文章目录
国内云服务器主要用来部署镜像网站,,国外服务器主要用来部署HTTP/HTTPS代理,因为目前国内环境访问Open AI的API服务器会有问题,所以最好有一个在美国的服务器,部署完成后就能达到快速访问ChatGPT的效果。
参考链接:https://itlao5.com/10247.html
参考链接:https://blog.csdn.net/weixin_44825557/article/details/129345140
V-u-l-t-r-服务器有些新地区刚开比较划算,性能基本能满足搭建梯子和HTTP代理
GitHub地址:chatgpt-mirror
蓝奏云:https://wwvb.lanzout.com/ik7Wy0tbx1vg 密码:ccng
我是使用自己的域名部署了一个网站,可以直接在浏览器输入网址后访问,这里就不放出来了,因为我这种部署方式用的是自己的API密钥,目前免费额度只有5$ ,太多人用很快就没了,你们可以用自己的API key,这个会在后面讲到!!![/狗头保命]

重要:部署时会修改glibc库,为了防止云服务器被搞坏,请提前进行备份或者创建快照重要:部署时会修改glibc库,为了防止云服务器被搞坏,请提前进行备份或者创建快照重要:部署时会修改glibc库,为了防止云服务器被搞坏,请提前进行备份或者创建快照在Vultr服务器上部署代理
yum install tinyproxy
# 修改配置文件
# 可以修改listen的IP还有监听的端口
vim /etc/tinyproxy/tinyproxy.conf
# 启动
systemctl start tinyproxy
# 开机自启
systemctl enable tinyproxy
在云服务器上部署
该项目明确表明需要用到Node.js 18.x
否则构建时会出现问题
因为系统中不同的项目可能需要不同的Node.js版本,为了方便管理,安装nvm
# nvm允许您通过命令行快速安装和使用不同版本的node
# 安装脚本:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh | bash
# 运行上述命令下载脚本并运行它。该脚本将 nvm 存储库克隆到~/.nvm,并尝试将下面代码段中的源代码行添加到正确的配置文件(~/.bash_profile、~/.zshrc、~/.profile或~/.bashrc)。
# 使配置生效
source .bashrc
验证:
a:nvm ls-remote
查看所有可安装的node版本号
b:nvm install 13.0.0
安装13.0.0版本的node
c:nvm install 15
安装15系列中最高版本的node
比如15系列有15.0.0, 15.0.1, 15.1.1, 15.1.2, 15.2.1, 15.3.0,那么最后安装的就是15.3.0
d:nvm install 14.2
安装14.2系列中最高版本的node
e:nvm list
查看已安装的所有node版本以及默认的版本
f:nvm use 13.0.0
使用13.0.0版本的node
g:nvm use 14.2
使用14.2系列的最高版本node
h:nvm uninstall 13.0.0
卸载13.0.0版本的node
# 安装对应版本node.js
nvm ls-remote
nvm install v18.16.0
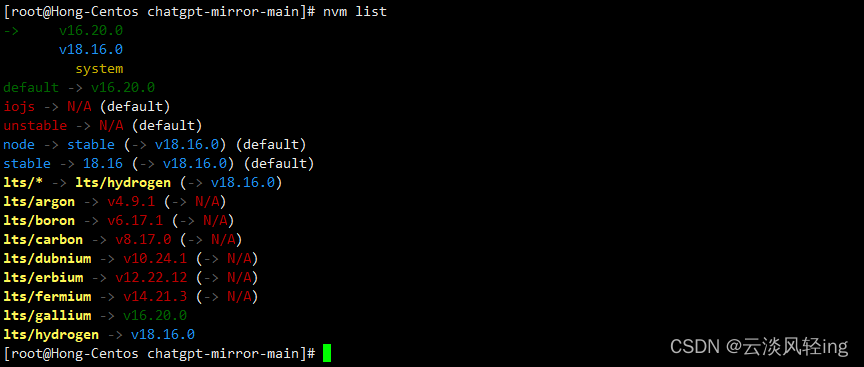
安装好nvm和nodejs后
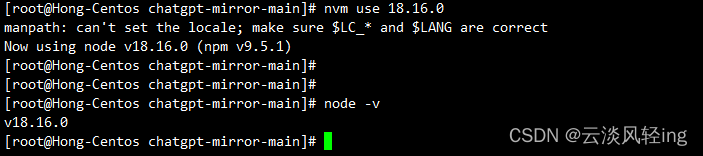
# 版本切换
nvm use 18.16.0
# 安装pnpm
npm install pnpm -g
# 环境验证
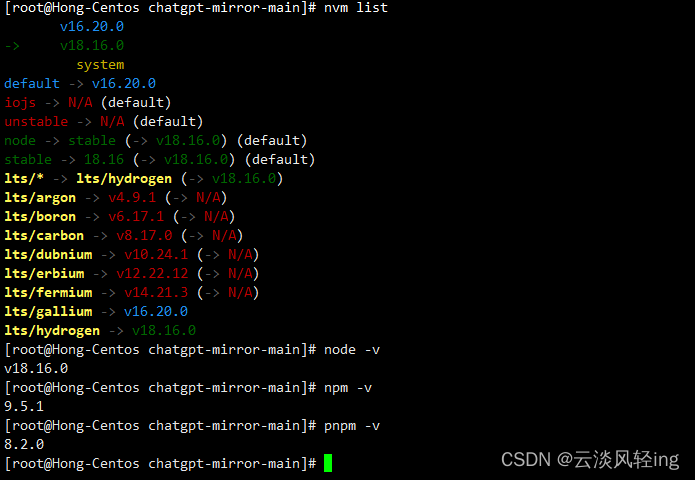
nvm list
node -v
npm -v
pnpm -v
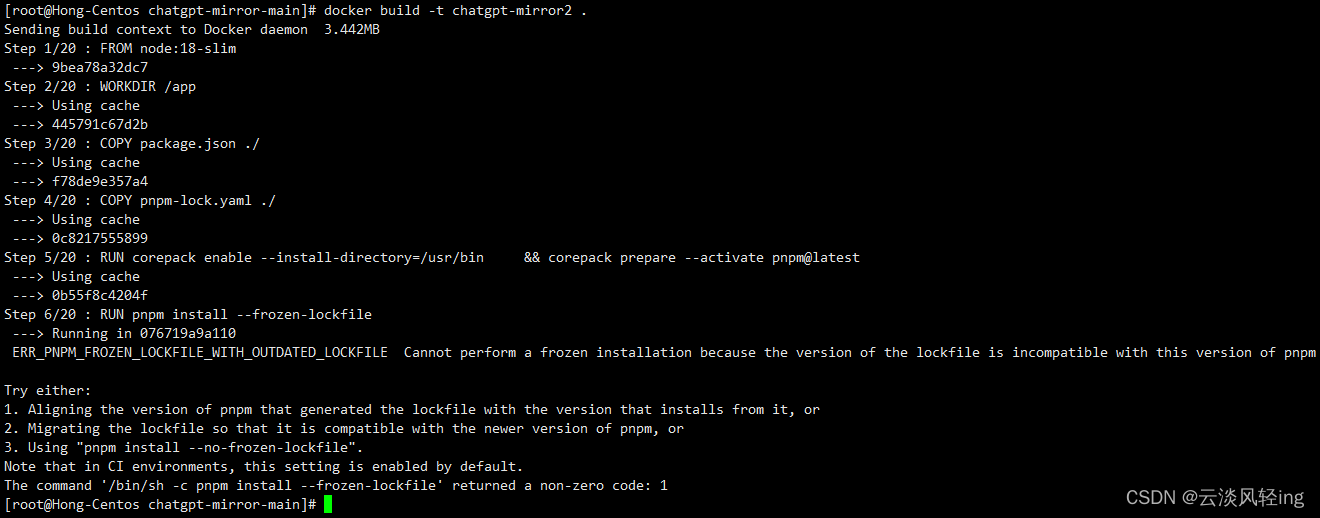
在上述步骤中会出现一些报错,例
node: /lib64/libm.so.6: version `GLIBC_2.27' not found (required by node)
node: /lib64/libc.so.6: version `GLIBC_2.25' not found (required by node)
node: /lib64/libc.so.6: version `GLIBC_2.28' not found (required by node)
node: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by node)
node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found (required by node)
node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found (required by node)
这是因为node.js 18.0依赖与高版本的glibc库,所以需要进行更新,从报错可知,我需要的最高版本为GLIBC_2.28,所有我需要安装这个版本
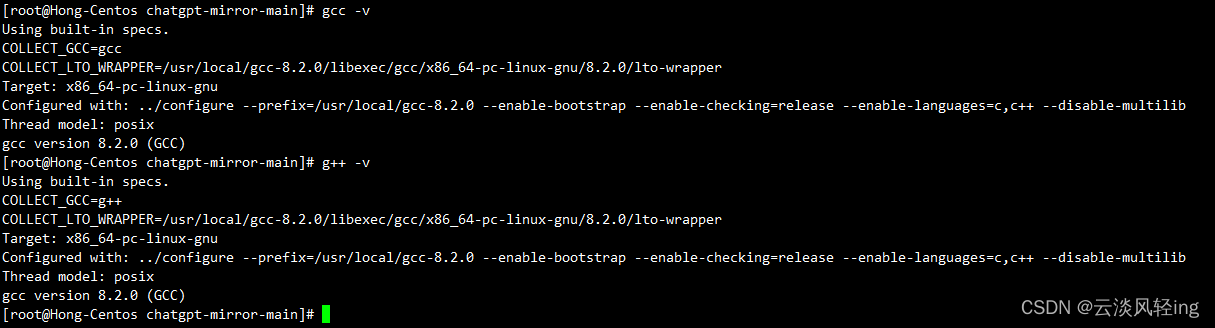
先更新gcc与g++,最新版的也不兼容,需要下载gcc-8.2.0
# 安装make
wget http://ftp.gnu.org/pub/gnu/make/make-4.3.tar.gz
tar -zxvf make-4.3.tar.gz
cd make-4.3
./configure --prefix=/usr
type make
make check
make install
# 安装gcc、g++
wget https://mirrors.tuna.tsinghua.edu.cn/gnu/gcc/gcc-8.2.0/gcc-8.2.0.tar.gz
tar -zxvf gcc-8.2.0.tar.gz
cd gcc-8.2.0
# 下载gmp mpfr mpc等供编译需求的依赖项
./contrib/download_prerequisites
# 配置
mkdir build
cd build
../configure --prefix=/usr/local/gcc-8.2.0 --enable-bootstrap --enable-checking=release --enable-languages=c,c++ --disable-multilib
# 编译安装 需要很久很久很久
make -j 2
make install
更新glibc库
wget http://ftp.gnu.org/pub/gnu/glibc/glibc-2.28.tar.gz
tar -zxvf glibc-2.28.tar.gz
cd glibc-2.28/
mkdir build
cd build
../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin
make && make install
# 查看文件软链接
ls -l /lib64/libc.so.6
# 再次查看系统中可使用的glibc版本
strings /lib64/libc.so.6 |grep GLIBC_
strings /usr/local/gcc-8.2.0/lib64/libstdc++.so.6 | grep GLIBCXX_
# 升级GLIBCXX
cd /usr/local/gcc-8.2.0/lib64
strings ./libstdc++.so.6 |grep GLIBCXX_
cp libstdc++.so.6.0.25 /usr/lib64/
# 重新链接libstdc++.so.6
cd /usr/lib64/
rm libstdc++.so.6 -f
ln -s ./libstdc++.so.6.0.25 ./libstdc++.so.6
# 查看可用版本
strings /lib64/libstdc++.so.6 |grep GLIBCXX_
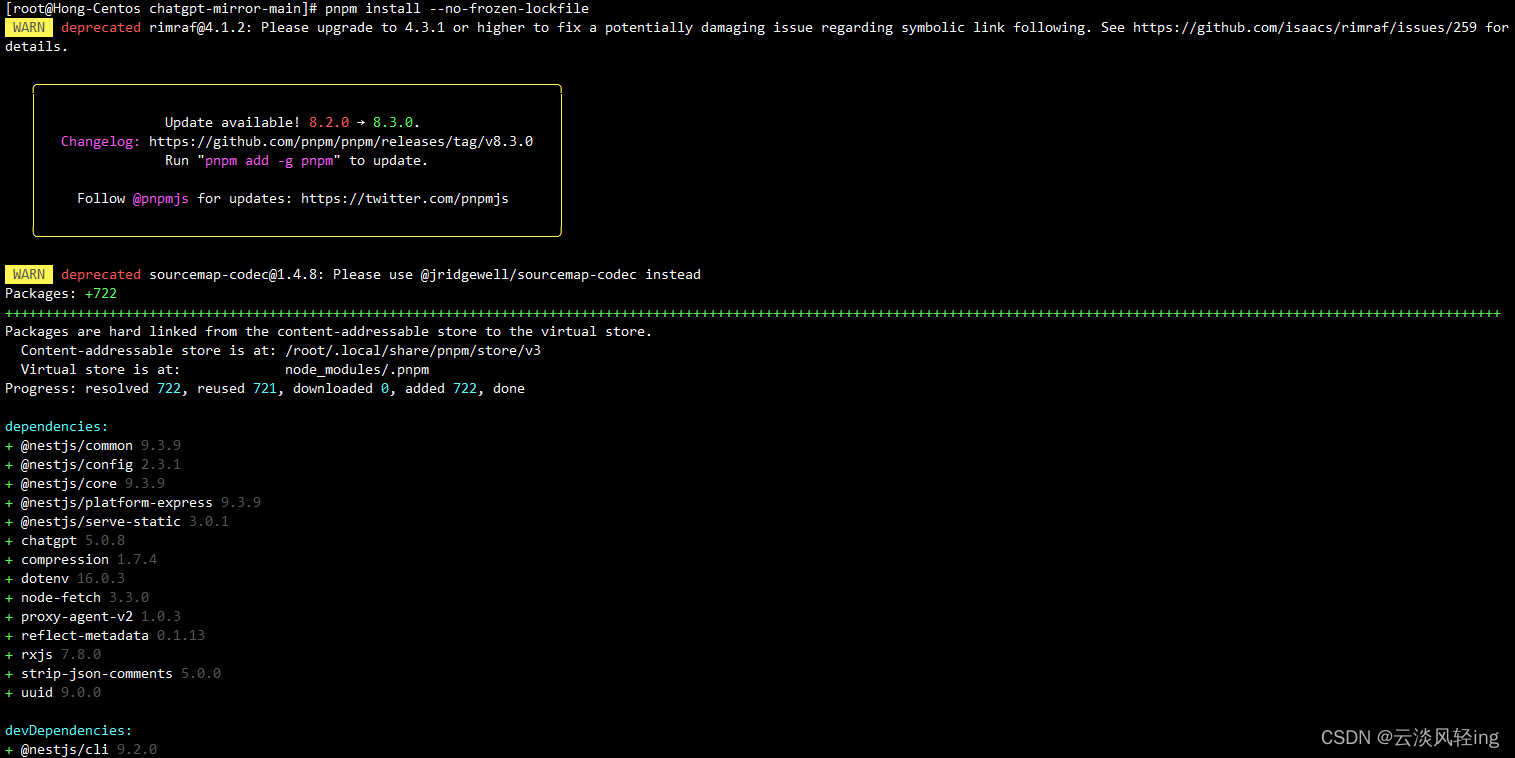
因为我采用的是用docker容器的方式部署,所以需要安装docker
cd /etc/yum.repos.d/
wget https://download.docker.com/linux/centos/docker-ce.repo
yum list docker-ce --showduplicates | sort -r
yum install docker-ce-18.06.3.ce-3.el7 -y
# 启动docker服务
systemctl start docker
# 设置docker服务开机自启
systemctl enable docker
git clone https://github.com/yuezk/chatgpt-mirror.git
cd chatgpt-mirror
# 新建一个 .env 文件,输入 OPENAI_API_KEY:使用自己申请的API密钥
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# optional, support http or socks proxy
# 代理配置
HTTP_PROXY=http://proxy-server-ip:port
# 构建镜像
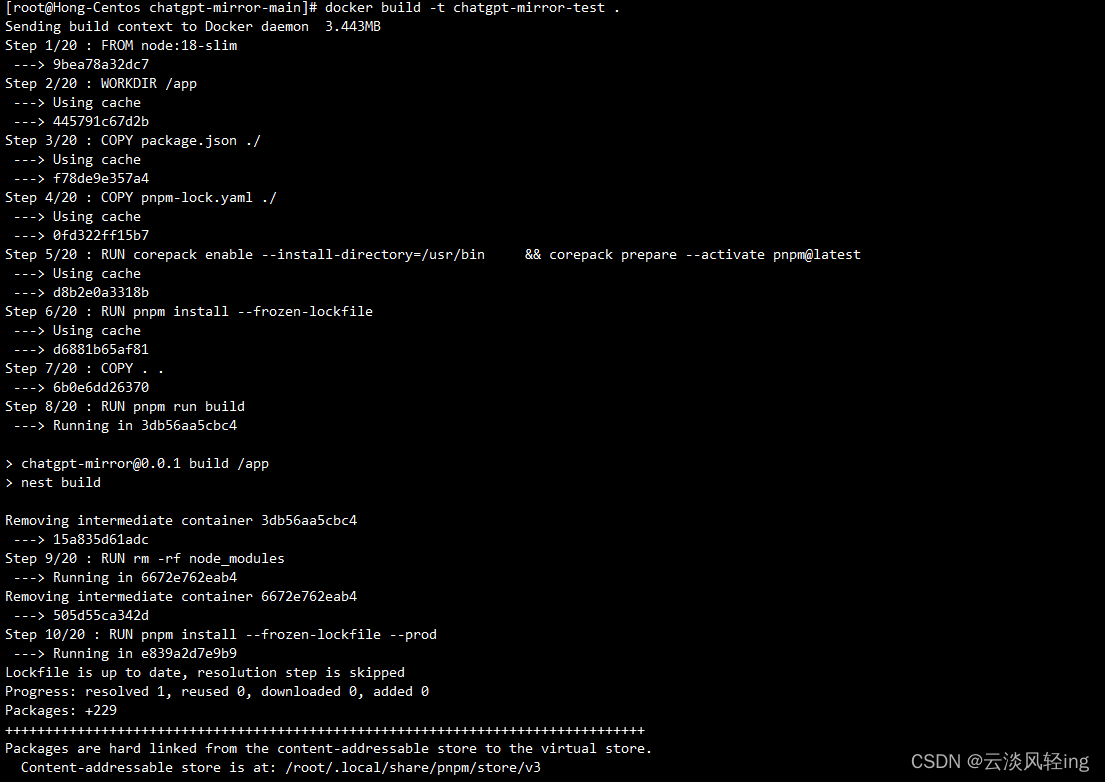
docker build -t chatgpt-mirror-test .
# 运行容器
docker run -itd -p 0.0.0.0:3000:3000 --name chatgpt -h chatgpt -m 1024m --cpus=1 --env-file .env chatgpt-mirror-test
此时输入http://IP:3000便可以访问网址,记得在云服务器管理后台开放该端口
若出现如下错误,可执行
pnpm install --no-frozen-lockfile
docker build -t chatgpt-mirror-test .
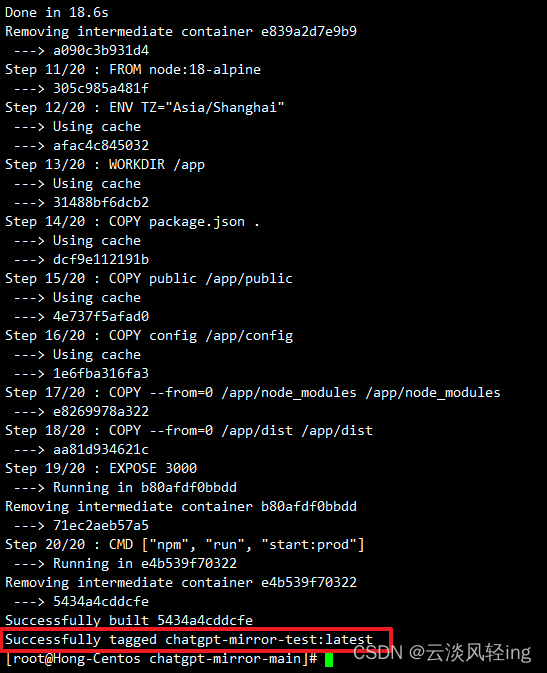
此时可以将之前创建的容器进行删除,同时云服务器那边只需要开发80和443端口
docker stop chatgpt && docker rm chatgpt
# 启动容器
docker run -itd -p 127.0.0.1:3000:3000 --name chatgpt -h chatgpt -m 1024m --cpus=1 --env-file .env chatgpt-mirror
使用宝塔后台添加网站
添加反向代理
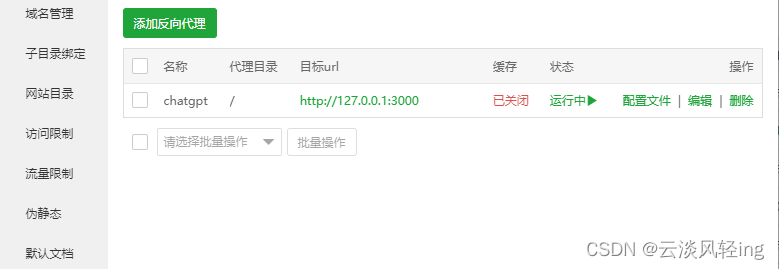
此时直接访问配置好的网站名便可访问镜像网站。
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
在这段Ruby代码中:ModuleMClassC当我尝试运行时出现“'M:Module'的未定义方法'helper'”错误c=M::C.new("world")c.work但直接从另一个类调用M::helper("world")工作正常。类不能调用在定义它们的同一模块中定义的模块函数吗?除了将类移出模块外,还有其他解决方法吗? 最佳答案 为了调用M::helper,你需要将它定义为defself.helper;结束为了进行比较,请查看以下修改后的代码段中的helper和helper2moduleMclassC
我想在Windows7上安装带有ruby1.9.3的rspec-railsgem。我收到一些错误消息,提示无法安装某些json库。所以,我使用下面的说明来解决它。来源=The'json'nativegemrequiresinstalledbuildtools从[rubyinstaller.org][3]下载[Ruby1.9.3][2]从[rubyinstaller.org][3]下载DevKit文件对于Ruby1.9.3,使用[DevKit-tdm-32-4.5.2-20110712-1620-sfx.exe][4]将DevKit解压到路径C:\Ruby193\DevKit运行cd
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa
来自Java,我正在尝试在Ruby中实现LinkedList。我在Java中实现它的通常方法是有一个名为LinkedList的类和一个名为Node的私有(private)内部类,其中LinkedList的每个对象都作为Node对象。classLinkedListprivateclassNodeattr_accessor:val,:nextendend我不想将Node类暴露给外部世界。然而,通过Ruby中的这个设置,我可以使用这个访问LinkedList类之外的私有(private)Node类对象-node=LinkedList::Node.new我知道,在Ruby1.9中,我们可以使用
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act