
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后端的开发语言ABAP,SQL进行任务的完成,对SAP企业管理系统,SAP ABAP开发和数据库具有较深入的研究。
💅文章概要: ChatGPT最近实在是太火了,各位小伙伴们都用上了吗?本文将从另一个角度出发,教大家如何十分钟学会将Chatgpt部署到我们本地,使用Python调用Chatgpt的API_KEY!
🤟每日一言: 你可以遗憾,但是你绝对不能后悔。遗憾证明你努力过了,只是力有不逮。而后悔,只能说明你当时没努力过。
目录

ChatGPT最近实在是太火了,各位小伙伴们都用上了吗?本文将从另一个角度出发,教大家如何十分钟学会将Chatgpt部署到我们本地,使用Python调用Chatgpt的API_KEY

在正式开始教程之前,首先我们需要完成如下的准备工作:
魔法(电脑能够正常登录Google官网)Python环境open ai库Chatgpt的API_KEYPS:在学习过程中遇到任何问题,请关注公众号
AI方舟点击菜单栏中的联系我,添加我的个人微信。
Python环境的安装市面上已经有大把的教程了,博主在此不再赘述,最好安装Python的最新3.9版本!
在CMD命令行中,输入如下代码安装open ai库:
pip install OPEN AI
PS:在安装open ai库的过程中可能会产生如下报错:
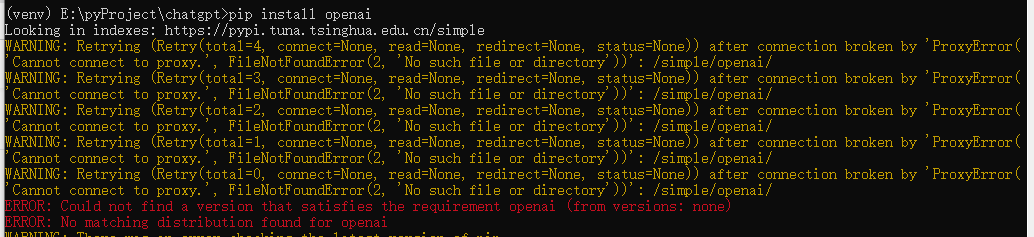
该报错可能是由于如下问题导致:
没有对open ai库给予信任pip版本过高
我们可以通过在pip install openai后面加上软件源并对该存储库给予信任,或者是降低我们的pip版本,CMD中的代码如下:
加上软件源对该存储库给予信任
pip install openai -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
降低pip版本到20.2
python -m pip install pip==20.2 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
PS:如果上述解决方案还是不能解决安装报错问题,请联系博主

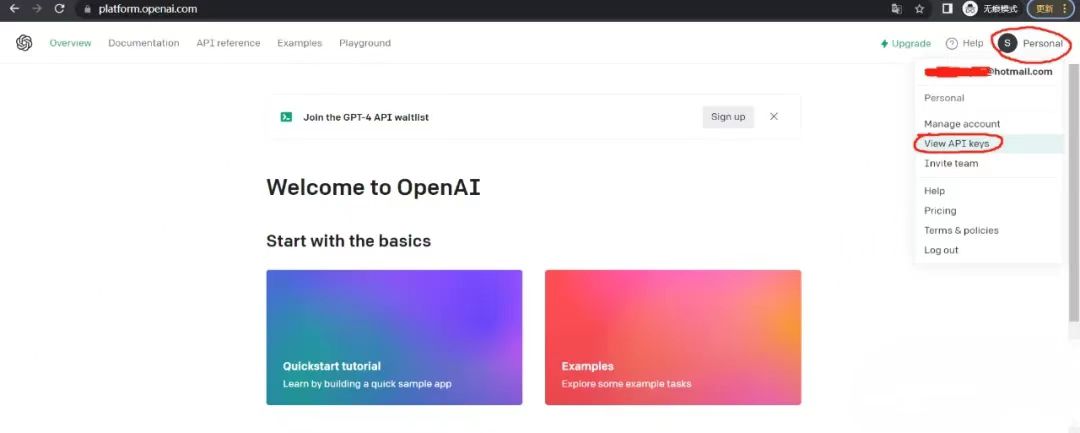
(一)首先,访问Chatgpt官网登录账号
PS:登录成功后,登录之后,点击右上角
“Personal”,展开菜单,找到“View API keys”
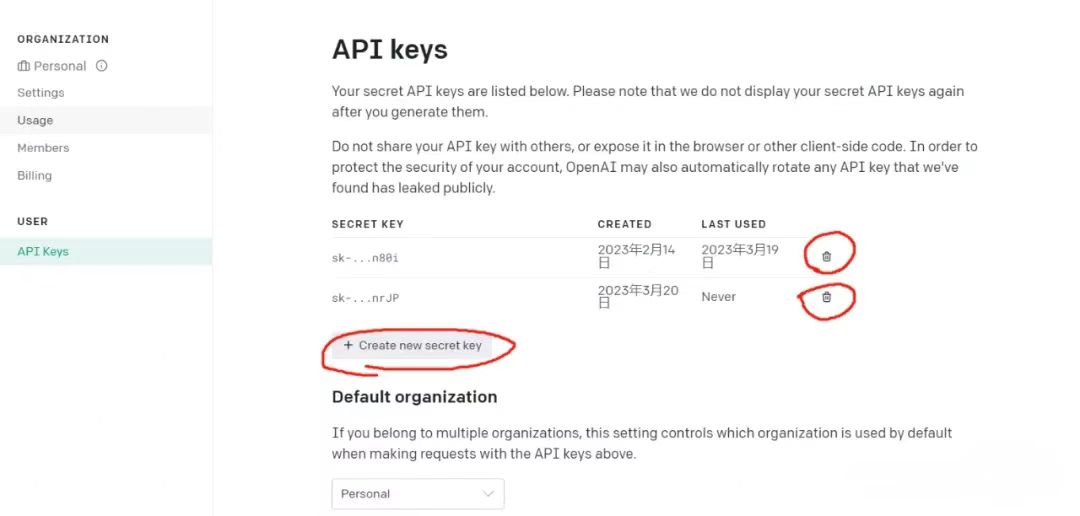
(二)进入页面后,点击“Create new secret key”按钮,来创建API_KEY。之后复制你的key,记住它!!!单个key只会显示一次!
PS:你可以创建多个key,但是多个key是共享总的金额。
import openai
import time
def use_openai_api(words,api_key):
#接收需求,调用openai_api
openai.api_key = 'YOUR_API_KEY'
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": words}]
)
return response
def total_counts(response,current_time):
print(response)
#计算本次任务花了多少钱和多少tokens:
tokens_nums = int(response['usage']['total_tokens']) #计算一下token的消耗
price = 0.002/1000 #根据openai的美元报价算出的1token美元价格
人民币花费 = price * tokens_nums * 7.5
合计内容 = f'当前时刻为{current_time},本次任务共消耗了{tokens_nums}个token,\
共花了{人民币花费}元(人民币)'
print(合计内容)
with open('tokens和费用的合计.txt','a',encoding="utf-8") as f:
f.write(合计内容+"\n"*2)
f.close()
def save_answer(response):
#打印ai最近一次的回答
answer = response.choices[0].message['content']
print(answer)
with open('answer.txt','w',encoding="utf-8") as f:
f.write(answer)
f.close()
def main():
words = input("\n请写出您的需求或问题:\n")
api_key = 'YOUR_API_KEY'
response = use_openai_api(words,api_key)
current_time=time.strftime("%Y年%m月%d日%H点%M分",time.localtime())
total_counts(response,current_time)
save_answer(response)
if __name__ == "__main__":
main()
PS:上面的代码实际运行过程中需要将两处的
YOUR_API_KEY替换为在上面步骤中获取到的自己的API_KEY!
PS:在运行上述代码之前,请全程确保你的电脑可以正常访问Google官网,如果不知道怎么做,请关注公众号
AI方舟点击菜单栏中的联系我,添加我的个人微信。
(一)输入你想要提出的问题
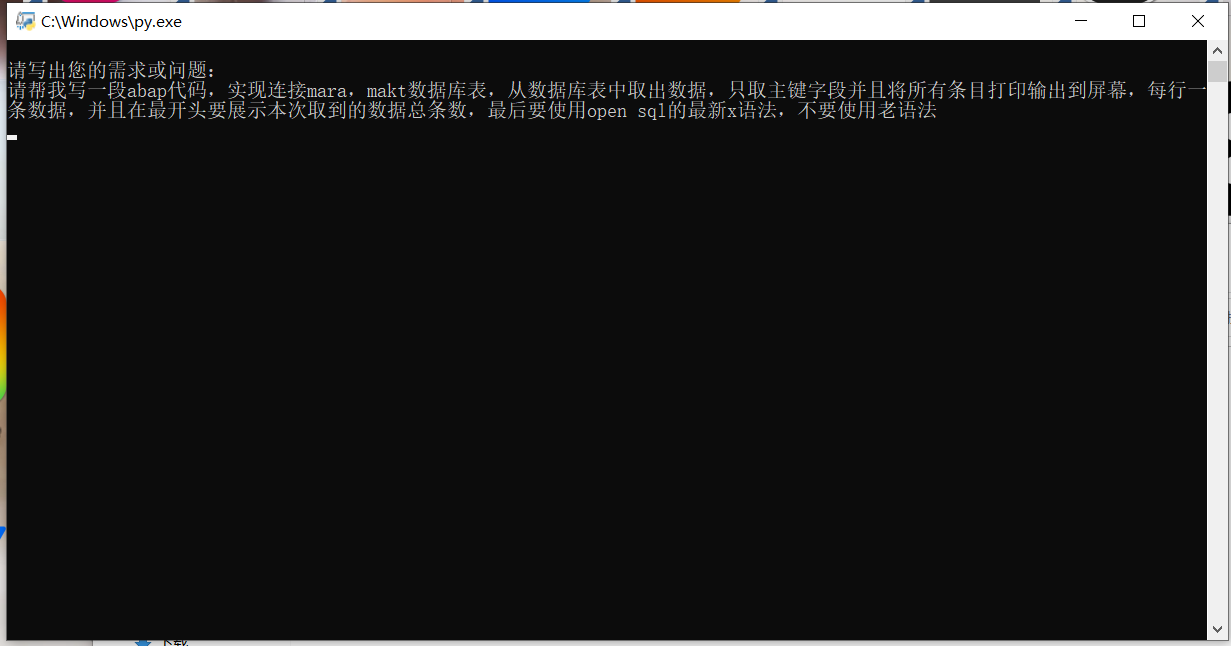
(二)按下回车键,等待运行结果
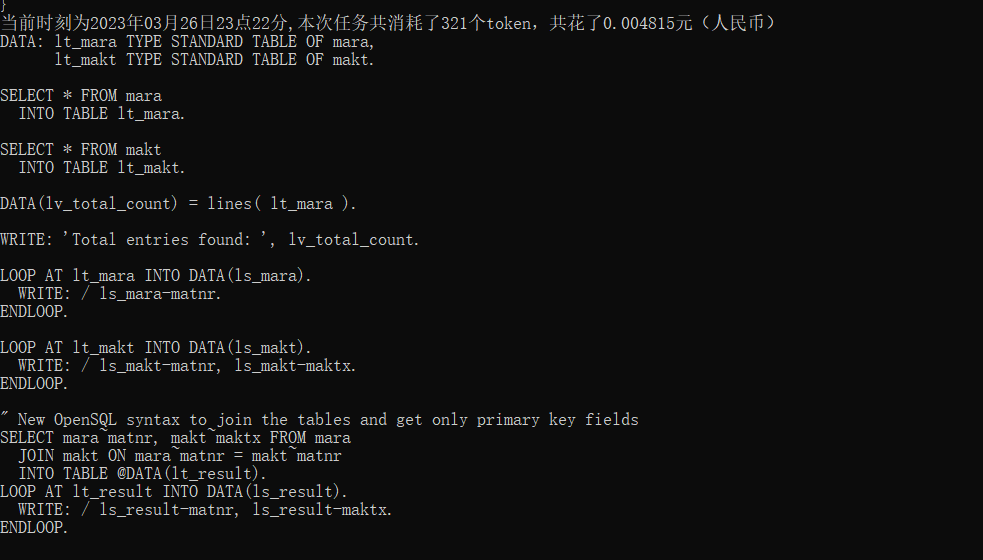
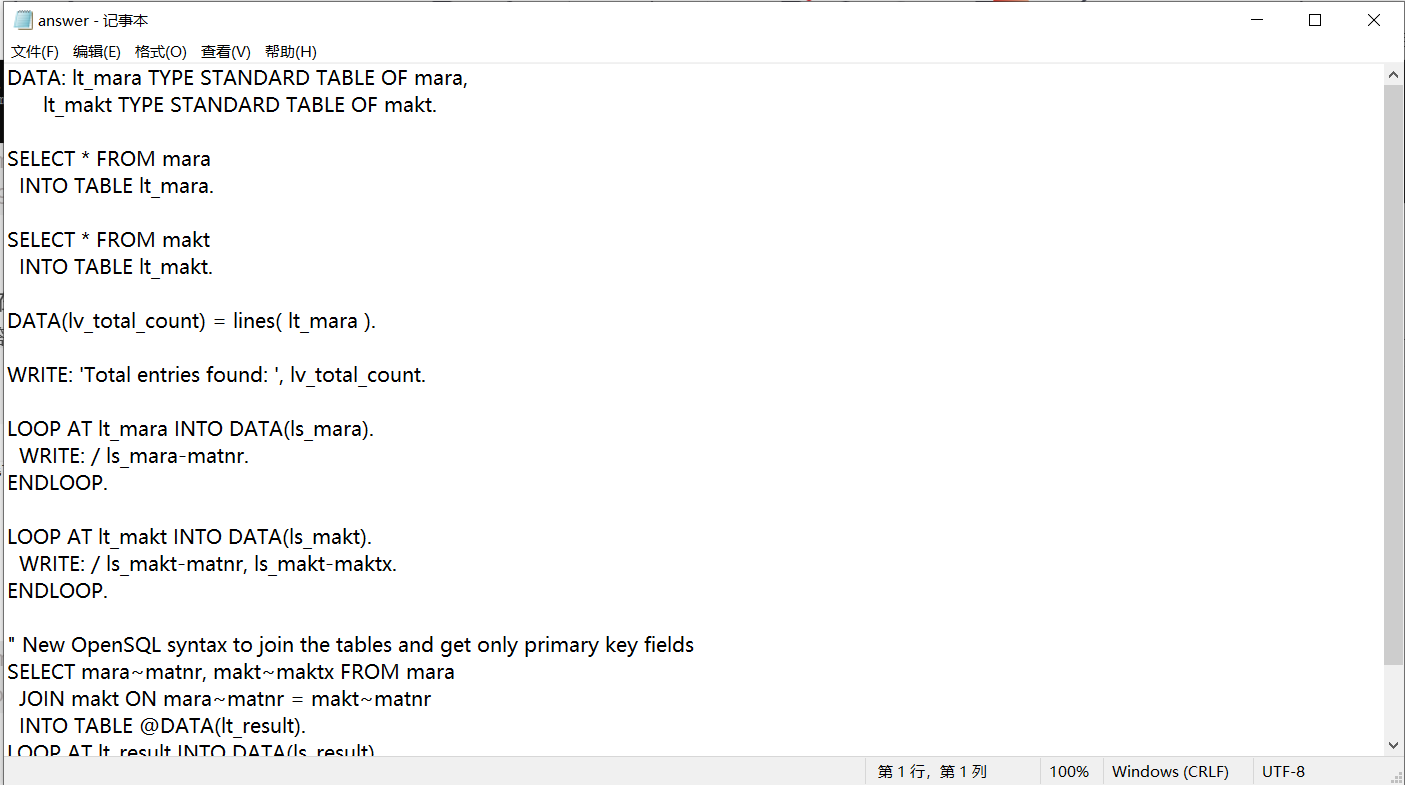
(三)同时还会在同一目录下创建两个文件answer和tokens和费用的合计,分别记录了答案和本次回答问题的费用消耗以及字数!


本文花费大量时间介绍了十分钟学会如何在本地调用API_KEY,希望能帮助到各位小伙伴,码文不易,还望各位大佬们多多支持哦,你们的支持是我最大的动力!

✨ 原 创 不 易 , 还 希 望 各 位 大 佬 支 持 一 下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点 赞 , 你 的 认 可 是 我 创 作 的 动 力 ! \textcolor{9c81c1}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收 藏 , 你 的 青 睐 是 我 努 力 的 方 向 ! \textcolor{ed7976}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评 论 , 你 的 意 见 是 我 进 步 的 财 富 ! \textcolor{98c091}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R