目录
前言 (目标链接放评论区了)
第二步,拉取视频网址,拿到contId,获取请求视频的json网址
我们在上一节学习了一些Request的进阶用法和session会话的概念以及很多安全校验信息。那么这一节我们将以某视频网站(链接在评论区)为例,展示一下我们的学习成果。
抓取某视频网站已知页面所包含的视频资源并保存到本地,绕过网站的反爬手段:防盗链。
1. 首先打开想要抓取的页面,检查页面源代码,利用我们熟悉的开发者工具(F12)来检查视频资源所在的标签,可以通过下图所示源代码轻松找到:
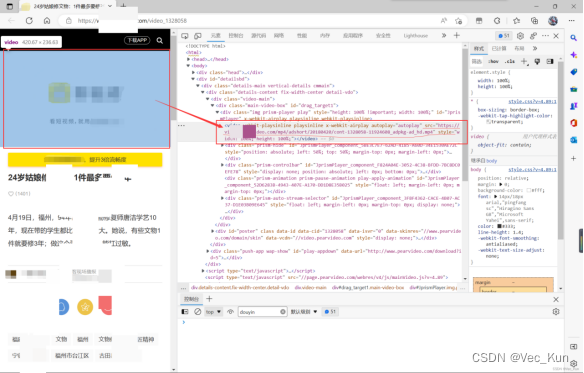
2. 把src里面包含的视频链接复制,访问页面观察是不是视频资源:
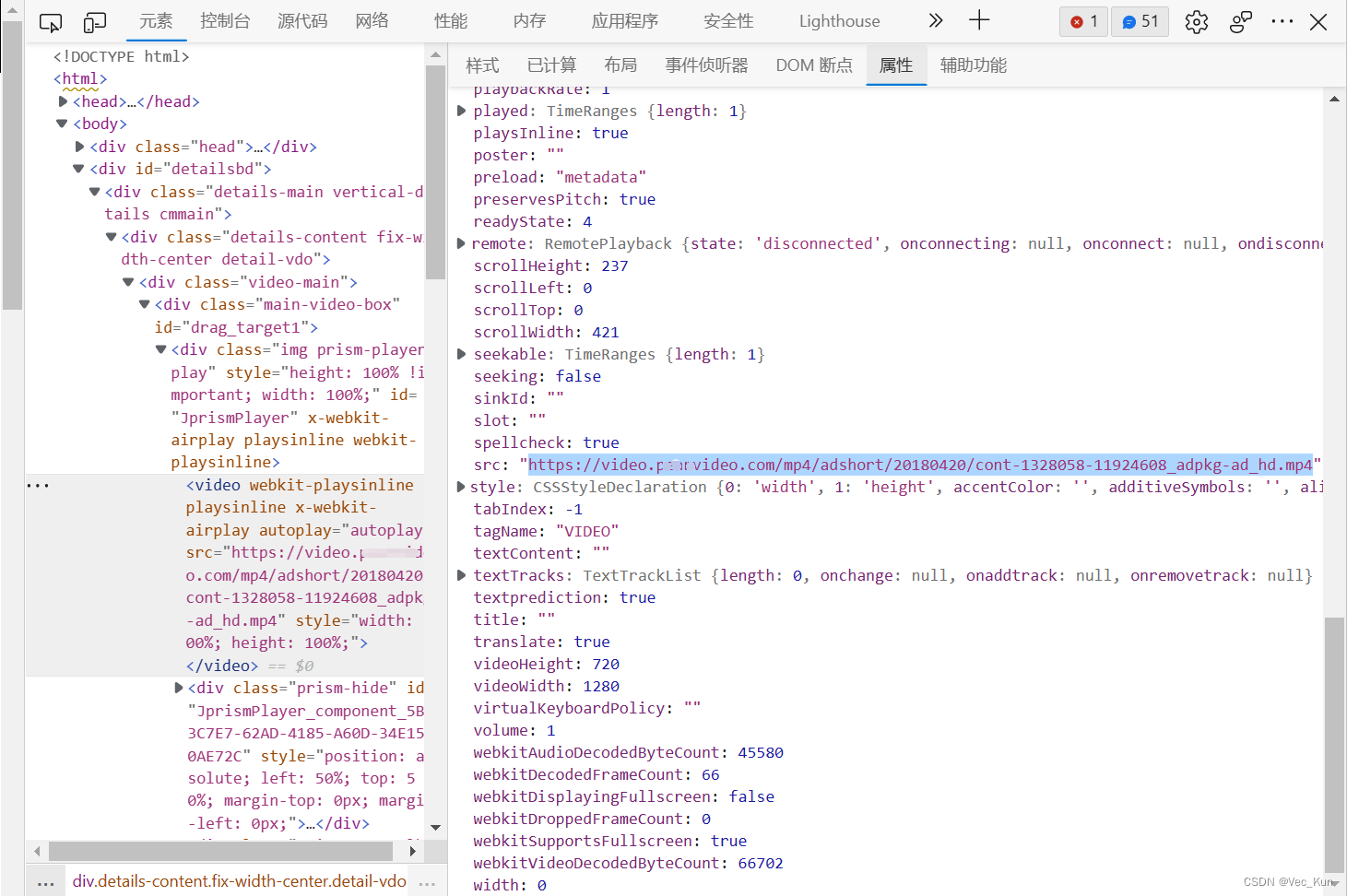
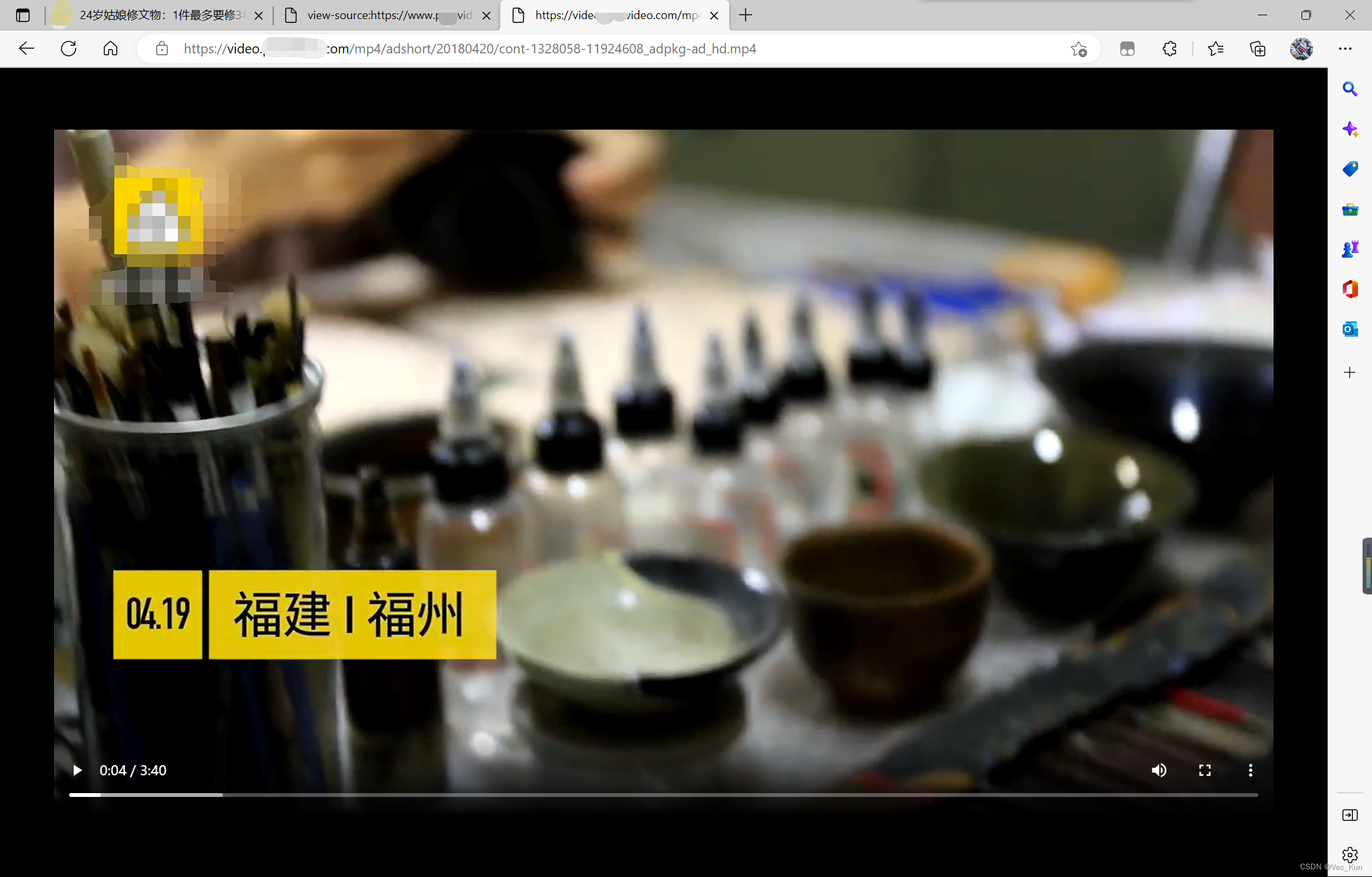 可以看到,我们成功拿到了视频资源。但是我们真的成功了吗?检查页面源代码,我们拿到的页面源代码里面有这样的<video>标签吗?或者是否在源代码中存在我们的视频链接呢?
可以看到,我们成功拿到了视频资源。但是我们真的成功了吗?检查页面源代码,我们拿到的页面源代码里面有这样的<video>标签吗?或者是否在源代码中存在我们的视频链接呢?
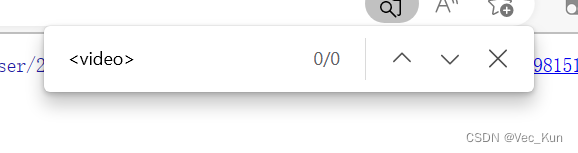
3. 源代码验证
我们查看页面源代码,CTRL+F查找,发现并没有上述资源:
实际上,我们使用开发者工具检查页面时,它所显示的"源代码"并不是原本的,而是已经通过了一系列的解析,呈现给我们所看到整个页面的资源信息。如果我们用PyCharm直接访问的话,是拿不到经处理的<video>标签的,所以这样抓视频链接是行不通的。但至少我们已经知道了我们想拿到的目标链接是什么了。
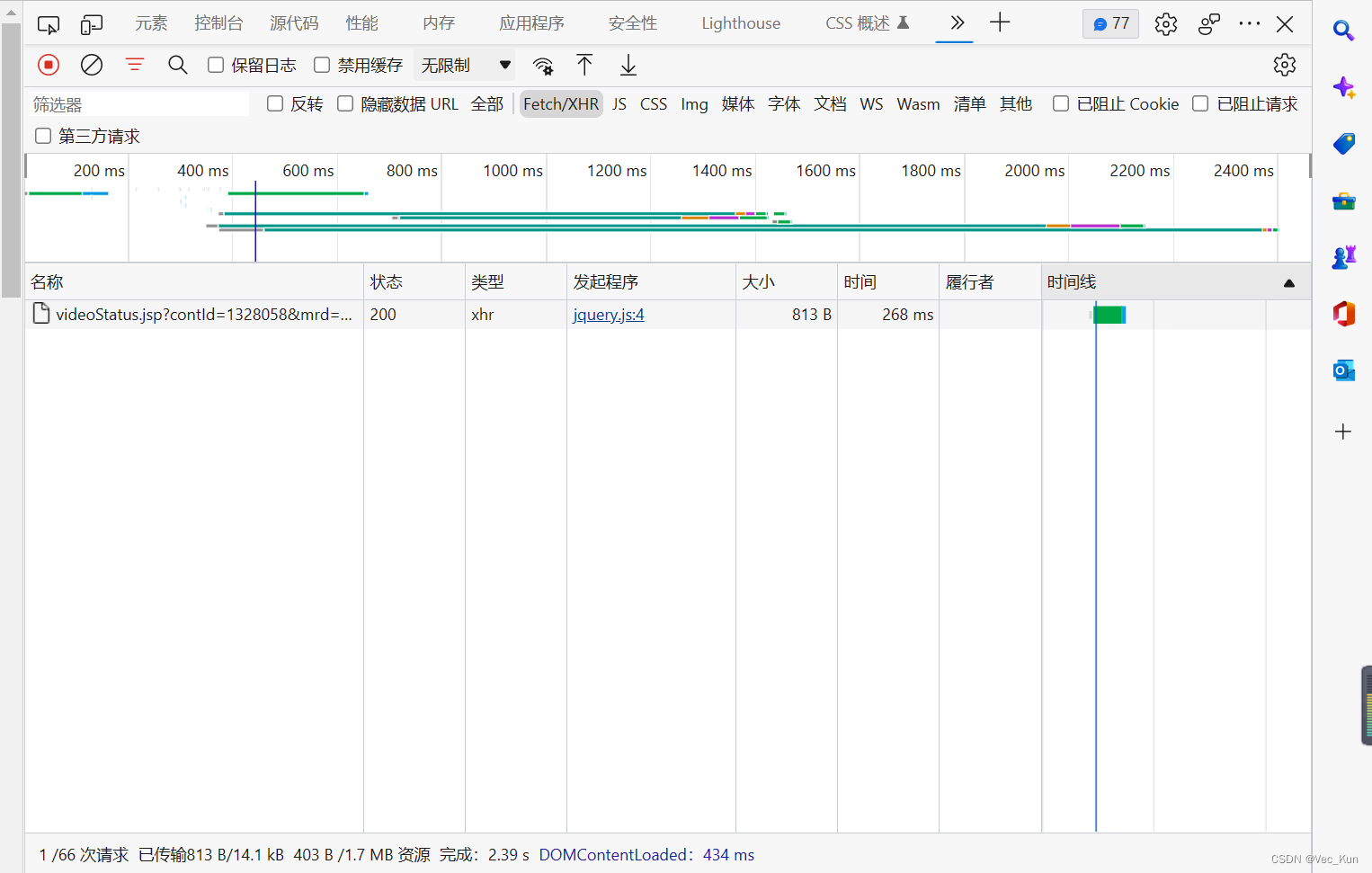
4. 开发者工具检查网络请求
打开开发者工具,切换到网络(Network) ,筛选选项到Fetch/XHR上。所谓XHR就是XMLHttpRequest,是浏览器提供的JavaScript对象,通过它,可以请求服务器上的数据资源。所以我们切换到这个筛选项,因为源代码里面没有,一般就一定在js对象中请求。
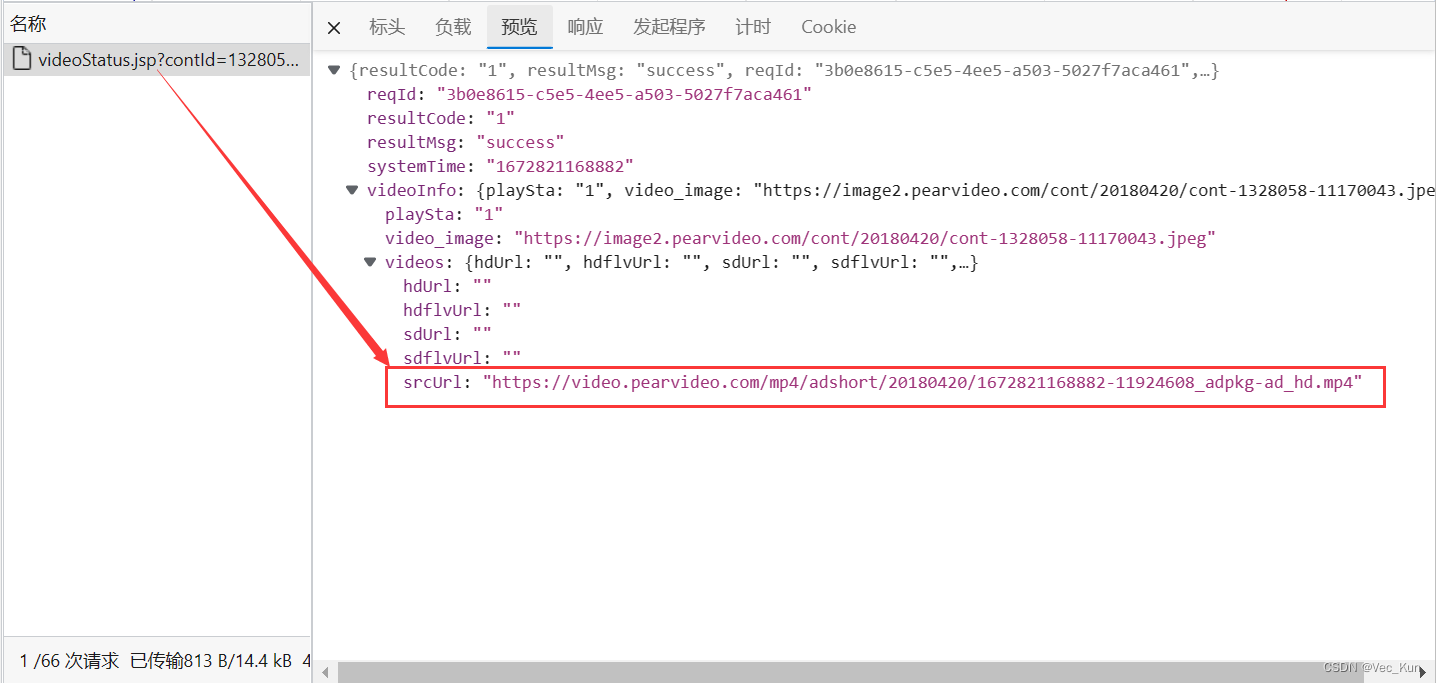
5. 打开上述请求进行检查,进行预览,一层层解开json数据,找到请求链接:
6. 访问此链接,查看是否能请求到视频资源:
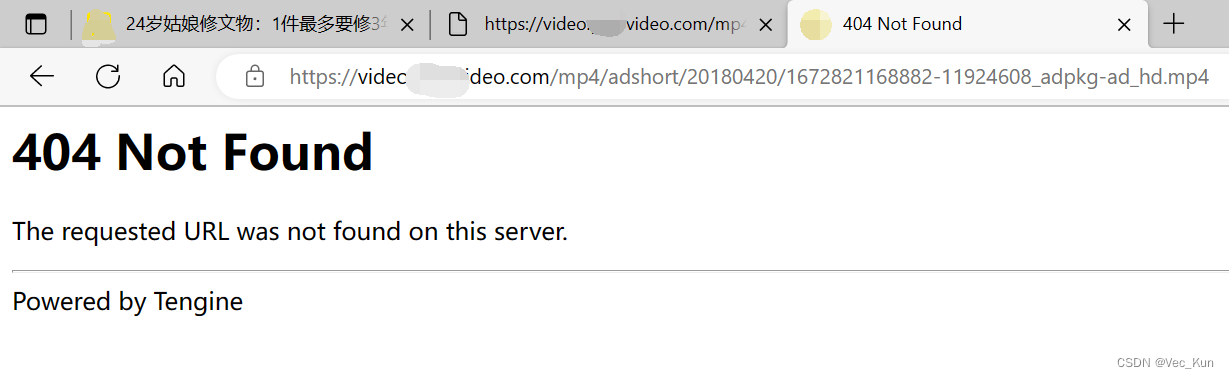
7. 发现无法访问,那么我们来对比两个链接的不同之处:
正确的:https://video.某某video.com/mp4/adshort/20180420/cont-1328058-11924608_adpkg-ad_hd.mp4
错误的:https://video.某某video.com/mp4/adshort/20180420/1672821168882-11924608_adpkg-ad_hd.mp4对比发现,只有‘cont-1328058’与‘1672821168882’的区别。那么我们只要搞清楚这两项分别是什么,再进行替换就OK了。
8. 查找两项的含义
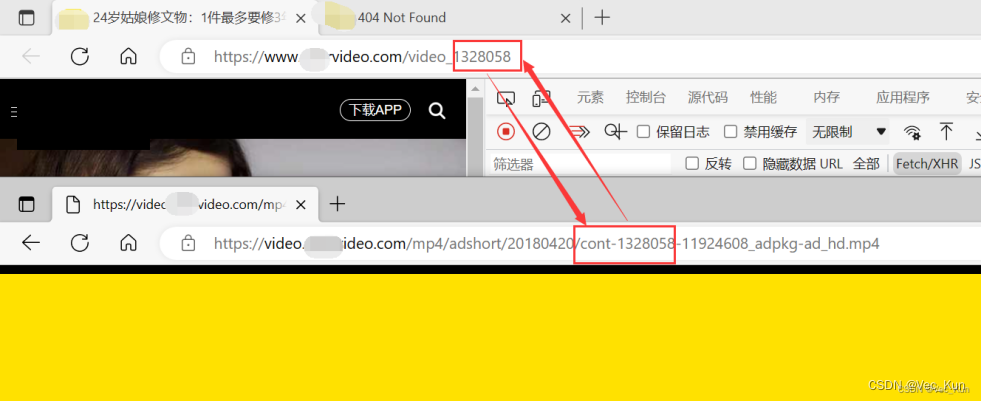
发现‘cont-1328058’后面的一串数字就是我们访问页面下划线后的那串数字!

发现‘1672821168882’就是我们抓取到json数据中的‘systemTime’!
现在思路就十分清晰了,直接进入代码部分。
# 1. 从链接拿到contId
# 2. 拿到videoStatus返回的json找到srcURL
# 3. 对srcURL里面的内容进行替换
# 4. 下载视频
import requests# 拉取视频的网址
url = "见评论区"
contId = url.split("_")[1]熟悉Python基础的同学应该知道split()是把目标字符串分成两部分,我们要的是下划线的后半部分,所以拿[1]。
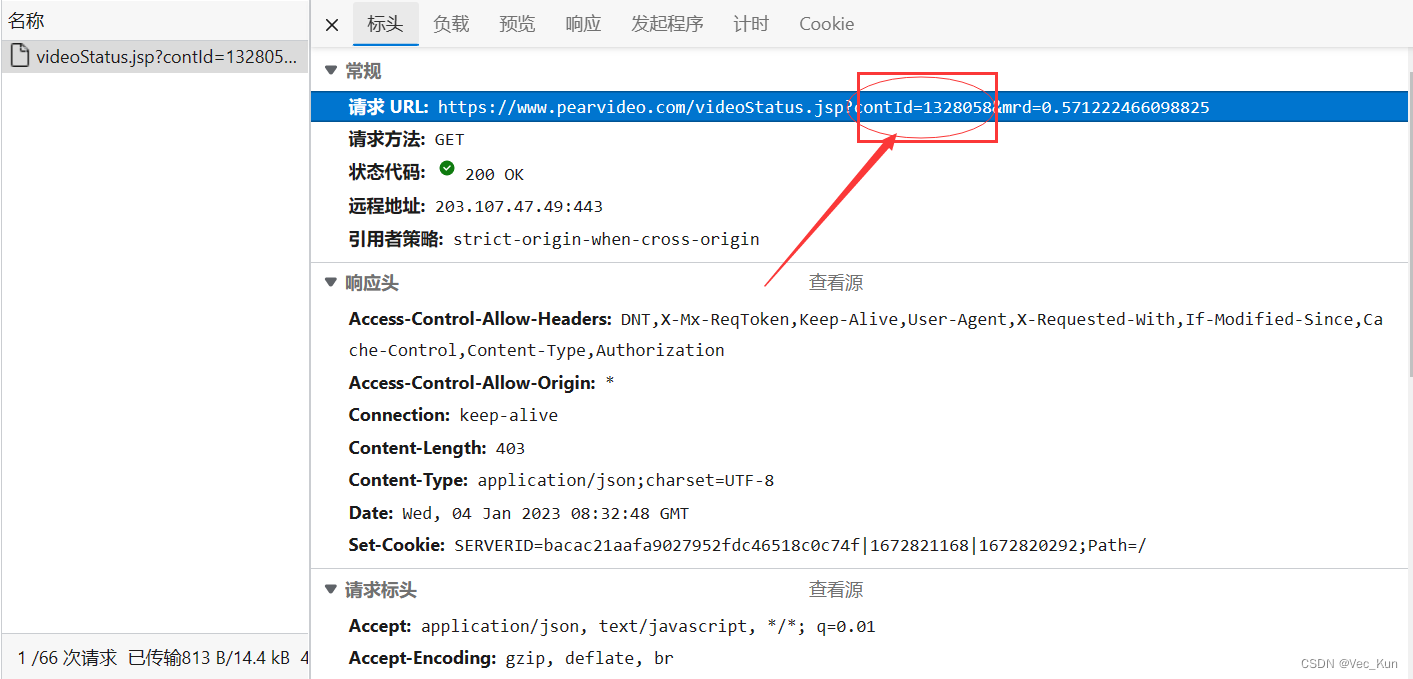
现在我们拿到了这部分,后面的mrd应该是一个自动生成的随机数,不用管它也可以。
生成普适的视频资源请求:
videoStatusUrl = f"https://www.某某video.com/videoStatus.jsp?contId={contId}"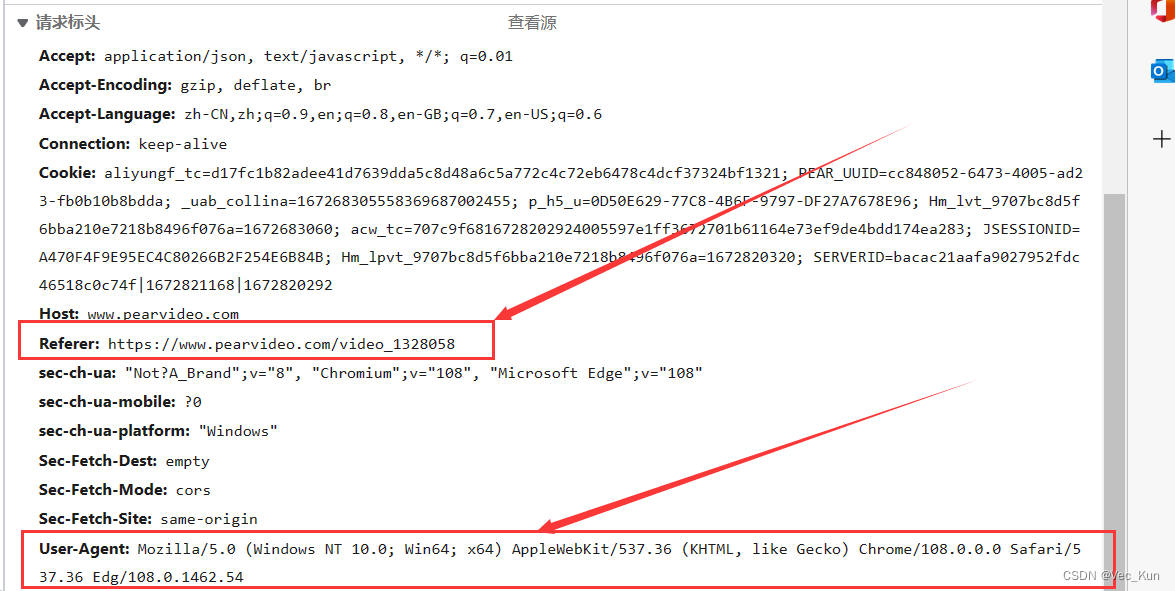
从请求标头中可以拿到UA,而我们只将UA放入headers中时是访问不到页面的,这是由于Referer的原因。
它就是我们一直在说的防盗链:,功能就是溯源,告诉服务器当前请求的上一级是谁?也就是从哪个页面跳转访问的。服务器会拒绝非页面跳转的访问,既然他要,那我们在headers里面也声明一下就好了。
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
# 防盗链: 溯源, 当前本次请求的上一级是谁
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()观察到防盗链就是我们最初的页面,那么直接把防盗链设置成它就好。
由于返回的是json文件,我们对它进行resp.json()的处理。
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")# 下载视频
with open("3_result.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)# 1. 拿到contId
# 2. 拿到videoStatus返回的json. -> srcURL
# 3. srcURL里面的内容进行修整
# 4. 下载视频
import requests
# 拉取视频的网址
url = "见评论区"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.某某video.com/videoStatus.jsp?contId={contId}"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36",
# 防盗链: 溯源, 当前本次请求的上一级是谁
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")
# 下载视频
with open("3_result.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
我们对requests的进阶用法进行了实践,并且熟悉了网页开发者工具的使用功能,“破解”了网站的防盗链,进行了一个反反爬操作。
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle