以上的相关性。
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
c=dataset3.corr()
c['违约'].sort_values(ascending=False)#获得相关性-最高的为-负债率-工龄
fig, ax = plt.subplots(figsize=(6, 6),facecolor='w')
import seaborn as sns
# 指定颜色带的色系
sns.heatmap(c,annot=True, vmax=1, square=True, cmap="Blues", fmt='.2g')
plt.title('相关性热力图')
plt.show()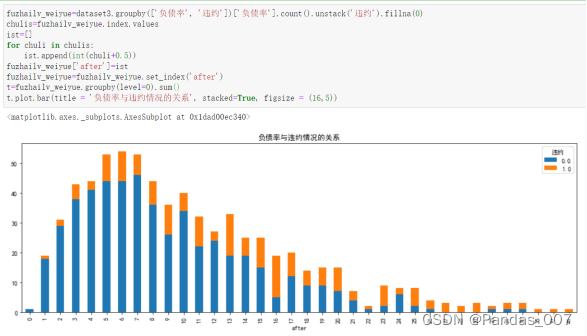
最后选择以下三种方式行数据集的列名构建进行探究
| 自变量X的取值 | Y值 |
| 负债率,信用卡负债 | 违约 |
| 负债率、工龄 | 违约 |
| 信用卡负债、工龄 | 违约 |
X=dataset3.loc[:,['负债率','信用卡负债']].values
y=dataset3.loc[:,'违约'].values

得到以下的图
以下是这块的代码
X=dataset3.loc[:,['负债率','信用卡负债']].values
y=dataset3.loc[:,'违约'].values
size=np.arange(0.1,1,0.1)
scorelist=[[],[],[],[]]
from sklearn.model_selection import train_test_split
for i in range(0,9):
train_X, test_X, train_y, test_y = train_test_split(X ,
y,
train_size=size[i],
random_state=76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
train_X = sc.fit_transform(train_X)
test_X = sc.transform(test_X)
#逻辑回归
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit( train_X , train_y )
scorelist[0].append(model.score(test_X , test_y ))
#决策树
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(train_X, train_y)
scorelist[1].append(model.score(test_X,test_y))
#支持向量机Support Vector Machines
from sklearn.svm import SVC
model = SVC()
model.fit( train_X , train_y )
scorelist[2].append(model.score(test_X , test_y ))
#KNN最邻近算法 K-nearest neighbors
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit( train_X , train_y )
scorelist[3].append(model.score(test_X , test_y ))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
color_list = ('red', 'blue', 'lightgreen', 'cornflowerblue')
for i in range(0,4):
plt.plot(size,scorelist[i],color=color_list[i])
plt.legend(['逻辑回归', '决策树','SVM支持向量机', 'KNN最邻近算法'])
plt.xlabel('训练集占比')
plt.ylabel('准确率')
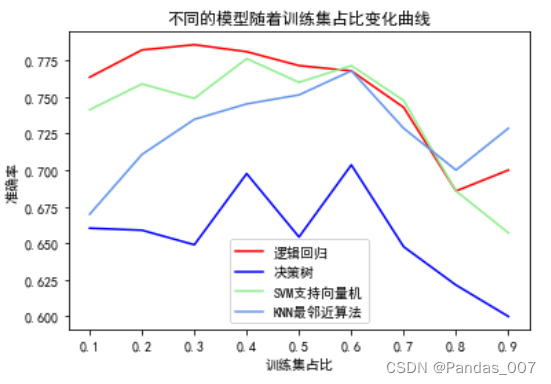
plt.title('不同的模型随着训练集占比变化曲线')
plt.show()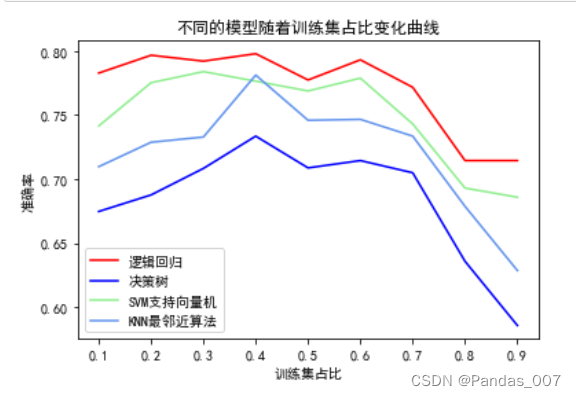
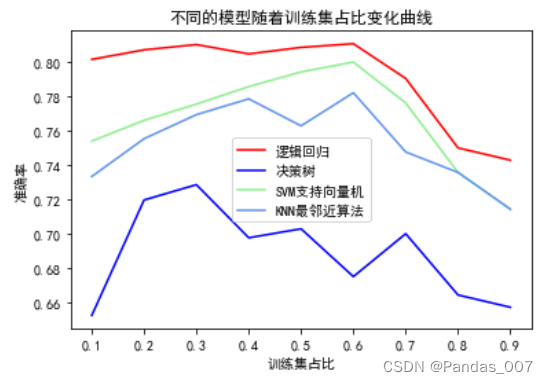
综合上述三个图可知第③种划分中,逻辑回归模型的准确率最高
①决策树的基本训练
②SVM的基本训练
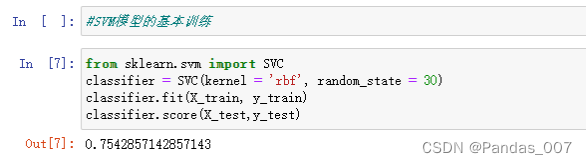
③逻辑回归的基本训练
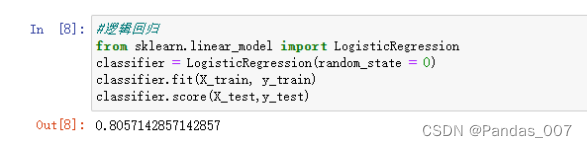
④KNN模型的基本训练

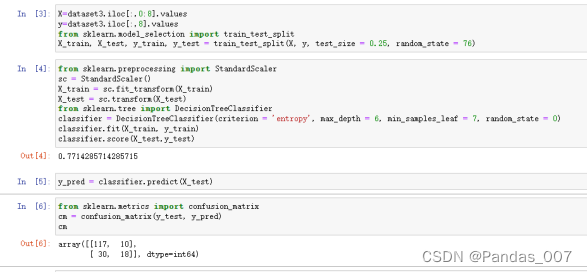
①决策树模基本型评估
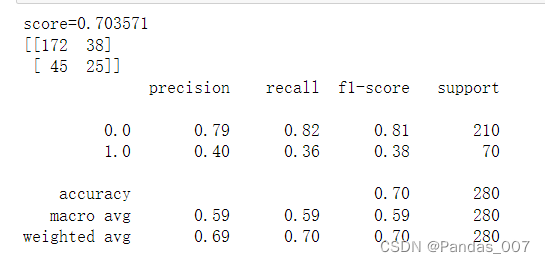
决策树模型:accuracy精确度为0.70
score得分为0.70
②SVM基本模型评估
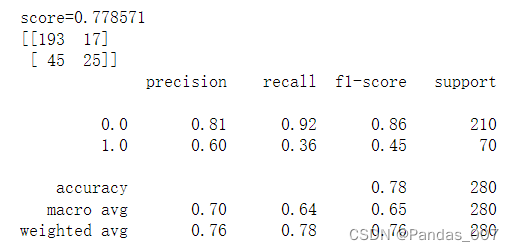
SVM模型:accuracy精确度为0.78
score得分为0.77
③逻辑回归基本模型评估
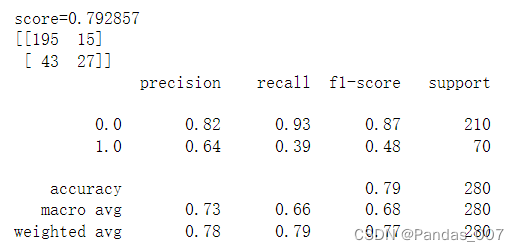
逻辑回归模型:accuracy精确度为0.79
score得分为0.79
④KNN基本模型评估
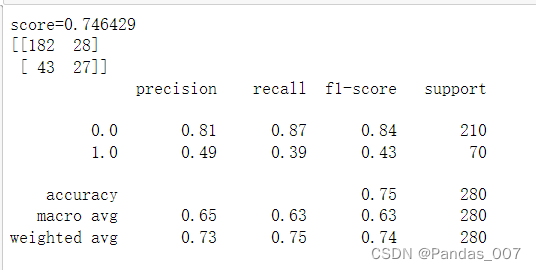
KNN模型:accuracy精确度为0.75
score得分为0.74
max_depth(决策树的最大深度),默认值为None。如果模型样本数量多,特征也多时,推荐限制这个最大深度,具体取值取决于数据的分布。常用的可以取值10-100之间,常用来解决过拟合。
4.3.1当max_depth为自变量,其他参数不变时score的变化情况如图所示:
参数变化情况:
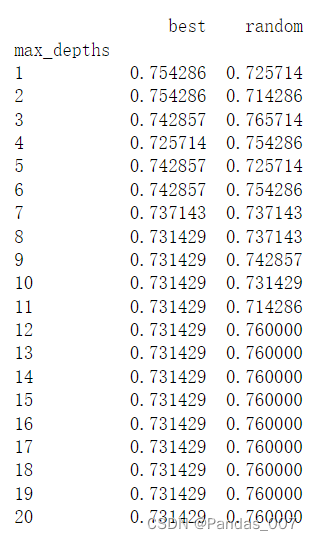
4.3.2当min_samples_leaf和splitter为自变量时,
spliiter参数为’best’和’random’的情况:
参数变化情况列表:
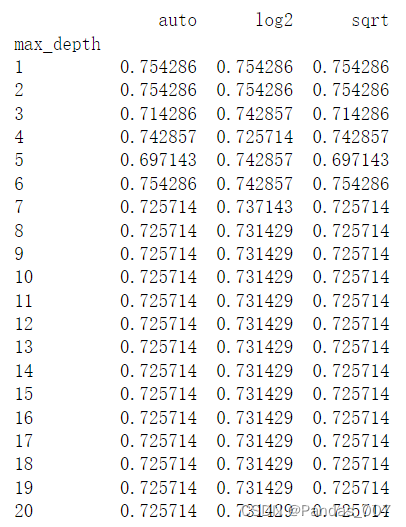
4.3.3当max_depth和max_features为自变量时,max_features为
‘auto’,’log2’,’sqrt’的情况:
详细信息如下:
4.3.4当min_samples_leaf和max_features为自变量时,max_features为‘auto’,’log2’,’sqrt’的情况:
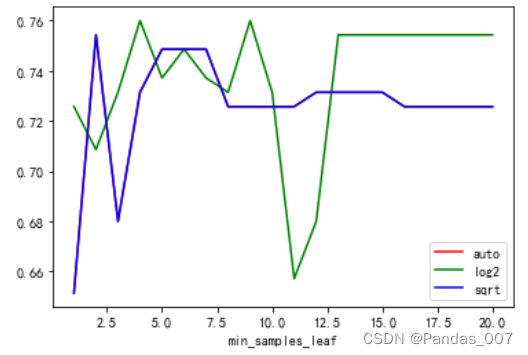
详细信息如下:
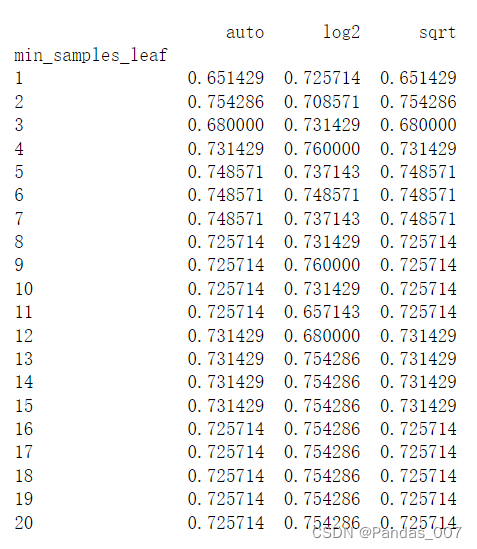
4.3.5最后通过循环,遍历所有可变的参数,进行自动调参得到最高score和accuracy
通过循环设置多个变量,如图所示

from sklearn.tree import DecisionTreeClassifier
best_score=0.0
best_criterion = 'entropy'
best_max_depth=0
best_min_samples_leaf=0
best_splitter='best'
best_max_features=''
#best_size=-1
best_state=-1
best_accuracy=-1
best_all_a_s=-1
from sklearn.model_selection import train_test_split
#for p in range(25,50):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
for j in range(5,20): #dep的值
for m in [2,3,5,10]:#sam的值
for n in ['best','random']: #im的值
for k in ['auto','log2','sqrt']:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
classifier = DecisionTreeClassifier(criterion = 'entropy', max_depth=j,max_features=k,
min_samples_leaf=m,splitter=n,random_state=0)
classifier.fit(X_train, y_train)
score=classifier.score(X_test,y_test)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred)
d=report.replace(" ","").split("\n")
d2=d[5][8:]
d2=float(d2)#得到准确度 accuracy
all=d2+score#获得score和accuracy的最高分
if best_all_a_s<all:
best_score=score
best_max_depth=j
best_min_samples_leaf=m
best_splitter=n
best_max_features=k
# best_min_impurity_decrease=n
#best_size=p2
best_accuracy=d2
best_all_a_s=all
print('best_accuracy={}'.format(best_accuracy))
print('best_all_a_s={}'.format(best_all_a_s))
print('best_score={}'.format(best_score))
print('best_max_depth={}'.format(best_max_depth))
print('best_min_samples_leaf={}'.format(best_min_samples_leaf))
print('best_splitter={}'.format(best_splitter))
print('best_max_features={}'.format(best_max_features))
#print('best_size={}'.format(best_size))
依次遍历循环最终得到最高的score和accuracy的得分如下:
best_score=0.80
best_accuracy=0.79
最高分其对应的最好参数如下:
| max_depth | min_samples_leaf | splitter
| max_features
| random_state |
| 6 | 10 | ‘best | ‘auto’ | 0 |

best_score2=0
best_i=0
best_kernel=''
best_degree=0
asd=["rbf","linear","poly","sigmoid"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
from sklearn.svm import SVC
for k2 in range(1,20):
for h in asd:
classifier = SVC(kernel = h,degree=k2, random_state = 0)
classifier.fit(X_train, y_train)
socre=classifier.score(X_test,y_test)
if best_score2<socre:
best_score2=socre
best_i=i
best_kernel=h
best_degree=k2
print("最好模型如下:")
print(best_i,best_kernel,best_degree,best_score2)
| degree | kernel |
| 1 | ‘rbf’ |

best_penalty=''
best_C=0
best_solver=''
best_score=0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
for u in range(1,101):
for j in ['l1','l2']:
for k2 in ['liblinear','lbfgs','newton-cg','sag']:
try:
u2=u*0.01
from sklearn.linear_model import LogisticRegression
classifer=LogisticRegression(C=u2,penalty=j,solver=k2)
classifer=classifer.fit(X_train,y_train)
score=classifer.score(X_test,y_test)
if best_score<score:
best_score=score
best_penalty=j
best_solver=k2
best_C=u2
except:
pass
print("最好模型如下:")
print(best_score,best_penalty,best_solver,best_C)
| C2 | penalty | solver |
| 0.09 | ‘l2’ | ‘liblinear’ |

from sklearn.neighbors import KNeighborsClassifier
best_score=0.0
best_k=-1
best_weight='uniform'
best_p=0
best_test=-1
best_state=-1
best_all_a_s=0
best_accuracy=0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 76)
for i in ['uniform','distance']:
for j in range(1,21): #k的值
for k in range(1,10): #p的值
classifier = KNeighborsClassifier(n_neighbors = j, weights = i, p = k,metric = 'minkowski')
classifier.fit(X_train, y_train)
score=classifier.score(X_test,y_test)
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred)
d=report.replace(" ","").split("\n")
d2=d[5][8:]
d2=float(d2)#得到准确度 accuracy
all=d2+score#获得score和accuracy的最高分
if best_all_a_s<all:
best_score=score
best_k=j
best_p=k
best_weight=i
best_all_a_s=all
best_accuracy=d2
print("score={},accuracy={}".format(best_score,best_accuracy))
print('best_weight={} 的条件下'.format(best_weight))
print('best_score={}'.format(best_score))
print('best_k={}'.format(best_k))
print('best_p={}'.format(best_p))
print("best_all_a_s={}".format(best_all_a_s))
print("best_accuracy={}".format(best_accuracy))
通过自动化调优调参得到最优参数如下:
| n_neighbors | weights | p |
| 8 | ‘uniform’ | 1 |
综上所述决策树模型的调优调参后的效果最好,精确度达到了0.8

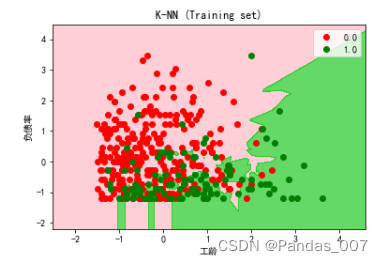
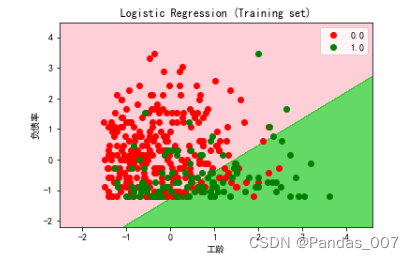
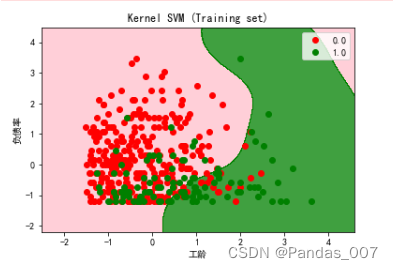
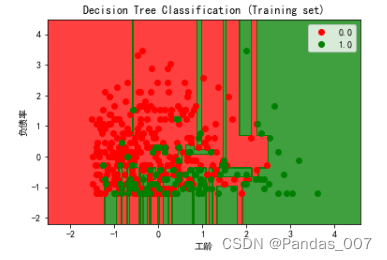
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('pink', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Kernel SVM (Training set)')
plt.xlabel('工龄')
plt.ylabel('负债率')
plt.legend()
plt.show()
由上图可知,逻辑回归的图形明显要好于其他模型的预测
优点:
一、 决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义。
二、 对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
三、 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
缺点:
一、 对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
二、 决策树处理缺失数据时的困难。
三、 过度拟合问题的出现。
四、 忽略数据集中属性之间的相关性。
优点:
一、 简单、有效。
二、 重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
三、 计算时间和空间线性于训练集的规模(在一些场合不算太大)
缺点:
- KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
优点
一、 可以解决小样本情况下的机器学习问题。
二、 可以提高泛化性能。
三、 可以解决高维问题。
缺点
一、 对缺失数据敏感。
优点:
一、预测结果是界于0和1之间的概率;
二、可以适用于连续性和类别性自变量;
三、容易使用和解释;
缺点:
对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
Python分类模型实战(KNN、逻辑回归、决策树、SVM)调优调参,评估模型-综合项目csv资源数据-Python文档类资源-CSDN下载
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序