事实1:Hadoop 不单单是一个产品。刚接触大数据的人通常认为 Hadoop 是数据科学新时代的关键产品。实际上,Hadoop 不单单是一个产品,还是一个生态系统。它由多个开源产品(在 Apache Hadoop 基金会的支特下开发)组成。它们就像幕后引擎一样将大数据转换为做出更明智、更快决策所需的宝贵知识。Apache Hadoop基金会的产品包括 MapReduce、HDFS、Hive、HBase、Pig、Sqoop、 Oozie、Hue、Zookeeper 和 Flume 等。这些产品能够以特定方式组合用于特定的业务分析以及相关的数据源。
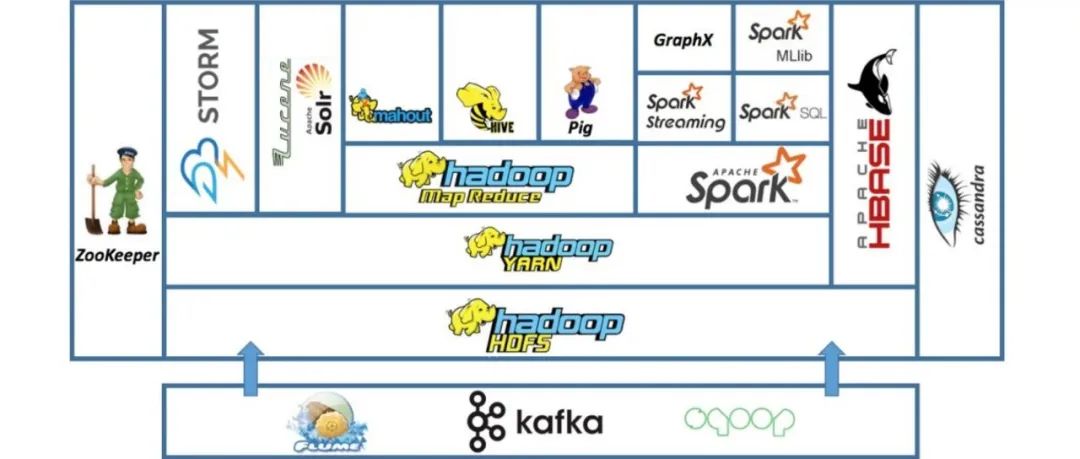
事实2:Hadoop 不仅来自 Apache,还是一个基于社区的生态系统。Hadoop解快方案库包含来自 Apache 基金会的多个产品,同时也包含来自大数据领城众多供应商的很多产品。随着 Hadoop 的发展,越来越多社区和供应商加人其中,以使其尽可能全面和通用。
事实3:Hadoop 是一个开源社区项目。任何人都可以免费使用Hadoop 作为开源软件库。Hadoop可以从Apache 网站 www.apache.org获取。一些初创公司为其他公司提供基于Hadoop库及其扩展特性的打包解改方案,其中扩展特性是根据各户的特定需要和需求定制的。
事实4:Hadoop 和MapReduce 是两个互补的产品。谷歌在发明 HDFS之前就开发了 MapReduce。因此,MapReduce不依赖 HDFS, 而是与其他非HDFS的数据存储技术(包括一些最常见的数据库管理系统)一起工作 (现在仍然可以一起工作)。
事实5:HDFS 是一个文件系统,而不是一个关系型数据库管理系统。Hadoop 主要处理分布式环境中的文件(而不是表和记录)。因此,其数据粒度是文件级的,且没有SQL 查询、关系型数据库、用于快速检索的有意索引以及对索引数据的快速访问等与关系型数据库管理系统相关的常见功能。但是,作为回报,HDFS 能够在文件级别执行关系型数据库管理系统无法执行的操作。
事实6:Hive 看起来像 SQL,但不是标准 SQL。Hive 是用于操作关系型数据库管理系统中数据的标准 SQL 的变体。对于熱悉 SQL 的数据分析师来说,学习使用Hive 编写代码是一个相对快速和简单的过程。大数据领域的很多人相信并希望,随着每次迭代,Hive 将更接近于SQL 的语法,而且,在不久的某个时候,标准SQL将很容易被用于处理 Hadoop 系列产品中的数据。
事实7:Hadoop 不能替代数据仓库。从历史上看,数据仓库旨在处理企业的结构化数据,通常是关系型数据。随着大数据的出现,数据仓库因为无法处理非结构化数据而受到批评。Hadoop 系列产品的目标是通过处理数据仓库无法处理的非结构化数据类型来补充(不是取代,至少目前还不是)数据仓库。
事实8:Hadoop 支持分析。虽然Hadoop 已被互联网公司广泛使用并被两极分化,但是它可以支持任何类型的分析,而不仅仅是网络分析(如分析网络日志和其他基于互联网的数据)。例如,Hadoop 在分析物联网数据方面发挥了重要作用,物联网数据主要是由运输、能源、零售、制造(如预测性维护)、电信和网络安全等行业的机器和传感器生成的。
事实9:MapReduce 不仅仅是分析。虽然 MapReduce 和分析之间存在着密切关系,但是这种关系并不是排他性的。虽然 MapReduce 是一个通用的执行引擎(它能够处理沙及并行编程、网络通信和容错的各和复杂任务),但是它不仅限于分析应用。相反,它可以用来执行任何类型的计算任务。
事实10:Hadoop 不仅与数据量相关,而且还与数据的多样性相关。HDFS 不仅可以处理非常大的分布式文件,而且还可以处理不同类型的文件。这个过程相当简单,任何类型和大小的数据都可以使用在 HDFS 中构建的非常简单和直接的过程进行存储(集中或分布式)和管理。
作者简介:杜尔森·德伦(Dursun Delen),俄克拉荷马州立大学博士。Business Analytics的Spears和Patterson主席、卫生系统创新中心研究主任,以及俄克拉荷马州立大学斯皮尔斯商学院管理科学和信息系统的杰出贡献教授。《预测性分析:基于数据科学的方法(原书第2版)》《商业分析:基于数据科学及人工智能技术的决策支持系统(原书第11版)》《规范性分析:循证管理与最优决策》作者。
本文摘编于《预测性分析:基于数据科学的方法(原书第2版)》,经出版方授权发布。(书号:9787111718345)转载请保留文章出处。
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我正在研究使用EventMachine支持的twitter-streamrubygem来跟踪和捕获推文。我对整个事件编程有点陌生。我如何判断我在事件循环中所做的任何处理是否导致我落后?有没有简单的检查方法? 最佳答案 您可以通过使用周期性计时器并打印出耗时来确定延迟。如果您使用的是1秒的计时器,您应该已经过了大约1秒,如果它更长,您就知道您正在减慢react器的速度。@last=Time.now.to_fEM.add_periodic_timer(1)doputs"LATENCY:#{Time.now.to_f-@last}"@
这里还有一个新手问题:require'tasks/rails'我在每个Rails项目的根路径中的Rakefile中看到了这一行。我猜这行用于要求vendor/rails/railties/lib/tasks/rails.rb加载所有rake任务:$VERBOSE=nil#LoadRailsrakefileextensionsDir["#{File.dirname(__FILE__)}/*.rake"].each{|ext|loadext}#LoadanycustomrakefileextensionsDir["#{RAILS_ROOT}/lib/tasks/**/*.rake"].so
下面的代码通过ftp上传文件并且它有效。require'net/ftp'ftp=Net::FTP.newftp.passive=trueftp.connect("***")ftp.login("***","***")ftp.chdir"claimsecure-xml-files"ftp.putbinaryfile("file.xls",File.basename("file.xls"))ftp.quit但是如何确定上传是否成功呢? 最佳答案 之后ftp.putbinaryfile("file.xls",File.basename("
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
我在尝试从它们的数组中检测某个字符串时遇到了一个奇怪的问题。有人知道这里发生了什么吗?(rdb:1)pmagic_string"TimePeriod"(rdb:1)pmagic_string.classString(rdb:1)pmagic_string=="TimePeriod"false(rdb:1)p"TimePeriod".length11(rdb:1)pmagic_string.length14(rdb:1)pmagic_string[0].chr"\357"(rdb:1)pmagic_string[1].chr"\273"(rdb:1)pmagic_string[2].c
我知道类方法告诉对象类的名称是什么,我怎么知道调用方法的名称?有办法知道吗? 最佳答案 ExaminingtheRubyCallStack共享此信息:您有没有想过在不引发异常的情况下查看调用堆栈?caller.each{|c|putsc} 关于ruby-有没有办法知道调用方法?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1859979/
begin#someroutinerescueretry#onthirdretry,output"nodice!"end我想让它在“第三次”重试时打印一条消息。 最佳答案 可能不是最好的解决方案,但一个简单的方法就是制作一个tries变量。tries=0begin#someroutinerescuetries+=1retryiftries 关于ruby:如何知道脚本是否在第3次重试?,我们在StackOverflow上找到一个类似的问题: https://st
有人知道RubySQL解析器吗? 最佳答案 这是一个使用rparsec完成的SQL解析器的示例:http://docs.codehaus.org/display/JPARSEC/SQL+parser+in+rparsec 关于sql-有人知道RubySQL解析器吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/2488791/
我正在从csv导入数据,我需要将一些值转换为BigDecimal,如果无法解析则引发错误。根据测试,BigDecimal("invalidnumber")返回0的BigDecimal。这没问题,但有点乱,除了有效值为0...Float("invalidnumber")的行为不同并抛出异常...我目前的解决方案是:classStringdefto_bdbeginFloat(self)rescueraise"Unabletoparse:#{self}"endBigDecimal(self)endend我是否完全遗漏了什么? 最佳答案 在