📜作者:不想脱发的基兄
📺专栏:《嵌入式面试》
📣格言:不管前方的路有多苦,只要走的方向正确,不管多么崎岖不平,都比站在原地更接近幸福。

2022年秋招我面试嵌入式MCU开发方向,经过了多场的笔试与面试,在准备的过程中看了非常多的资料,我的汇总的笔记一直写在有道云笔记中,没有分享出来。现在已经到了23年春招了,特此整理后分享出来。资料看过了觉得不错就保存下来了,如果有不对的地方,欢迎批评指正,侵权联删!
(1)影响执行效率
(2)栈溢出。
因为每一次调用函数是,栈区都要给函数分配空间,而且上一次调用并没有结束,调用的次数太多,栈区的内存不够分配了,便会出现栈溢出的情况。
(1)栈的空间是系统自动分配和回收,堆的空间是用户手动分配回收(malloc,calloc,realloc,free)
(2)栈的空间较小,堆的空间较大
(3)栈的地址空间往地址向下增长,堆的地址空间是由低地址到高地址
(4)栈的存储效率更高
因为goto会破坏程序的栈逻辑。
(1)常用来跳出死循坏;
(2)打印错误;
(3)goto被经常使用,只是使用场合受到局限,因为他会破坏程序的栈逻辑。
字节对齐主要是针对结构体而言的,通常编译器会自动对其成员变量进行对齐,以提高数据存取的效率;
默认对齐方式、指定对齐方式;
(1)默认对齐方式内存分配满足以下三个条件:
结构体第一个成员的地址和结构体的首地址相同;
结构体每个成员地址相对于结构体首地址的偏移量(offset)是该成员大小的整数倍,如果不是则编译器会在成员之间添加填充字节;
结构体总的大小要是其成员中最大size的整数倍,如果不是编译器会在其末尾添加填充字节。
如char是1字节,short是2字节,int是4字节...
(2)指定对齐方式使用以下方式声明:
//注:通过#pragma pack(n)改变C编译器的字节对齐方式
#pragma pack(4) //安装4字节的对齐方式指定对齐方式内存分配满足以下几个条件:
结构体第一个成员的地址和结构体的首地址相同
结构体每个成员的地址偏移需要满足:N大于等于该成员的大小,那么该成员的地址偏移需满足默认对齐方式(地址偏移是其成员大小的整数倍);N小于该成员的大小,那么该成员的地址偏移是N的整数倍。
结构体总的大小需要时N的整数倍,如果不是需要在结构体的末尾进行填充。
如果N大于结构体成员中最大成员的大小,则N不起作用,仍然按照默认方式对齐。
注:在使用#pragma pack设定对齐方式一定要是2的整数幂,也就是(1,2,4,8,16,…),不然不起作用的,仍然按照默认方式对齐。
例1:结构体使用字节对齐为1
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c语言
#include <stdio.h>
#pragma pack(1) //通过#pragma pack(n)改变C编译器的字节对齐方式 在C语言中,结构是一种复合数据类型
struct s1{
char ch; // 1
int a; //4
double b; //8
char c1; //1
};
#pragma pack(1)
struct s2{
char ch; //1
int a; //4
double b; //8
};
int main()
{
printf("s1的大小:%ld\n ",sizeof(struct s1));
printf("s2的大小:%ld\n ",sizeof(struct s2));
return 0;
}
结果:
s1的大小:14
s2的大小:13
例2:结构体使用默认字节对齐方式,m值
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c语言
#include <stdio.h>
struct s1{
char ch; // 1
int a; //4
double b; //8
char c1; //1
};
struct s2{
char ch; //1
int a; //4
double b; //8
};
int main()
{
printf("s1的大小:%ld\n ",sizeof(struct s1));
printf("s2的大小:%ld\n ",sizeof(struct s2));
return 0;
}结果:
s1的大小:24
s1的大小:16
参考链接:https://blog.csdn.net/wdl20170204/article/details/109386825
(1)能,局部变量会屏蔽全局变量。C++中要用全局变量,需要使用 "::"(域解析符) 。C语言中局部变量可以与全局变量同名,在函数内引用这个变量时,会用到同名的局部变量,而不会用到全局变量。
(2)对于有些编译器而言,在同一个函数内可以定义多个同名的局部变量,比如在两个循环体内都定义一个同名的局部变量,而那个局部变量的作用域就在那个循环体内。
fsync()负责将参数fd 所指的文件数据, 由系统缓冲区写回磁盘, 以确保数据同步。
头文件:#include
定义函数:int fsync(int fd);
函数说明:fsync()负责将参数fd 所指的文件数据, 由系统缓冲区写回磁盘, 以确保数据同步.
返回值:成功则返回0, 失败返回-1, errno 为错误代码。
参考链接:https://blog.csdn.net/Michaelwubo/article/details/41210547
const的 常规用法,在变量初次定义时赋初,并用关键字const修饰,使变量只可访问,不能重新赋值修改变量。
(1)限制指针变量修饰:指针变量指向的位置不能被修改。定义时,被 const 修饰的指针变量指针只能在定义时初始化,不能定义之后重新指向新的数据。
(2)限制指针变量指向的数据修饰【指针的解引用】:修饰的指针变量指向的变量的值不能被修改,但是该指针可以指向其它空间。
(3)同时限制指针变量和指针变量指向的变量的值修饰:指针变量指向的位置不能被修改,并且指针变量指向变量的值也不能被修改。
(4)修饰函数形参【指针】:函数形参可以利用const关键字进行限制,来防止在函数内部修改指针指向的数据。
文本段(.text)、数据段(.data)、.bss段、堆(heap)、栈(stack)
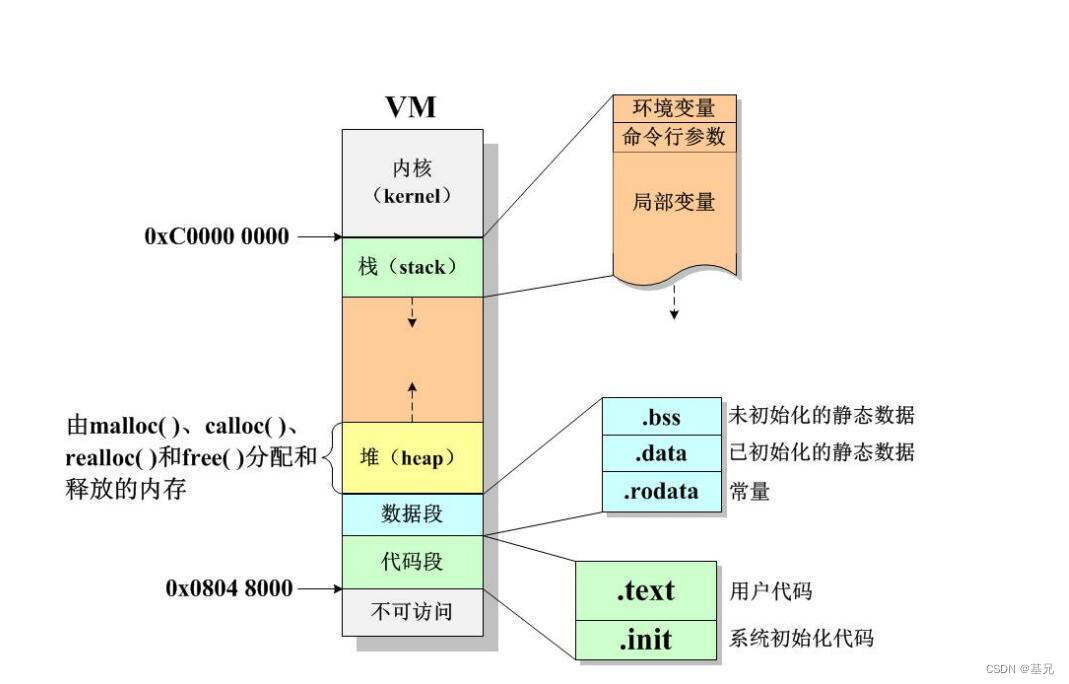
图 虚拟空间的各个部分
(1)裸机编程时,某变量是指向寄存器中某一特定地址,添加volatile的变量不进行优化处理;
(2)某函数与中断函数共享全局变量时,加上volatile,让编译器不要省略该变量的访问;
(3)多线程中修饰共享全局变量,让编译器不要省略该变量的访问。
(1)sizeof是运算符,计算能容纳实现所建立的最大对象的字节大小,参数可以是数组、指针、类型、对象、函数等;
(2)strlen是函数,功能是返回字符串的长度,参数必须是字符型指针(char*)。
(1)内存溢出:指程序申请内存时,没有足够的内存供申请者使用。或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错Out Of Memory,即所谓的内存溢出。
(2)内存泄漏:是指程序在申请内存后,无法释放已申请的内存空间。一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
(1)指针赋值字符串是指向一定内存的指针,只不过是指向字符串常量的指针,指针中的数据不能修改。
(2)数组赋值字符串是一片char型的数组,可以理解为缓冲区,只不过是赋值为了字符串。
(1)malloc申请后空间的值是随机的,并没有进行初始化;而calloc却在申请后,对空间逐一进行初始化,并设置值为0;
(2)malloc要申请的空间大小,需要我们手动的去计算;calloc并不需要人为的计算空间的大小。
while、for 、do while 、goto 循环。
(1)全局变量保存在内存的全局存储区中,占用静态的存储单元;
(2)局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。
预处理器可以删除注释、包含其他文件以及执行宏(宏macro是一段重复文字的简短描写)替代。
编译器就是将一种语言(通常为高级语言)翻译为另一种语言(通常为低级语言)的程序。一个现代编译器的主要工作流程:源代码(.c)→ 预处理器(.i) → 编译器 (.s)→ 目标代码 (.o)→ 链接器 → 可执行程序 。
.ELF是C语言在linux中的可执行文件。
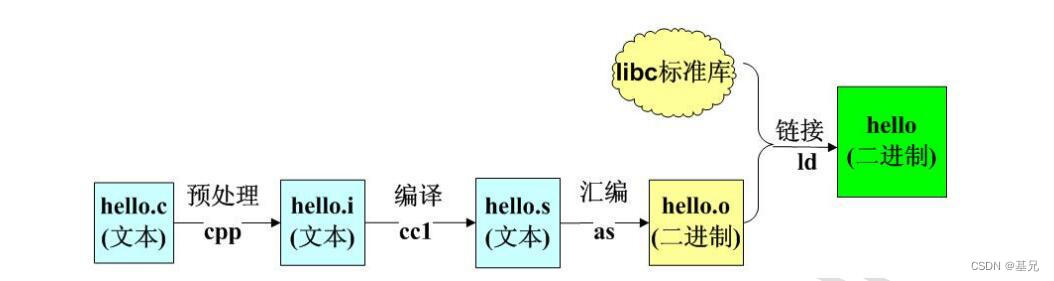
图 编译过程
(1)预处理:根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行文本替换、宏展开、删除注释这类简单工作。
对应的命令:linux> gcc -E hello.c hello.i
(2)编译:编译器将文本文件hello.i翻译成hello.s,包含相应的汇编语言程序。
对应的命令:linux> gcc -S hello.c hello.s
(3)汇编:将.s文件翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行词法分析和语法分析,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。
对应的命令:linux> gcc -c hello.c hello.o
(4)链接:将静态库和动态库的库函数连接到可执行程序中。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为.so,gcc在编译时默认使用动态库。
原文链接:https://blog.csdn.net/daide2012/article/details/73065204
(1)由于C语言是面向过程,而C++是面向对象,所以在定义数据时,可以用C的结构体成员充当C++类的成员定义;
(2)由于结构体只能定义变量,不能够定义函数,所以通过函数指针的方法来实现其类函数的定义。
参考链接:https://blog.csdn.net/forever__1234/article/details/61429870
C语言是嵌入式的基础,像我总结的这些面试题,都是去年我去面试好几家公司所遇到的常见面试题。因此,在面试找工作的那段时间,归纳总结常遇到过的面试题,并将不会的知识点进行检索归纳,是很必要的。这样做的话,可以提升自己的知识面,面试时,就能从容面对不同面试官各种不同的问题。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改
我使用Ruby编程已经有一段时间了,现在只使用Ruby的标准MRI实现,但我一直对我经常听到的其他实现感到好奇。前几天我在读有关Rubinius的文章,这是一个用Ruby编写的Ruby解释器。我试着在不同的地方查找它,但我很难弄清楚这样的东西到底是如何工作的。我在编译器或语言编写方面从来没有太多经验,但我真的很想弄明白。一门语言究竟如何才能被自己解释?编译中是否有一个我不明白这有意义的基本步骤?有人可以像我是个白痴一样向我解释这个吗(因为无论如何这都不会太离谱) 最佳答案 它比你想象的要简单。Rubinius并非100%用Ruby编