链表作为 C 语言中一种基础的数据结构,在平时写程序的时候用的并不多,但在操作系统里面使用的非常多。不管是RTOS还是Linux等使用非常广泛,所以必须要搞懂链表,链表分为单向链表和双向链表,单向链表很少用,使用最多的还是双向链表。单向链表懂了双向链表自然就会了。
文章目录
定义:
链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构。
特点:
链表由一系列节点(链表中每一个元素称为节点)组成,节点在运行时动态生成 (malloc),每个节点包括两个部分:
一个是存储数据元素的数据域
另一个是存储下一个节点地址的指针域

图1 单向链表
链表由一个个节点构成,每个节点一般采用结构体的形式组织,例如:
typedef struct student{
int num;
char name[20];
struct student *next;
}STU;链表节点分为两个域
数据域:存放各种实际的数据,如:num、score等
指针域:存放下一节点的首地址,如:next等.

图2 节点内嵌在一个数据结构中
链表最大的作用是通过节点把离散的数据链接在一起,组成一个表,这大概就是链表 的字面解释了吧。 链表常规的操作就是节点的插入和删除,为了顺利的插入,通常一条链 表我们会人为地规定一个根节点,这个根节点称为生产者。通常根节点还会有一个节点计 数器,用于统计整条链表的节点个数,具体见图2中的 root_node。

图3带根节点的链表
双向链表与单向链表的区别就是节点中有两个节点指针,分别指向前后两个节点,其 它完全一样。有关双向链表的文字描述参考单向链表小节即可,有关双向链表的示意图具 体见图3

图4双向链表
在很多公司的嵌入式面试中,通常会问到链表和数组的区别。在 C 语言中,链表与数 组确实很像,两者的示意图具体见图4,这里以双向链表为例。
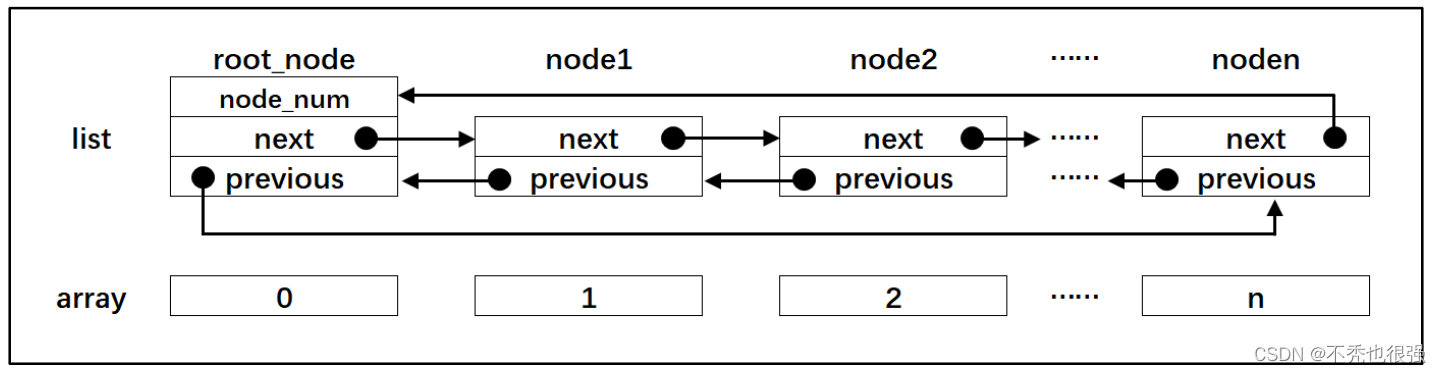 图5 链表与数组的对比
图5 链表与数组的对比
链表是通过节点把离散的数据链接成一个表,通过对节点的插入和删除操作从而实现 对数据的存取。而数组是通过开辟一段连续的内存来存储数据,这是数组和链表最大的区 别。数组的每个成员对应链表的节点,成员和节点的数据类型可以是标准的 C 类型或者是 用户自定义的结构体。数组有起始地址和结束地址,而链表是一个圈,没有头和尾之分, 但是为了方便节点的插入和删除操作会人为的规定一个根节点。
第一步:创建一个节点
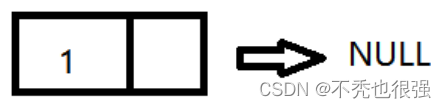
第二步:创建第二个节点,将其放在第一个节点的后面(第一的节点的指针域保存第二个节点的地址)

第三步:再次创建节点,找到原本链表中的最后一个节点,接着讲最后一个节点的指针域保存新节点的地址,以此内推。
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *next;
}STU;
void link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov = *p_head;
if(*p_head == NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->next=NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->next = NULL;
}
}
int main()
{
STU *head = NULL,*p_new = NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i = 0; i < num;i++)
{
p_new = (STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
link_creat_head(&head,p_new); //将新节点加入链表
}
}
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
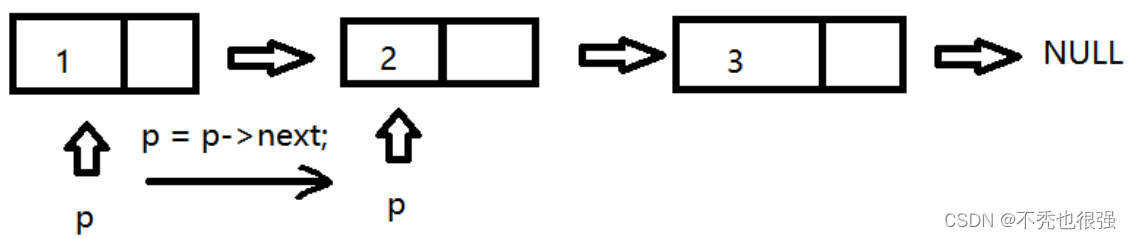
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移
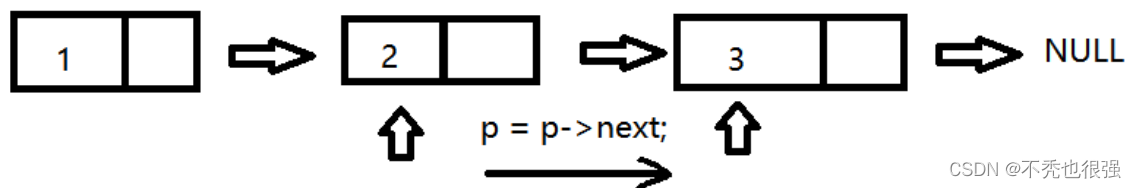
第三步:以此类推,直到节点的指针域为NULL
//链表的遍历
void link_print(STU *head)
{
STU *p_mov;
//定义新的指针保存链表的首地址,防止使用head改变原本链表
p_mov = head;
//当指针保存最后一个结点的指针域为NULL时,循环结束
while(p_mov!=NULL)
{
//先打印当前指针保存结点的指针域
printf("num=%d score=%d name:%s\n",p_mov->num,\
p_mov->score,p_mov->name);
//指针后移,保存下一个结点的地址
p_mov = p_mov->next;
}
}重新定义一个指针q,保存p指向节点的地址,然后p后移保存下一个节点的地址,然后释放q对应的节点,以此类推,直到p为NULL为止

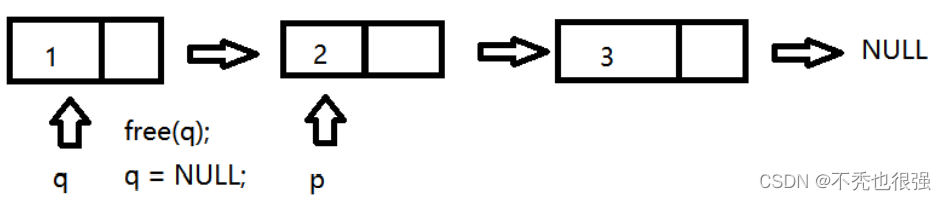
//链表的释放
void link_free(STU **p_head)
{
//定义一个指针变量保存头结点的地址
STU *pb=*p_head;
while(*p_head!=NULL)
{
//先保存p_head指向的结点的地址
pb=*p_head;
//p_head保存下一个结点地址
*p_head=(*p_head)‐>next;
//释放结点并防止野指针
free(pb);
pb = NULL;
}
}先对比第一个结点的数据域是否是想要的数据,如果是就直接返回,如果不是则继续查找下 一个结点,如果到达最后一个结点的时候都没有匹配的数据,说明要查找数据不存在
//链表的查找
//按照学号查找
STU * link_search_num(STU *head,int num)
{
STU *p_mov;
//定义的指针变量保存第一个结点的地址
p_mov=head;
//当没有到达最后一个结点的指针域时循环继续
while(p_mov!=NULL)
{
//如果找到是当前结点的数据,则返回当前结点的地址
if(p_mov->num == num)//找到了
{
return p_mov;
}
//如果没有找到,则继续对比下一个结点的指针域
p_mov=p_mov->next;
}
//当循环结束的时候还没有找到,说明要查找的数据不存在,返回NULL进行标识
return NULL;//没有找到
}
//按照姓名查找
STU * link_search_name(STU *head,char *name)
{
STU *p_mov;
p_mov=head;
while(p_mov!=NULL)
{
if(strcmp(p_mov->name,name)==0)//找到了
{
return p_mov;
}
p_mov=p_mov->next;
}
return NULL;//没有找到
}如果链表为空,不需要删除 如果删除的是第一个结点,则需要将保存链表首地址的指针保存第一个结点的下一个结点的 地址 如果删除的是中间结点,则找到中间结点的前一个结点,让前一个结点的指针域保存这个结 点的后一个结点的地址即可
//链表结点的删除
void link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head == NULL)//链表为空,不用删
{
printf("链表为空,没有您要删的节点");\
return ;
}
while(pb->num != num && pb->next !=NULL)//循环找,要删除的节点
{
pf=pb;
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同
{
if(pb == *p_head)//要删除的节点是头节点
{
//让保存头结点的指针保存后一个结点的地址
*p_head = pb->next;
}
else
{
//前一个结点的指针域保存要删除的后一个结点的地址
pf->next = pb->next;
}
//释放空间
free(pb);
pb = NULL;
}
else//没有找到
{
printf("没有您要删除的节点\n");
}
}链表中插入一个结点,按照原本链表的顺序插入,找到合适的位置
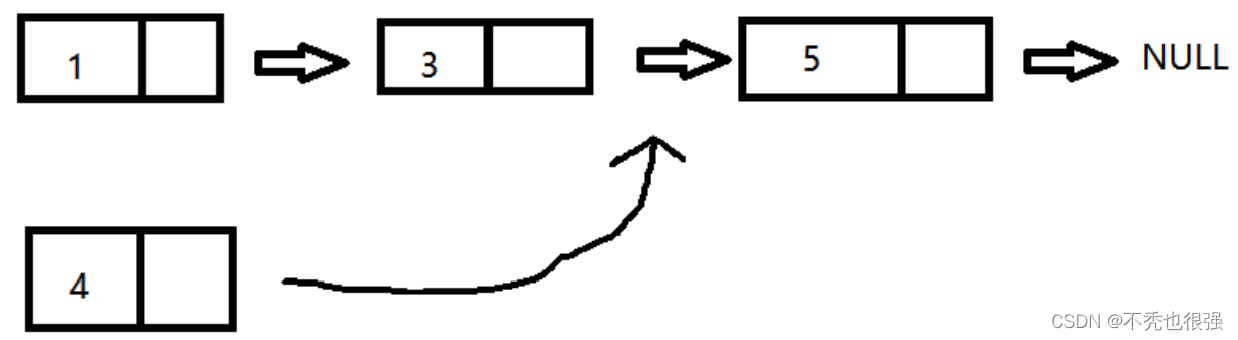
情况(按照从小到大):
如果链表没有结点,则新插入的就是第一个结点。
如果新插入的结点的数值最小,则作为头结点。
如果新插入的结点的数值在中间位置,则找到前一个,然后插入到他们中间。
如果新插入的结点的数值最大,则插入到最后。
//链表的插入:按照学号的顺序插入
void link_insert_num(STU **p_head,STU *p_new)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head ==NULL)// 链表为空链表
{
*p_head = p_new;
p_new->next=NULL;
return ;
}
while((p_new->num >= pb->num) && (pb->next !=NULL) )
{
pf=pb;
pb=pb->next;
}
if(p_new->num < pb->num)//找到一个节点的num比新来的节点num大,插在pb的前面
{
if(pb== *p_head)//找到的节点是头节点,插在最前面
{
p_new->next= *p_head;
*p_head =p_new;
}
else
{
pf->next=p_new;
p_new->next = pb;
}
}
else//没有找到pb的num比p_new->num大的节点,插在最后
{
pb->next =p_new;
p_new->next =NULL;
}
}如果链表为空,不需要排序。
如果链表只有一个结点,不需要排序。
先将第一个结点与后面所有的结点依次对比数据域,只要有比第一个结点数据域小的,则交 换位置。
交换之后,拿新的第一个结点的数据域与下一个结点再次对比,如果比他小,再次交换,依 次类推。
第一个结点确定完毕之后,接下来再将第二个结点与后面所有的结点对比,直到最后一个结 点也对比完毕为止。
//链表的排序
void link_order(STU *head)
{
STU *pb,*pf,temp;
pf=head;
if(head==NULL)
{
printf("链表为空,不用排序\n");
return ;
}
if(head->next ==NULL)
{
printf("只有一个节点,不用排序\n");
return ;
}
while(pf->next !=NULL)//以pf指向的节点为基准节点,
{
pb=pf->next;//pb从基准元素的下个元素开始
while(pb!=NULL)
{
if(pf->num > pb->num)
{
temp=*pb;
*pb=*pf;
*pf=temp;
temp.next=pb->next;
pb->next=pf->next;
pf->next=temp.next;
}
pb=pb->next;
}
pf=pf->next;
}
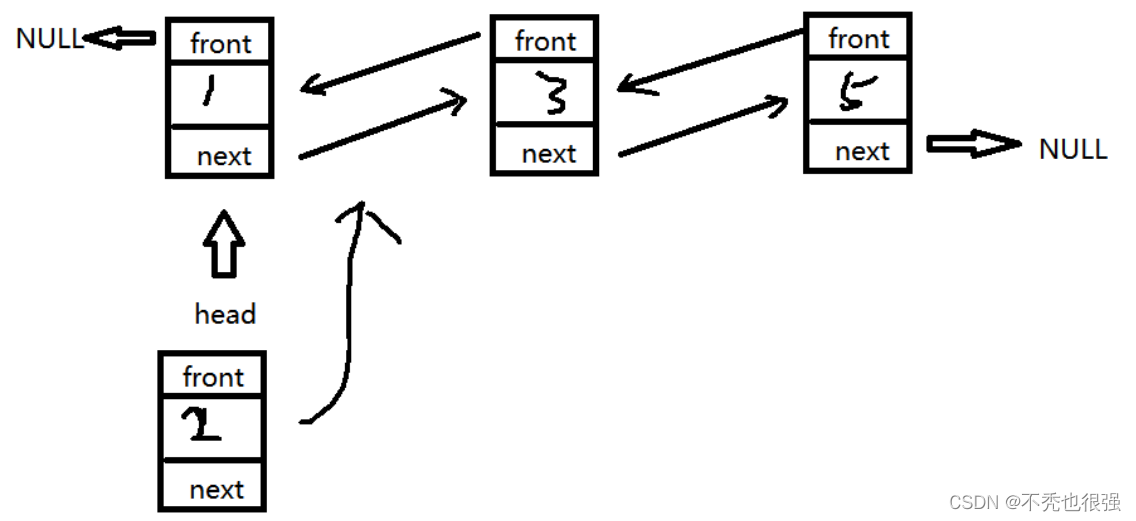
}第一步:创建一个节点作为头节点,将两个指针域都保存NULL
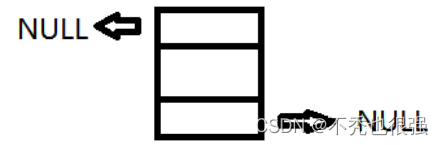
第二步:先找到链表中的最后一个节点,然后让最后一个节点的指针域保存新插入节点的地址,新插入节点的两个指针域,一个保存上一个节点的地址,一个保存NULL
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
}
按照顺序插入结点
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
//双向链表的删除
void double_link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=*p_head;
if(*p_head==NULL)//链表为空,不需要删除
{
printf("链表为空,没有您要删除的节点\n");
return ;
}
while((pb->num != num) && (pb->next != NULL) )
{
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同,删除pb指向的节点
{
if(pb == *p_head)//找到的节点是头节点
{
if((*p_head)->next==NULL)//只有一个节点的情况
{
*p_head=pb->next;
}
else//有多个节点的情况
{
*p_head = pb->next;//main函数中的head指向下个节点
(*p_head)->front=NULL;
}
}
else//要删的节点是其他节点
{
if(pb->next!=NULL)//删除中间节点
{
pf=pb->front;//让pf指向找到的节点的前一个节点
pf->next=pb->next; //前一个结点的next保存后一个结点的地址
(pb->next)->front=pf; //后一个结点的front保存前一个结点的地址
}
else//删除尾节点
{
pf=pb->front;
pf->next=NULL;
}
}
free(pb);//释放找到的节点
}
else//没找到
{
printf("没有您要删除的节点\n");
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
printf("请输入您要删除的节点的num\n");
scanf("%d",&num);
double_link_delete_num(&head,num);
double_link_print(head);
}
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
在前面两节的例子中,主界面窗口的尺寸和标签控件显示的矩形区域等,都是用C++代码编写的。窗口和控件的尺寸都是预估的,控件如果多起来,那就不好估计每个控件合适的位置和大小了。用C++代码编写图形界面的问题就是不直观,因此Qt项目开发了专门的可视化图形界面编辑器——QtDesigner(Qt设计师)。通过QtDesigner就可以很方便地创建图形界面文件*.ui,然后将ui文件应用到源代码里面,做到“所见即所得”,大大方便了图形界面的设计。本节就演示一下QtDesigner的简单使用,学习拖拽控件和设置控件属性,并将ui文件应用到Qt程序代码里。使用QtDesigner设计界面在开始菜单中找到「Q
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear