有些网页源码中找不到相应的要爬的数据,其实这不是什么被反扒了,只是网页有可能是动态加载出来,这时候我们可以找到相应的数据接口,找到真正的目标url一样能找到包含我们想要的数据的真正url,就像我今天要讲的这个案例。
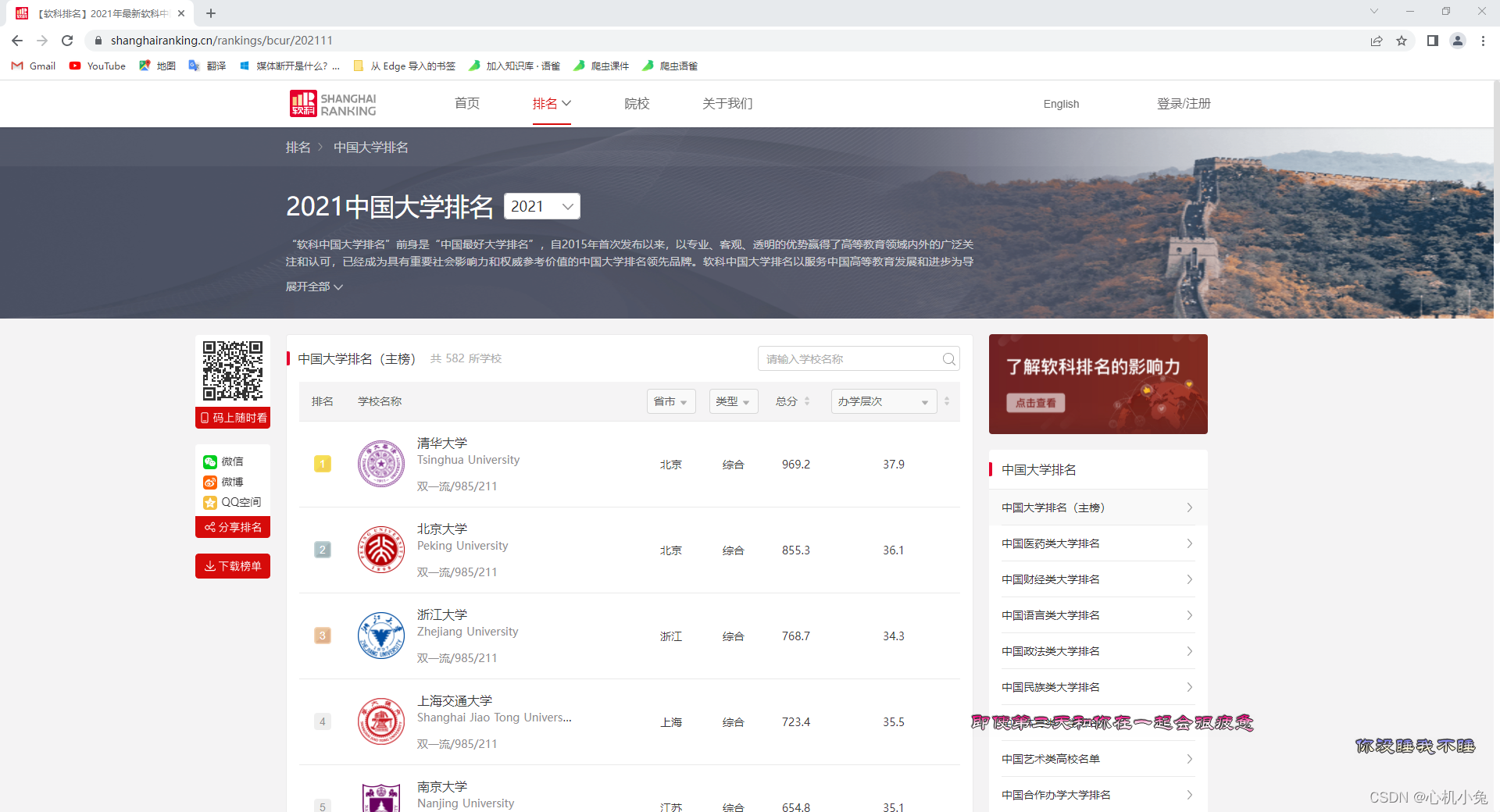
右键查看网页源码,我们会发现数据虽然存在于网页源码中,但是,我们点一下翻页功能,再观察
第一页
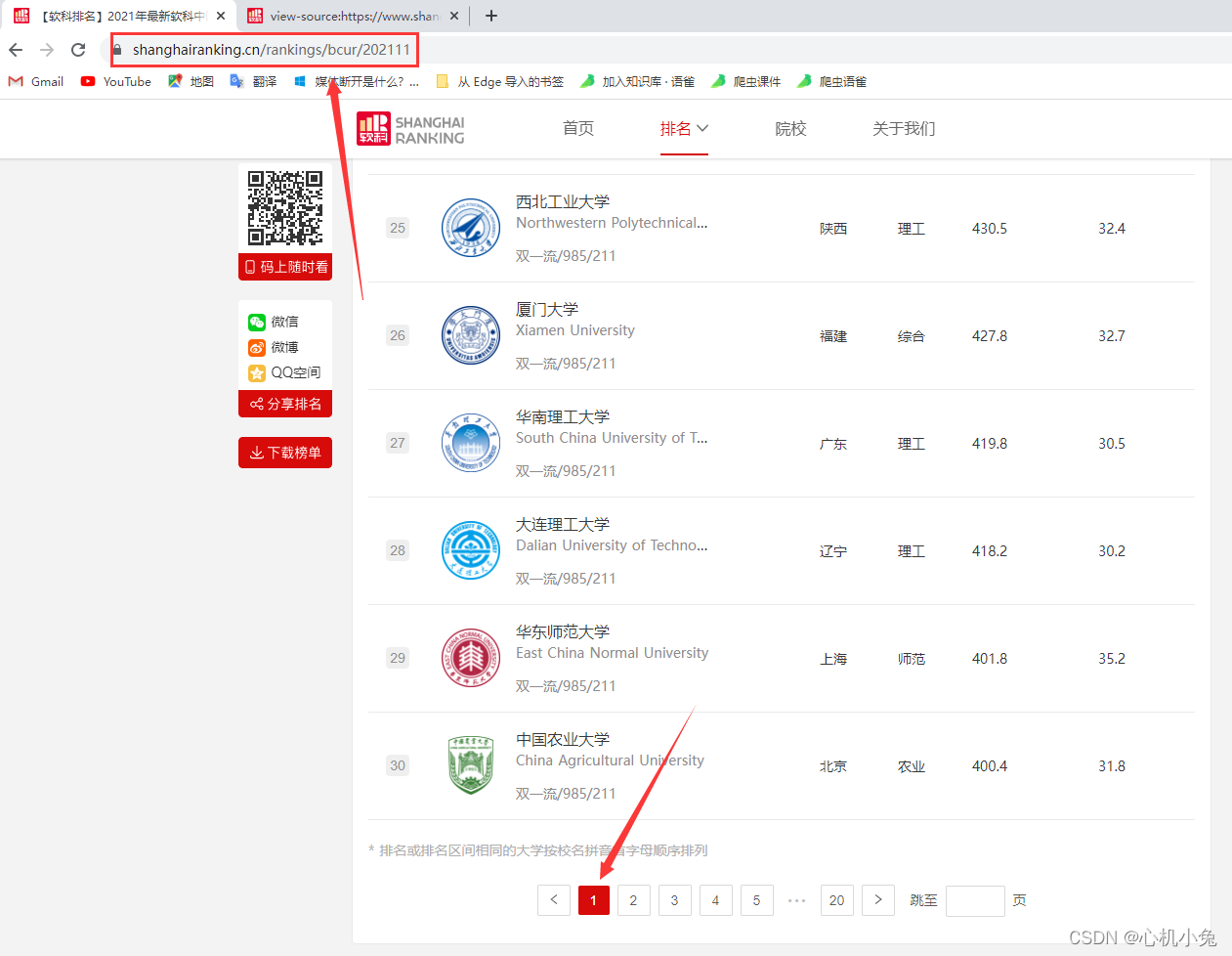
第二页
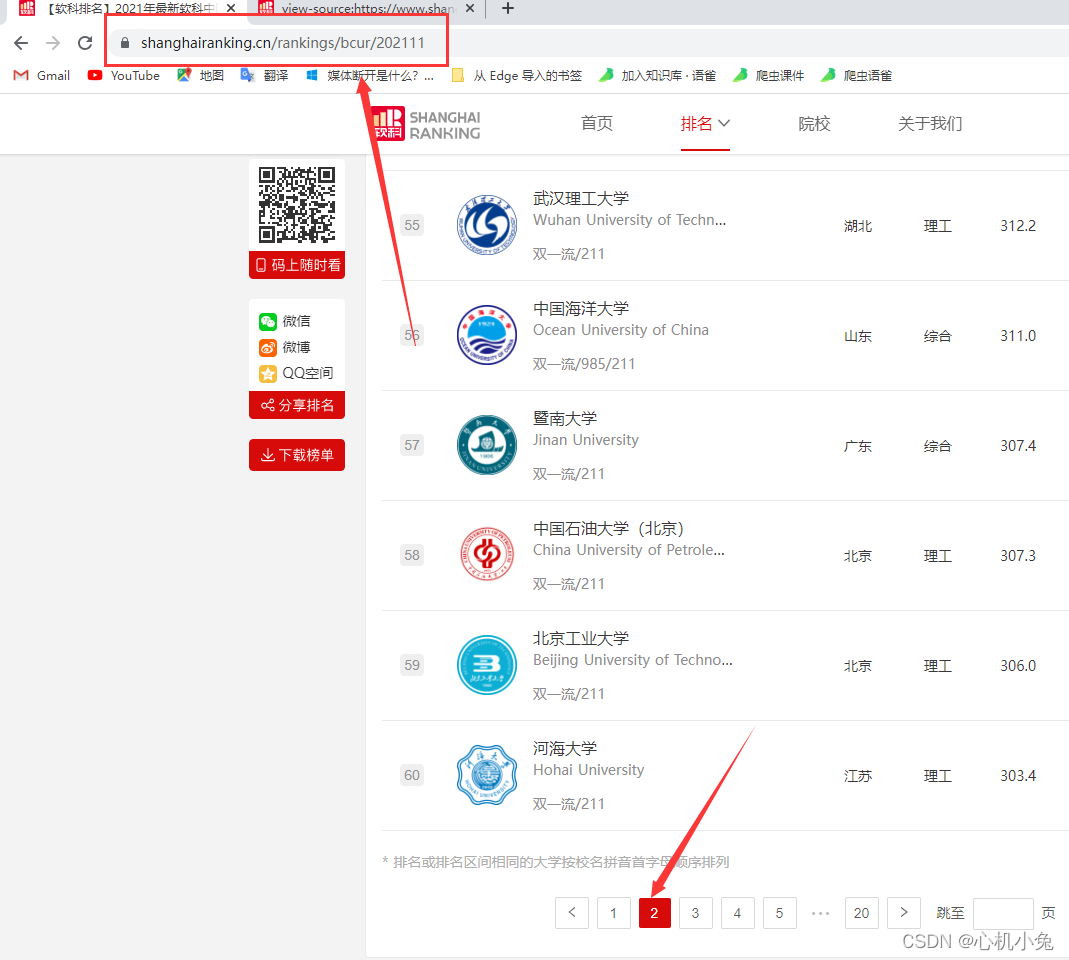
我们会发现,无论我们怎么翻页,url 都是不变的,这个时候,我们应该考虑网页是不是动态加载出来的。在 “开发者工具”->“网络” 中找看看有没有相应的数据接口,一找果然是
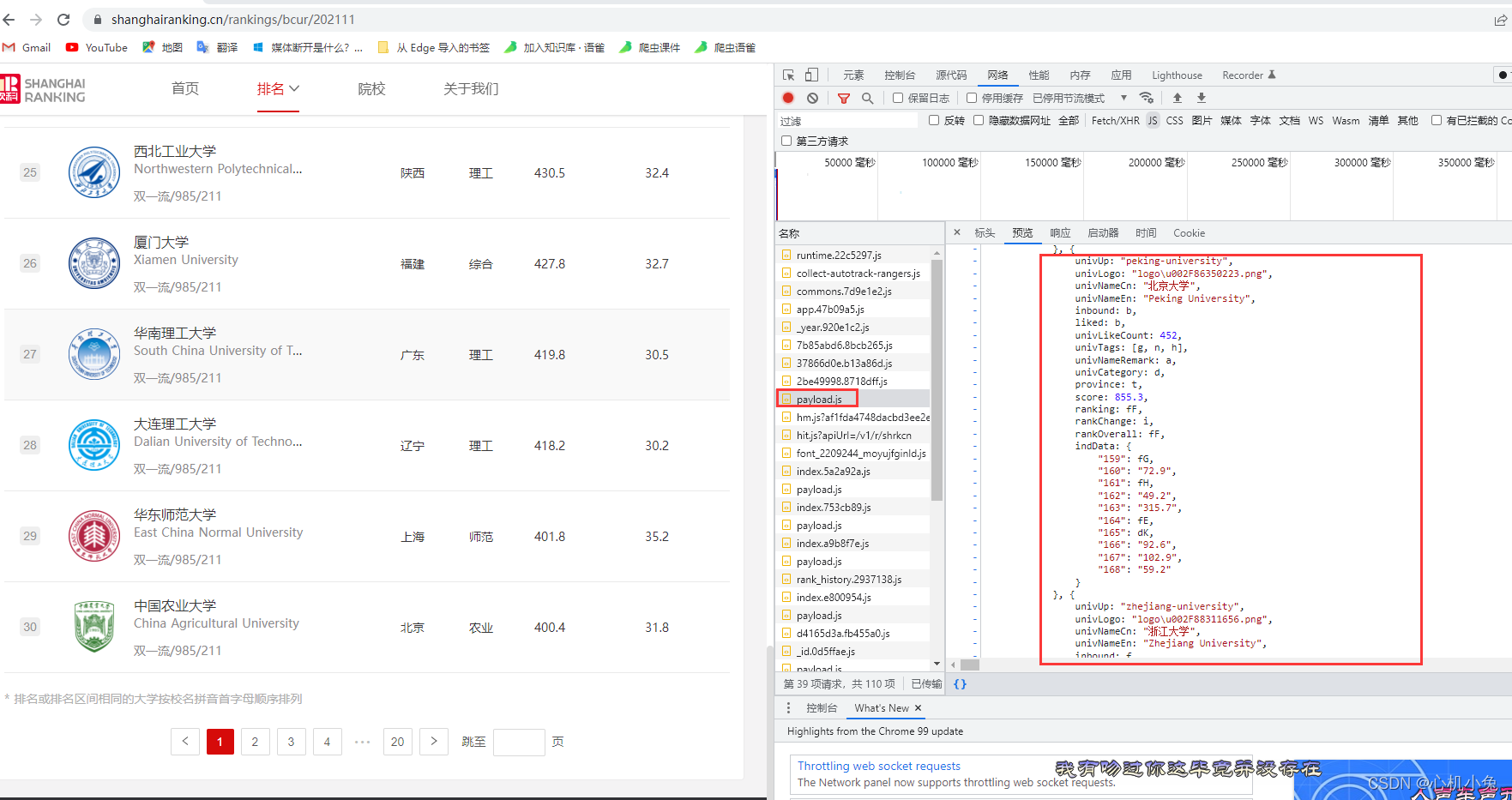
发现数据是保存在一个js格式的文件中的,下面才是它真正url
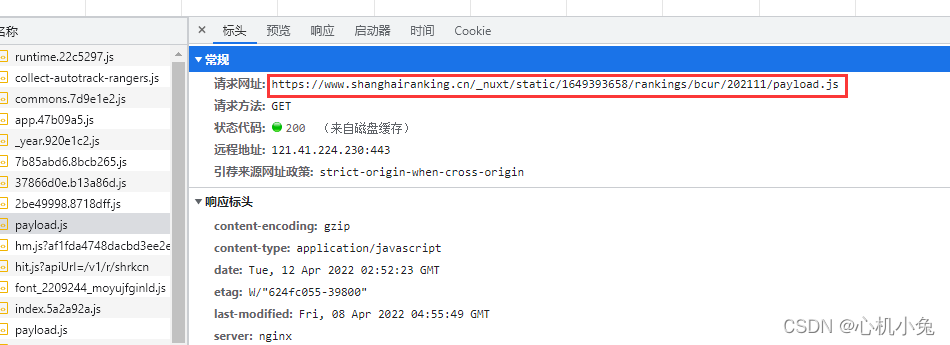
如果用传统的方法去爬,就会经历一个较为繁琐的数据解析过程。所以这时候,selenium的好处就体现出来了,直接获取页面元素,虽然有点慢,但是我们不用再经历繁琐的解析过程。
直接查看页面元素
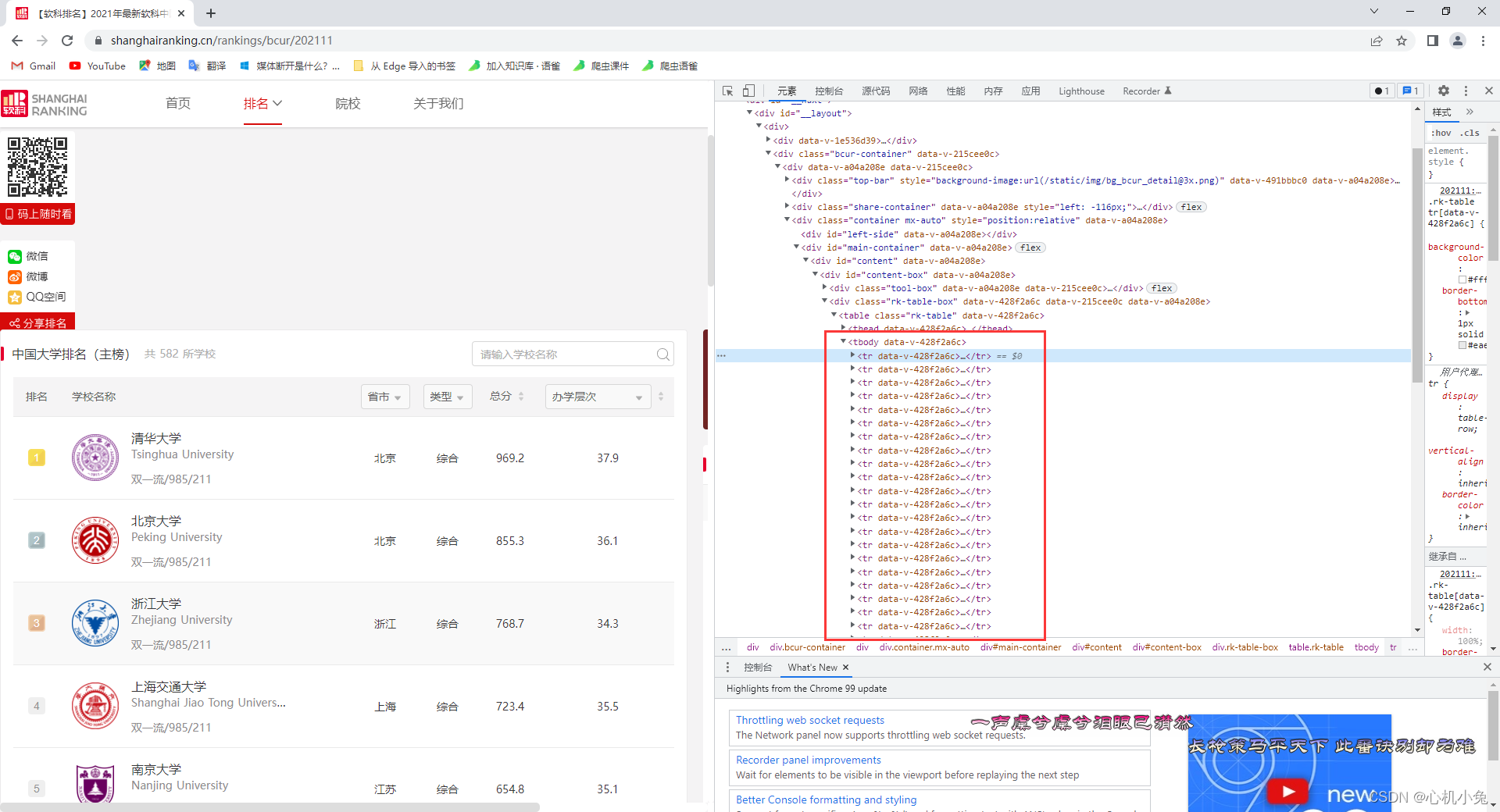
发现每个大学的数据信息都是保存在一个 tr 标签中的,再分析就会发现,每个大学的详细信息分别保存在一个 td 标签中
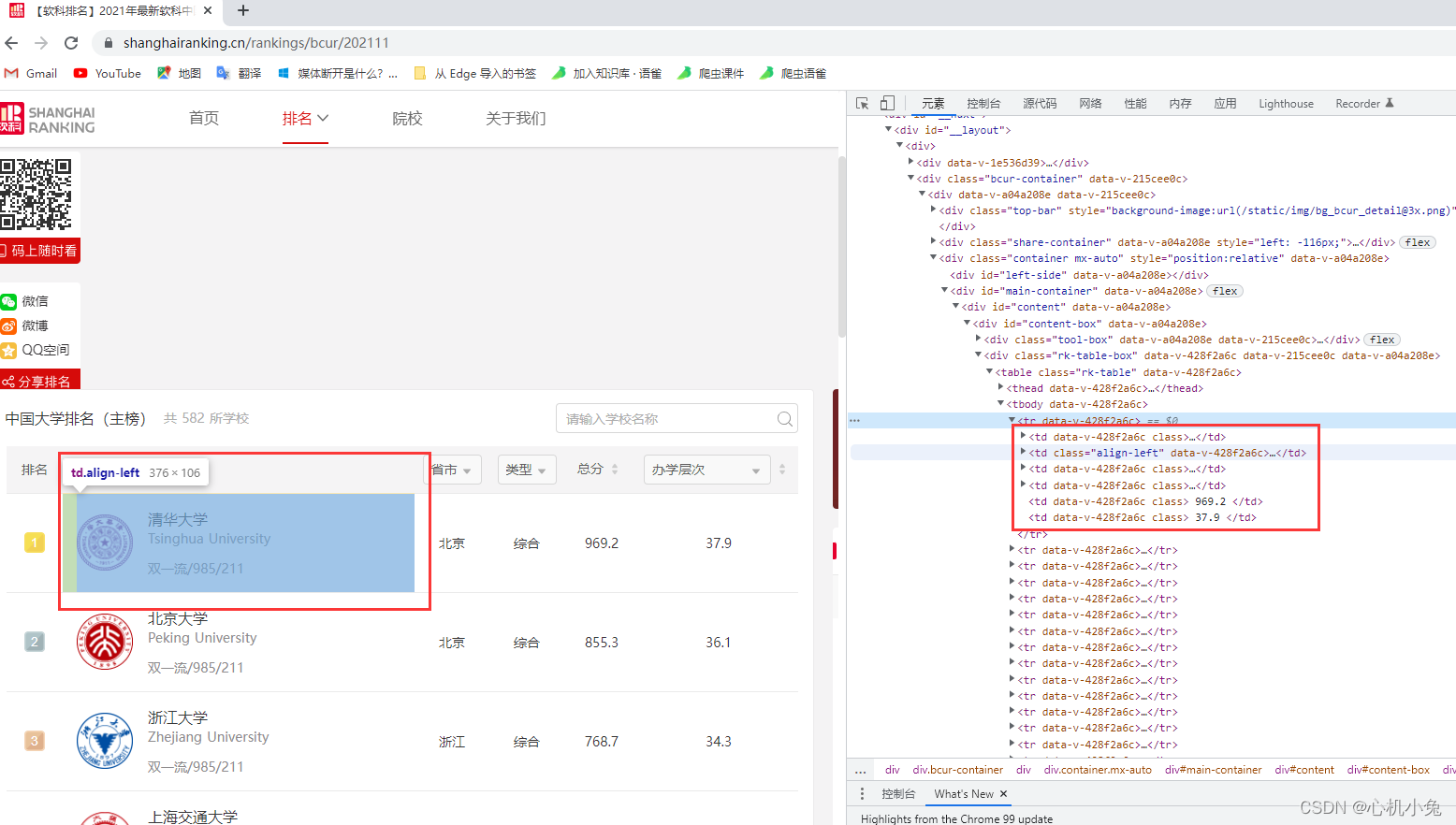
(一)获取大学排名、名称、类型、地点等信息
(二)以csv文件格式保存文件
(三)以面向对象的形式实现
只需要用到两个包,selenium.webdriver和csv模块。详细的实现步骤我都在代码中做了注释,就不再多做说明了
要强调的是翻页的处理,分别分析一下最后一页和其他页下的“下一页”按钮有什么区别

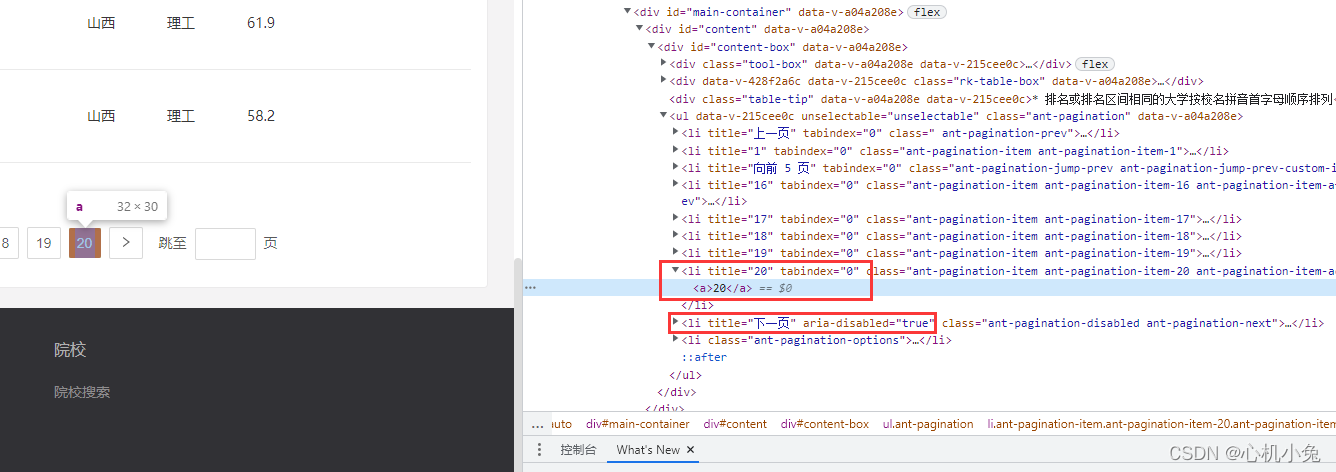
我们会发现,在没到达最后一页时,下一页标签中没有 aria-disabled="true"这个值,到了最后一页才出现的,也就说明,当我们到达最后一页后,下一页按钮就不能再点了,所以找到了这个翻页就相当简单了,话不多说,上代码
# 心机小兔的python之路
from selenium import webdriver # 导入selenium,用于实现网页的爬取
import csv # 导入csv模块,用于保存文件
class Univercity(object): # 定义一个类方法
def __init__(self): # 重写__init__
self.driver = webdriver.Chrome() # 加载谷歌驱动
self.driver.maximize_window() # 浏览器窗口最大化处理
# 定义csv文件的列名
self.header = ['Rank','Cn','En','Rate','Location','Type']
# 用于接收爬取到的数据
self.data = []
# 后期代码基本实现后,把浏览器设置成无头模式,也就是不打开浏览器
options = webdriver.ChromeOptions() # 创建chrome的设置对象
options.add_argument('--headless') # 设置成无界面,也就是不打开浏览器
self.driver = webdriver.Chrome(options=options)
# 解析网页页面函数
def parse_html(self,url):
self.driver.get(url) # 从类的入口函数接收目标url,也就是下面的self.main()函数
self.driver.implicitly_wait(1) # 隐式等待
while True: # 当未到达最后一页,一直执行
# 先获取每一页的所有tr标签
tr_list = self.driver.find_elements_by_xpath('.//*[@id="content-box"]/div[2]/table/tbody/tr')
# 从每一个 tr 标签中分别获取到详细信息
for tr in tr_list:
items = {} # 定义一个空字典,存储每一个大学的详细信息
# 通过xpath方式获取大学排名 .//表示在当前的xpath路径下寻找
items['Rank'] = tr.find_element_by_xpath('.//td/div').text
# 通过寻找属性名的方式,获取大学的中文名
items['Cn'] = tr.find_element_by_class_name('name-cn').text
# 通过寻找属性名的方式,获取大学的英文名
items['En'] = tr.find_element_by_class_name('name-en').text
# 这里获取大学是否为985/211的时候,就得做一些异常处理,因为到后面很多高校是非985/211的,就是说标签里面是空的,如果为空,将其定义为空字符
try:
items['Rate'] = tr.find_element_by_class_name('tags').text
except:
items['Rate'] = ""
# 通过xpath获取大学的地点
items['Location'] = tr.find_element_by_xpath('.//td[3]').text
# 通过xpath获取大学的类型,综合、理工、师范等
items['Type'] = tr.find_element_by_xpath('.//td[4]').text
# 将一个大学的数据添加到列表中
self.data.append(items)
# 翻页处理,page_source.find()返回的是一个布尔值,如果在每一页中没找到标签属性为 nt-pagination-disabled ant-pagination-next 的元素则会返回 -1,到了最后一页的时候则为真,跳出循环
if self.driver.page_source.find('ant-pagination-disabled ant-pagination-next') == -1:
self.driver.find_element_by_class_name('ant-pagination-next').click()
self.driver.implicitly_wait(2)
else:
break
# 数据保存操作
def save_data(self,header,data):
with open('test.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=header) # 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writeheader() # 写入列名
writer.writerows(data) # 一列一列写入数据
# 函数入口
def main(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/202111'
self.parse_html(url) # 调用解析函数
self.save_data(self.header,self.data) # 调用保存数据函数
if __name__ == '__main__':
u = Univercity() # 实例化一个对象
u.main() # 函数入口

到这,这个案例就算结束了,是不是很简单?
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。9年前关闭。我打算学习Seleni
我一直在工作中使用seleniumIDE。现在我们决定将Seleniumwebdriver与Ruby结合使用。我完全不知道如何设置我的Mac,MacProYosemite10.10.5。在我的终端中,我运行了这些命令:$ruby-e"$(curl-fsSLhttps://raw.githubusercontent.com/Homebrew/install/master/install)"$brewdoctorYoursystemisreadytobrew.$brewinstallruby==>Summary/usr/local/Cellar/openssl/1.0.2d_1:464fi
我正在尝试使用ruby脚本进行一些headless测试。本质上,我在显示器:1上执行Xvfb,然后使用watir-webdriver启动Watir::Browser.new(:firefox)。如果您以root身份运行脚本,效果会很好-我可以运行x11vnc并观察脚本执行浏览器并与之交互。问题是,我需要能够从Rails应用程序调用这个ruby脚本,而不是以root身份运行它...如果我尝试以普通用户身份从命令行运行脚本,Xvfb会启动on:1像往常一样,但Watir不会启动浏览器......它最终会在60秒后超时。通过VNC连接会显示带有鼠标光标的黑屏。我可以从命令行完成所有操
出于某种原因,我必须为Firefox禁用javascript(手动,我们按照提到的步骤执行http://support.mozilla.org/en-US/kb/javascript-settings-for-interactive-web-pages#w_enabling-and-disabling-javascript)。使用Ruby的SeleniumWebDriver如何实现这一点? 最佳答案 是的,这是可能的。而是另一种方式。您首先需要查看链接Selenium::WebDriver::Firefox::Profile#[]=
我正在尝试使用Ruby中的SeleniumWebDriver2.4模拟鼠标移动如果我运行测试,是否应该看到鼠标在我的屏幕上移动?我很困惑。我试过很多不同的方法示例代码:require'selenium-webdriver'driver=Selenium::WebDriver.for:firefoxdriver.navigate.to'http://www.google.com'element=driver.find_element(:id,'gbqfba')那我试过了driver.action.move_to(element).performdriver.mouse.move_to(e
我正在使用TrixWYSIWYGeditor在我的应用程序中。对于我的capybara测试:我要填写编辑器。我找到了这篇文章:Howtotestbasecamp'stripeditor...这似乎很有希望。不幸的是,它一直给我这个错误:Selenium::WebDriver::Error::ElementNotVisibleError:elementnotvisible所以看起来Capybara发现元素没问题,但它只是没有与之交互,因为Capybara必须有一些默认设置才能不与隐藏/不可见元素交互。环顾四周后,我发现了这个Stackoverflow问题:Isitpossibletoin
我正在学习将Selenium用于基本操作,例如截屏、抓取和测试,并希望将其与headlessChrome一起使用,Chrome59现已稳定。我已经能够使用“selenium-webdriver”gem和chromedriver截取屏幕截图,但不是headless的。这是我正在运行的ruby脚本,它在开始初始化驱动程序后挂起require'rubygems'require'selenium-webdriver'Selenium::WebDriver.logger.level=:debugp'initializingdriver'driver=Selenium::WebDriver.f