/user资源
/user/1 :查询/user/1 :删除/user :添加、修改/user :添加、修改相当于MySQL的数据库
PUT goods_index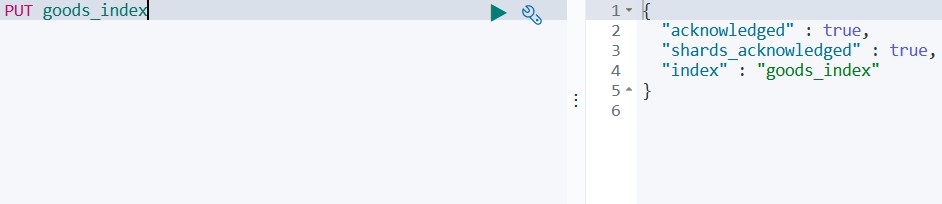
GET goods_index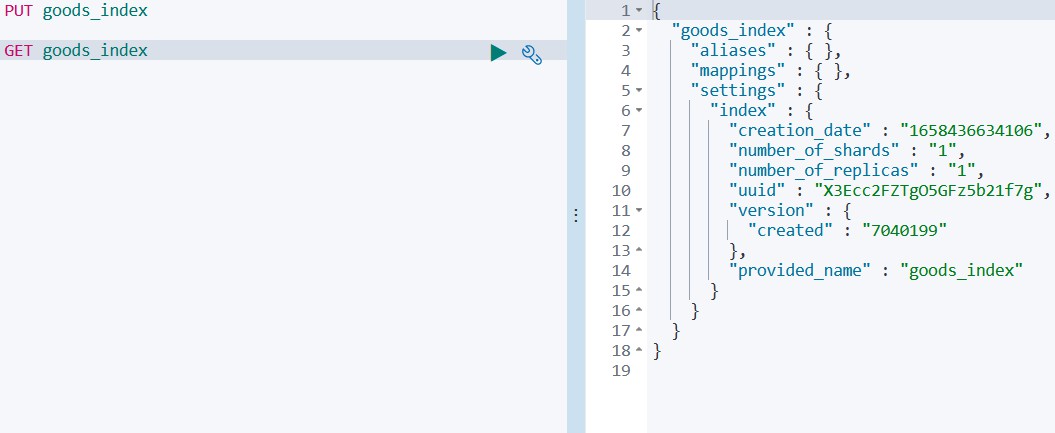
delete goods_index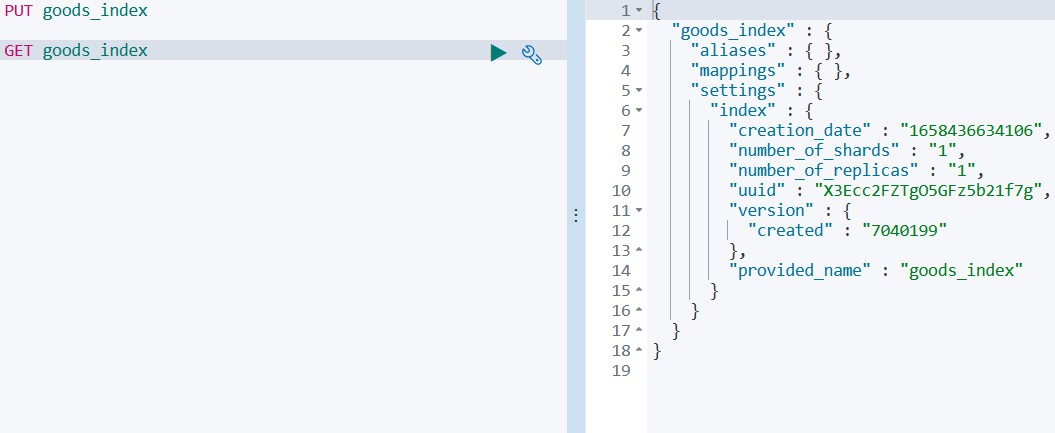
PS:当索引处于关闭状态,是不能添加文档的
POST goods_index/_close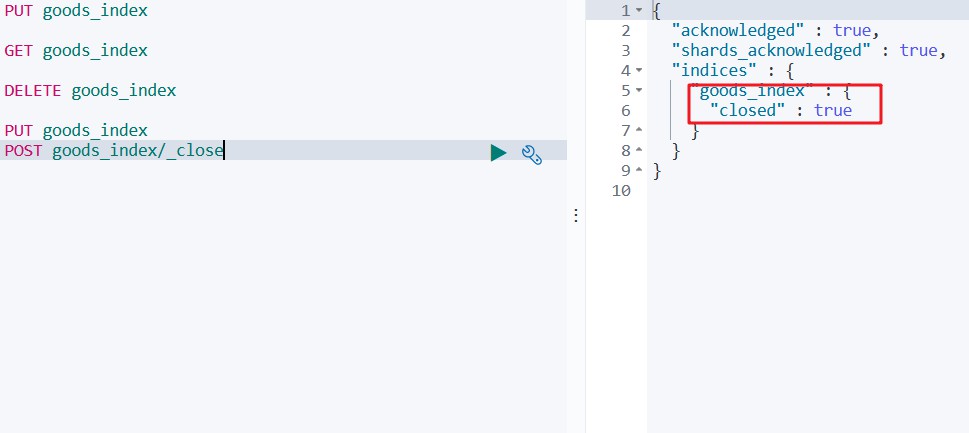
POST goods_index/_open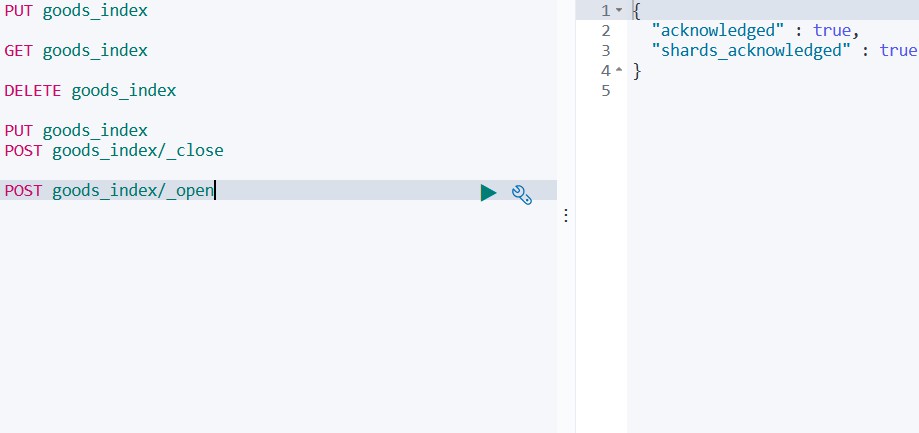
了解ES中字段有那些数据类型
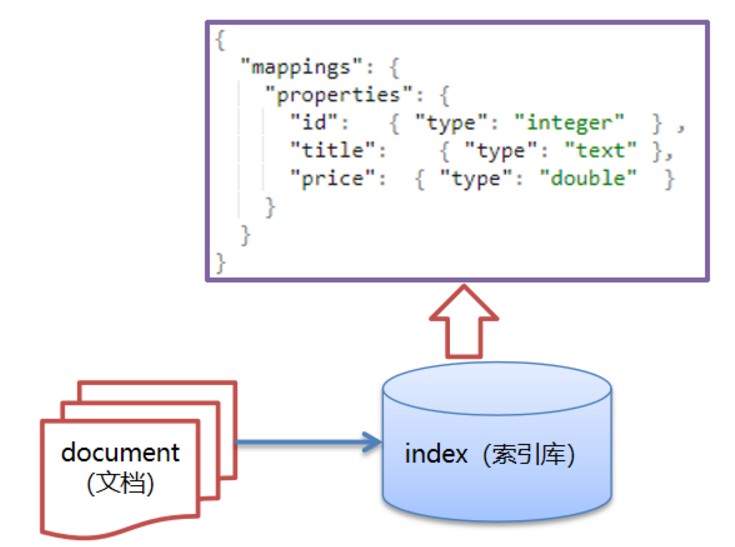
字符串
| 类型 | 说明 |
|---|---|
| text | 可以分词,不支持聚合(统计) |
| keyword | 不会分词,将全部内容作为一个词条,支持聚合(统计) |
例如:有个文档(相当于表中的一条数据,其中一个字段的值是华为手机
数值(不一定分词)
| 类型 | 说明 |
|---|---|
| long | 带符号的64位数其最小值为-263263,最大值为263263 |
| integer | 带符号的32为整数,其最小值为-231231,最大值为231231 |
| short | 带符号的16位整数,其最小值为-32,768,最大值为32,767 |
| byte | 带符号的8位整数,其最小值位-128,最大值为127 |
| double | 双精度64位IEEE 754浮点数,限制为有限制 |
| float | 单精度32位IEEE 754浮点数,限制为有限制 |
| half_float | 半精度IEEE 754浮点数,限制为有限制 |
| scale_float | 由a支持的有限浮点数long,由固定double比例因子缩放 |
布尔类型
boolean二进制
binary日期
date范围类型
integer_rangefloat_rangelong_rangedouble_rangedate_rangearray数据类型,任何一个字段的值,都可以被添加0个到多个,但是要求它们的类型必须一直,当类型一致,含有多个值存储到ES中会自动转化成数组类型
geo_point命令
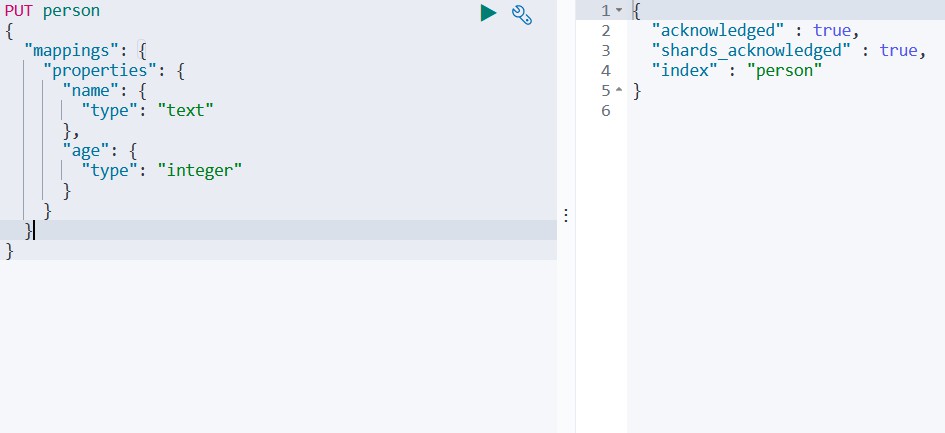
# 创建带映射(表结构)的索引库
PUT person
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
如下所示
命令
GET person/_mapping
如下所示
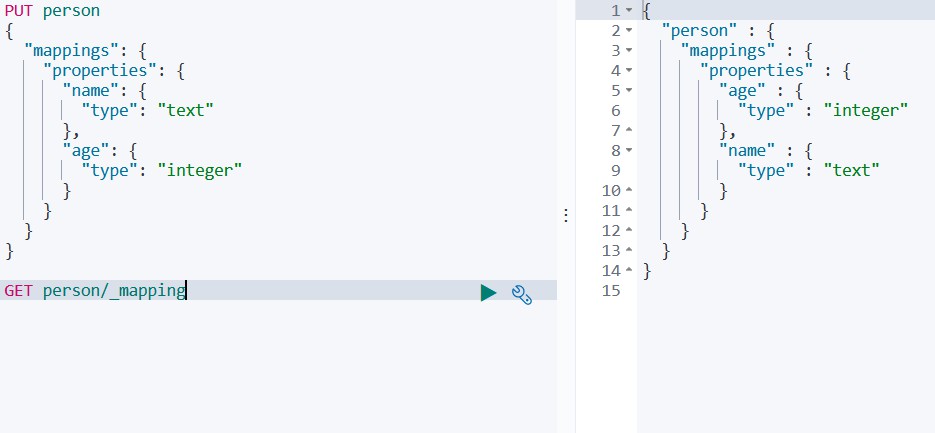
命令
PUT person/_mapping
{
"properties":{
"sex":{
"type":"keyword"
}
}
}
如下所示
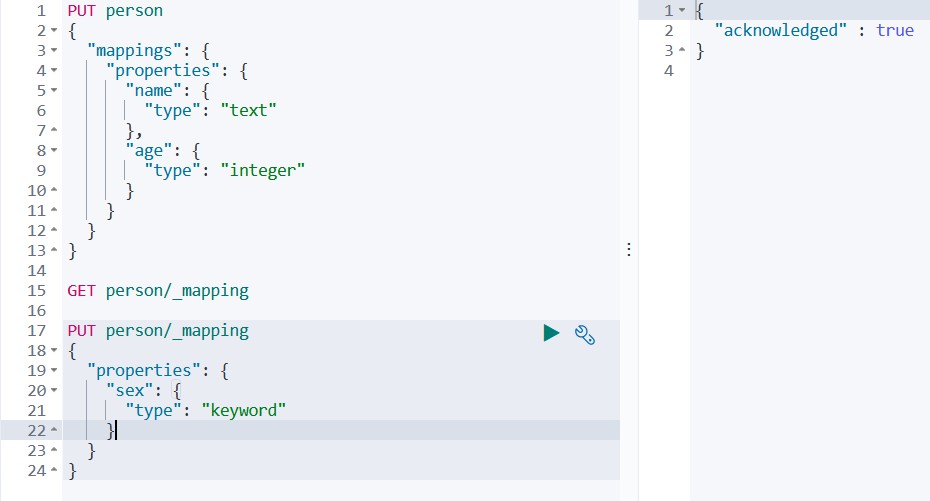
再次查询映射
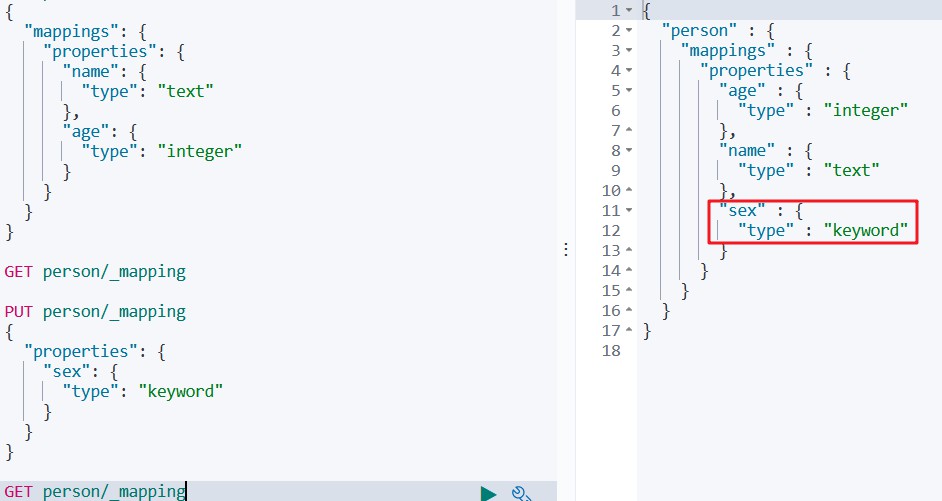
PS:ES不能单独修改映射字段名称或类型,也不能单独删除某个字段,如果需要修改,直接删除整个索引库再重建
命令
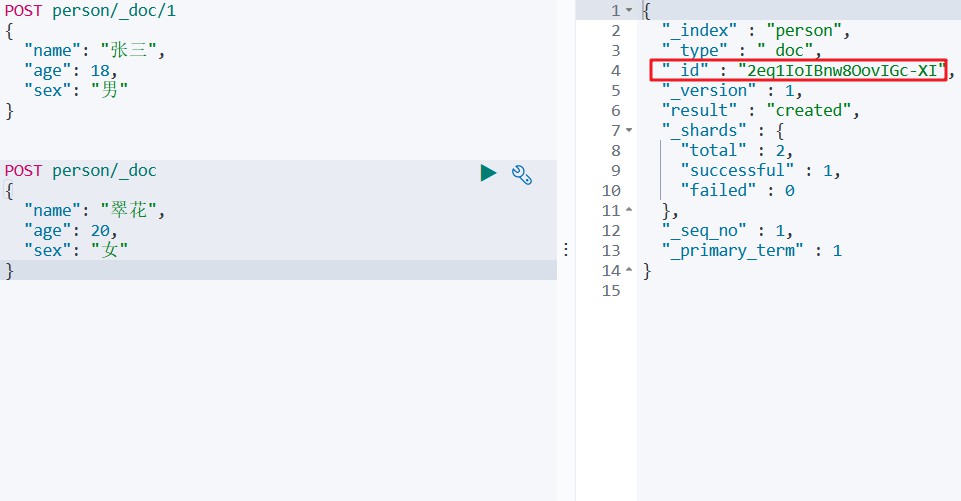
# 指定id
POST person/_doc/1
{
"name":"张三",
"age":18,
"sex":"男"
}
# 不指定id
POST person/_doc
{
"name":"翠花",
"age":20,
"sex":"女"
}
如下所示
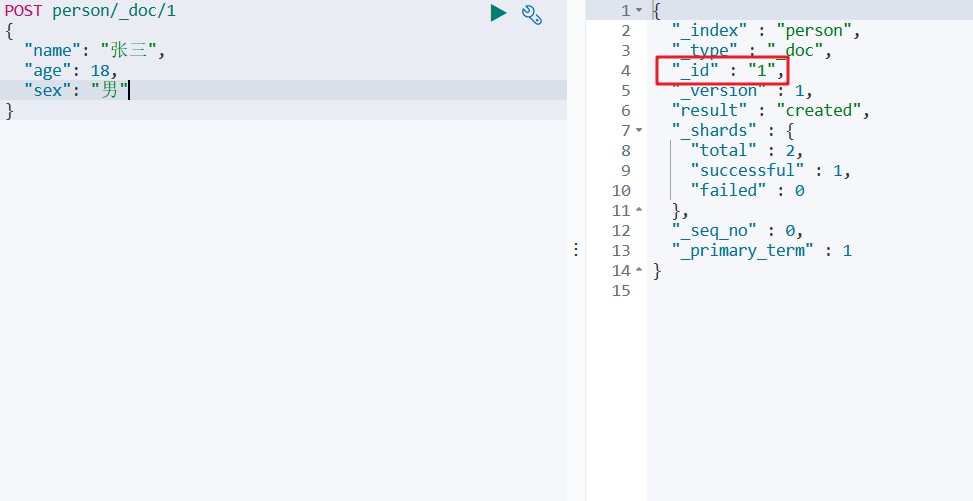
命令
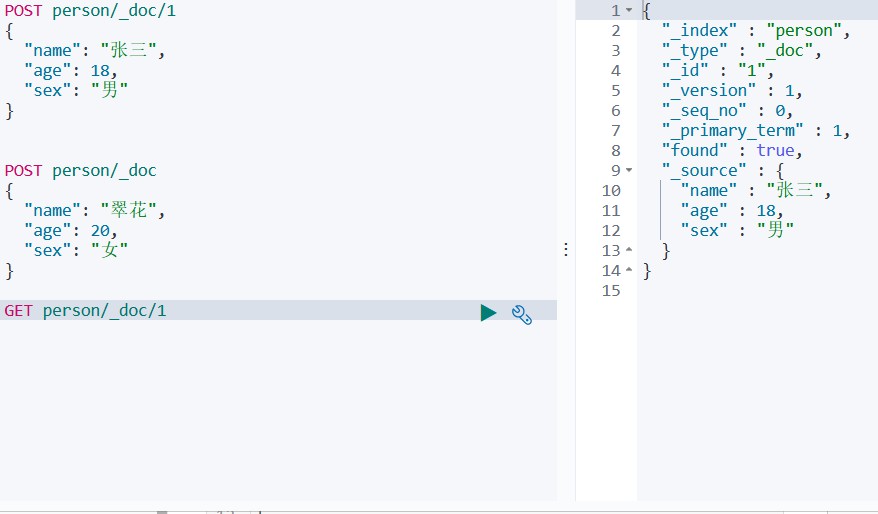
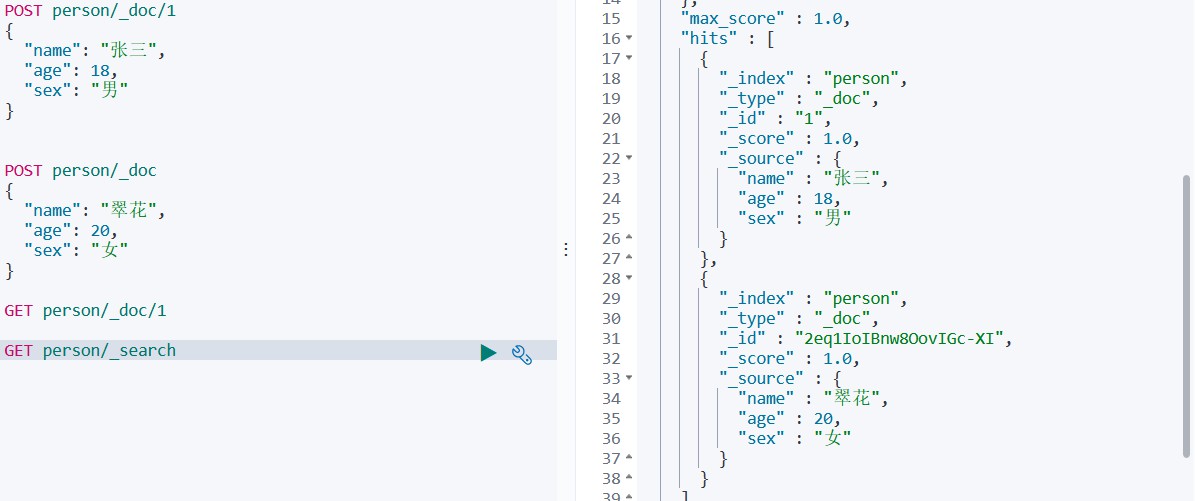
GET person/_doc/1 # 查询一个
GET person/_search # 查询全部
如下所示
命令
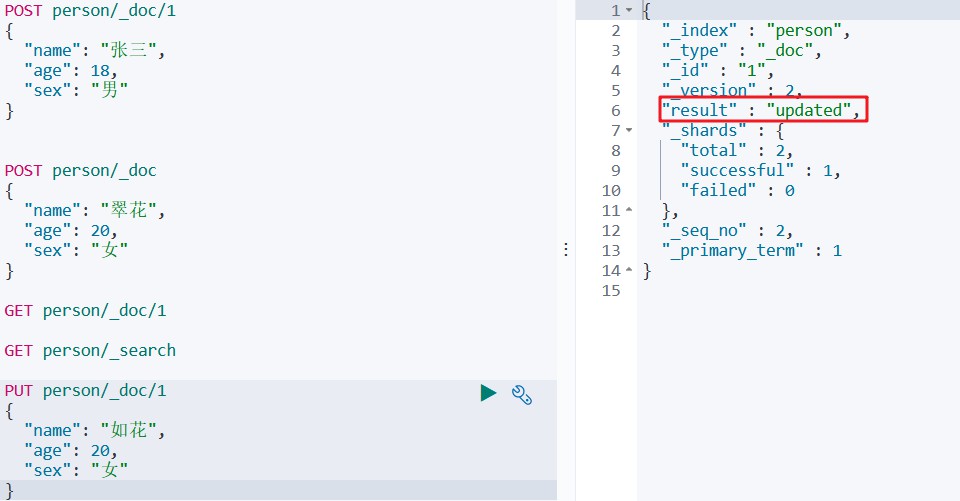
PUT person/_doc/1
{
"name":"如花",
"age":20,
"sex":"女"
}
如下所示
记得之前说过的
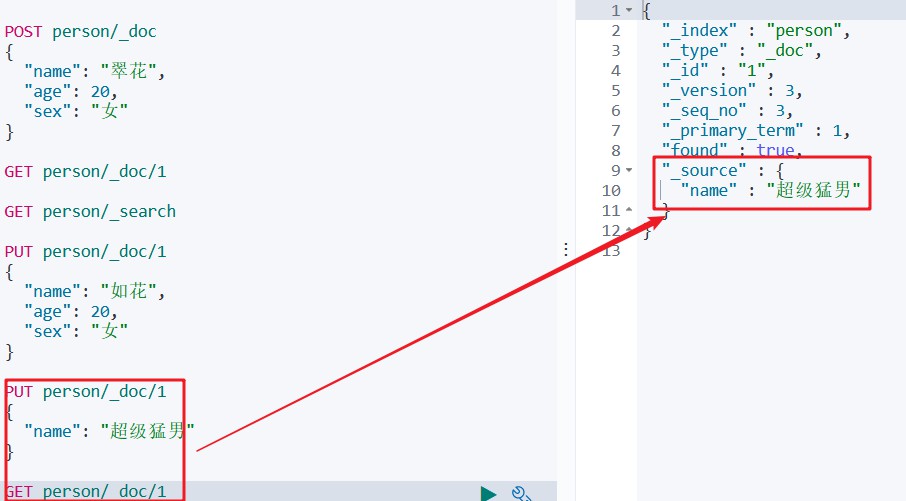
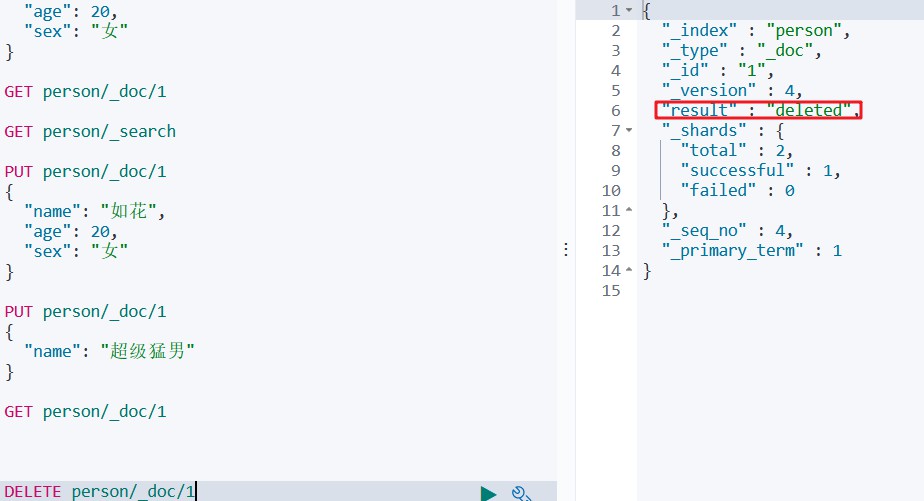
命令
DELETE person/_doc/1
如下所示
我正在尝试找出如何为我的Ruby项目创建一种“无类DSL”,类似于在Cucumber步骤定义文件中定义步骤定义或在Sinatra应用程序中定义路由。例如,我想要一个文件,其中调用了我的所有DSL函数:#sample.rbwhen_string_matches/hello(.+)/do|name|call_another_method(name)end我认为用我的项目特有的一堆方法污染全局(内核)命名空间是一种不好的做法。因此方法when_string_matches和call_another_method将在我的库中定义,并且sample.rb文件将以某种方式在我的DSL方法的上下文中
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.