一键将本地已经打包好的SpringBoot项目部署到linux环境,实现秒级部署
前置知识:需掌握Maven的打包
- 在windows环境使用命令启动SpringBoot项目
- 在Linux环境使用命令启动项目
- 在Linux环境使用脚本启动项目
- 优化脚本,每次重启时先关闭项目
- 分离依赖,每次上传Linux环境只上传几百k的代码包
- 搭配IDEA插件,实现在IDEA中一键部署
例如:
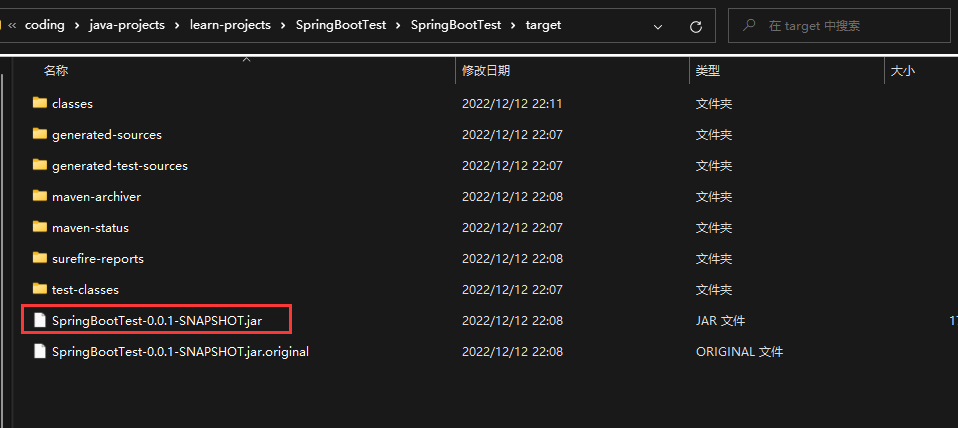
java -jar SpringBootTest-0.0.1-SNAPSHOT.jar
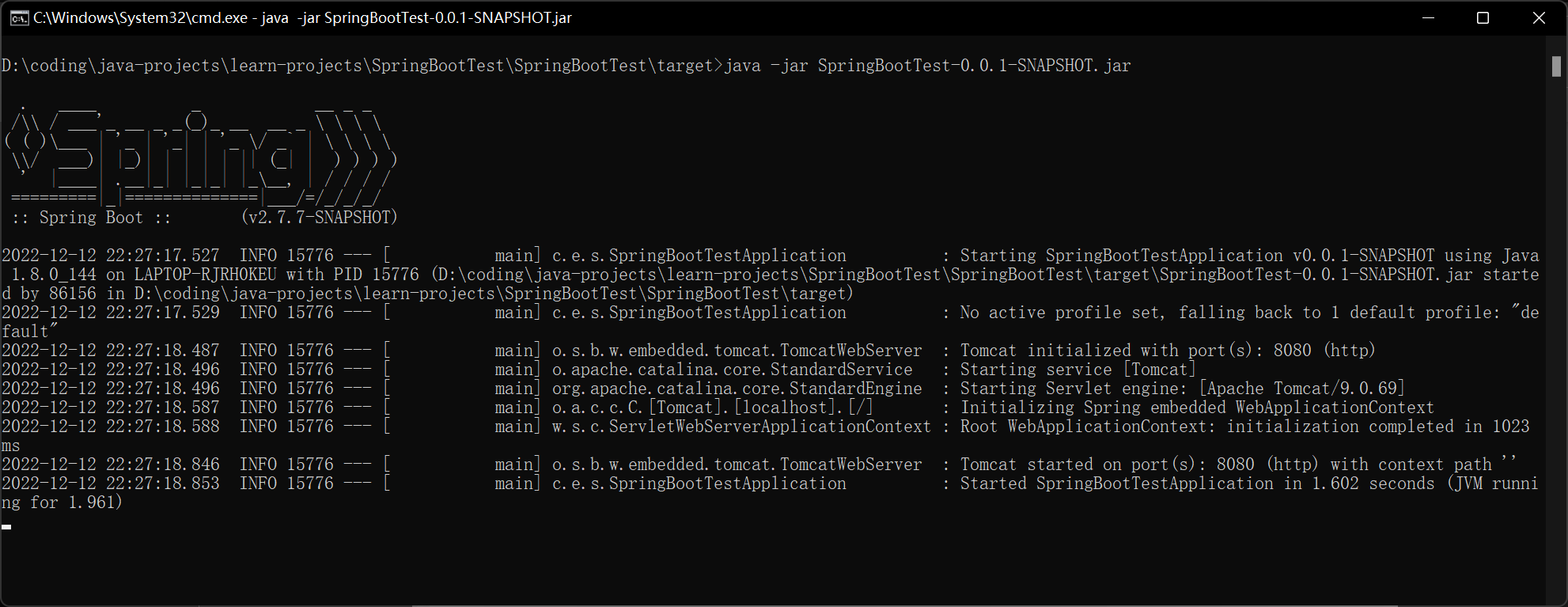
启动完毕,说明jar包是可以正常启动的。

java -jar SpringBootTest-0.0.1-SNAPSHOT.jar
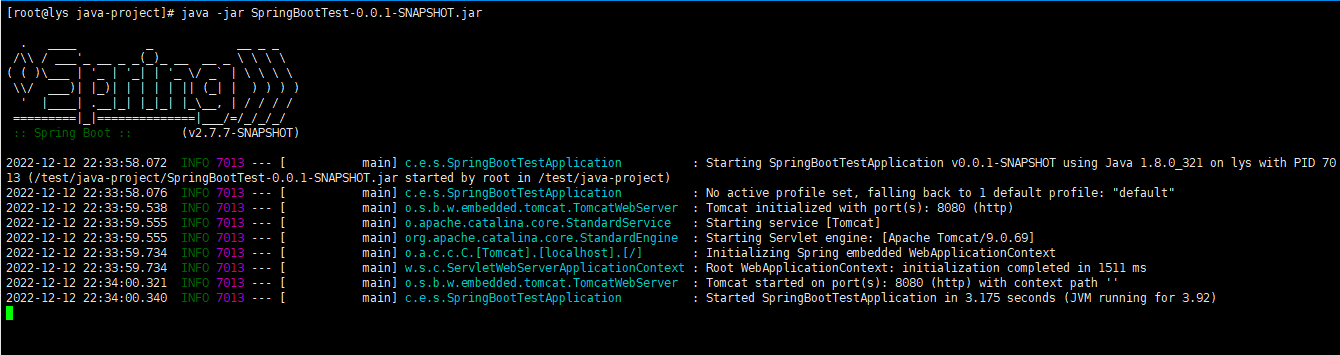
说明在Linux环境也是可以正常启动的
但是以上的启动方式有个问题,窗口一关项目就自动关闭了
springboot.lognohup java -jar SpringBootTest-0.0.1-SNAPSHOT.jar > springboot.log &

启动成功,进程号为9777
以上的脚本也存在问题,第二次启动的时候,会因为已经启动了一个服务,端口占用启动不了
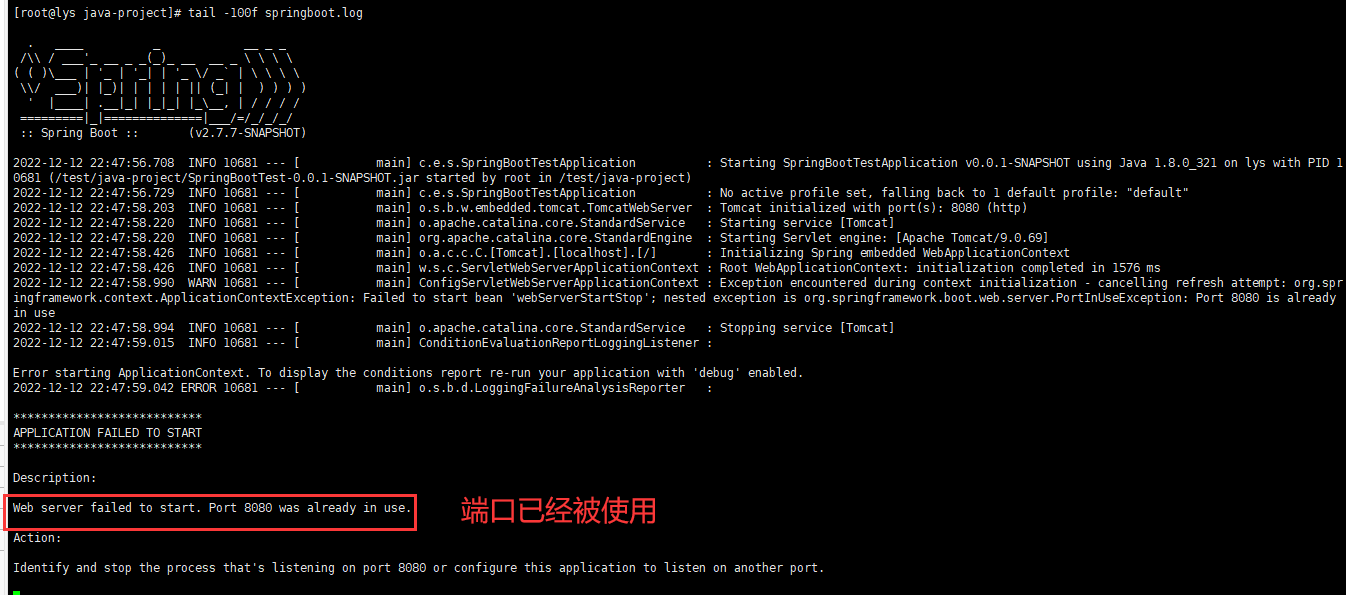
创建脚本
vim start.sh
脚本内容
# 关闭程序
# fileName为jar包的名称
fileName=SpringBootTest-0.0.1-SNAPSHOT.jar
pid=$(ps -ef | grep $fileName| grep -v "grep" | awk '{print $2}')
kill -9 $pid
# 启动项目
nohup java -jar $fileName > springboot.log &
之后,启动项目就可以
sh start.sh
至此,SpringBoot项目在Linux的启动就说明完毕。
但是,以上的部署方式还存在一些问题,在只有web依赖的时候,jar的大小就已经达到17M,

而在实际开发中,jar包的大小甚至会到达一百多兆。例如这样:
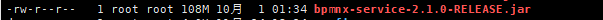
为什么明明没有多少代码,包的大小却这么大呢?
解压SpringBootTest-0.0.1-SNAPSHOT.jar包查看内容
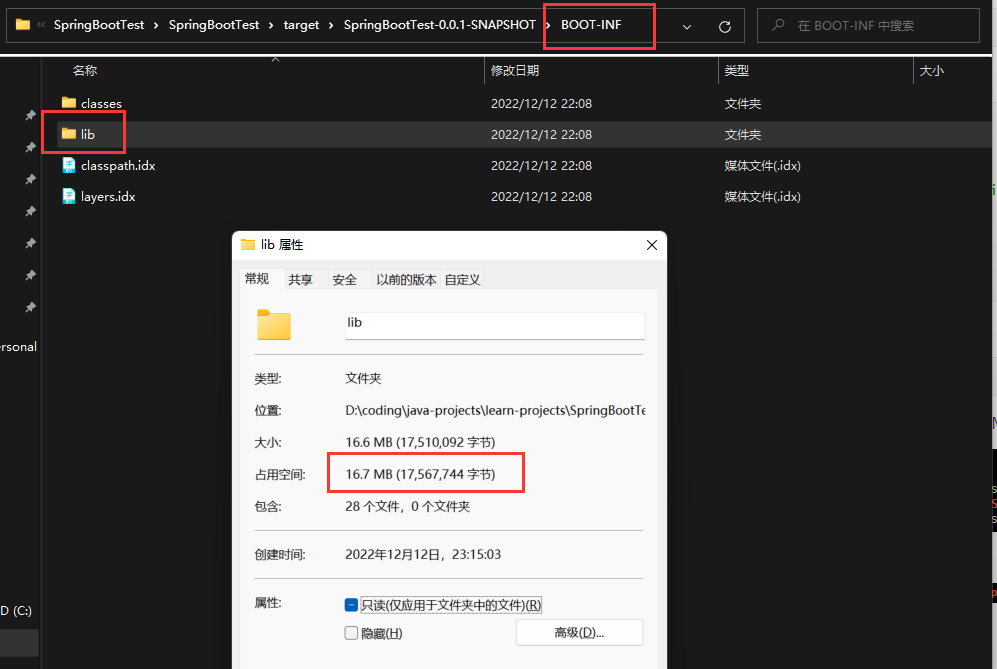
可以看出,lib文件夹占用了16.7M,而lib文件夹里面是什么东西呢?
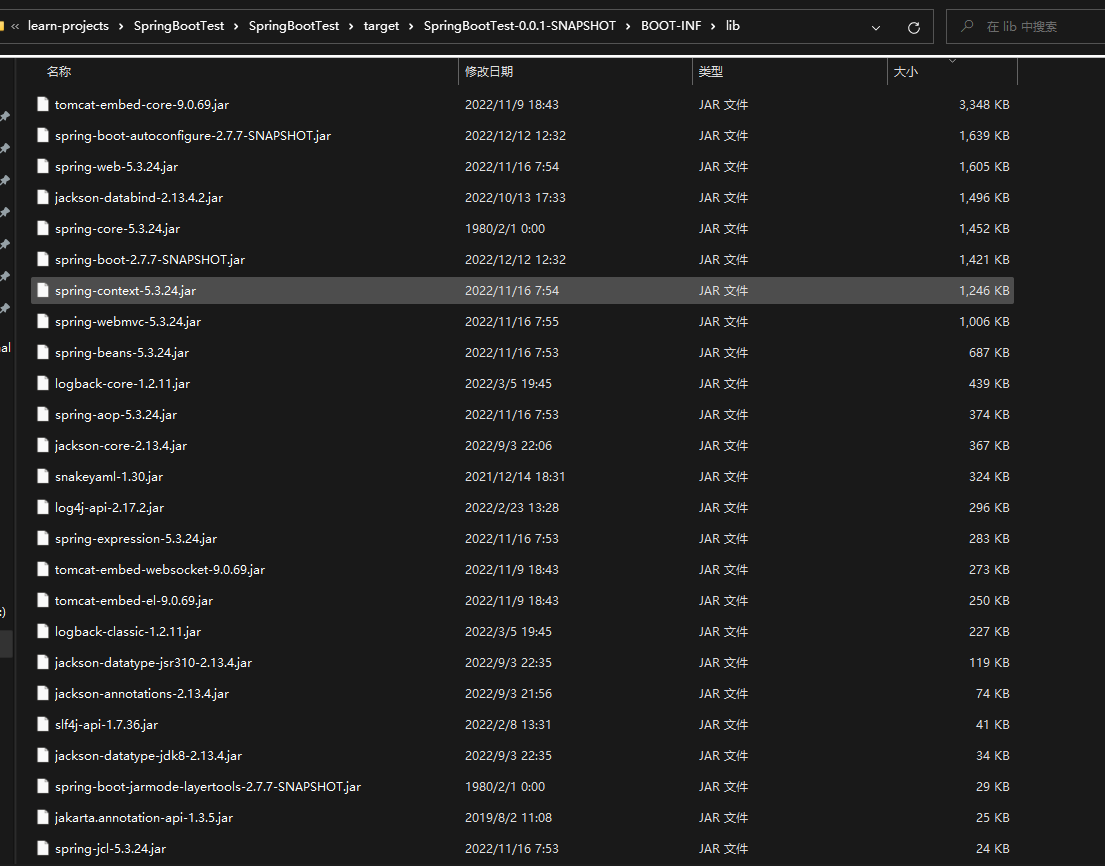
可以看到,就是各种的依赖。
所以,就引发了新的优化方向,能不能将依赖包直接放在服务器上,每次只更新自己的代码?
答案是:可以!在实际开发中,依赖包一般来说是不会动的,于是开始第三步。
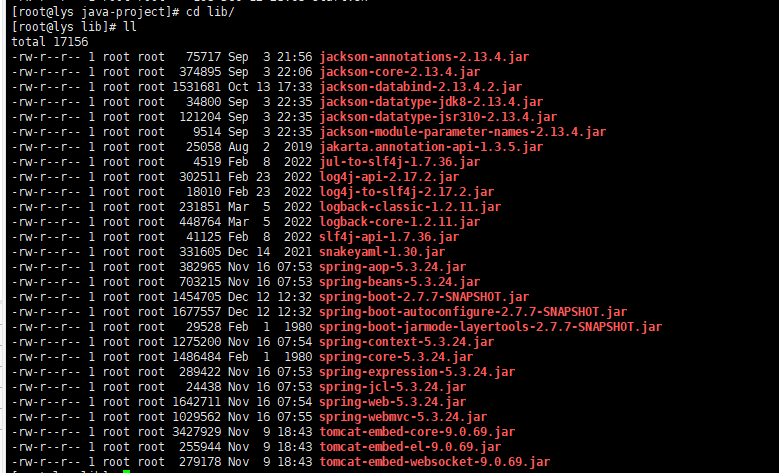
(1)创建lib文件夹
mkdir lib

(2)将jar包中的/BOOT-INF/lib目录底下的jar包全部上传到Linux服务器的lib文件夹
增加配置:
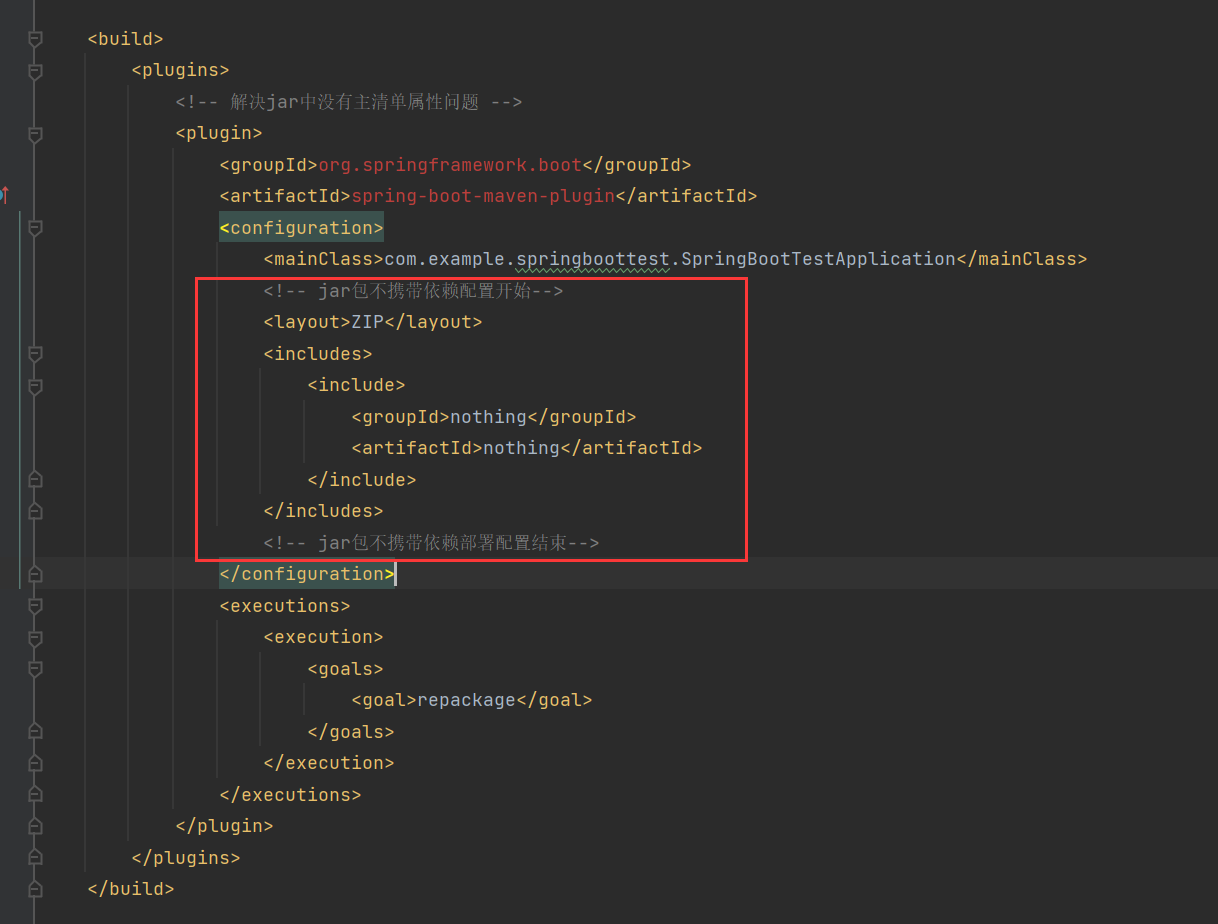
<build>
<plugins>
<!-- 解决jar中没有主清单属性问题 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<mainClass>com.example.springboottest.SpringBootTestApplication</mainClass>
<!-- jar包不携带依赖配置开始-->
<layout>ZIP</layout>
<includes>
<include>
<groupId>nothing</groupId>
<artifactId>nothing</artifactId>
</include>
</includes>
<!-- jar包不携带依赖部署配置结束-->
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
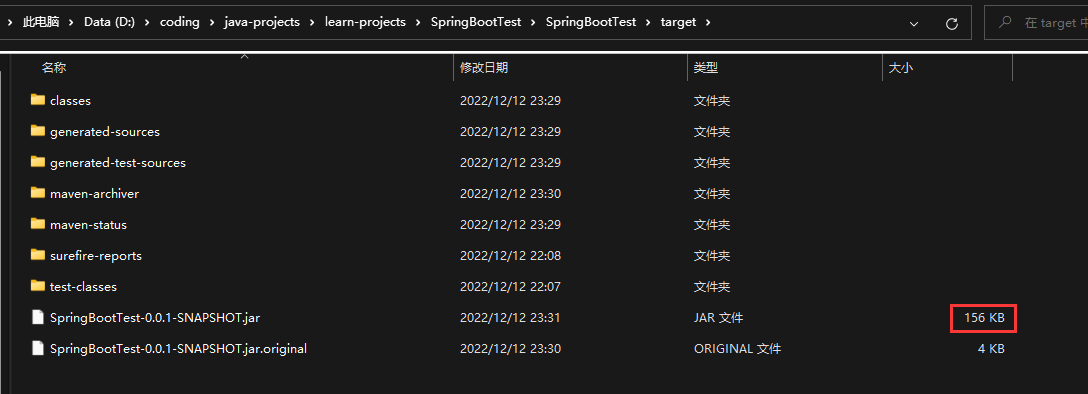
新生成的jar包仅仅只有156kb!

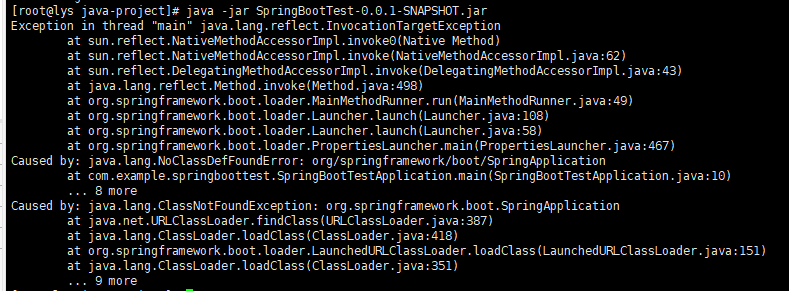
这时候,如果使用原本的脚本启动就会报错:
(1)增加启动文件start2.sh
cp start.sh start2.sh
(2)在java -jar后追加-Dloader.path=./lib
# 关闭程序
fileName=SpringBootTest-0.0.1-SNAPSHOT.jar
pid=$(ps -ef | grep $fileName| grep -v "grep" | awk '{print $2}')
kill -9 $pid
# 启动项目
nohup java -jar -Dloader.path=./lib $fileName > springboot.log &
使用外部依赖启动成功
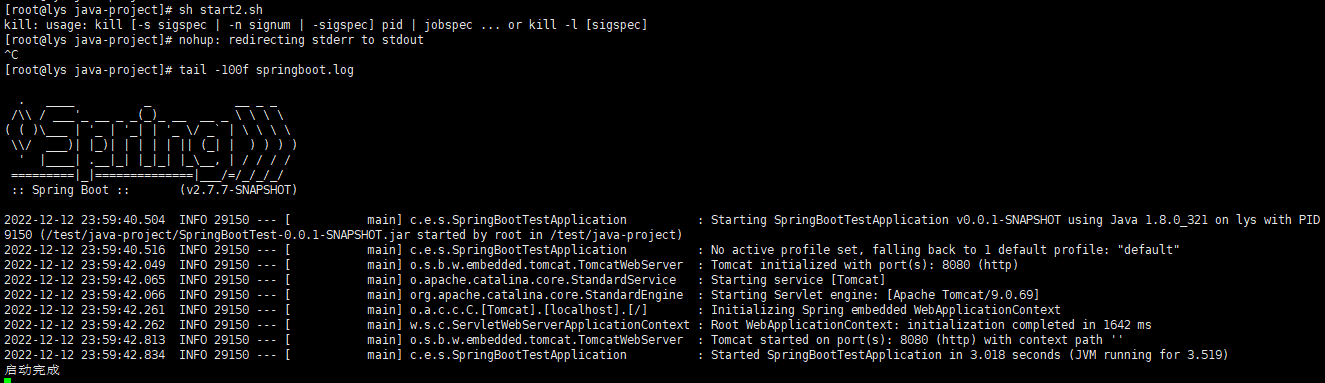
到此,使用外部依赖启动就完成了,只要加上
-Dloader.path=./lib就可以了
start.sh和start2.sh脚本第五步还存在的一个问题,虽然这个方法很好用,但是又增加了一个脚本。公司内部,总是有人想要打全量包,使用自带的依赖,有的人想要打不携带依赖的包,可以快速部署启动,这时候,就需要区分,到底是要用
start.sh脚本还是start2.sh脚本,于是,将start.sh和start2.sh脚本进行合并,大于10M的时候,就使用内部依赖,小于10M的时候就使用外部依赖
合并后的start.sh脚本:
# 关闭程序
fileName=SpringBootTest-0.0.1-SNAPSHOT.jar
pid=$(ps -ef | grep $fileName| grep -v "grep" | awk '{print $2}')
kill -9 $pid
# 获取jar包的大小
filesize=`ls -l $fileName | awk '{ print $5 }'`
# 多少M以上使用外部依赖
maxsize=$((1024 * 1024 * 10)) # 10M
if [ $filesize -gt $maxsize ]
then
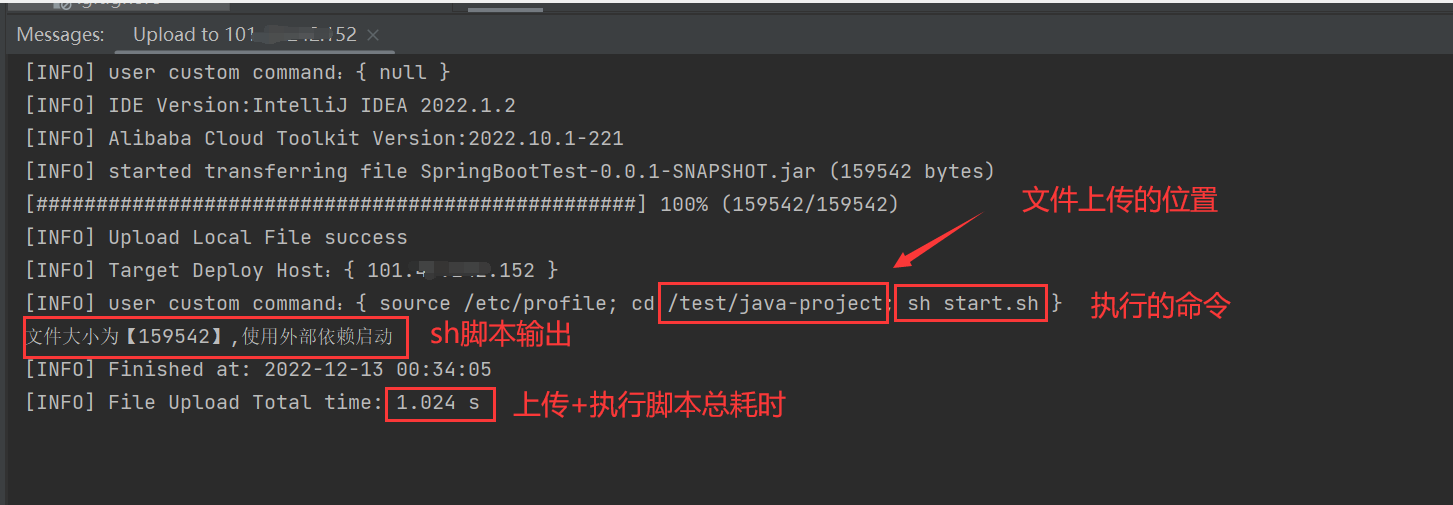
echo "文件大小为【$filesize】,使用内部依赖启动"
nohup java -jar -Dloader.path=./lib $fileName > springboot.log &
else
echo "文件大小为【$filesize】,使用外部依赖启动"
nohup java -jar $fileName > springboot.log &
fi
适配两种情况
小于10M的jar包使用外部依赖

大于10M的jar包使用内部依赖

在第三步优化完之后,jar包的大小大大减少,只剩下1M都不到,每次上传耗时不到1s,还能不能继续优化呢?
答案也是可以!当前还存在的问题是:
1、需要手动选择文件上传。
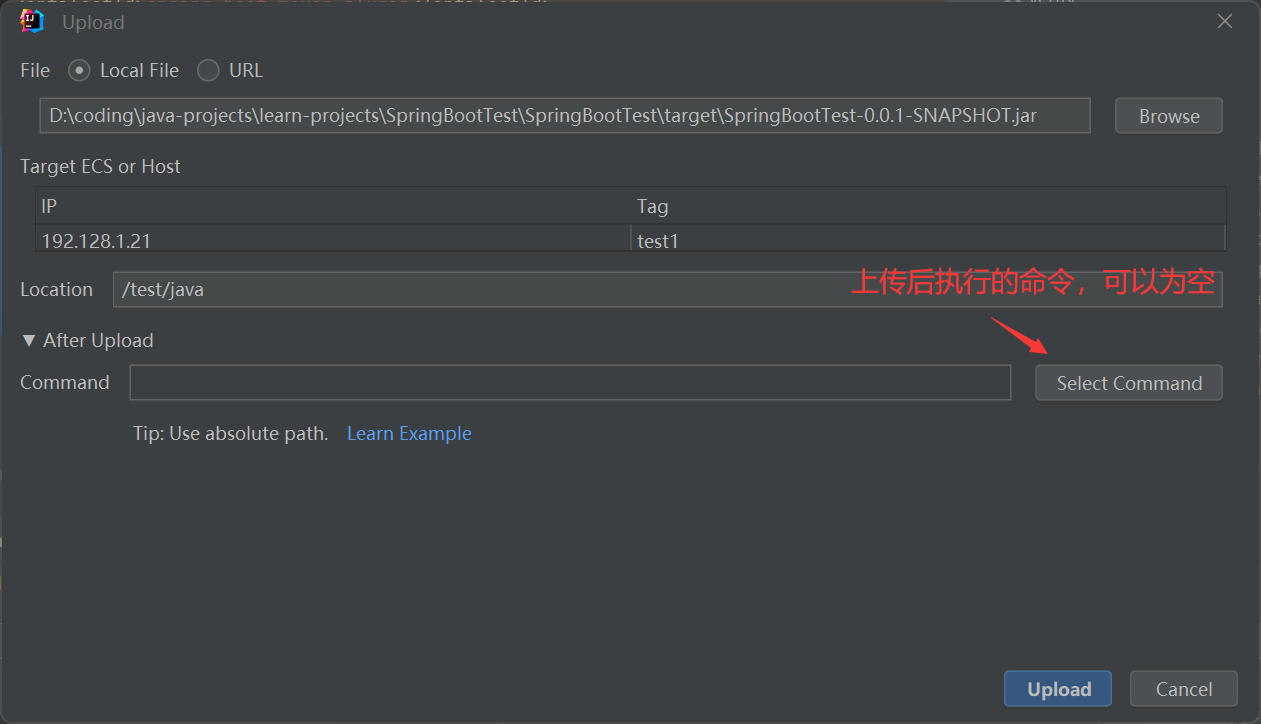
2、需要手动执行脚本
于是,进行第四步优化,引入Alibaba Cloud Toolkit插件
1.1 从插件市场中下载Alibaba Cloud Toolkit插件,并重启IDEA。
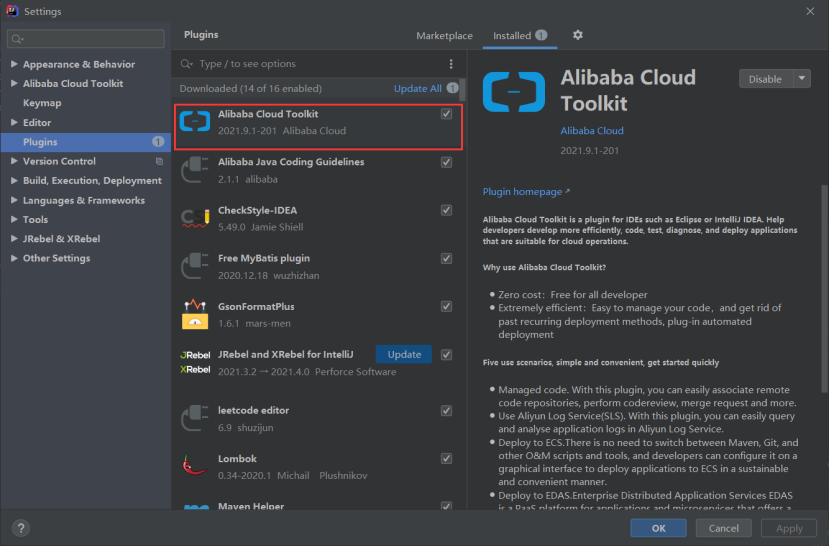

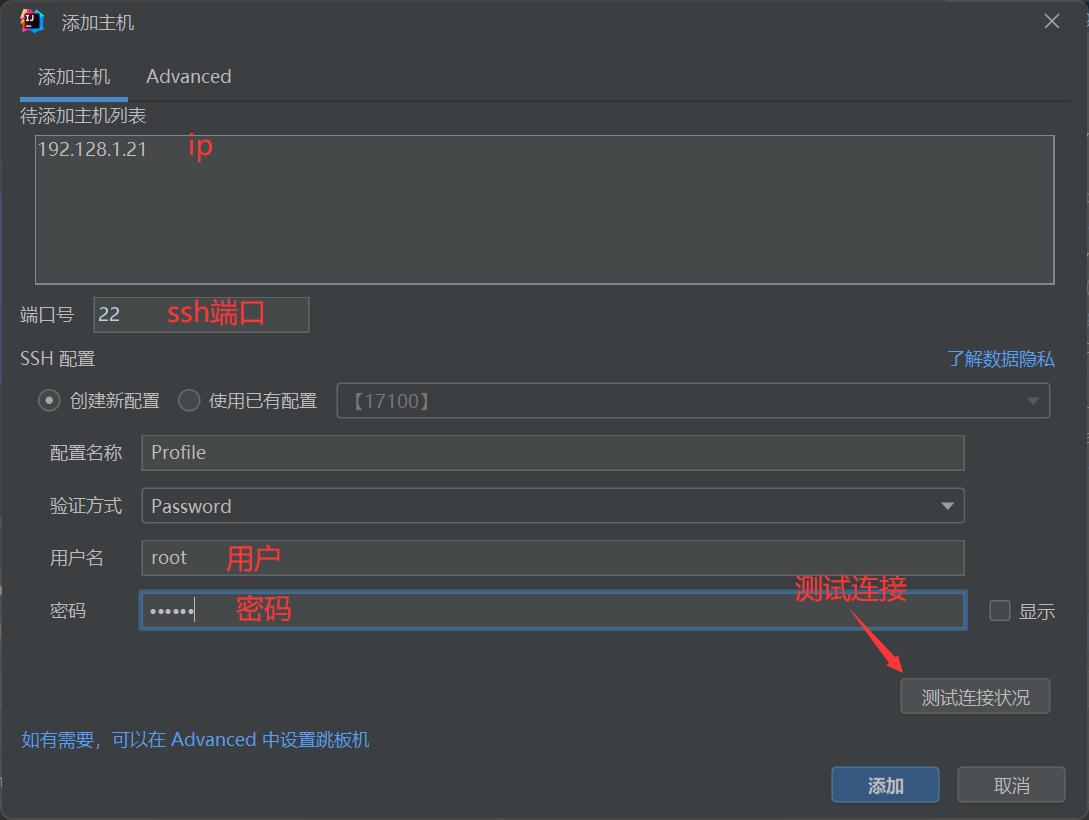
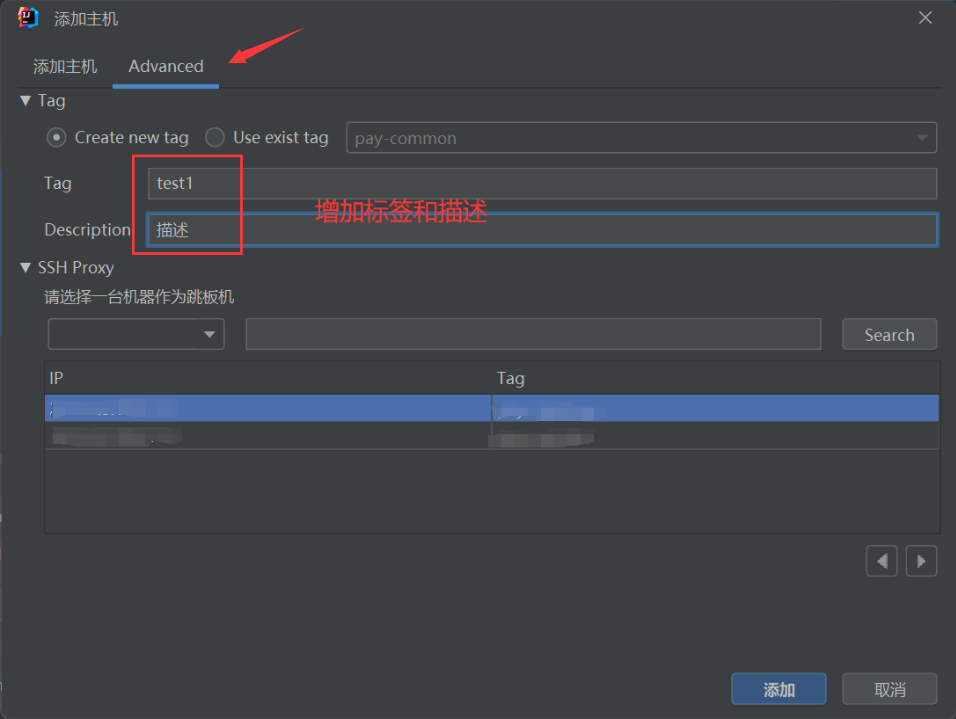
可以看到就增加了一条新的配置

查看所在路径
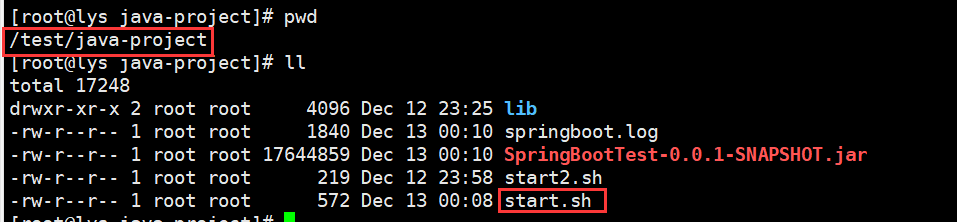
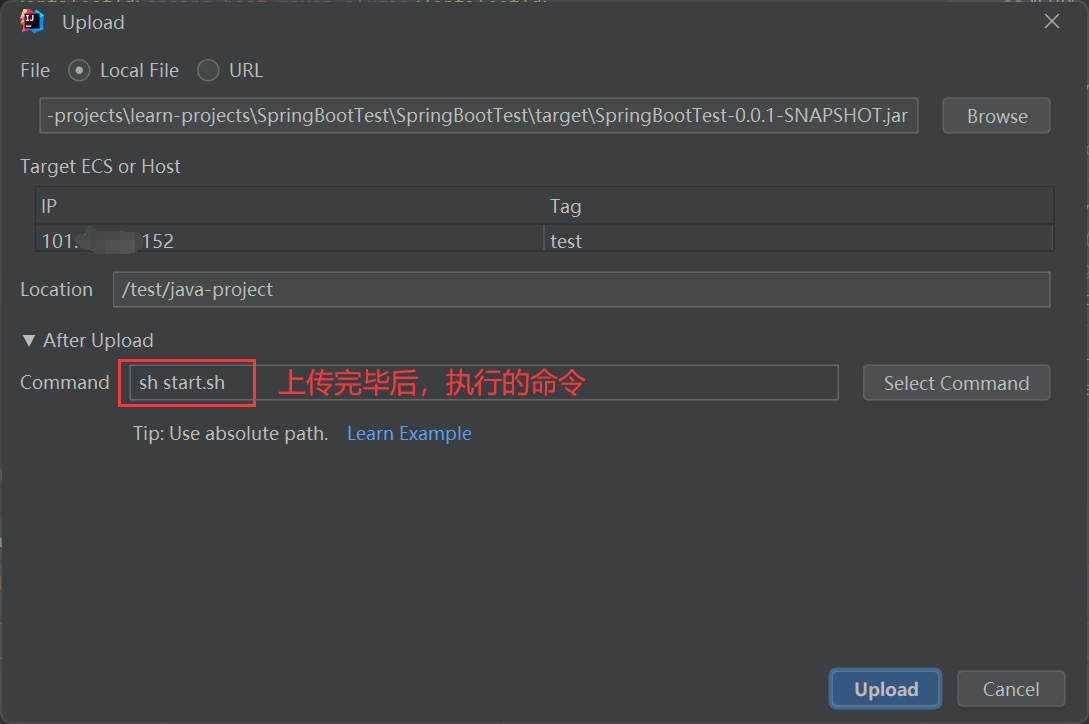
点击上传,配置上传的文件、上传地址以及执行的脚本
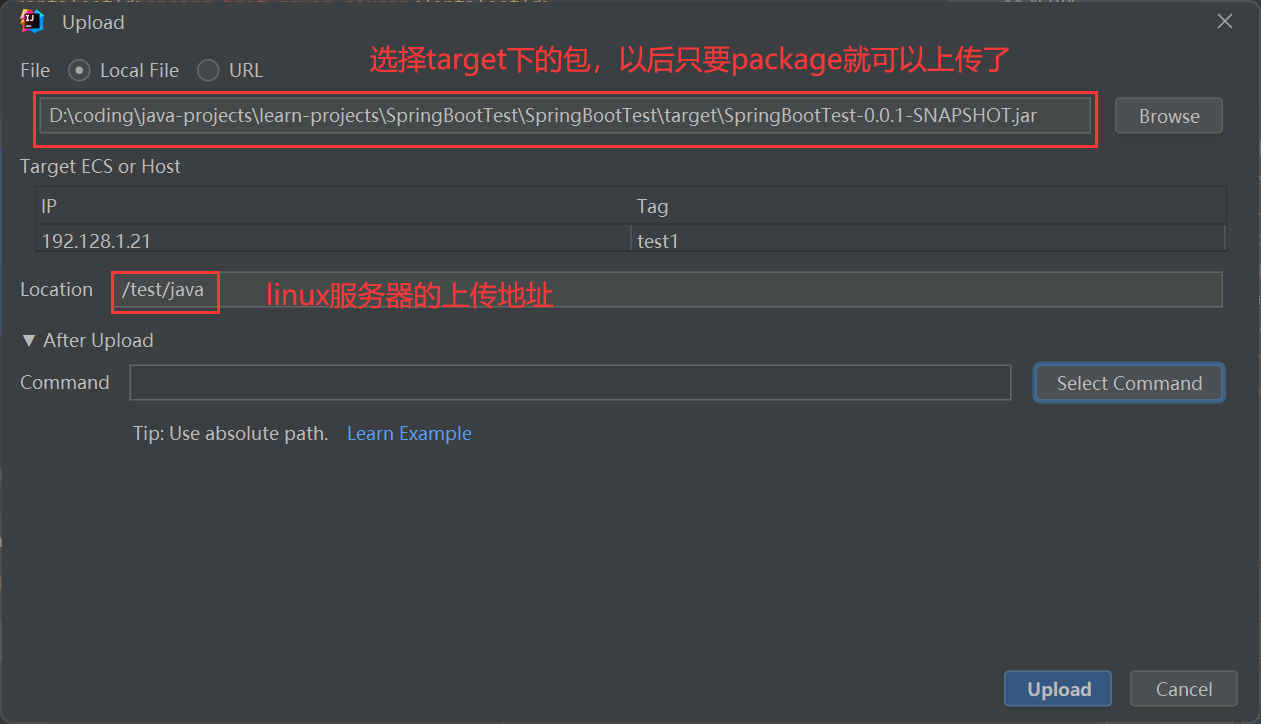
填加执行命令
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m