文章目录
kubectl api-versions # 查看所有apiVersion版本
kubectl api-resources # 查看所有资源类型
kubectl get all -o wide -A
如下:
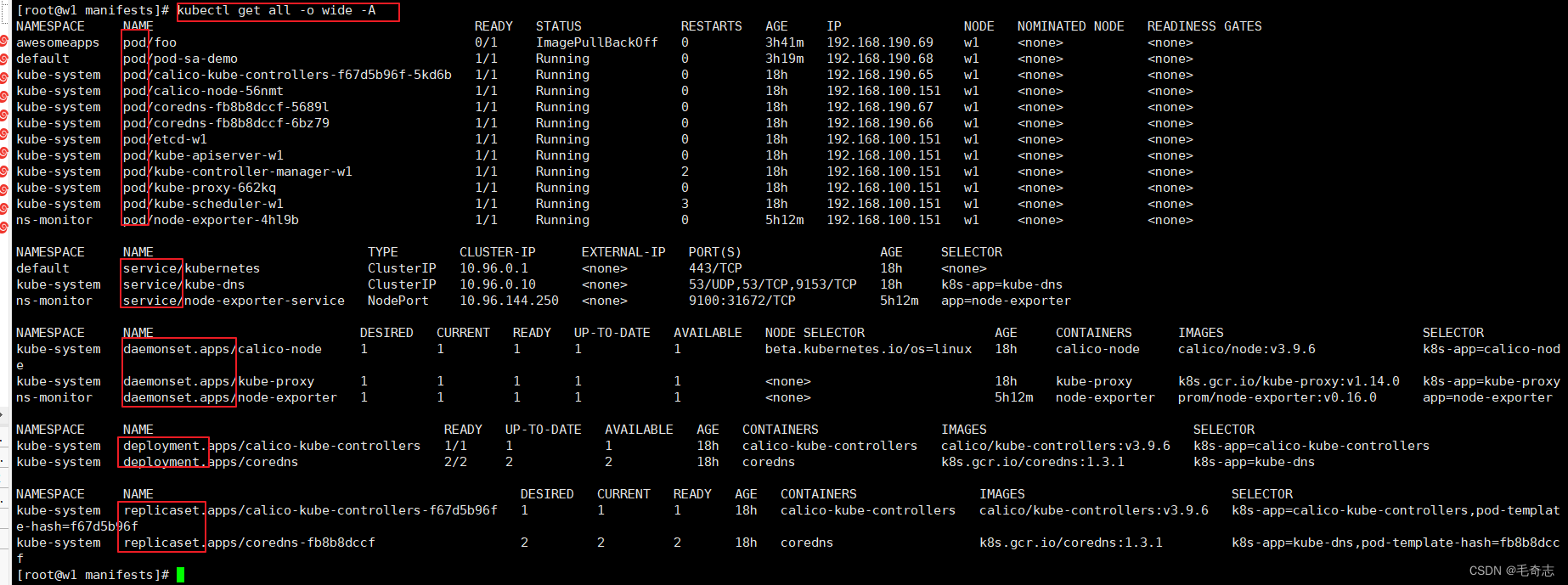
缺点:这种方法 kubectl get all 其实查询出来不是全部资源,仅仅是常用资源,仅仅是 service - deployment/statefulset/daemonset/job/cronjob - replicaset - pod 这个绑定链资源,还有 rbac 的 role rolebinding,配置文件 configmap secrets,服务账号 serviceAccount ,service与pod的绑定endpoints都没有查询出来,且看下文。
只需要查询一个命名空间就好
kubectl api-resources --verbs=list --namespaced -o name
解释
kubectl api-resources 列出所有资源
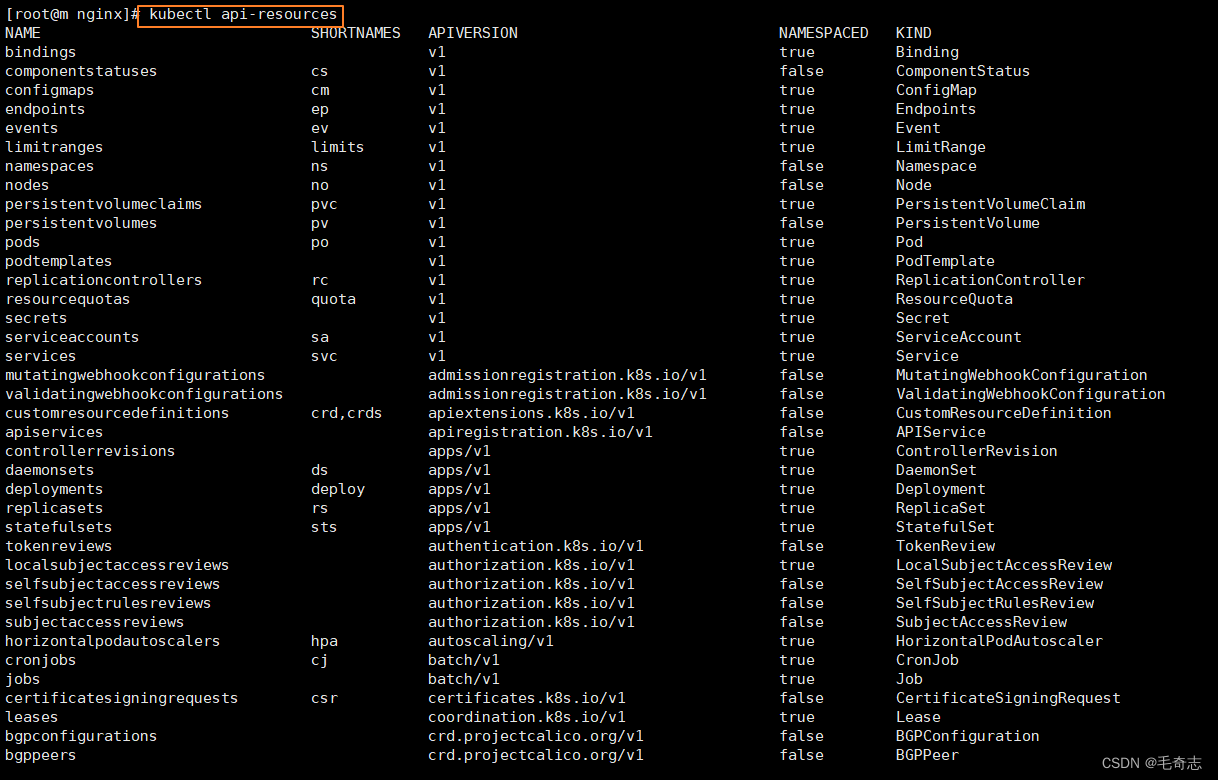
-o 表示输出 -o name 表示仅仅输出名称 (类似mysql语句中select的功能)

kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -A

当然,也可以只查询一个命名空间下的所有资源
kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -n xxx(ns-name)
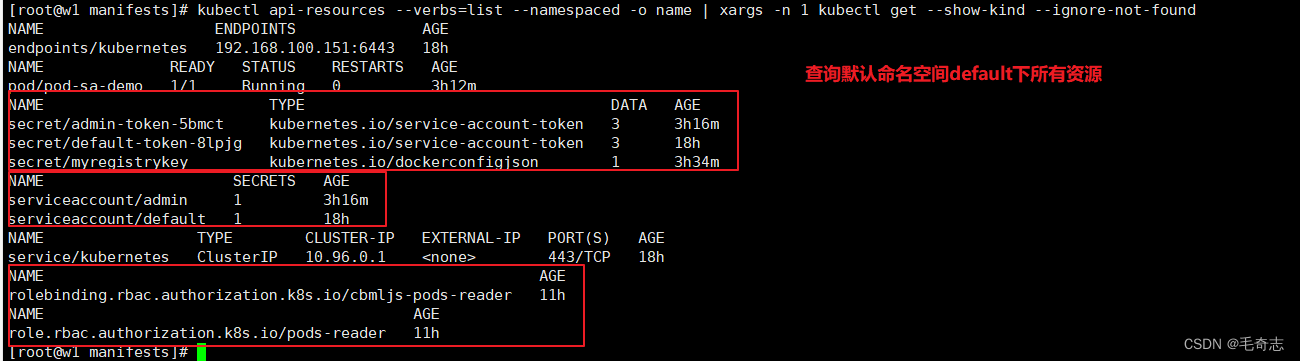
熟悉这三条命令,kubernetes的查询操作都在这里了
kubectl get all -o wide -A 【最简单,但是不是查看所有资源】
kubectl api-versions 【查看所有apiVersion版本】
kubectl api-resources 【查看所有资源类型】
kubectl api-resources --verbs=list --namespaced -o name
kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -A
最低成本学习法,记得最少,学习的时间成本才最低。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
当我的预订模型通过rake任务在状态机上转换时,我试图找出如何跳过对ActiveRecord对象的特定实例的验证。我想在reservation.close时跳过所有验证!叫做。希望调用reservation.close!(:validate=>false)之类的东西。仅供引用,我们正在使用https://github.com/pluginaweek/state_machine用于状态机。这是我的预订模型的示例。classReservation["requested","negotiating","approved"])}state_machine:initial=>'requested
我有这个html标记:我想得到这个:我如何使用Nokogiri做到这一点? 最佳答案 require'nokogiri'doc=Nokogiri::HTML('')您可以通过xpath删除所有属性:doc.xpath('//@*').remove或者,如果您需要做一些更复杂的事情,有时使用以下方法遍历所有元素会更容易:doc.traversedo|node|node.keys.eachdo|attribute|node.deleteattributeendend 关于ruby-Nokog
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时