1、在python中把一组数据写进mysql中,重点主要是实现python和MySQL的初步连接:
import pymysql # 导入pymysql模块,这样才能连接到mysql,但是还需要我们在DOS中-u root -p输入密码登陆一下,否则连接会报错,可以下载另一个模块解决,但是我觉得没必要登录一下就登录呗,否则模块太多了
db = pymysql.Connect(host='localhost', port=3306, user='root', # 连接数据库MySQL
passwd='******', database='db_securities', charset='utf8') #这就是pymysql.Connect函数,里面的参数大家可以主义研究,直接拿来用只需要改你的密码就是passwd='******'和要连接的数据库database='db_securities'
cursor = db.cursor() # 相当创建一个光标
sql = """ # 典型的SQL语句,以str的形式
insert into t_pe(date, 10yearsyotb, cna, hs300, zz500, zz1000, cyb, kcb, shch, hkt, nsdq100)
values('2022-10-21', 2.7287, 16.36, 10.98, 20.96, 28.35, 45.43, 40.4, 54.72, 36.95, 23.45)
"""
cursor.execute(sql) # 执行SQL语句相当于“;+enter”,SQL遇到;结束,按下enter执行
db.commit() # 提交命令写入硬盘,不过MySQL默认提交,你不乱改的话
cursor.close() # 关闭光标
db.close() # 关闭数据库

2、python连接mysql并写入简单的爬虫数据,重点是json
import requests # 爬虫requests模块
import re # 正则匹配模块
import json # 接送模块,能把类字典的字符串干成字典,能把字典字符串干成字典,反正很强大
import pymysql
index_tuple = [] # 建立一个空列表放爬出来的数据
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'} # 复制过来一个'user-agent'让爬虫模拟用户的更逼真一些,还可以用cookie,代理IP(免费的已经用烂了)
rule = r'quote: (.*),' # 指定正则匹配规则,看一下网页源码数据,自己需求的数据开头是啥,结尾是啥,然后匹配出来
response = requests.get('https://xueqiu.com/S/SH000001', headers=headers) # 发一个get请求,post请求需要交互参数,比如你要输入一个验证码啥的
result = re.findall(rule, response.text) # 把我们的结果匹配出来,匹配出来是个['{目标数据}']这个类型
data = result[0] # 从列表里拿出来'{目标数据}'
data1 = json.loads(data) # 用json还原成字典,然后根据key就可以获得value,一下就是重复爬虫部分和第一部分的连接
index_tuple.extend([float(data1['current']), data1['amount']/100000000])
response = requests.get('https://xueqiu.com/S/SZ399006', headers=headers)
result = re.findall(rule, response.text)
data = result[0]
data1 = json.loads(data)
index_tuple.extend([float(data1['current']), data1['amount']/100000000])
index_list = []
asd = round(index_tuple[1]+index_tuple[3],2)
date = '2022-10-21'
db = pymysql.Connect(host='localhost', port=3306, user='root', # 连接数据库MySQL
passwd='******', database='db_securities', charset='utf8')
cursor = db.cursor()
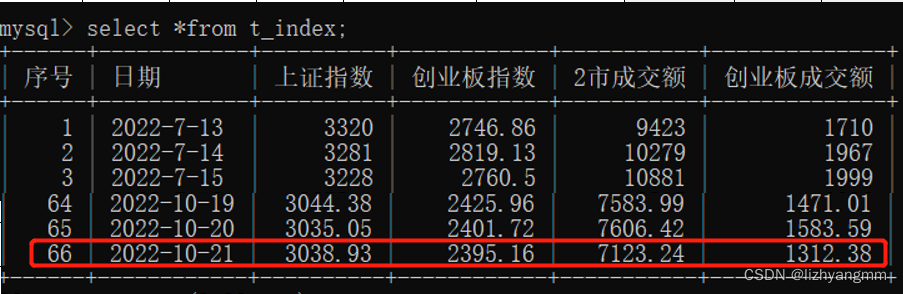
sql = "insert into t_index(日期, 上证指数, 创业板指数, 2市成交额, 创业板成交额)" \
" values('%s', '%.2f', '%.2f', '%.2f', '%.2f')" %(date, index_tuple[0], index_tuple[4], asd, index_tuple[5])
cursor.execute(sql)
db.commit()
cursor.close()
db.close()
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。