文章目录
MyBatis 是一个支持普通 SQL 查询、存储过程以及高级映射的持久层框架,它消除了几乎所有的 JDBC 代码和参数的手动设置以及对结果集的检索,使用简单的 XML 或注解进行配置和原始映射,将接口和 Java 的 POJO 映射成数据库中的记录,使得 Java 开发人员可以使用面向对象的编程思想来操作数据库。
针对 JDBC 编程的劣势,MyBatis 提供了以下解决方案,具体如下:
① 在 SqlMapConfig.xml 中配置数据连接池,使用连接池管理数据库链接;
② MyBatis 将 SQL 语句配置在 MyBatis 的映射文件中,实现了与 Java 代码的分离;
③ MyBatis 自动将 Java 对象映射至 SQL 语句,通过 Statement 中的 parameterType 定义输入参数的类型;
④ MyBatis 自动将 SQL 执行结果映射至 Java 对象,通过 Statement 中的 resultType 定义输出结果的类型。
官方地址:https://github.com/mybatis/mybatis-3
(1)打开之后往下滑,找到 Download Latest 下载最新版本。
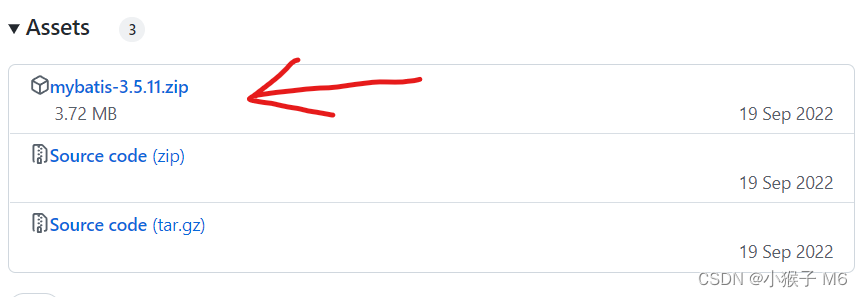
(2)这里可以看到三个包,第一个是我们要的架包,后两个是不同系统下的源码,我们下载第一个架包。
File → Project Structure → Project,1处选择你的 jdk 版本,2 处版本与1一致,Apply。

(1)由于 IDEA 中集成了 Maven,所以我们就不需要下载了,直接使用 IDEA 默认的 Maven 进行项目构建。
(2)打开 IDEA 开发工具,单击 File → new → Project,选择 Maven,点击 Next。

(3)第一行给你的项目起一个名字吧,第二行选择项目要存放的位置,我这里项目的名字叫 MyProject,可以提前在桌面上创了一个文件夹 My 用来放项目文件。(当然位置自己决定)

不要忘记点击 finish 完成!
(4)如图创建成功后就是这个样子。

① View → Tool Windows → DataBase → 屏幕右侧点加号 → DataSource → MySQL
② 填写以下内容
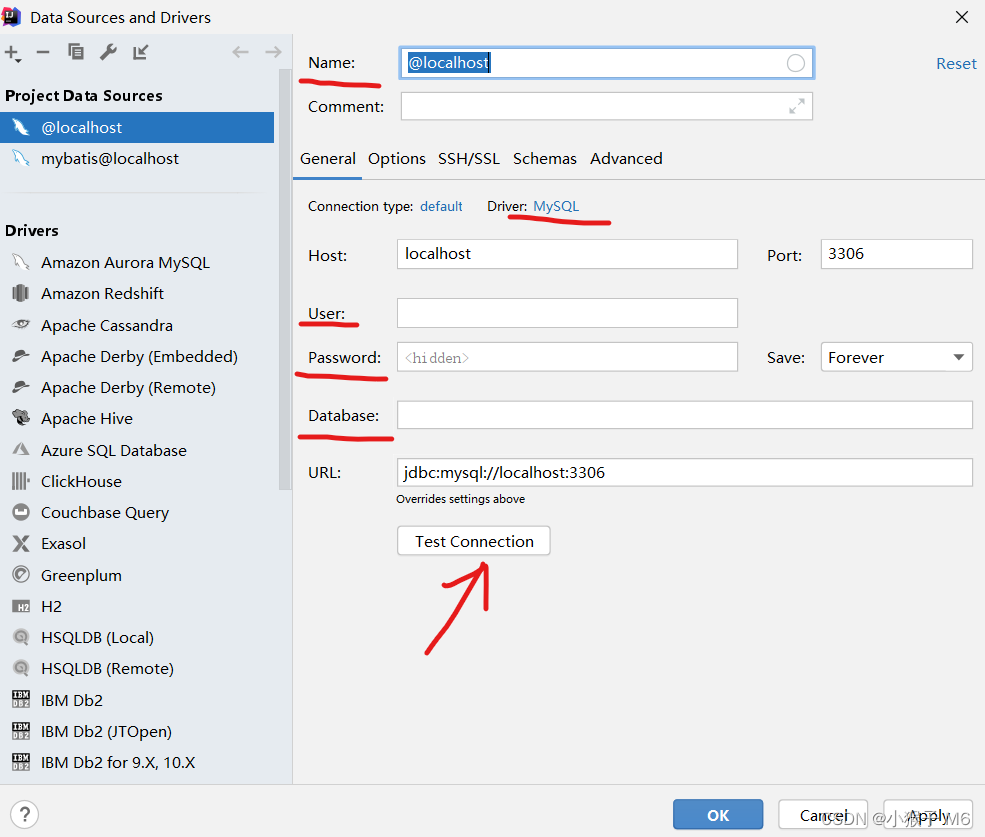
Name 值随便起无所谓,填写你的 MySQL 用户名及密码,Database 处填数据库名,我们刚刚的数据库名叫 mybatis,下面URL路径不用管填了 Database 会自动生成。
③ 点击 Driver:MySQL → Go to driver,选择你的数据库 jar 包,这个包的位置要看你当初把 MySQL 安装在哪个地方了。
④ 点击下面的 Test Connection,是一个测试,如果下面不报错则代表连接成功,最后一步点击 Apply 应用,连接成功后会在 IDEA 右侧显示。
下图是我的项目目录,全部都展开了,大家先按这个构架去创建各种包及文件,名字最好先跟我的一样,避免后面出错。
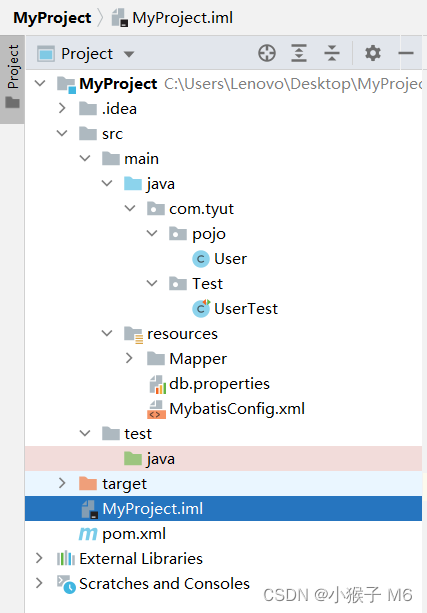
项目需要创建的文件我都展开了,target 里面的不用你管是自动生成的!
将以下依赖代码复制并粘贴到 pom.xml 文件中,什么都不用改,直接复制!
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>

大约粘贴到这个位置,至于我的主题颜色为什么又换成白色的了,hhhhh因为电脑没电了,感JIO眼睛快X了~好了好了言归正传,听我的听我的,下一步赶快去创建一个数据库备用!
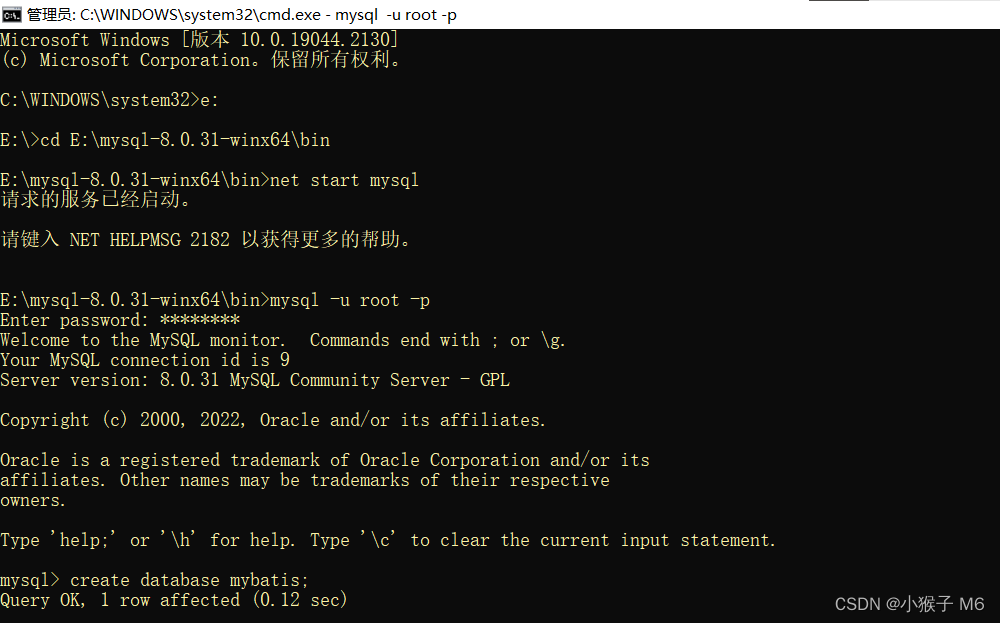
命令行创建数据库:
create database mybatis;
db.properties 文件就是数据库连接的配置文件,在该文件中配置相关参数。
mysql.driver=com.mysql.cj.jdbc.Driver
mysql.username=root
mysql.password=123456bb
mysql.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
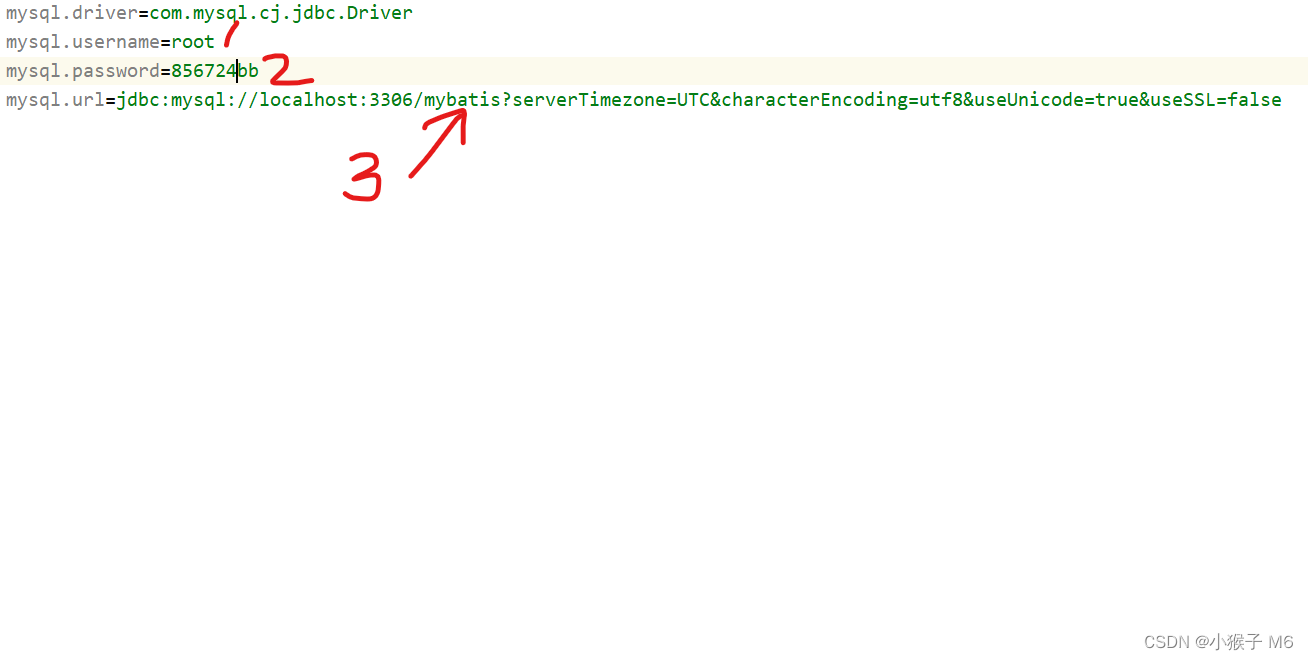
先把我的代码全部复制上,需要你自己修改的地方有三个,1处是你的 MySQL 用户名,2处是你的 MySQL 密码,3处是数据库名,即 mybatis 这是我们刚才创建的那个数据库!
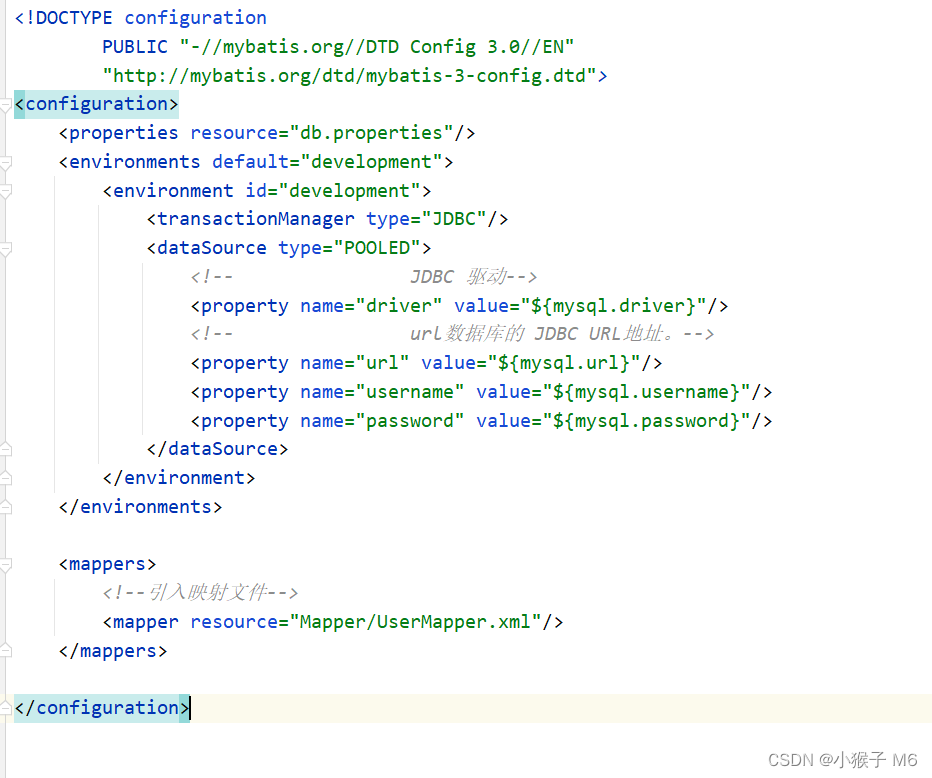
刚刚创建的 MybatisConfig.xml 就是 Mybatis 的核心配置文件。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"/>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- JDBC 驱动-->
<property name="driver" value="${mysql.driver}"/>
<!-- url数据库的 JDBC URL地址。-->
<property name="url" value="${mysql.url}"/>
<property name="username" value="${mysql.username}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--引入映射文件-->
<mapper resource="Mapper/UserMapper.xml"/>
</mappers>
</configuration>
如果你是跟着我的步骤一步一步来的,那么不需要修改任何地方,可以完全复制。
use mybatis;
//创建表
create table Users(
uid int not null auto_increment primary key,
uname varchar(10) not null,
uage int not null
);
//插入数据
insert into Users(uid,uname,uage) values(null,'张三',20),(null,'李四',18);

pojo 包下的 User 类,用于封装 User 对象的属性。
package com.tyut.pojo;
public class User {
private int uid;
private String uname;
private int uage;
public int getUid() {
return uid;
}
public void setUid(int uid) {
this.uid = uid;
}
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public int getUage() {
return uage;
}
public void setUage(int uage) {
this.uage = uage;
}
}
各变量名称与数据库里的保持一致,同样如果你是完全跟着我走的,那可以直接复制了!
Mapper 文件夹下的 UserMapper.xml 文件即映射文件。
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tyut.pojo.User">
<select id="findById" parameterType="int" resultType="com.tyut.pojo.User">
select * from users where uid = #{id}
</select>
</mapper>
如果上面配置都是完整跟下来的话,可以直接复制我上面的代码粘贴到你的 UserMapper.xml 文件里,如果文件名或者数据库里面的表名等等不一样的话,可自行修改,注意路径写对。
每次新建一个实体类就要创建一个映射文件,由于创建映射文件不会提供头部声明,复制粘贴起来也很麻烦,所以这里我们可以通过创建一个映射文件模板的方式,新建映射文件。(当然不影响本项目,你可以不创建,只不过为了方便)
具体步骤,File → Settings → Editor → File and Code Templates → 加号
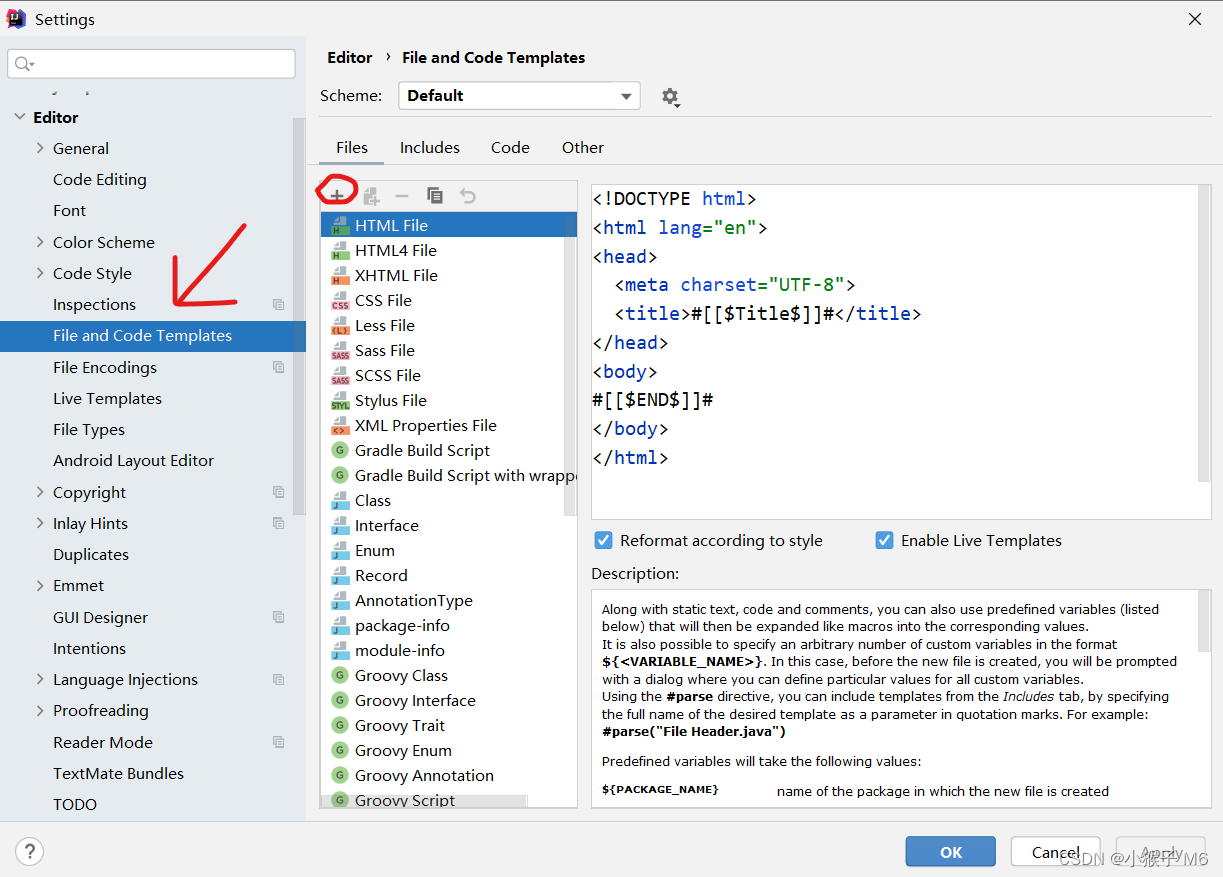
复制我的代码进去:
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tyut.pojo.User">
</mapper>

别忘了 Apply,下次需要可直接在选项卡中看到 mapperxml!
继续打开我们前面已经创建好的 MybatisConfig.xml 文件,现在我们给它配置文件路径,至于刚刚为什么没有配置,是因为这个路径就是映射文件所在的位置,所以我们先把映射文件编写完再返回来给 MybatisConfig.xml 设置路径。
<mappers>
<!--配置xxxMapper.xml文件的位置-->
<mapper resource="Mapper/UserMapper.xml"/>
</mappers>
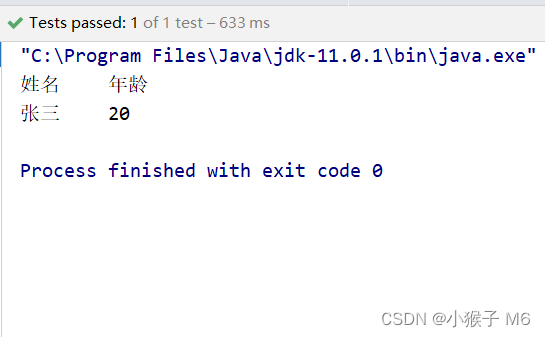
测试类在Test下的 UserTest 中。
package com.tyut.Test;
import com.tyut.pojo.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import java.io.Reader;
import java.io.IOException;
public class UserTest {
@Test
public void userFindByTest() {
String resources = "MybatisConfig.xml";
Reader reader = null;
try {
reader = Resources.getResourceAsReader(resources);
}catch (IOException e) {
e.printStackTrace();
}
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlMapper.openSession();
User user = session.selectOne("findById",1);
System.out.println("姓名\t年龄");
System.out.println(user.getUname()+"\t"+user.getUage());
session.close();
}
}
运行结果:
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe