目录
我们都熟知栈是一种先进后出的数据结构,数据只能从一段进入,从这一段出去
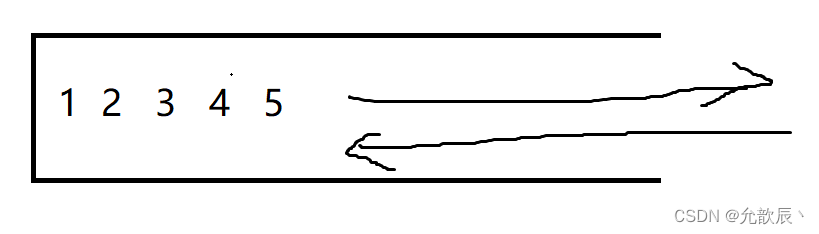
如下图就是抽象的栈结构,数据只能从右端进入,从右端出去,例如只能弹出5(也就是最后插入的元素),要进入6元素,只能在5的后面
我们都熟知队列是一种先进后出的数据结构,数据从一段进出,并从另一端出去
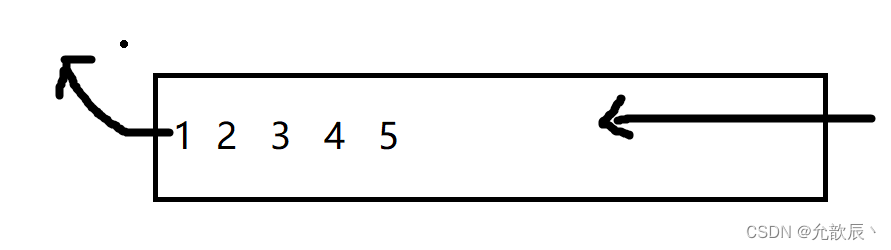
如下图就是抽象的队列结构,数据只能从左端出,从右端进入,例如只能先弹出1(也就是最先进入队列的元素),也只能在右端插入新数据6
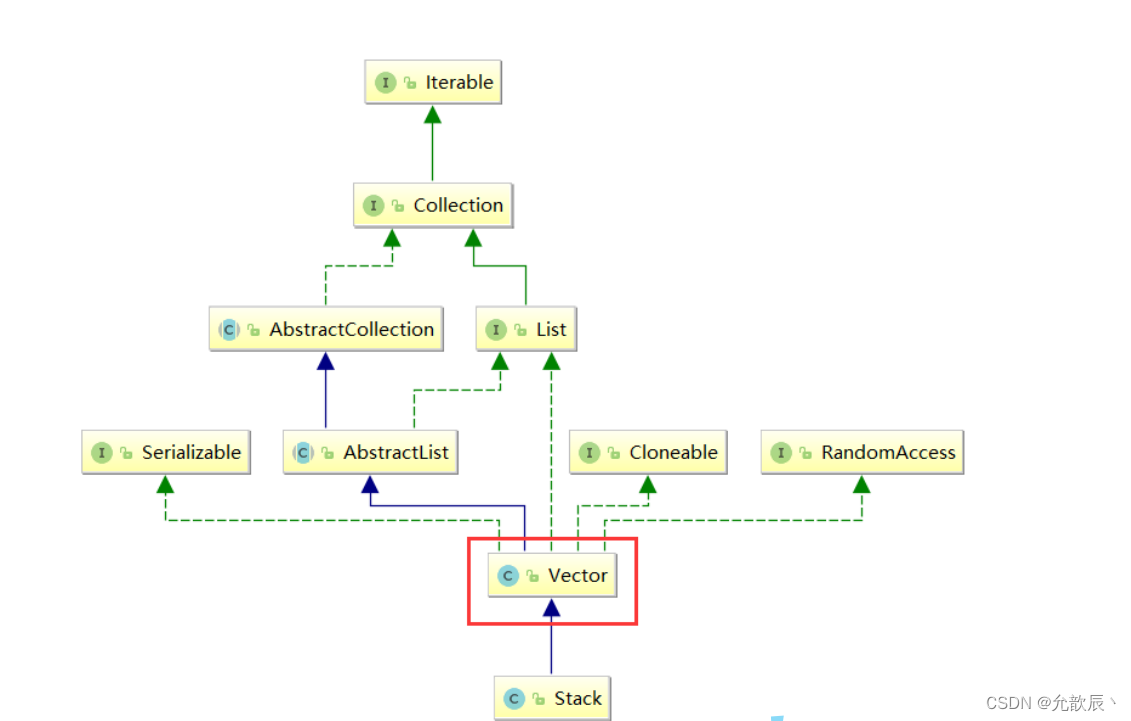
Java API中有专门的栈的API,如图,但是这个类用来实现栈的效率十分低,因为Vector是一个线程安全的类,因此在具体的使用中,我们不建议创建Stack的对象.推荐的我们放在了第三个:双端队列
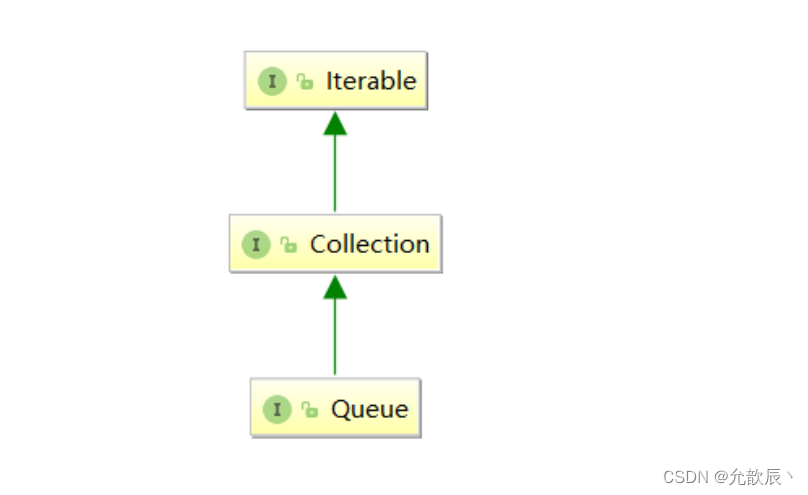
Java中没有命名为Queue的类,但是相应的接口,我们不可以直接创建Queue的对象,因为Queue是接口不是类,但是有实现Queue接口的队列,具体看第三个:双端队列
双端队列虽然叫队列,但他同样也可以实现栈的功能,因此一种API既可以实现栈,也可以实现队列,都有具体的实现方法
我们都知道队列和栈有两种实现的方式,线性表(数组)和链表,同样的双端队列也有两种实现的方式
LinkedList底层使用链表来实现的,现在我们来具体介绍一下实现队列和栈的功能的API
栈
LinkedList<Integer> stack = new LinkedList<>(); stack.push(1); stack.push(2); stack.push(3); stack.push(4); System.out.println(stack);//[4, 3, 2, 1] System.out.println(stack.pop());//4 System.out.println(stack.peek());//3
从以上方法可以看出,LinkedList的确可以实现栈的功能,只需要使用push和pop方法即可
队列
LinkedList<Integer> queue = new LinkedList<>(); queue.offer(1); queue.offer(2); queue.offer(3); queue.offer(4); System.out.println(queue);//[1, 2, 3, 4] System.out.println(queue.poll());//1 System.out.println(queue.peek());//2
从以上方法可以看出,LinkedList的确可以实现队列的功能,只需要使用offer和poll方法即可
总结: 按我的理解就是当执行offer方法的时候,就是在链表的尾部插入数据,执行push方法的时候,就是在链表的头部插入数据,当执行poll方法的时候,就是在链表的头部删除数据,执行pop方法的时候,就是在链表的尾部删除数据,peek方法就是取出链表头部的数据,我们可以使用peekLast取出链表尾部的数据
LinkedList底层使用数组来实现的,现在我们来具体介绍一下实现队列和栈的功能的API
具体方法调用和LinkedList一模一样,只是new对象不同,这里不做更多的介绍
ArrayDeque<Integer> queue = new ArrayDeque<>();
力扣上专门的题目,在这里可以作参考:力扣
我们都知道栈最后入栈的元素最先出栈,而队列最先入栈的元素最后出栈.
用队列来实现栈,我们需要考虑的就是如何将最先入队列的元素置入队列的尾端,最后入队列的元素置入队列的首端(正好符合栈的出栈序列),也就是说原本的{1,2,3,4}顺序,现在需要以{4,3,2,1}顺序存储到队列中.我们可以用双队列来执行
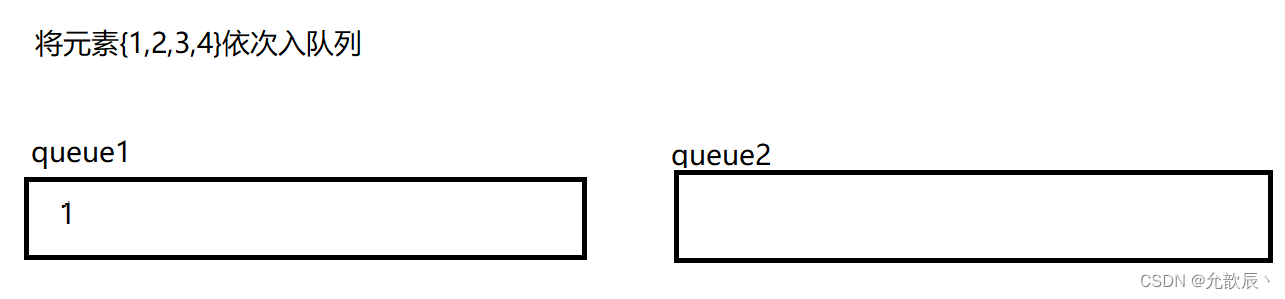
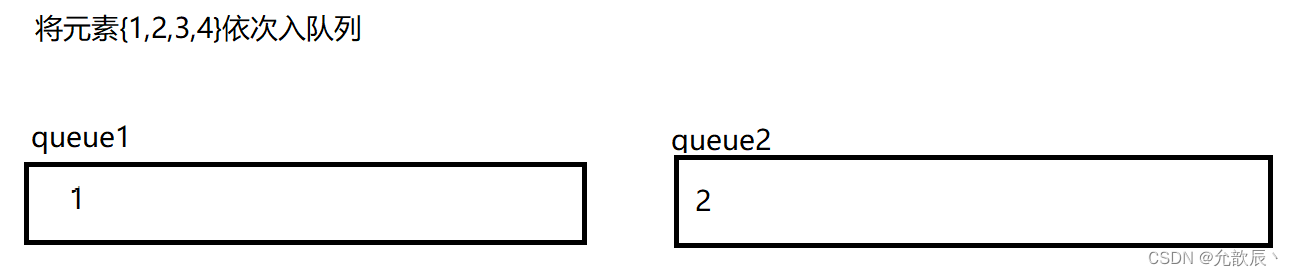
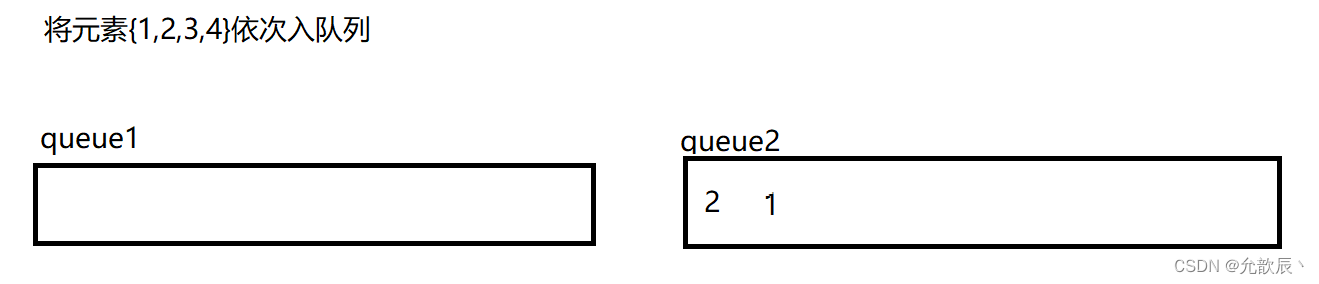
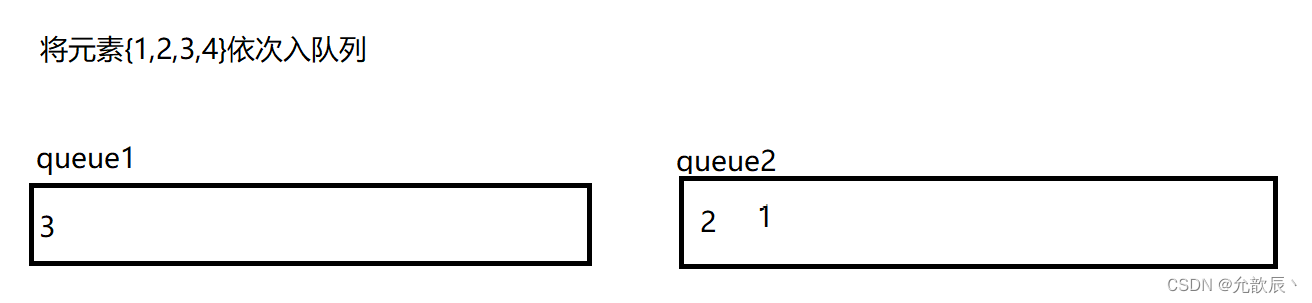
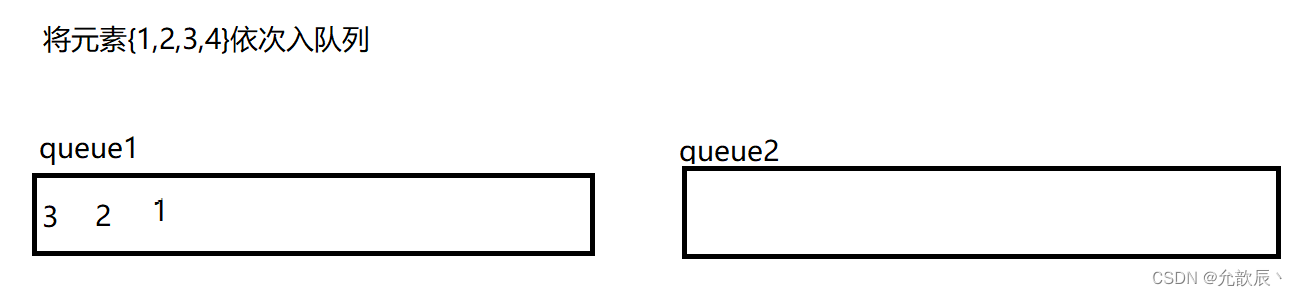
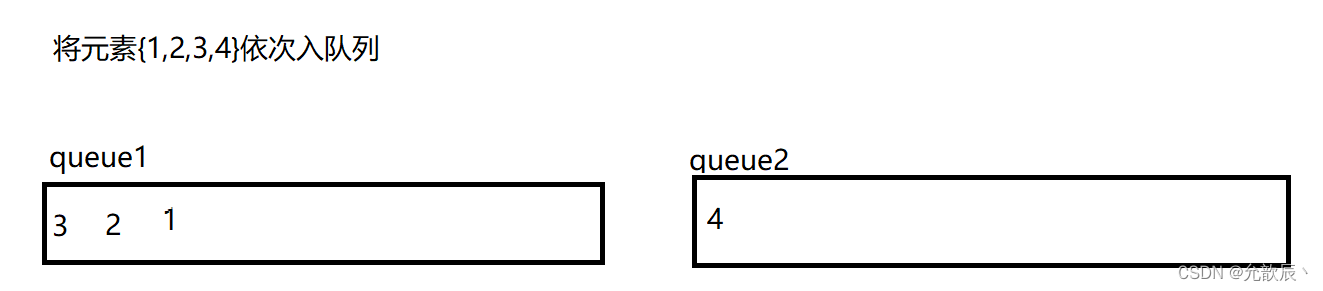
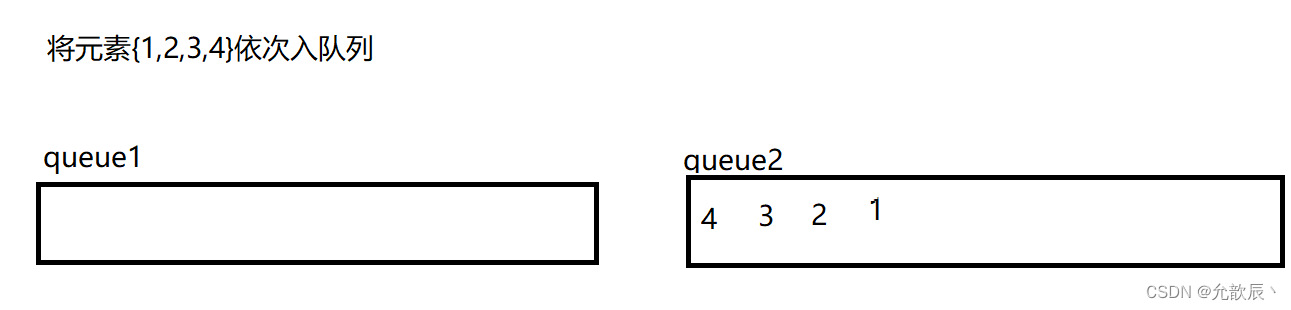
以上便可以用双队列达到了栈的效果,但是我们这样每次数据保存的在队列的位置不确定,我们不妨每次将queue1和queue2的引用进行交换,使得每次queue1引用指向的队列就是我们存放数据的队列.
class MyStack {
//存储元素的队列
private LinkedList<Integer> queue1 = new LinkedList<>();
//辅助队列
private LinkedList<Integer> queue2 = new LinkedList<>();
public MyStack() {
}
public void push(int x) {
queue2.offer(x);
while(!empty()){
queue2.offer(queue1.pop());
}
LinkedList<Integer> temp=queue1;
queue1=queue2;
queue2=temp;
}
public int pop() {
if (empty()) {
return -1;
}
return queue1.poll();
}
public int top() {
if (empty()) {
return -1;
}
return queue1.peek();
}
public boolean empty() {
return queue1.isEmpty();
}
}经历了上面的双队列实现栈,我们其实可以很容易的想到如何使用单队列实现栈的功能,我们只需要每次入队列指定的元素,然后将队列之前的元素重新入队列,便可以实现栈的功能,接下来看演示




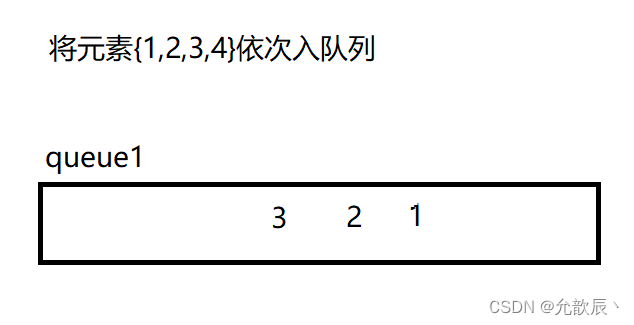


class MyStack {
private LinkedList<Integer> queue = new LinkedList<>();
public MyStack() {
}
public void push(int x) {
queue.offer(x);
int size=queue.size();
for(int i=0;i<size-1;++i){
queue.offer(queue.poll());
}
}
public int pop() {
return queue.poll();
}
public int top() {
return queue.peek();
}
public boolean empty() {
return queue.size()==0;
}
}力扣上专门的题目,在这里可以作参考:力扣
可能很多人会想单队列能够实现栈,单栈一定也能够实现队列,其实我们只能用双栈来实现队列,这是因为栈的特殊性,所以我们这里来讨论双栈实现队列的思路
因为队列的先进先出的,所以这里栈一定要把先进的元素放在栈的顶部,这样才能够满足队列的结构,也就是说我们要把栈的结构倒转过来,这时候一定需要另一个栈的辅助,比如入栈的顺序为{1,2,3,4},这个时候放入到栈中的顺序应该为{4,3,2,1},这样出栈的顺序满足出队列的先进先出的原则.接下里我们使用演示的方式看看如何实现这个功能
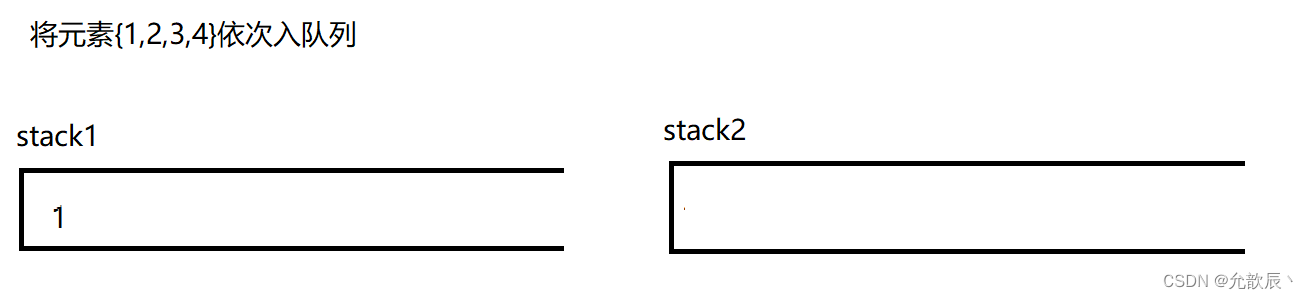
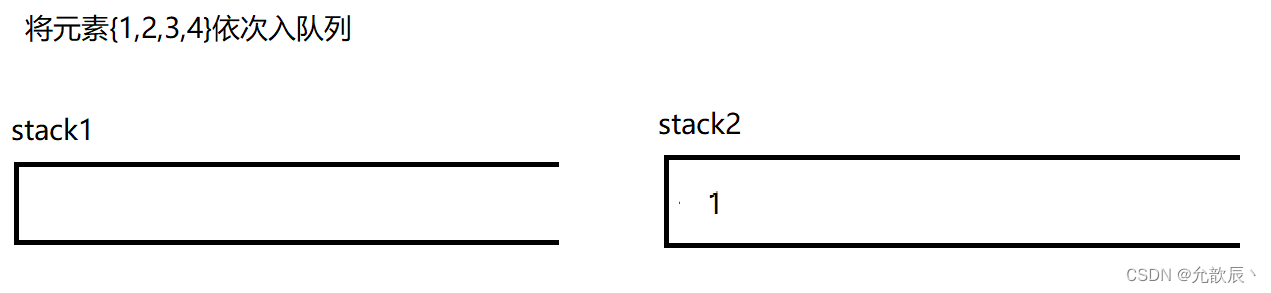
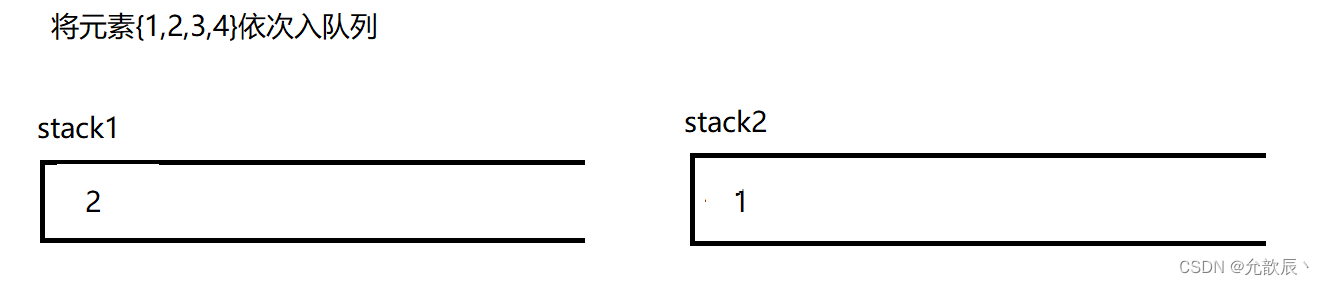
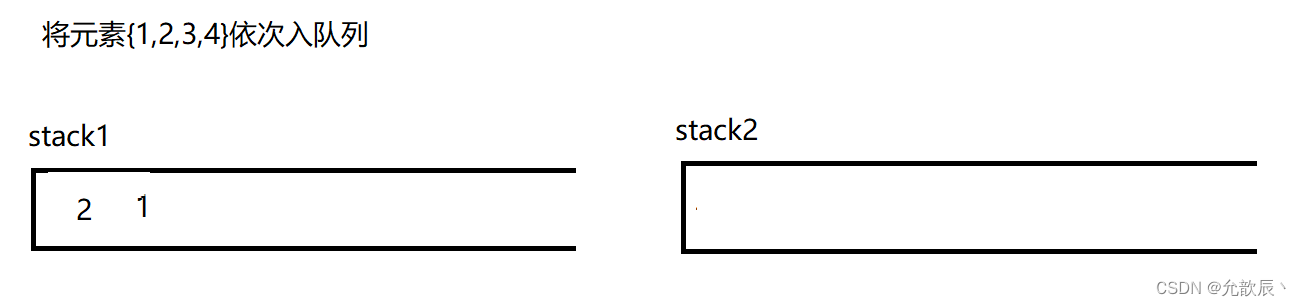
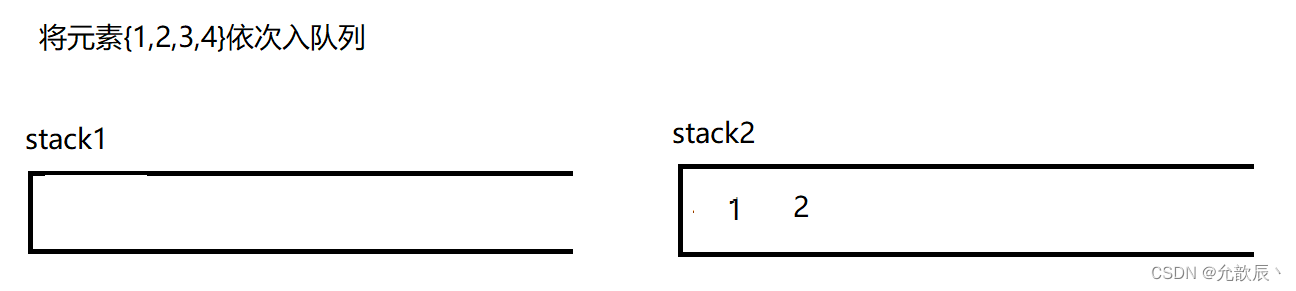
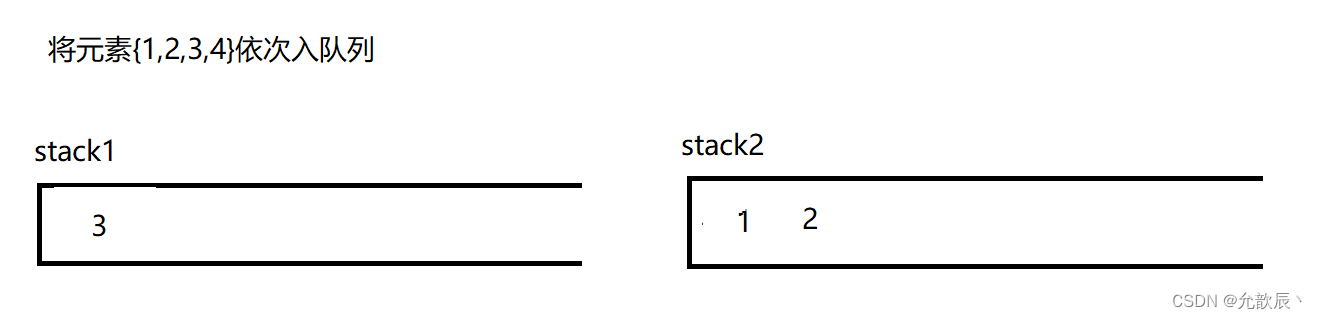
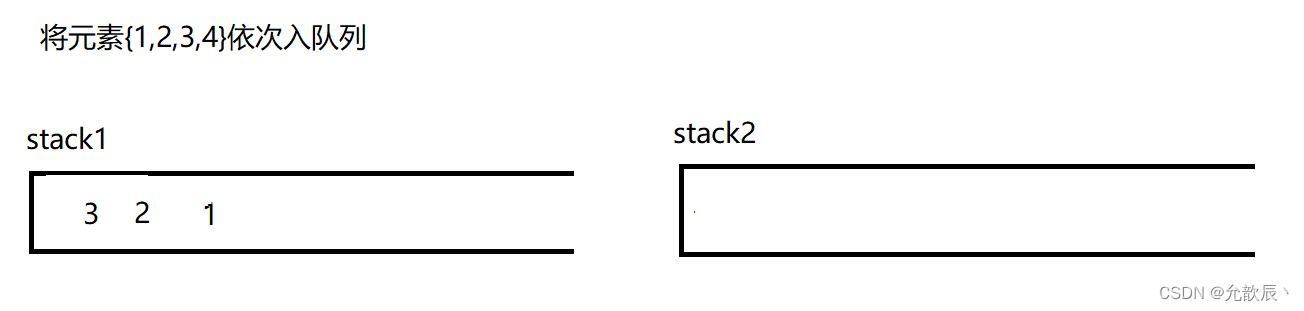
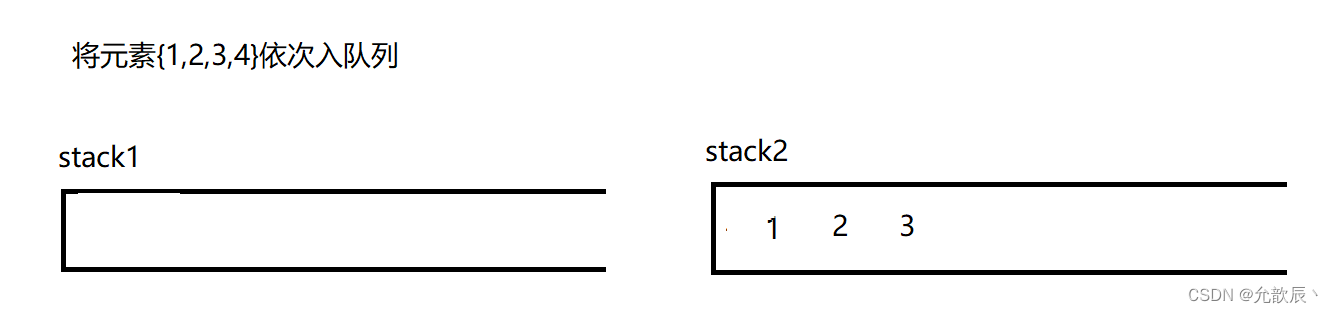
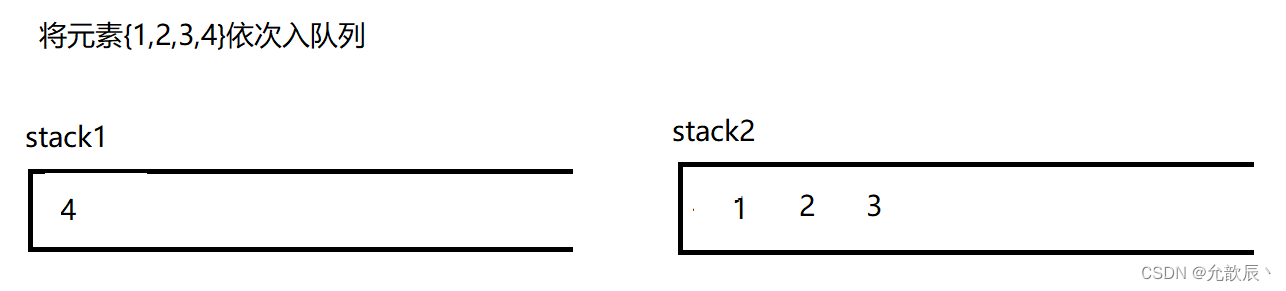
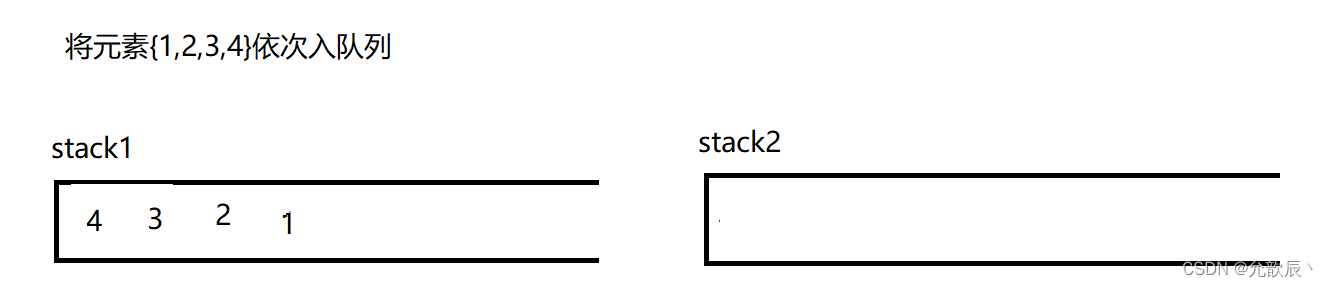
class MyQueue {
LinkedList<Integer> stack1=new LinkedList<>();
LinkedList<Integer> stack2=new LinkedList<>();
public MyQueue() {
}
public void push(int x) {
while(!stack1.isEmpty()){
stack2.push(stack1.pop());
}
stack1.push(x);
while(!stack2.isEmpty()){
stack1.push(stack2.pop());
}
}
public int pop() {
int val=stack1.pop();
return val;
}
public int peek() {
return stack1.peek();
}
public boolean empty() {
return stack1.isEmpty();
}
}给定
pushed和popped两个序列,每个序列中的 值都不重复,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回true;否则,返回false。
力扣:力扣
对于一个序列,因为我们可以在入栈的同时进栈,所以出栈的可以有多种顺序,例如对A,B,C,D入栈,出栈的顺序不一定是D,C,B,A,因为随时可以出栈,比如入栈一个出栈一个,出栈的顺序就为:A,B,C,D
因此判断是否为栈序列,我们判断栈顶元素是否为popped的元素,如果不是将pushed的元素进行入栈,直到栈顶元素为popped的元素,然后对入栈的pushed元素依次进行出栈,直到栈顶的元素不为popped的出栈序列
public boolean validateStackSequences(int[] pushed, int[] popped) {
LinkedList<Integer> stack = new LinkedList<>();
int i=0;
for(int val:pushed){
stack.push(val);
while(!stack.isEmpty()&&stack.peek()==popped[i]){
stack.pop();
i++;
}
}
return stack.isEmpty();
}
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
当我的预订模型通过rake任务在状态机上转换时,我试图找出如何跳过对ActiveRecord对象的特定实例的验证。我想在reservation.close时跳过所有验证!叫做。希望调用reservation.close!(:validate=>false)之类的东西。仅供引用,我们正在使用https://github.com/pluginaweek/state_machine用于状态机。这是我的预订模型的示例。classReservation["requested","negotiating","approved"])}state_machine:initial=>'requested
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下