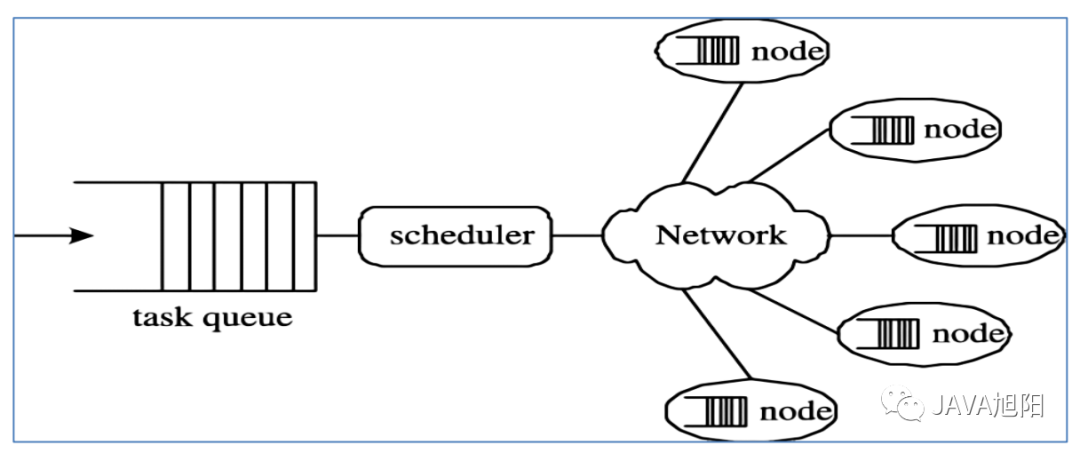
 整个思想的核心就是“先分再合,分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。 那么Hadoop也借鉴了这样的思想,设计出了MapReduce计算框架。那么MapReduce框架具体设计上有什么亮点呢?
整个思想的核心就是“先分再合,分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。 那么Hadoop也借鉴了这样的思想,设计出了MapReduce计算框架。那么MapReduce框架具体设计上有什么亮点呢?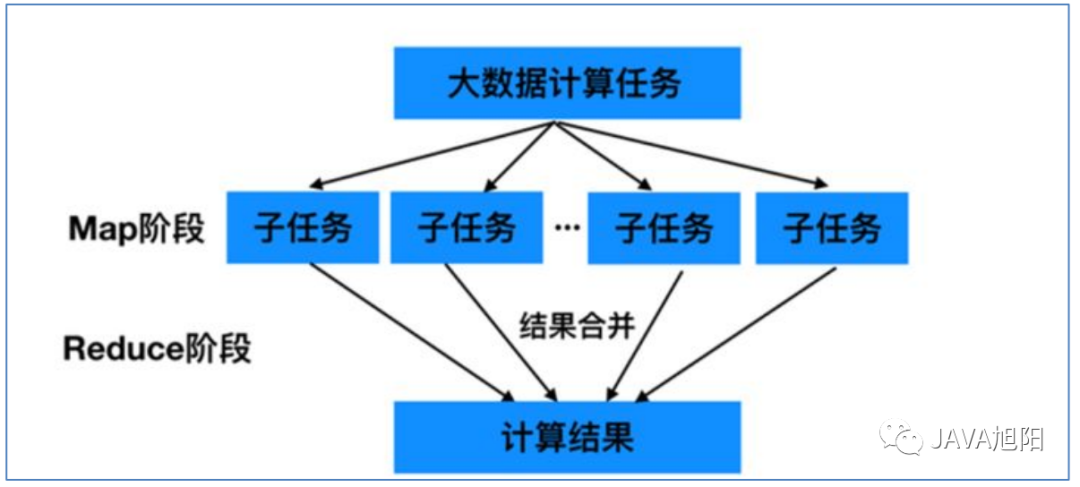
 MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:map: (k1; v1) → (k2; v2)
reduce: (k2; [v2]) → (k3; v3)
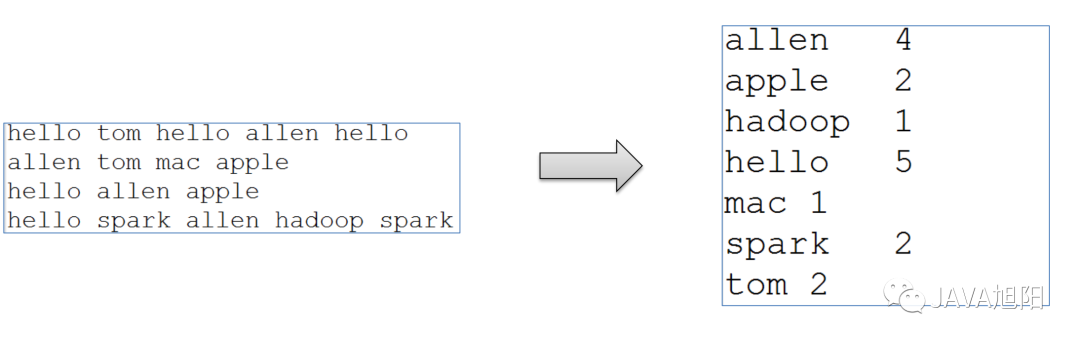 Map阶段代码实现
Map阶段代码实现 实现了map接口,把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。Reduce阶段代码实现
实现了map接口,把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。Reduce阶段代码实现 实现了reduce接口,对所有的1进行累加求和,就是单词的总次数启动代码
实现了reduce接口,对所有的1进行累加求和,就是单词的总次数启动代码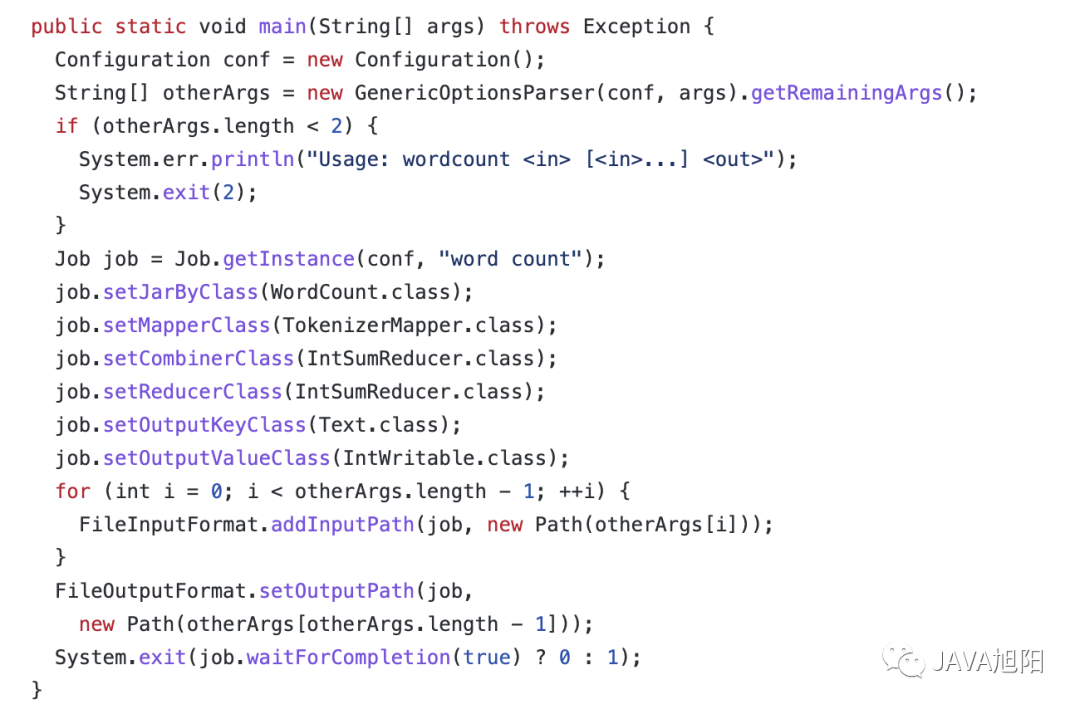 可以参考官方例子:https://github.com/apache/hadoop/blob/branch-3.3.0/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java运行
可以参考官方例子:https://github.com/apache/hadoop/blob/branch-3.3.0/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java运行hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount
/input /output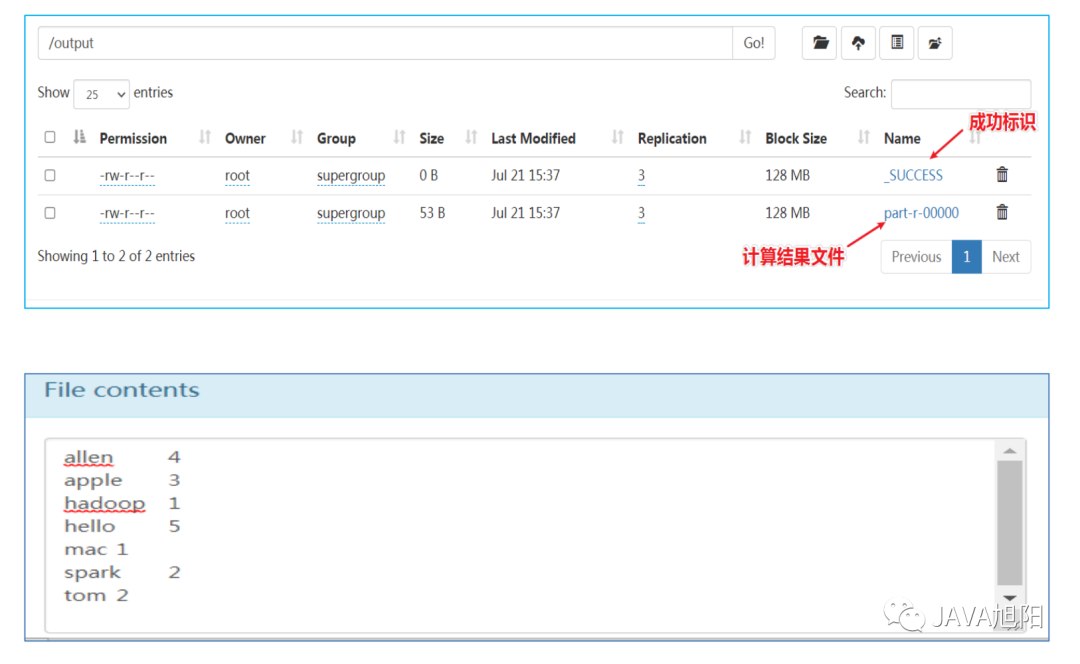
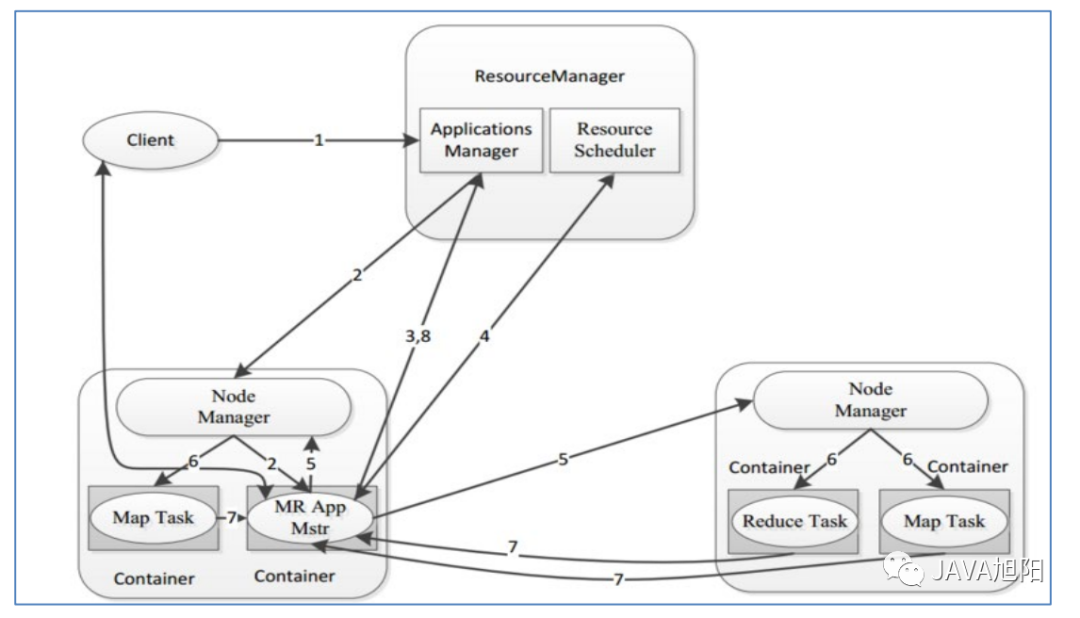 MapReduce任务优先会提交到Yarn组件上,这个主要是用来管理资源的,因为计算需要CPU、内存等资源。首先会运行1个MRAppMaster程序,主要负责整个MR程序的过程调度及状态协调。然后运行多个MapTask,最后运行ReduceTask。从业务逻辑层面上,以上面的wordCount为例,它的运行流程如下图所示:
MapReduce任务优先会提交到Yarn组件上,这个主要是用来管理资源的,因为计算需要CPU、内存等资源。首先会运行1个MRAppMaster程序,主要负责整个MR程序的过程调度及状态协调。然后运行多个MapTask,最后运行ReduceTask。从业务逻辑层面上,以上面的wordCount为例,它的运行流程如下图所示: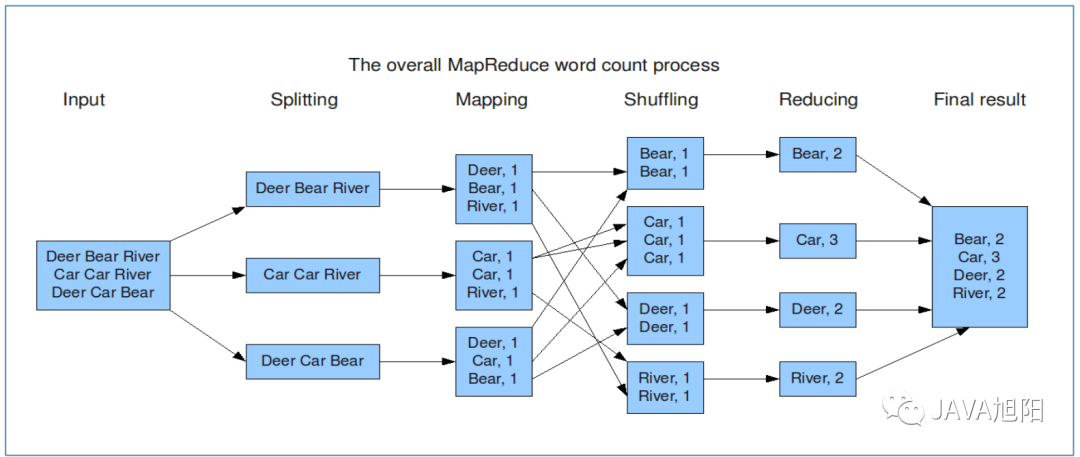 Map阶段执行流程
Map阶段执行流程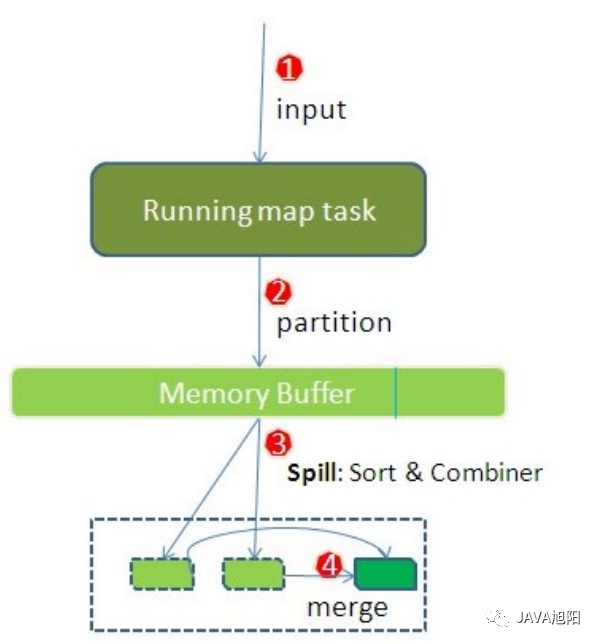 Reduce阶段执行过程
Reduce阶段执行过程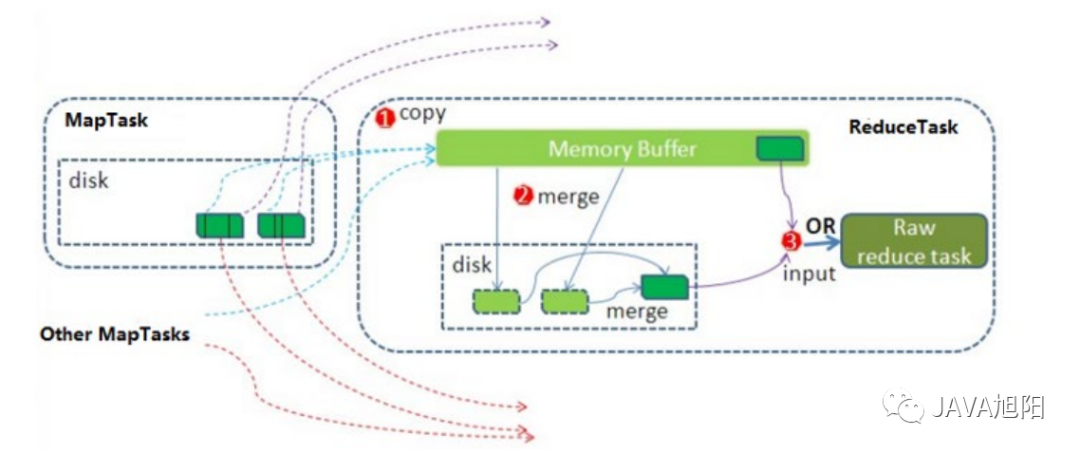 shuffle阶段
shuffle阶段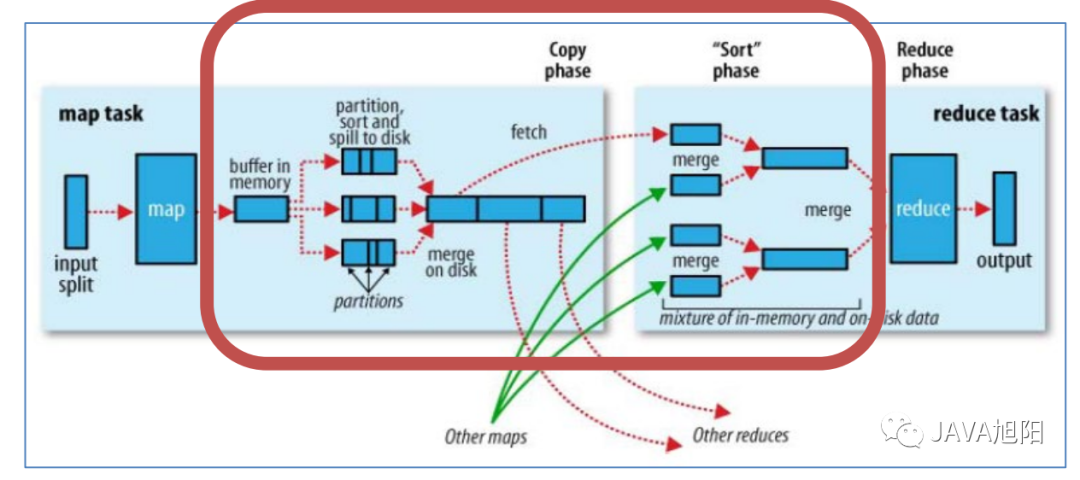 以上就是整个MapReduce执行的整个流程。
以上就是整个MapReduce执行的整个流程。这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
下面例子中的Nested和Child有什么区别?是否只是同一事物的不同语法?classParentclassNested...endendclassChild 最佳答案 不,它们是不同的。嵌套:Computer之外的“Processor”类只能作为Computer::Processor访问。嵌套为内部类(namespace)提供上下文。对于ruby解释器Computer和Computer::Processor只是两个独立的类。classComputerclassProcessor#Tocreateanobjectforthisc
所以我开始关注ruby,很多东西看起来不错,但我对隐式return语句很反感。我理解默认情况下让所有内容返回self或nil但不是语句的最后一个值。对我来说,它看起来非常脆弱(尤其是)如果你正在使用一个不打算返回某些东西的方法(尤其是一个改变状态/破坏性方法的函数!),其他人可能最终依赖于一个返回对方法的目的并不重要,并且有很大的改变机会。隐式返回有什么意义?有没有办法让事情变得更简单?总是有返回以防止隐含返回被认为是好的做法吗?我是不是太担心这个了?附言当人们想要从方法中返回特定的东西时,他们是否经常使用隐式返回,这不是让你组中的其他人更容易破坏彼此的代码吗?当然,记录一切并给出
给定以下方法:defsome_method:valueend以下语句按我的预期工作:some_method||:other#=>:valuex=some_method||:other#=>:value但是下面语句的行为让我感到困惑:some_method=some_method||:other#=>:other它按预期创建了一个名为some_method的局部变量,随后对some_method的调用返回该局部变量的值。但为什么它分配:other而不是:value呢?我知道这可能不是一件明智的事情,并且可以看出它可能有多么模棱两可,但我认为应该在考虑作业之前评估作业的右侧...我已经在R
我在我的Rails3示例应用程序上使用CarrierWave。我想验证远程位置上传,因此当用户提交无效URL(空白或非图像)时,我不会收到标准错误异常:CarrierWave::DownloadErrorinImageController#createtryingtodownloadafilewhichisnotservedoverHTTP这是我的模型:classPaintingtrue,:length=>{:minimum=>5,:maximum=>100}validates:image,:presence=>trueend这是我的Controller:classPaintingsC
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in