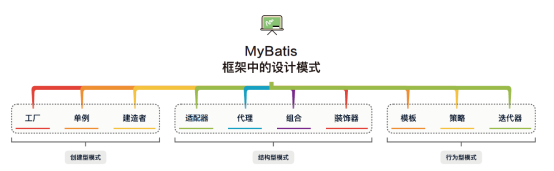
 图1
图1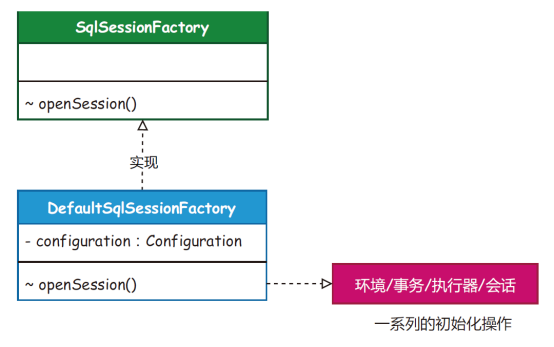 图2工厂模式:简单工厂是一种创建型模式,在父类中提供一个创建对象的方法,允许子类决定实例对象的类型。场景介绍:SqlSessionFactory 是获取会话的工厂,每次使用MyBatis 操作数据库时, 都会开启一个新的会话。在会话工厂的实现中,SqlSessionFactory 负责获取数据源环境配置信息、构建事务工厂和创建操作SQL 的执行器,最终返回会话实现类。同类设计:SqlSessionFactory、ObjectFactory、MapperProxyFactory 和DataSourceFactory。
图2工厂模式:简单工厂是一种创建型模式,在父类中提供一个创建对象的方法,允许子类决定实例对象的类型。场景介绍:SqlSessionFactory 是获取会话的工厂,每次使用MyBatis 操作数据库时, 都会开启一个新的会话。在会话工厂的实现中,SqlSessionFactory 负责获取数据源环境配置信息、构建事务工厂和创建操作SQL 的执行器,最终返回会话实现类。同类设计:SqlSessionFactory、ObjectFactory、MapperProxyFactory 和DataSourceFactory。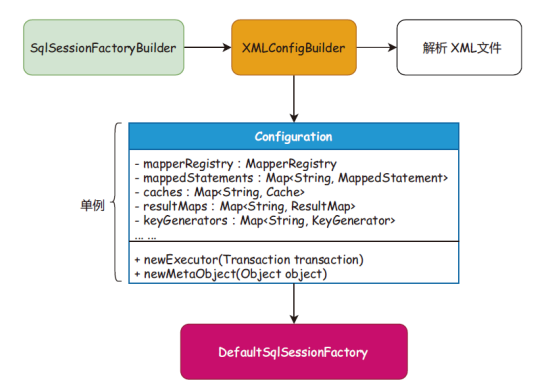 图3单例模式:是一种创建型模式,能够保证一个类只有一个实例,并且提供一个访问该实例的全局节点。场景介绍:Configuration 是一个大单例,贯穿整个会话周期,所有的配置对象(如映射、缓存、入参、出参、拦截器、注册机和对象工厂等)都在Configuration 配置项中初始化, 并且随着SqlSessionFactoryBuilder 构建阶段完成实例化操作。同类场景:ErrorContext、LogFactory 和Configuration。
图3单例模式:是一种创建型模式,能够保证一个类只有一个实例,并且提供一个访问该实例的全局节点。场景介绍:Configuration 是一个大单例,贯穿整个会话周期,所有的配置对象(如映射、缓存、入参、出参、拦截器、注册机和对象工厂等)都在Configuration 配置项中初始化, 并且随着SqlSessionFactoryBuilder 构建阶段完成实例化操作。同类场景:ErrorContext、LogFactory 和Configuration。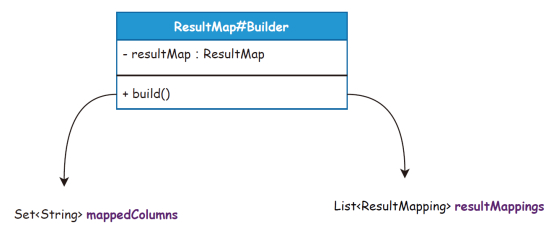 图4建造者模式:使用多个简单的对象一步一步地构建成一个复杂的对象,提供了一种创建对象的最佳方式。场景介绍:建造者模式在MyBatis 中使用了大量的XxxxBuilder,将XML 文件解析到各类对象的封装中,使用建造者及建造者助手完成对象的封装。它的核心目的是不希望把过多的关于对象的属性设置写到其他业务流程中,而是用建造者方式提供最佳的边界隔离。同类场景:SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XML StatementBuilder 和CacheBuilder。
图4建造者模式:使用多个简单的对象一步一步地构建成一个复杂的对象,提供了一种创建对象的最佳方式。场景介绍:建造者模式在MyBatis 中使用了大量的XxxxBuilder,将XML 文件解析到各类对象的封装中,使用建造者及建造者助手完成对象的封装。它的核心目的是不希望把过多的关于对象的属性设置写到其他业务流程中,而是用建造者方式提供最佳的边界隔离。同类场景:SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XML StatementBuilder 和CacheBuilder。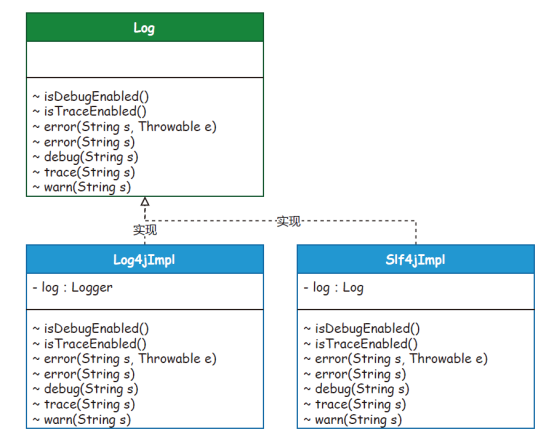 图5适配器模式:是一种结构型模式,能使接口不兼容的对象也可以相互合作。场景介绍:正是因为有太多的日志框架,包括Log4j、Log4j2 和Slf4J 等,而这些日志框架的使用接口又各有差异,为了统一这些日志框架的接口,MyBatis 定义了一套统一的接口,为所有的其他日志框架的接口做相应的适配。同类场景:主要集中在对Log 日志的适配上。
图5适配器模式:是一种结构型模式,能使接口不兼容的对象也可以相互合作。场景介绍:正是因为有太多的日志框架,包括Log4j、Log4j2 和Slf4J 等,而这些日志框架的使用接口又各有差异,为了统一这些日志框架的接口,MyBatis 定义了一套统一的接口,为所有的其他日志框架的接口做相应的适配。同类场景:主要集中在对Log 日志的适配上。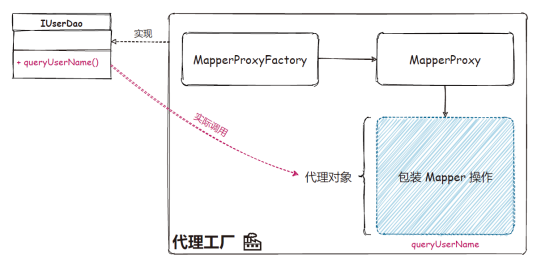 图6代理模式:是一种结构型模式,能够提供对象的替代品或占位符。代理控制元对象的访问,并且允许在将请求提交给对象前进行一些处理。场景介绍:没有代理模式就不存在各类框架。就像MyBatis 中的MapperProxy 实现类, 代理工厂实现的功能就是完成DAO 接口的具体实现类的方法,配置的任何一个DAO 接口调用的CRUD 方法,都会被MapperProxy 接管,调用到方法执行器等,并返回最终的数据库执行结果。同类场景:DriverProxy、Plugin、Invoker 和MapperProxy。
图6代理模式:是一种结构型模式,能够提供对象的替代品或占位符。代理控制元对象的访问,并且允许在将请求提交给对象前进行一些处理。场景介绍:没有代理模式就不存在各类框架。就像MyBatis 中的MapperProxy 实现类, 代理工厂实现的功能就是完成DAO 接口的具体实现类的方法,配置的任何一个DAO 接口调用的CRUD 方法,都会被MapperProxy 接管,调用到方法执行器等,并返回最终的数据库执行结果。同类场景:DriverProxy、Plugin、Invoker 和MapperProxy。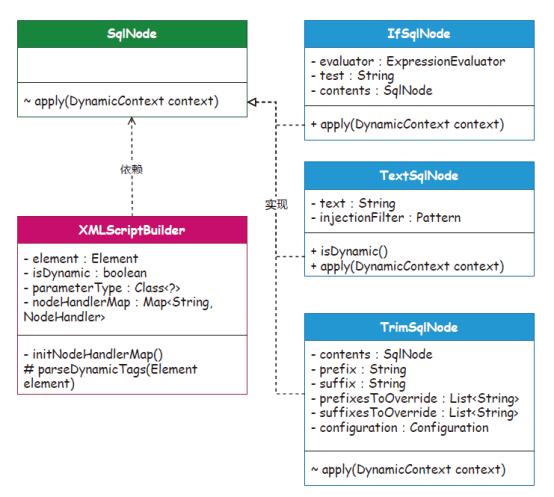 图7组合模式:是一种结构型模式,可以将对象组合成树形结构以表示“部分—整体” 的层次结构。场景介绍:在MyBatis XML 动态的SQL 配置中,共提供了9 种标签(trim、where、set、foreach、if、choose、when、otherwise 和bind),使用者可以组合出各类场景的SQL 语句。而SqlNode 接口的实现就是每个组合结构中的规则节点,通过规则节点的组装,完成规则树组合模式的使用。同类场景:主要体现在对各类SQL 标签的解析上,以实现SqlNode 接口的各个子类为主。
图7组合模式:是一种结构型模式,可以将对象组合成树形结构以表示“部分—整体” 的层次结构。场景介绍:在MyBatis XML 动态的SQL 配置中,共提供了9 种标签(trim、where、set、foreach、if、choose、when、otherwise 和bind),使用者可以组合出各类场景的SQL 语句。而SqlNode 接口的实现就是每个组合结构中的规则节点,通过规则节点的组装,完成规则树组合模式的使用。同类场景:主要体现在对各类SQL 标签的解析上,以实现SqlNode 接口的各个子类为主。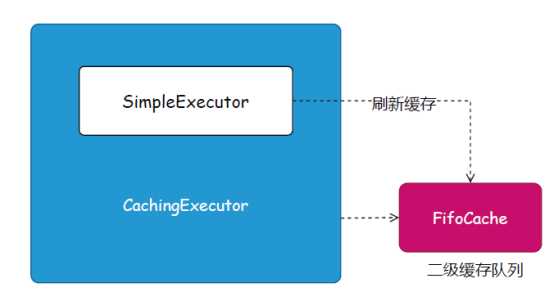 图8装饰器模式:是一种结构型设计模式,允许将对象放入包含行为的特殊封装对象中, 为元对象绑定新的行为。场景介绍:MyBatis 的所有SQL 操作都是经过SqlSession 调用SimpleExecutor 完成的, 而一级缓存的操作也是在简单执行器中处理的。这里的二级缓存因为是基于一级缓存刷新的,所以在实现上,通过创建一个缓存执行器,包装简单执行器的处理逻辑,实现二级缓存操作。这里用到的就是装饰器模式,也叫俄罗斯套娃模式。
图8装饰器模式:是一种结构型设计模式,允许将对象放入包含行为的特殊封装对象中, 为元对象绑定新的行为。场景介绍:MyBatis 的所有SQL 操作都是经过SqlSession 调用SimpleExecutor 完成的, 而一级缓存的操作也是在简单执行器中处理的。这里的二级缓存因为是基于一级缓存刷新的,所以在实现上,通过创建一个缓存执行器,包装简单执行器的处理逻辑,实现二级缓存操作。这里用到的就是装饰器模式,也叫俄罗斯套娃模式。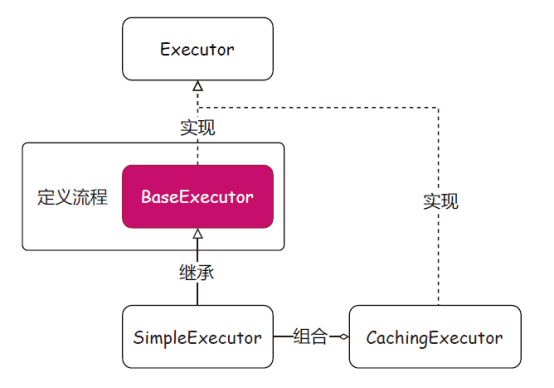 图9模板模式:是一种行为型模式,在超类中定义了一个算法的框架,允许子类在不修改结构的情况下重写算法的特定步骤。场景介绍:存在一系列可被标准定义的流程,并且流程的步骤大部分采用通用逻辑,只有一小部分是需要子类实现的,通常采用模板模式来定义这个标准的流程。就像MyBatis 的BaseExecutor 就是一个用于定义模板模式的抽象类,在这个类中把查询、修改的操作都定义为一套标准的流程。同类场景:BaseExecutor、SimpleExecutor 和BaseTypeHandler。
图9模板模式:是一种行为型模式,在超类中定义了一个算法的框架,允许子类在不修改结构的情况下重写算法的特定步骤。场景介绍:存在一系列可被标准定义的流程,并且流程的步骤大部分采用通用逻辑,只有一小部分是需要子类实现的,通常采用模板模式来定义这个标准的流程。就像MyBatis 的BaseExecutor 就是一个用于定义模板模式的抽象类,在这个类中把查询、修改的操作都定义为一套标准的流程。同类场景:BaseExecutor、SimpleExecutor 和BaseTypeHandler。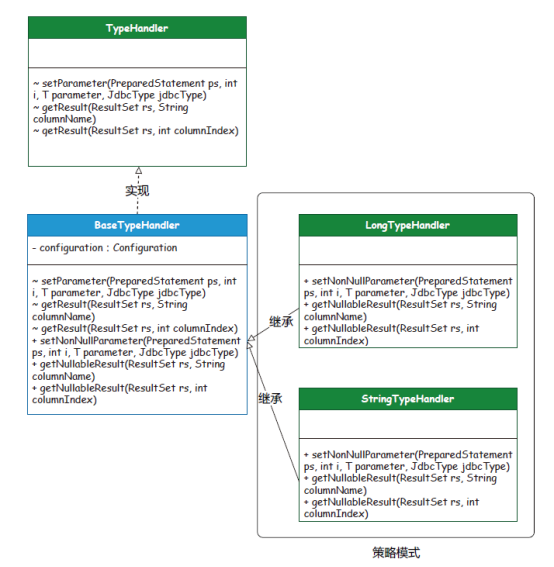 图10策略模式:是一种行为型模式,能定义一系列算法,并将每种算法分别放入独立的类中,从而使算法的对象能够互相替换。场景介绍:在MyBatis 处理JDBC 执行后返回的结果时,需要按照不同的类型获取对应的值,这样就可以避免大量的if 判断。所以,这里基于TypeHandler 接口对每个参数类型分别做了自己的策略实现。同类场景:PooledDataSource、UnpooledDataSource、BatchExecutor、ResuseExecutor、SimpleExector、CachingExecutor、LongTypeHandler、StringTypeHandler 和DateTypeHandler。
图10策略模式:是一种行为型模式,能定义一系列算法,并将每种算法分别放入独立的类中,从而使算法的对象能够互相替换。场景介绍:在MyBatis 处理JDBC 执行后返回的结果时,需要按照不同的类型获取对应的值,这样就可以避免大量的if 判断。所以,这里基于TypeHandler 接口对每个参数类型分别做了自己的策略实现。同类场景:PooledDataSource、UnpooledDataSource、BatchExecutor、ResuseExecutor、SimpleExector、CachingExecutor、LongTypeHandler、StringTypeHandler 和DateTypeHandler。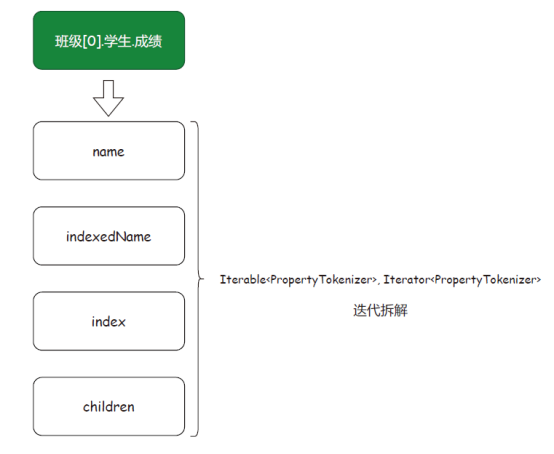 图11迭代器模式:是一种行为型模式,能在不暴露集合底层表现形式的情况下遍历集合中的所有元素。场景介绍:PropertyTokenizer 用于MyBatis 的MetaObject 反射工具包下,用来解析对象关系的迭代操作。这个类在MyBatis 中使用得非常频繁,包括解析数据源配置信息并填充到数据源类上,同时参数的解析、对象的设置都会使用这个类。同类场景:PropertyTokenizer。
图11迭代器模式:是一种行为型模式,能在不暴露集合底层表现形式的情况下遍历集合中的所有元素。场景介绍:PropertyTokenizer 用于MyBatis 的MetaObject 反射工具包下,用来解析对象关系的迭代操作。这个类在MyBatis 中使用得非常频繁,包括解析数据源配置信息并填充到数据源类上,同时参数的解析、对象的设置都会使用这个类。同类场景:PropertyTokenizer。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我正在研究使用EventMachine支持的twitter-streamrubygem来跟踪和捕获推文。我对整个事件编程有点陌生。我如何判断我在事件循环中所做的任何处理是否导致我落后?有没有简单的检查方法? 最佳答案 您可以通过使用周期性计时器并打印出耗时来确定延迟。如果您使用的是1秒的计时器,您应该已经过了大约1秒,如果它更长,您就知道您正在减慢react器的速度。@last=Time.now.to_fEM.add_periodic_timer(1)doputs"LATENCY:#{Time.now.to_f-@last}"@