🌈欢迎来到Linux专栏~~进程通信
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort
- 目前状态:大三非科班啃C++中
- 🌍博客主页:张小姐的猫~江湖背景
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给自己的一句鸡汤🤔:
- 🔥真正的大师永远怀着一颗学徒的心
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!

文章目录

进程之间会存在特定的协同工作的场景:
进程间通信的本质就是,让不同的进程看到同一份资源
进程是具有独立性的。虚拟地址空间+页表 保证了进程运行的独立性(进程内核数据结构+进程代码和数据)
进程通信的前提,首先需要让不同的进程看到同一份“内存”(特定的结构组织)
综上,进程间通信的前提就是:由OS参与,提供一份所有通信进程都能看到的公共资源。
进程间通信的发展
什么是管道?
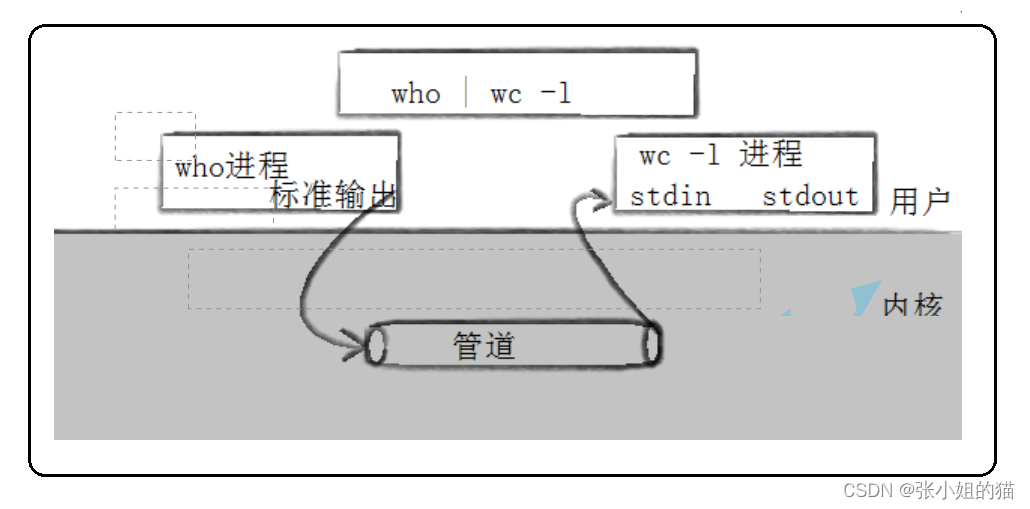
所以计算机领域设计者,设计了一种单向通信的方式 —— 管道
众所周知,父子进程是两个独立进程,父子通信也是进程间通信的一种,基于父子间进程通信就是匿名管道。我们首先要对匿名管道有一个宏观的认识
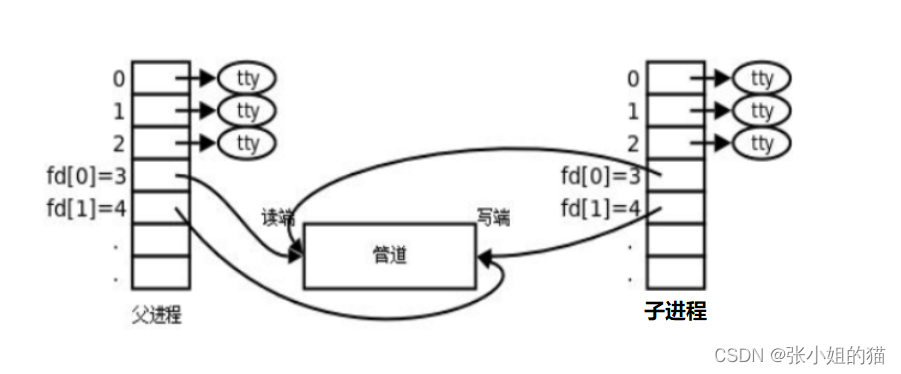
父进程创建子进程,子进程需要以父进程为模板创建自己的files_struct ,而不是与父进程共用;但是struct file这个结构体就不会拷贝,因为打开文件也与创建进程无关(文件的数据不用拷贝)

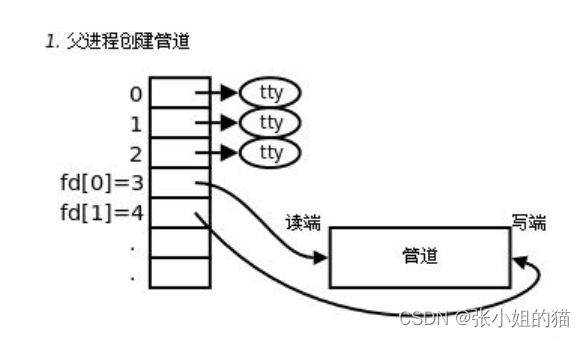
父进程fork创建子进程
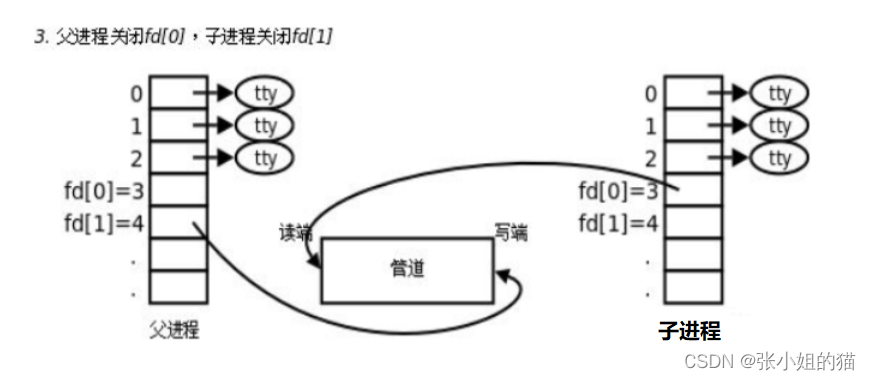
因为管道是一个只能单向通信的信道,父子进程需要关闭对应读写端,至于谁关闭谁,取决于通信方向。
于是,通过子进程继承父进程资源的特性,双方进程看到了同一份资源。
pipe谁调用就让以读写方式打开一个文件(内存级文件)
#include <unistd.h>
int pipe(int pipefd[2]);
pipefd:输出型参数!通过这个参数拿到两个打开的fd数组pipefd用于返回两个指向管道读端和写端的文件描述符:
| 数组元素 | 含义 |
|---|---|
| pipefd[0]~嘴巴 | 管道读端的文件描述符 |
| pipefd[1] ~ 钢笔 | 管道写端的文件描述符 |
此处提取查一下要用到的函数
man2是获得系统(linux内核)调用的用法; man 3 是获得标准库(标准C语言库、glibc)函数的文档//linux中用man可以查哦
#include <unistd.h>
pid_t fork(void);
#include <unistd.h>
int close(int fd);
#include <stdlib.h>
void exit(int status);
下面按照之前讲的原理进行逐一操作:①创建管道 ②父进程创建子进程 ③关闭对应的读写端,形成单向信道
#include <iostream>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <string.h>
#include <assert.h>
using namespace std;
int main()
{
//1.创建管道
int pipefd[2] = {0};
int n = pipe(pipefd); //失败返回-1
assert(n != -1); //只在debug下有效
(void)n; //仅此证明n被使用过
#ifdef DEBUG
cout<< "pipefd[0]" << pipefd[0] << endl; //3
cout<< "pipefd[1]" << pipefd[1] << endl; //4
#endif
//2.创建子进程
pid_t id = fork();
assert(id != -1);
if(id == 0)
{
//子进程
//3. 构建单向通信的信道
//3.1 子进程关闭写端[1]
close(pipefd[1]);
exit(0);
}
//父进程
//父进程关闭读端[0]
close(pipefd[0]);
return 0;
}
在此基础上,我们就要进行通信了,实际上就是对某个文件进行写入,因为管道也是文件,下面提提前查看要用到的函数
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
返回值:
- 返回写入的字节数
- 零表示未写入任何内容,这里意味着对端进程关闭文件描述符
#include <unistd.h>
unsigned int sleep(unsigned int seconds);
简单实现了管道通信的demo版本:
#include <iostream>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <string.h>
#include <assert.h>
#include<sys/types.h>
#include<sys/wait.h>
using namespace std;
int main()
{
//1.创建管道
int pipefd[2] = {0};
int n = pipe(pipefd); //失败返回-1
assert(n != -1); //只在debug下有效
(void)n; //仅此证明n被使用过
#ifdef DEBUG
cout<< "pipefd[0]" << pipefd[0] << endl; //3
cout<< "pipefd[1]" << pipefd[1] << endl; //4
#endif
//2.创建子进程
pid_t id = fork();
assert(id != -1);
if(id == 0)
{
//子进程 - 读
//3. 构建单向通信的信道
//3.1 子进程关闭写端[1]
close(pipefd[1]);
char buffer[1024];
while(1)
{
size_t s = read(pipefd[0], buffer, sizeof(buffer)-1);
if(s > 0)
{
buffer[s] = 0;//因为read是系统调用,没有/0,此处给加上
cout<<"child get a message["<< getpid() << "] 爸爸对你说" << buffer << endl;
}
}
//close(pipefd[0]);
exit(0);
}
//父进程 - 写
//父进程关闭读端[0]
close(pipefd[0]);
string message = "我是父进程,我正在给你发消息";
int count = 0; //计算发送次数
char send_buffer[1024];
while(true)
{
//3.2构建一个变化的字符串
snprintf(send_buffer, sizeof(send_buffer), "%s[%d] : %d",message.c_str(), getpid(), count);
count++;
//3.3写入
write(pipefd[1], send_buffer, strlen(send_buffer));//此处strlen不能+1
//3.4 故意sleep
sleep(1);
}
pid_t ret = waitpid(id, nullptr, 0);
assert(ret != -1);
(void)ret;
return 0;
}
此处有个问题:为什么不定义一个全局的buffer来进行通信呢?
上面的方法就是把数据交给管道,让对方通过管道进行读取
之前父子进程同时向显示器中写入的时候,二者会互斥 —— 缺乏访问控制
而对于管道进行读取的时候,父进程如果写的慢,子进程就会等待读取 —— 这就是说明管道具有访问控制
父进程疯狂的进行写入,子进程隔10秒才读取,子进程会把这10秒内父进程写入的所有数据都一次性的打印出来!
代码如非就是在父进程添加了打印conut,子进程sleep(10),可以自行的在demo代码上添加
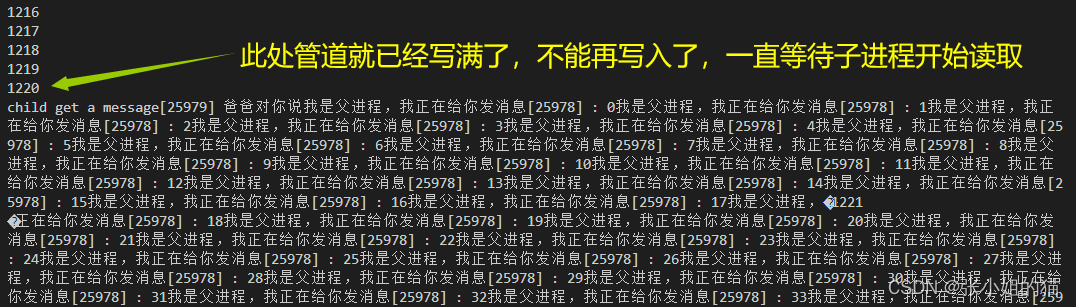
父进程写了1220次,子进程一次就给你读完了,读写之间没有关系,这就叫做流式的服务。
也就是管道是面向字节流的,也就是只有字节的概念,究竟读成什么样也无法保证,甚至可能读出乱码,所以父子进程通信也是需要制定协议的,但这个我们网络再细说。。
管道没有数据的时候,读端必须等待:父进程每隔2秒才进行写入,子进程疯狂的读取

父进程写入10秒,后把写端fd关闭,读端会怎么样?
read会返回0,表示读到了文件结尾,退出读端#include <iostream>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <string.h>
#include <assert.h>
#include<sys/types.h>
#include<sys/wait.h>
using namespace std;
int main()
{
//1.创建管道
int pipefd[2] = {0};
int n = pipe(pipefd); //失败返回-1
assert(n != -1); //只在debug下有效
(void)n; //仅此证明n被使用过
#ifdef DEBUG
cout<< "pipefd[0]" << pipefd[0] << endl; //3
cout<< "pipefd[1]" << pipefd[1] << endl; //4
#endif
//2.创建子进程
pid_t id = fork();
assert(id != -1);
if(id == 0)
{
//子进程 - 读
//3. 构建单向通信的信道
//3.1 子进程关闭写端[1]
close(pipefd[1]);
char buffer[1024*8];
while(1)
{
//sleep(10);//20秒读一次
//写入的一方,fd没有关闭,如果有数据就读,没有数据就等
//写入的一方,fd关闭了,读取的一方,read会返回0,表示读到了文件结尾
size_t s = read(pipefd[0], buffer, sizeof(buffer)-1);
if(s > 0)
{
buffer[s] = 0;//因为read是系统调用,没有/0,此处给加上
cout<<"child get a message["<< getpid() << "] 爸爸对你说" << buffer << endl;
}
else if (s == 0)
{
cout << "write quit(father), me quit!!!" <<endl;
break;
}
}
//close(pipefd[0]);
exit(0);
}
//父进程 - 写
//父进程关闭读端[0]
close(pipefd[0]);
string message = "我是父进程,我正在给你发消息";
int count = 0; //计算发送次数
char send_buffer[1024*8];
while(true)
{
//3.2构建一个变化的字符串
snprintf(send_buffer, sizeof(send_buffer), "%s[%d] : %d",message.c_str(), getpid(), count);
count++;
//3.3写入
write(pipefd[1], send_buffer, strlen(send_buffer));//此处strlen不能+1
//3.4 故意sleep
sleep(1);
cout<< count <<endl;
if(count == 5)
{
cout<< "父进程写端退出" << endl;
break;
}
}
close(pipefd[1]);//关闭读端
pid_t ret = waitpid(id, nullptr, 0);
assert(ret != -1);
(void)ret;
return 0;
}
运行结果如下:

读端关闭,写端继续写入,直到OS终止写进程
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if (pipe(fd) < 0){ //使用pipe创建匿名管道
perror("pipe");
return 1;
}
pid_t id = fork(); //使用fork创建子进程
if (id == 0){
//child
close(fd[0]); //子进程关闭读端
//子进程向管道写入数据
const char* msg = "hello father, I am child...";
int count = 10;
while (count--){
write(fd[1], msg, strlen(msg));
sleep(1);
}
close(fd[1]); //子进程写入完毕,关闭文件
exit(0);
}
//father
close(fd[1]); //父进程关闭写端
close(fd[0]); //父进程直接关闭读端(导致子进程被操作系统杀掉)
int status = 0;
waitpid(id, &status, 0);
printf("child get signal:%d\n", status & 0x7F); //打印子进程收到的信号
return 0;
}
运行结果显示,子进程退出时收到的是13号信号

通过kill -l命令可以查看13对应的具体信号

由此可知,当发生情况四时,操作系统向子进程发送的是SIGPIPE信号将子进程终止的。
🐋总结上述的4中场景:
read会返回0,表示读到了文件结尾,退出读端🧐由上总结出匿名管道的5个特点 ——
管道的容量是有限的,如果管道已满,那么写端将阻塞或失败,那么管道的最大容量是多少呢?
ps:原子性:要么做了,要么不做,没有中间状态
方法1 :man手册查询

然后我们可以使用uname -r命令,查看自己使用的Linux版本

我使用的是Linux 2.6.11之后的版本,因此管道的最大容量是65536字节
方法二:自行测试
也就是如果读端一直不读取,写端又不断的写入,当管道被写满后,写端进程就会被挂起。据此,我们可以写出以下代码来测试管道的最大容量。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if (pipe(fd) < 0){ //使用pipe创建匿名管道
perror("pipe");
return 1;
}
pid_t id = fork(); //使用fork创建子进程
if (id == 0){
//child
close(fd[0]); //子进程关闭读端
char c = 'a';
int count = 0;
//子进程一直进行写入,一次写入一个字节
while (1){
write(fd[1], &c, 1);
count++;
printf("%d\n", count); //打印当前写入的字节数
}
close(fd[1]);
exit(0);
}
//father
close(fd[1]); //父进程关闭写端
//父进程不进行读取
waitpid(id, NULL, 0);
close(fd[0]);
return 0;
}
写端进程最多写65536字节的数据就被操作系统挂起了,也就是说,我当前Linux版本中管道的最大容量是65536字节

为了解决匿名管道只能在父子之间通信,我们引入命名管道,可以在任意不相关进程进行通信
多个进程打开同一个文件,OS只会创建一个struct_file
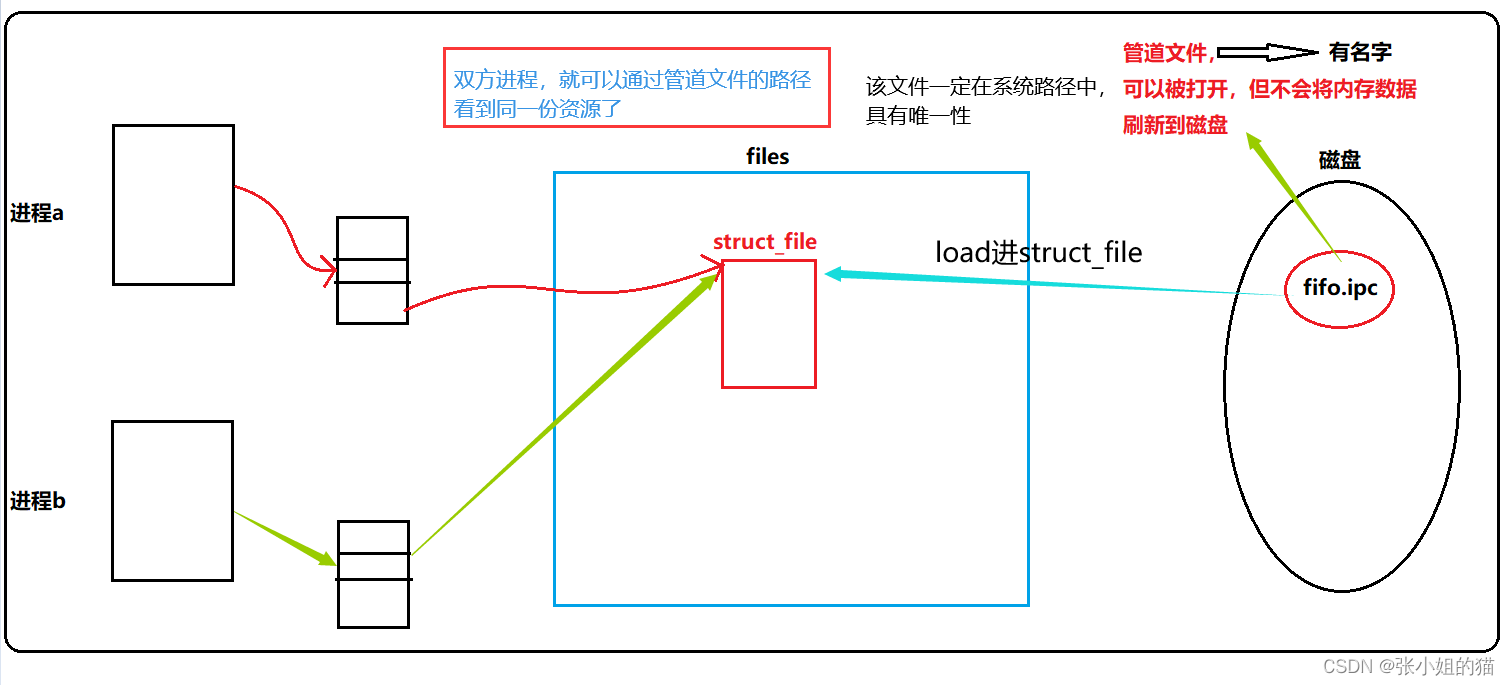
命名管道就是一种特殊类型的文件(可以被打开,但不会将数据刷新进磁盘),两个进程通过命名管道的文件名打开同一个管道文件,此时这两个进程也就看到了同一份资源,进而就可以进行通信了。
命名管道就是通过唯一路径/文件名的方式定位唯一磁盘文件的
ps:命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像(所以有名字),但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
💛 make FIFOs 在命令行上创建命名管道
mkfifo (named pipes)
FIFO:First In First Out 队列呀
来个小实验:
命令行上执行的命令echo和cat都是进程,所以这就是通过管道文件进行的进程间通信 ——


💛 那么如何用代码实现命名管道进程间通信的呢?
//查手册:man 3 mkfifo
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
pathname:管道文件路径mode:管道文件权限我touch了server.c和client.c,最终希望在server和client两个进程之间相互通信,先写一个Makefile ——
.PHONY:all
all:client server
client:client.cxx
g++ -o $@ $^ -std=c++11
server:server.cxx
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f client server
.PHONY: all,并添加依赖关系comm.h
我们创建一个共用的头文件,这只是为了两个程序能有看到同一个资源的能力了
#ifndef _COMM_H_ //能避免头文件的重定义
#define _COMM_H_
//hpp和.h的区别:.h里面只有声明,没有实现,而.hpp里声明实现都有,后者可以减少.cpp的数量
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
using namespace std;
#define MODE 0666
#define SIZE 128
string ipcPath = "./fifo.ipc";
#endif
server.c
#include "comm.hpp"
int main()
{
//1.创建管道文件
if(mkfifo(ipcPath.c_str(), MODE) < 0)
{
perror("mkfifo");
exit(1);
}
//2. 正常的文件操作
int fd = open(ipcPath.c_str(), O_RDONLY);
if(fd < 0)
{
perror("open");
exit(2);
}
//3.编写正常的通信代码
char buffer[SIZE];
while(1)
{
memset(buffer, '\0', sizeof(buffer));
ssize_t s = read(fd, buffer, sizeof(buffer)-1);
if(s > 0)
{
cout << "client say >" << buffer << endl;
}
else if(s == 0)
{
//说明写端关闭了
cerr << "read end of file, client quit, server quit too" <<endl;
}
else
{
//读取失败
perror("read");
break;
}
}
//4. 关闭文件
close(fd);
unlink(ipcPath.c_str());//通信完毕,删除文件
return 0;
}
client.c
此时不需要再创建命名管道,只需要获取已打开的命名管道文件
#include "comm.hpp"
int main()
{
//不需要创建fifo,只需获取即可
int fd = open(ipcPath.c_str(), O_WRONLY);
if(fd < 0)
{
perror("open");
exit(1);
}
//2.ipc通信
string buffer;
while(1)
{
cout << "Place Enter Message:";
std::getline(std::cin, buffer);
write(fd, buffer.c_str(), sizeof(buffer));
}
//3.关闭
close(fd);
return 0;
}
效果展示:
一定要先运行服务端server创建命名管道,再运行客户端,实现了不相关进程通信 ——
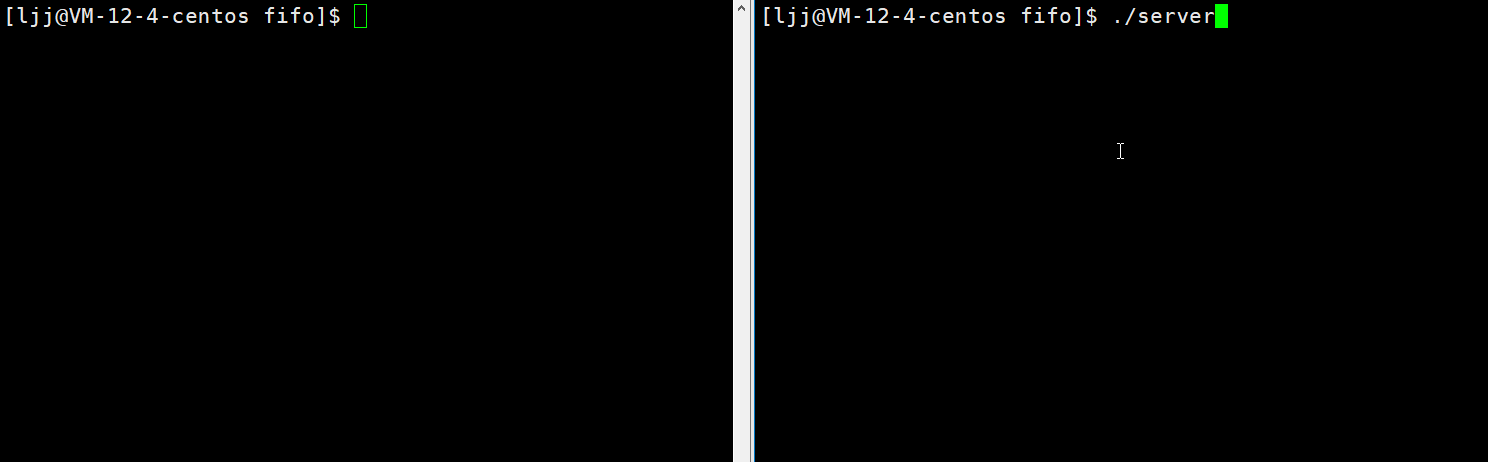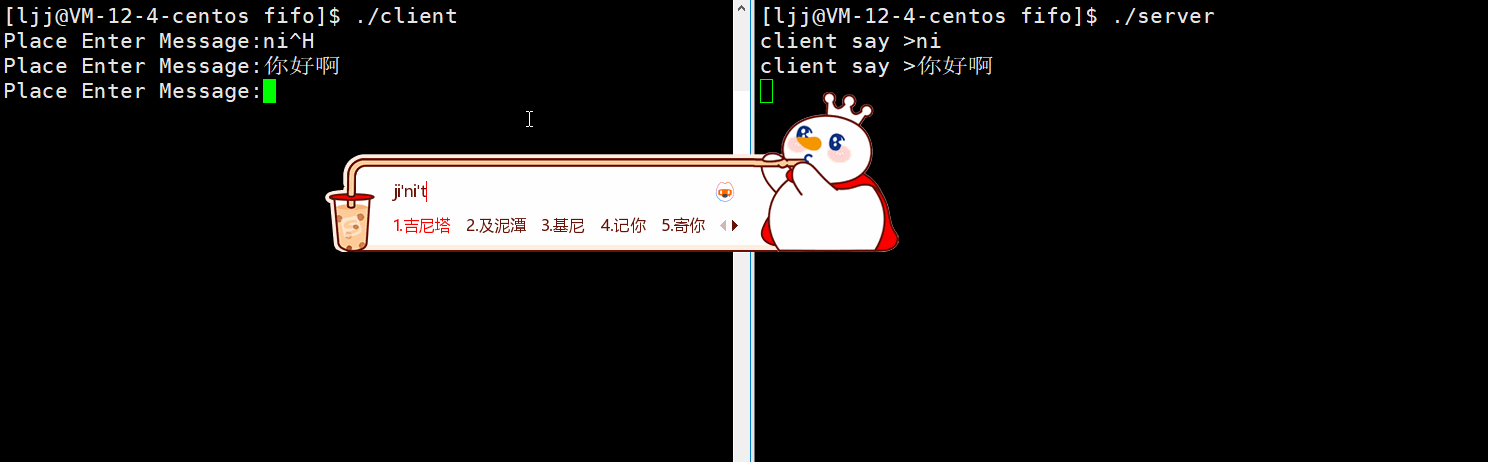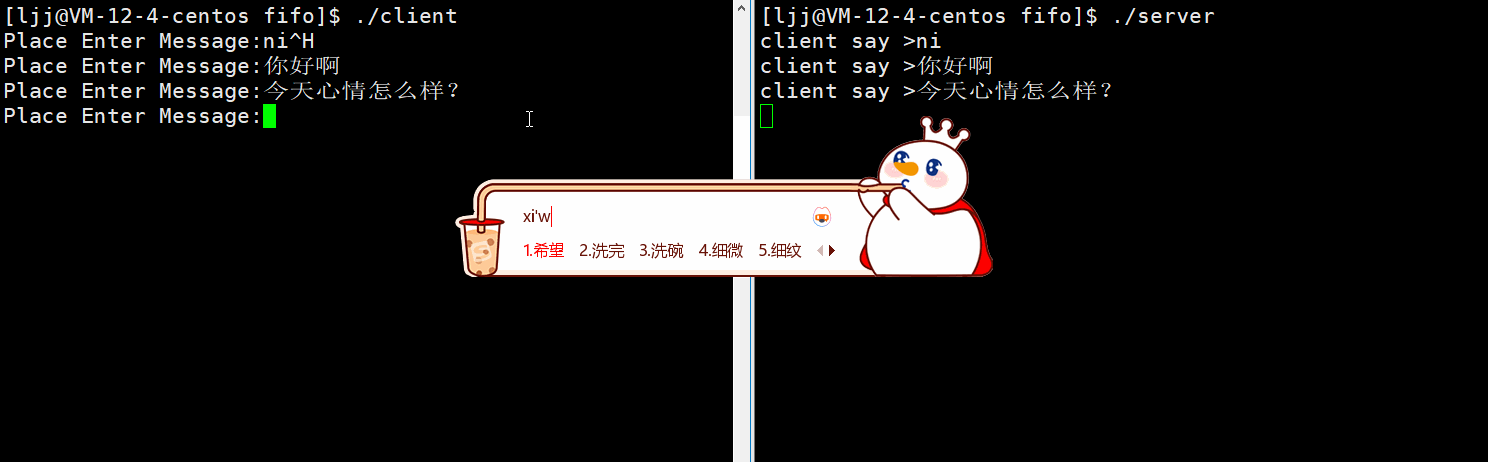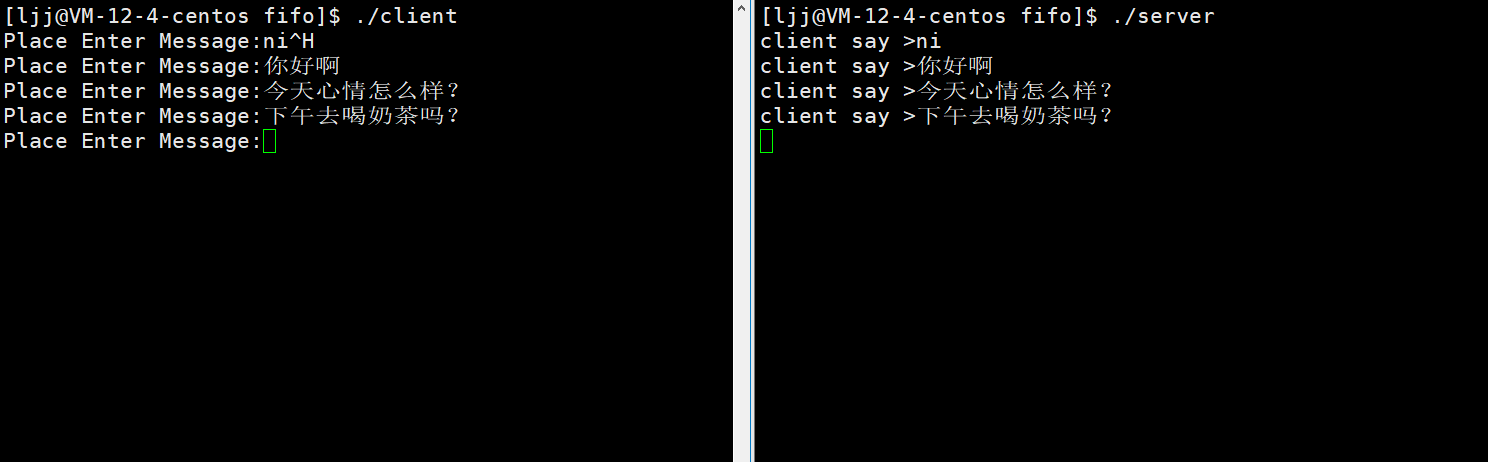
如果我想让多个子进程来执行打印任务
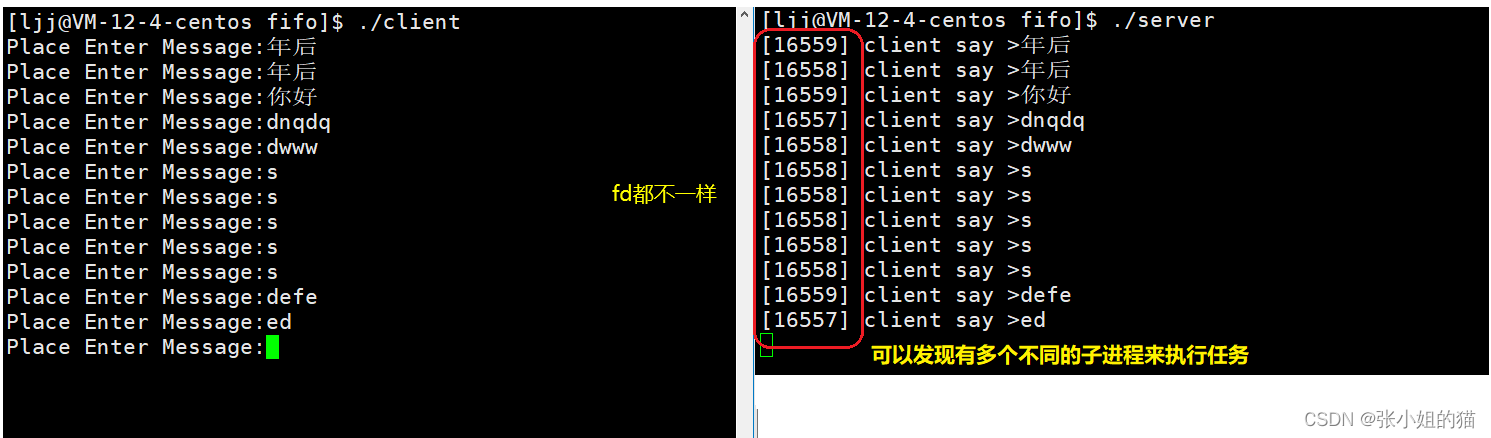
当然我们就要调整一下server.c的业务逻辑:
#include "comm.hpp"
#include <sys/wait.h>
static void getMessage(int fd)
{
//3.编写正常的通信代码
char buffer[SIZE];
while(1)
{
memset(buffer, '\0', sizeof(buffer));
ssize_t s = read(fd, buffer, sizeof(buffer)-1);
if(s > 0)
{
cout << "[" << getpid() << "] " << "client say >" << buffer << endl;
}
else if(s == 0)
{
//说明写端关闭了
cerr << "[" << getpid() << "] " << "read end of file, client quit, server quit too" <<endl;
}
else
{
//读取失败
perror("read");
break;
}
}
}
int main()
{
//1.创建管道文件
if(mkfifo(ipcPath.c_str(), MODE) < 0)
{
perror("mkfifo");
exit(1);
}
//log("创建管道文件成功", Debug) << "step 1" <<endl;
//2. 正常的文件操作
int fd = open(ipcPath.c_str(), O_RDONLY);
if(fd < 0)
{
perror("open");
exit(2);
}
//log("打开管道文件成功", Debug) << "step 2" <<endl;
int nums = 3;
for(int i = 0; i < nums; i++)
{
pid_t id = fork();
if(id==0)
{
//子进程
getMessage(fd);
exit(2);
}
}
for(int i = 0; i < nums; i++)
{
waitpid(-1, nullptr, 0);
}
//4. 关闭文件
close(fd);
//log("关闭管道文件成功", Debug) << "step 3" <<endl;
unlink(ipcPath.c_str());//通信完毕,删除文件
//log("删除管道文件成功", Debug) << "step 4" <<endl;
return 0;
}
为什么pipe叫做匿名管道和和fifo叫做命名管道?
下面我们要学习System V标准,是在同一主机内的进程间通信方案,是站在OS层面,专门为进程间通信设计的方案。
进程通信的本质是先让不同进程看到同一份资源,System V提供了这三个主流方案 ——
基于共享内存进行进程间通信原理 ——
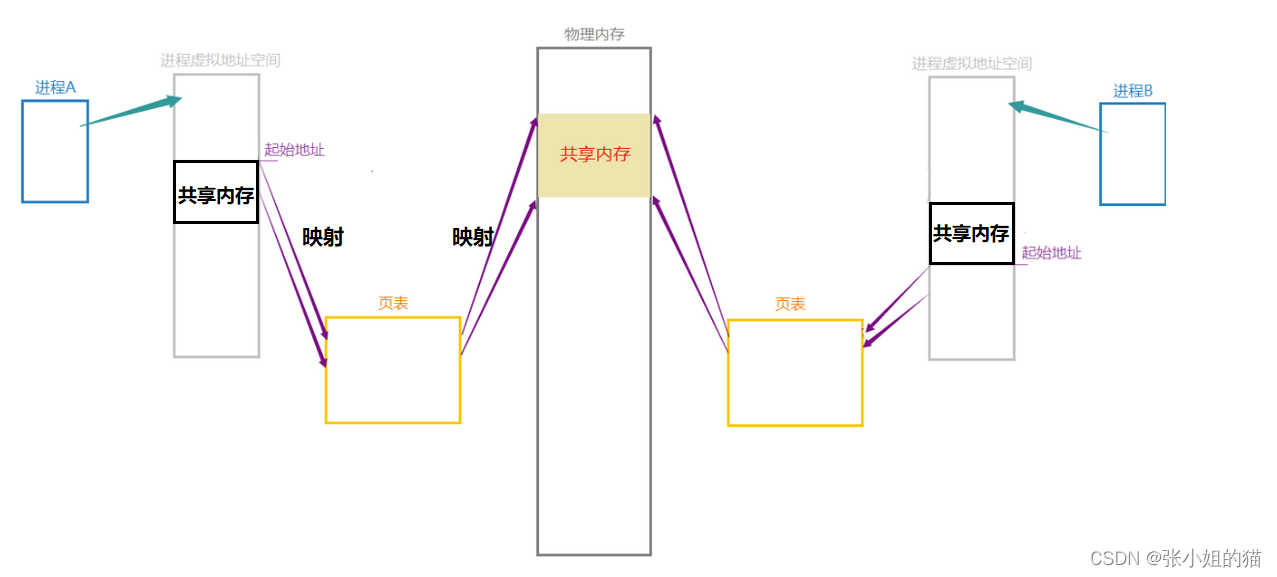
共享内存提供者是操作系统OS,那么操作系统要不要管理共享内存呢? -> 先描述再组织
共享内存 = 共享内存块 + 对应的共享内存的内核数据结构(来描述其属性)
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
参数:
key:为了使不同进程看到同一段共享内存,即让不同进程拿到同一个ID,需要由用户自己设定,但如何设定的与众不同好难啊,就要借助下面这个函数。
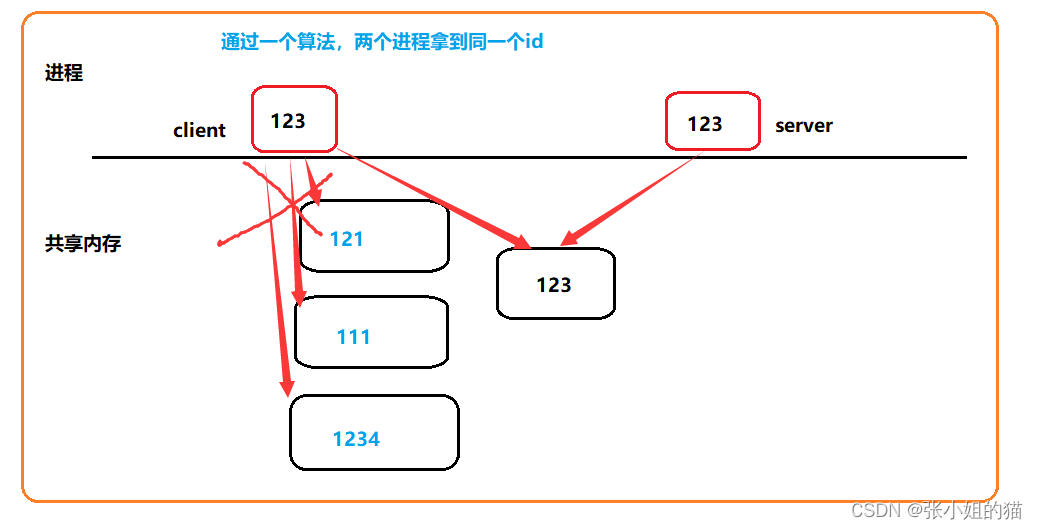 所以怎么样保证两个进程拿到同一个
所以怎么样保证两个进程拿到同一个key值呢?
#include <sys/types.h>
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
pathname:自定义路径名proj_id:自定义项目IDszie:共享内存的大小,建议是4KB的整数倍,因为共享内存在内核中申请的基本单位是页(内存页)。
shmflg:标记位,这一看就是宏,都是只有一个比特位是1且相互不重复的数据,这样|在一起,就能传递多个标志位
IPC_CREAT:如果单独使用IPC_CREAT或者flg为0,如果创建共享内存时,底层已经存在,获取之;如果不存在,就创建之IPC_EXCL:单独使用没有意义,通常要搭配起来IPC_CREAT | IPC_EXCL,如果底层不存在,就创建,并返回;如果底层存在就出错返回。这样的意义在于 如果调用成功,得到的一定是一个全新的共享内存。返回值:成功后,将返回有效的共享内存标识符。失败了,返回-1,并设置errno错误码。
手动查看与手动删除
ipcs -m 查看ipc资源,不带选项默认查看消息队列(-q)、共享内存(-m)、信号量(-s)
ipcrm -m + shmid //删除共享内存
system V IPC资源,生命周期随内核!所以我们要手动 / 自动删除,那怎么样自动删除呢?
💛 控制共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数:
cmd:设置IPC_RMID就行,IPC_RMID:即便是有进程和当下的shm挂接,依旧删除共享内存(强大)buf:这就是描述共享内存的数据结构啊!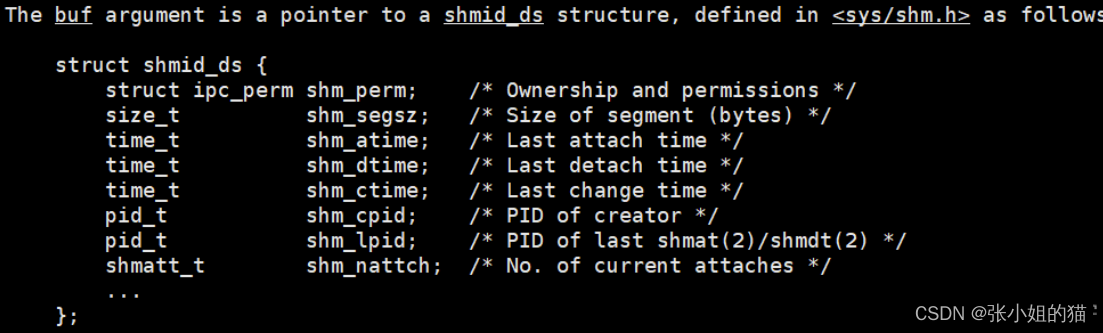
attach 挂接 ——
#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
shmaddr:挂接到什么位置,我们也不知道,给NULL,让操作系统来设置shmflg: 给0最重要的是返回值:
detach 去关联 ——
int shmdt(const void *shmaddr);
shmaddr:shmat返回的地址注意:去关联,不是释放共性内存,而是取消当前进程和共享内存的关系,本质是去掉进程和物理内存构建映射关系的页表项去掉
返回值:成功返回0,失败返回-1
只有创建的时候用key,大部分用户访问共享内存,都用的是shmid(用户层)
comm.h
#pragma one
#include <iostream>
#include <cstdio>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include "log.hpp"
using namespace std;//不推荐
#define PATH_NAME "/home/ljj"
#define PROJ_ID 0x66
server.c
创建公共的key值
创建共享内存 - 建议创建一个全新的共享内存:因为是通信的发起者
带选项IPC_CREAT | IPC_EXCL若和系统中已经存在的ID冲突,则出错返回;
注意到其中权限perm是0,那也可以设置一下
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666);

将指定的共享内存,挂接到自己的地址空间上
将指定的共享内存,从自己的地址空间去关联
删除共享内存
#include "comm.hpp"
string TransToHex(key_t k)
{
char buffer[32];
snprintf(buffer, sizeof(buffer), "0x%x", k);
return buffer;
}
int main()
{
//1.创建公共的key值
key_t k = ftok(PATH_NAME, PROJ_ID);
assert(k != -1);
Log("create key done", Debug) << "server key : " << TransToHex(k) << endl;
//2. 创建共享内存 - 建议创建一个全新的共享内存:因为是通信的发起者
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);
if(shmid == -1)
{
perror("shmget");
exit(1);
}
Log("creat shm done", Debug) << "shmid : " << shmid << endl;
sleep(10);
//3.将指定的共享内存,挂接到自己的地址空间上
char *shmaddr = (char*)shmat(shmid, nullptr, 0);
Log("attach shm done", Debug) << "shmid : " << shmid << endl;
sleep(10);
//这里就是通信的代码
//4.将指定的共享内存,从自己的地址空间去关联
int n = shmdt(shmaddr);
assert(n != -1);
(void)n;
Log("detach shm done", Debug) << "shmid : " << shmid << endl;
sleep(10);
//5.删除共享内存
n = shmctl(shmid, IPC_RMID, nullptr);
assert(n != -1);
(void)n;
Log("delete shm done", Debug) << "shmid : " << shmid << endl;
return 0;
}
关于申请共享内存的大小size,我们说建议是4KB的整数倍,因为共享内存在内核中申请的基本单位是页(内存页),4KB。如果我申请4097Byte大小的空间,内核会向上取整给我4096* 2Byte,诶?那我监视到的↑怎么还是4097啊!虽然在底层申请到的是4096*2,但不会多给你,这样也可能引起错误~
client.c
#include "comm.hpp"
int main()
{
key_t k = ftok(PATH_NAME, PROJ_ID);
if(k < 0)
{
Log("create key failed", Error) << "client key : " << k << endl;
exit(1);
}
Log("create key done", Debug) << "client key : " << k << endl;
//获取共享内存
int shmid = shmget(k, SHM_SIZE, IPC_CREAT);
if(shmid < 0)
{
Log("create shm failed", Error) << "client key : " << k << endl;
exit(2);
}
Log("attach shm success", Error) << "client key : " << k << endl;
sleep(10);
//挂接地址
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == nullptr)
{
Log("attach shm failed", Error) << "client key : " << k << endl;
exit(3);
}
Log("attach shm success", Error) << "client key : " << k << endl;
sleep(10);
//使用
//去关联
int n = shmdt(shmaddr);
assert(n != -1);
Log("datach shm success", Error) << "client key : " << k << endl;
sleep(10);
//你只管用,不需要删除共享内存
return 0;
}
效果展示:
写一个命令行脚本来监视共享内存 ——
while :; do ipcs -m; echo "_________________________________________________________________"; sleep 1; done
注意观察nattch这个参数的变化:0->1->2->1->0

上面的框架都搭建好了之后,接下来就是通信部分:
1️⃣客户端不断向共享内存写入数据:
//client将共享内存看成一个char类型的buffer
char a = 'a';
for(; a <= 'z'; a++)
{
//每一次都想共享内存shmaddr的起始地址
snprintf(shmaddr, SHM_SIZE - 1,\
"hello server, 我是其他进程, 我的pid: %d, inc: %c\n",\
getpid(), a);
sleep(2);
}
2️⃣服务端不断读取共享内存当中的数据并输出:
//将共享内存当成一个大字符串
for(;;)
{
printf("%s\n", shmaddr);
sleep(1);
}
结果如下:

ps:我们发现即使我们没有向server端发消息,server也是不断的在读取信息的
共享内存是所有进程间通信方式中最快的一种通信方式。
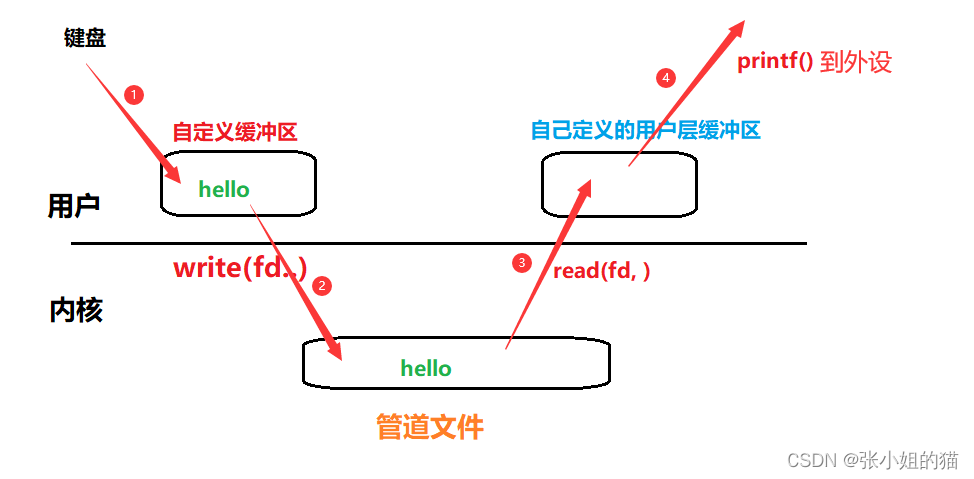
将一个文件从一个进程传输到另一个进程需要进行四次拷贝操作:
我们再来看看共享内存通信:

键盘写入shm,另一端可以直接获取到,哪里还需要什么拷贝?最多两次拷贝(键盘输入一次,输出到外设一次)
共享内存的区域是在OS内核?还是在用户空间?
其中文本、初始化数据区、未初始化数据区、堆、栈、环境变量、命令行参数、再 往上就是1G的OS内核,其中剩余3G都是用户自己支配的
用户空间:不用经过系统调用,直接进行访问!
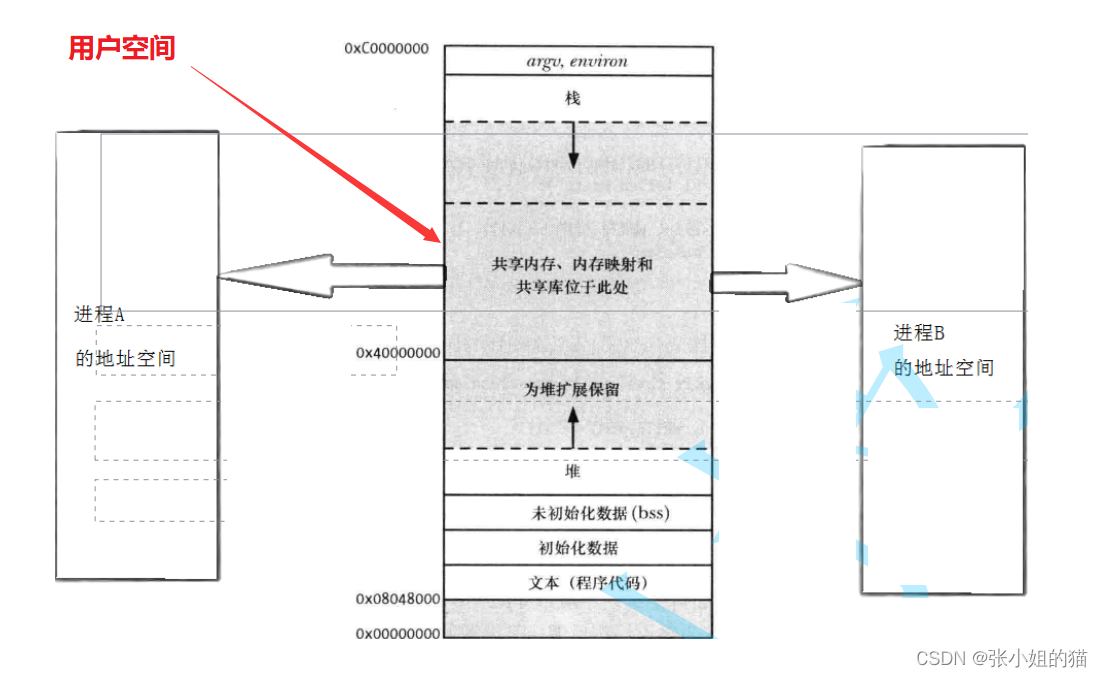
那为什么之前将的pipe和fifo都要通过read、write进行通信,为什么呢?
因为管道双方看到的资源都属于内核级的文件,我们无权直接进行访问,必须调用系统接口
严重过时:接口与文件不对应
创建消息队列,与创建共享内存极其相似:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgget(key_t key, int msgflg);
删除消息队列:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
我们可以通过key找到同一个共享内存。
我们发现共享内存、消息队列、信号量的 ——
struct ipc_perm是完全一致的!我们由shmid申请到的都是01234… 大胆推测,在内核中,所有的ipc资源都是通过数组组织起来的。可是描述它们的结构体类型并不相同啊?但是~ System V标准的IPC资源,xxxid_ds结构体的第一个成员都是ipc_perm都是一样的。
简单认识一下信号量
多个执行流,互相运行的时候互相干扰,我们不加保护的访问了同样的资源(临界资源),在非临界区多个执行流互相是不影响的
信号量本质是一个计数器,类似int count,用来衡量临界资源中的资源数目(好比电影院里面的座位,我们需要买票进入)

什么是临界资源?
我们把多个进程(执行流)看到的公共资源 叫做临界资源
什么是临界区?
我们把自己的进程,访问临界资源的代码 —— 临界区
什么是原子性?
一件事儿,要么不做,要么就做完,没有中间态。
什么是互斥?
在任意一个时刻,只能允许一个执行流进入临界区
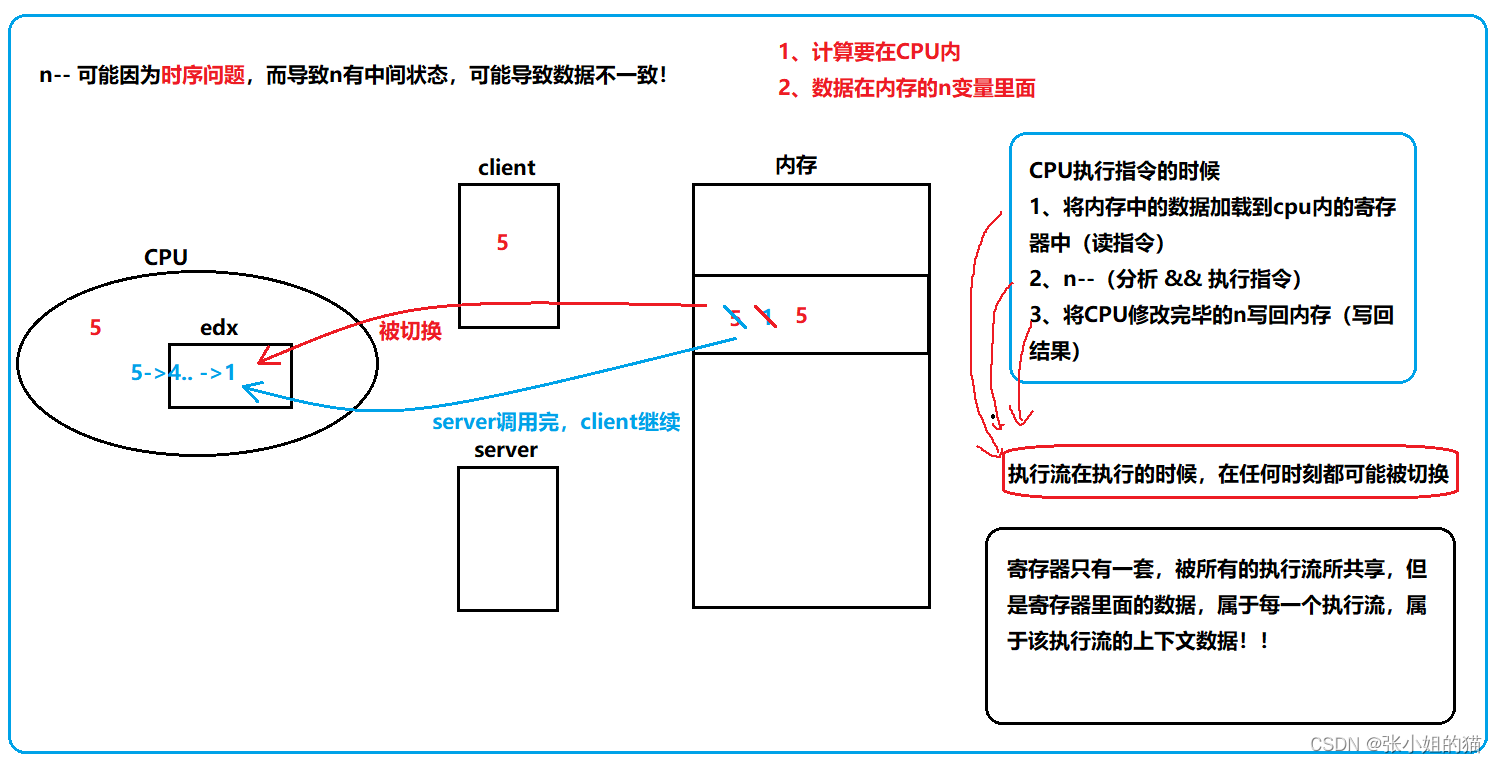
n--:可能因为时序问题,而导致n有中间状态,导致数据不一致
n--操作只有一行汇编,该操作是原子的!!做总结: 信号量计数器
应该是我写过最长的一篇博客了

假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我没有理解以下行为(另请参阅inthisSOthread):defdef_testputs'def_test.in'yieldifblock_given?puts'def_test.out'enddef_testdoputs'def_testok'endblock_test=procdo|&block|puts'block_test.in'block.callifblockputs'block_test.out'endblock_test.calldoputs'block_test'endproc_test=procdoputs'proc_test.in'yieldifblock_gi
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
