专栏: 数据结构和算法
这不是马上要蓝桥杯了嘛,我就开始刷蓝桥杯的真题和模拟题( 点这(填空)| 点这(编程))
发现出现了很多涉及矩阵的的题,其中前缀和差分很重要,但每次做题又容易写错或理解不当。
因此我要在这认真的总结一下这部分知识点,并搭配图解和习题从本质上深刻的理解它们。
在高中的时候我们肯定都学了数列吧,还有数列求和。那这个公式就一点不陌生了。
数列的前n项和Sn 减去 数列的前n-1项和Sn-1等于它的通项公式,而将这种方式运用在编程中就能快速算出每一项对应的前缀和。

一般为了方便起见数组下标都从1开始,上面动态图掩饰主要是便于大家理解。
将上述图解用代码实现:
for (int i = 1 ; i <= n ; i++)
{
cin>>nums[i];
presum[i] = presum[i-1] + nums[i]; //求前缀和
}光说,又不刷题……
大家看一下这道题(就知道这东西是有多么方便了)
输入一个长度为 n 的整数序列。
接下来再输入 m 个询问,每个询问输入一对 l , r。
对于每个询问,输出原序列中从第 l 个数到第 r 个数的和。
输入格式
第一行包含两个整数 n 和 m。
第二行包含 n 个整数,表示整数数列。
接下来 m 行,每行包含两个整数 l 和 r,表示一个询问的区间范围。
输出格式
共 m 行,每行输出一个询问的结果。
数据范围
1 ≤ l ≤ r ≤ n
1 ≤ n , m ≤ 100000
−1000 ≤ 数列中元素的值 ≤ 1000
输入样例:
5 3
2 1 3 6 4
1 2
1 3
2 4
输出样例:
3
6
10
这道题如果你不会这个方法,你多半会选择对于每一次的查询然后去遍历一遍[l , r] 求和。
那多浪费时间啊,这里以后就用这个方法就行了~(超大声)
#include <iostream>
using namespace std;
const int N = 1e5+10;
int nums[N] , presum[N] , n , m , l , r;
int main()
{
cin>>n>>m;
for (int i = 1 ; i <= n ; ++i)
{
cin>>nums[i];
presum[i] = presum[i-1] + nums[i];
}
while(m--)
{
cin>>l>>r;
cout<<presum[r] - presum[l-1]<<endl; //这就算出来了,多爽啊~
}
return 0;
}上述presum[ l - 1 ] 处注意啊,别写成presum[ l ] 了。
二维前缀可谓是本节的重中之重,且一定要理解性的掌握~

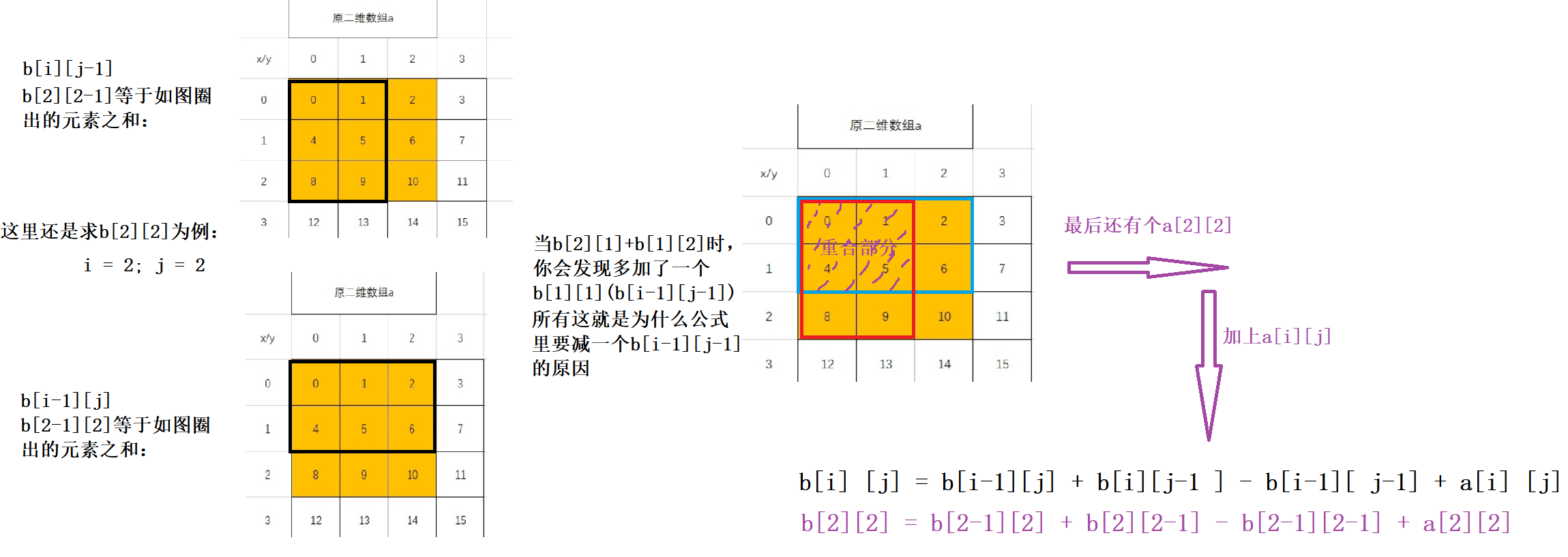
这里我给出一张原二维数组a ,和二维前缀和数组b ,你能看出b它是怎么得来的嘛?(基于一维前缀)
这里以b[2][2] ==45 为例,它就是图中原二维数组a 涂色的部分的数值之和。
你会想这多容易啊,哈哈,但是如果我给你如图a[][]数组让你用代码去构造如图b[][]的二维前缀和数组,你能有什么快捷的方法嘛?
难道你要选择对于求每一个二位前缀和的值都用两个循环!!!!
天啊~,你可以先冷静下来,想一想,一维前缀和s[ i ] = s[ i-1 ] +a[ i ] ; 你会发现对于每一个前缀和都可以利用到它的前一个前缀和 ,然后只需要加上这一项的原数组值就完事了,一个循环就搞定了~ ,那这里的二维前缀和不也是异曲同工之妙嘛!!
这里我直接给出公式,然后你在结合图解理解一下~
b[i] [j] = b[i-1][j] + b[i][j-1 ] - b[i-1][ j-1] + a[i] [j]
上述图解是从数组0开始的,只是为了帮助大家理解,在以后的做题中,要从数组下标1开始赋值和运算,这会很方便的。
好了,既然都学到了二维前缀和了,我们再随其自然把求子矩阵和讲一下。
子矩阵和:给你二维数组中两个坐标 (x1 , y1)和 (x2 , y2),以它们作为一个子矩阵的左上角坐标和右下角坐标,求所围成的矩阵中所有元素之和。
对于新知识没有思路,先别慌!!(暴力肯定谁都会,这里强调的是快捷的方法)
你可以先和已经学过的类似的知识做一下对比,说不定就有思路勒~ ,就像一维前缀推导二维前缀一样,这里也可以试着尝试推导一下公式。
指引:你会发现,之前我们就用一维前缀很快的求出来了,一维数组对应的区间之间的所有元素之和(只是这个比较容易理解),那这里也是不是可以用二维前缀和求子矩阵和呢?
我的答案是:Yes , 方向对了,你离成功就快了,这里的方法可以对比求二维前缀和的思想,很相似的~
这里我先把公式给出来,然后你再根据图解理解一下。
Sum(之矩阵和) = b[x2][y2] - b[x2][y1- 1] - b[x1 - 1][y2] + b[x1 - 1][y1 - 1]

好了,我这里给出一道模板题( 就是用我上面讲的方法 ),来练一下手吧~
输入一个 n 行 m 列的整数矩阵,再输入 q 个询问,每个询问包含四个整数 x1,y1,x2,y2,表示一个子矩阵的左上角坐标和右下角坐标。
对于每个询问输出子矩阵中所有数的和。
输入格式
第一行包含三个整数 n,m,q 。
接下来 n 行,每行包含 m 个整数,表示整数矩阵。
接下来 q 行,每行包含四个整数 x1,y1,x2,y2,表示一组询问。
输出格式
共 q 行,每行输出一个询问的结果。
数据范围
1≤ n, m ≤ 1000
1 ≤ q ≤ 200000
1 ≤ x1 ≤ x2 ≤ n
1≤ y1 ≤ y2 ≤ m
−1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 7 2 4
3 6 2 8
2 1 2 3
1 1 2 2
2 1 3 4
1 3 3 4
输出样例:
17
27
21
#include <iostream>
using namespace std;
const int N=1001;
int a[N][N], b[N][N], n, m, q, x1, x2, y1, y2;
int main()
{
scanf("%d%d%d",&n, &m, &q);
for (int i = 1 ; i <= n ; i++){
for (int j = 1 ; j <= m ; j++){
scanf("%d", &a[i][j]);
b[i][j] = b[i-1][j] + b[i][j-1] - b[i-1][j-1] + a[i][j];//求二维前缀和
}
}
while(q--){
scanf("%d%d%d%d", &x1, &y1, &x2, &y2);
printf("%d\n", b[x2][y2] - b[x1 - 1][y2] - b[x2][y1 - 1] + b[x1 - 1][y1 - 1]);//直接就来了,多方便啊,哈哈
}
return 0;
}
类似于数学中的求导和积分,差分可以看成前缀和的逆运算。
对比一维前缀:我们通过presum[i] = presum[i-1] + nums[i] 来求nums[i] 的一维前缀和数组presum[i] , 而我们要研究的一维差分就是通过presum[i]数组来重构它的nums[i]数组。
方法:这其实很简单,聪明的你们肯定已经发现,将presum[i] = presum[i-1] + nums[i] 这个公式变一下型,就是:nums[i] = presum[i] - presum[i-1] ,然后就和一维前缀的求法一样了~
那这又有什么实际用途呢?
这和高数的求导和差分一样, 用途可多了,而且非常实用~
这里看一道题,你就知道是有多么方便了。
输入一个长度为 n 的整数序列。
接下来输入 m 个操作,每个操作包含三个整数 l , r , c,表示将序列中 [l,r] 之间的每个数加上 c。
请你输出进行完所有操作后的序列。
输入格式
第一行包含两个整数 n 和 m。
第二行包含 n 个整数,表示整数序列。
接下来 m 行,每行包含三个整数l,r,c,表示一个操作。
输出格式
共一行,包含 n 个整数,表示最终序列。
数据范围
1≤ n , m ≤ 100000
1 ≤ l ≤ r ≤ n
−1000 ≤ c ≤ 1000
−1000 ≤ 整数序列中元素的值 ≤ 1000
输入样例:
6 3
1 2 2 1 2 1
1 3 1
3 5 1
1 6 1
输出样例:
3 4 5 3 4 2
如果你没学一维差分,那我初学时也和你们一样,对于每次操作,都用一个循环去给区间的每个元素加上一个c , 这显而易见,我们肯定会超时的,那怎样优化呢,这里就要采用这个妙招了~
解释:你想一下,假如现在你已经构造出来presum[i] 的差分数组 nums[i], 你会想到它的什么特点嘛?
原来,你对num[i] 的一个下标为r1的数组值加上一个 c ,那么将会对它前缀和数组presum[i] 产生很大的影响,即将presum[r1] ~ presum[n] 都加上了一个 c .
Amazing ! ! .这太妙了吧,对,算法就是这么的奇妙,同样的知识翻转一下,用途又大大提高了~
#include <iostream>
using namespace std;
const int N=100010;
int presum[N], nums[N], n, m, l, r, c;
int main(){
scanf("%d%d", &n, &m);
for (int i = 1 ; i <= n ; i++){
scanf("%d", &presum[i]);
nums[i] = presum[i] - presum[i-1]; //构造一维差分
}
while (m--)
{
scanf("%d%d%d", &l, &r, &c);
nums[l] += c;
nums[r+1] -= c; //我们只想对[l , r]区间元素产生影响,需要对r ~ n 元素的影响消除掉。
}
for (int i = 1 ; i <= n ; i++){
presum[i] = presum[i-1] + nums[i]; //我们改变的是nums[i],还要采用一维前缀和求回presum[i]。
printf("%d ", presum[i]);
}
return 0;
}认真点哦 ,掉头发的难点来了~
二维差分就是通过a[][] 的二维前缀和数组b[][] 去求它的二维差分数组a[][],这听上去很简单,但如果将二维差分融入实际问题的求解中去,代码操作起来还是有点费劲的,不过你可以放一百个♥,我一定会用最通俗易懂的那种方法教会你的,哈哈,不吹了,我也没把握~
这里对比一维差分数组的求解,就是巧妙的将求二维前缀和的公式:
b[i] [j] = b[i-1][j] + b[i][j-1 ] - b[i-1][ j-1] + a[i] [j]
转换后求二维差分公式:a[i][j] = b[i][j] - b[i-1][j] - b[i][j-1] + b[i-1][j-1];
这里我就举例一道求子矩阵和的升级版,就是将求得的每个子矩阵全部元素加上一个 c ,然后输出操作完所有步骤后的二维数组。
你看不起谁啊,这题不就是和之前讲的那道一维差分一样的方法嘛!!
先别骄傲,二维差分要考虑的情况要比一维差分复杂多了,并且还是建立在差分的基础上,这题只是这类知识点最典型的实际问题,更为复杂多变的题型还要我们多练,多学习,多总结,这样才算真真掌握了这类知识点 !!
输入一个 n 行 m 列的整数矩阵,再输入 q 个操作,每个操作包含五个整数 x1 , y1 , x2 , y2 , c,其中 (x1,y1) 和 (x2,y2) 表示一个子矩阵的左上角坐标和右下角坐标。
每个操作都要将选中的子矩阵中的每个元素的值加上 c。
请你将进行完所有操作后的矩阵输出。
输入格式
第一行包含整数 n,m,q。
接下来 n 行,每行包含 m 个整数,表示整数矩阵。
接下来 q 行,每行包含 5 个整数 x1,y1,x2,y2,c ,表示一个操作。
输出格式
共 n 行,每行 m 个整数,表示所有操作进行完毕后的最终矩阵。
数据范围
1≤n,m≤1000
1≤q≤100000
1≤x1≤x2≤n
1≤y1≤y2≤m
−1000≤c≤1000
−1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 2 2 1
3 2 2 1
1 1 1 1
1 1 2 2 1
1 3 2 3 2
3 1 3 4 1
输出样例:
2 3 4 1
4 3 4 1
2 2 2 2
这题难点不在如何构造二维差分数组,而在于如何在求出的二维差分数组上加上一个c ,使它的原二维前缀和数组的子矩阵里的所有元素都加上一个c ,这里的操作,很多同学要么写错,要么没考虑全面,这里我就将对此步操作,着重细讲一下,希望能帮助大家理解它~
假设我们已经构建好了二维数组b[][] 的二维差分数组 a[][] ,现在要处理的是如何在a[][] 上加c,使其二维前缀和数组b[][]在指定的子矩阵内的所有元素都加上一个c 。
void insert(int x1, int y1, int x2, int y2, int c)
{
a[x1][y1] += c;
a[x2 + 1][y1] -= c;
a[x1][y2 + 1] -= c;
a[x2 + 1][y2 + 1] += c;
}上面给出的这个自定义函数就能实现上述功能。如果你能看懂那肯定更好啊(先思而后行),
如果没看懂,可以看我给出的图解加以理解~

明白上面这个自定义函数那么你就基本成功了,鼓励下自己吧~
#include <iostream>
using namespace std;
const int N = 1e3 + 10;
int b[N][N], a[N][N];
void insert(int x1, int y1, int x2, int y2, int c)
{
a[x1][y1] += c;
a[x2 + 1][y1] -= c;
a[x1][y2 + 1] -= c;
a[x2 + 1][y2 + 1] += c;
}
int main()
{
int n, m, q;
cin >> n >> m >> q;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cin >> b[i][j],
a[i][j] = b[i][j] - b[i][j-1] - b[i-1][j] + b[i-1][j-1];//构建二维差分数组
while (q--)
{
int x1, y1, x2, y2, c;
cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1, y1, x2, y2, c); //这一步是精髓
}
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
{
b[i][j] = b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1] + a[i][j]; //二维前缀和
}
}
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
{
printf("%d ", b[i][j]);//输出操作完所有步骤后的b[][]
}
printf("\n");
}
return 0;
}看到这里,我如果告诉你这个insert()函数还可以用来构建二维差分数组a[][](不用那个二维差分公式),你相信嘛。哈哈~
答案是肯定的,只不过这需要你对这个函数
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
{
insert(i, j, i, j, b[i][j]); //构建二维差分数组a[][]
}
}主观的解释:我们可以先假想b数组为空,那么a数组一开始也为空,但是实际上b数组并不为空,因此我们每次让a数组以(i,j)为左上角到以(i,j)为右下角面积内元素(其实就是一个小方格的面积)去插入 c=b[i][j],等价于原数组b中(i,j) 到(i,j)范围内 加上了 b[i][j] (既然你都通过二维前缀将a数组构建出了题目给出的b数组,那么是不是说明a[][]就是b[][]的二维差分数组呢!!),因此执行n*m次插入操作,就成功构建了差分a数组.
听懂了嘛?,没听懂的话,你画个图分析下也挺简单的。
作者为啥要给出这个方法啊?哈哈,直接用公式多爽啊,我也想啊,但是我也是在别人的优秀题解中看到的这个方法,真是太秀了,而且理解这个方式,对于我们更为深入掌握二维差分和前缀有一定的帮助的,还有就是方法有很多,但是最好的永远不止于当下,因为它等待我们去探索!!
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳