协同过滤算法(Collaborative Filtering) 是比较经典常用的推荐算法,从1992年一直延续至今。所谓协同过滤算法,基本思想是根据用户的历史行为数据的挖掘发现用户的兴趣爱好,基于不同的兴趣爱好对用户进行划分并推荐兴趣相似的商品给用户。协同过滤算法主要分为两类:
- 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品
- 基于用户的协同过滤算法:给用户推荐与他兴趣相似的用户喜欢的物品
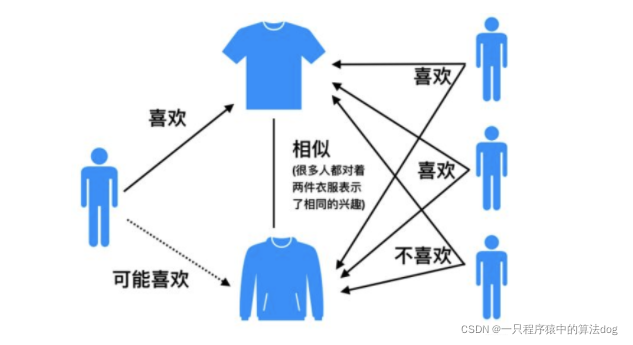
UserCF,思想其实比较简单,当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A没有听说过的物品推荐给A。如图:
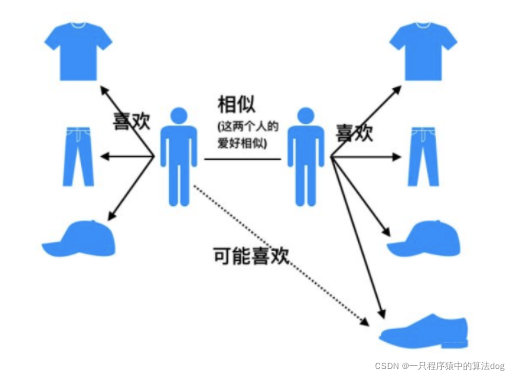
UserCF算法两步骤:
- 找到与当前用户A相似的用户B;
- 将相似用户B喜欢的物品而用户A没有见过的物品推荐给用户A。
那这两步如何做呢?接下来,咱们来个例子具体看一下:
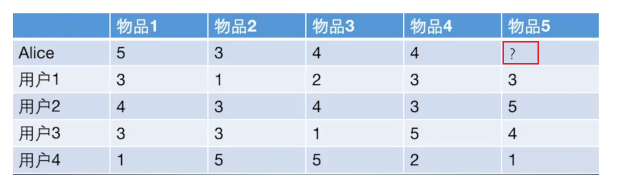
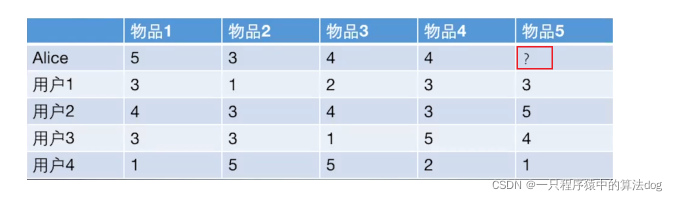
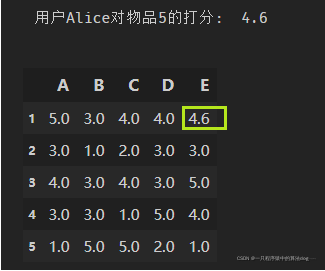
给用户推荐物品的过程可以形象化为给物品打分的过程上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度,分数越高,说明对这个物品越喜欢。
UserCF算法的两个步骤:
杰卡德(Jaccard)相似系数:
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度),jaccard值越大说明相似度越高。
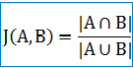
余弦相似度:
如图公式所示,余弦相似度衡量了用户向量i和用户向量j之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
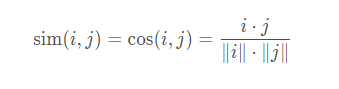
公式中是向量表示,可以换成具体数值,假设用户i和用户j的向量都是n维,那么向量i(x11,x12,x13,…,x1n),j(x21,x22,x23,…,x2n),那么余弦相似度可以表示为
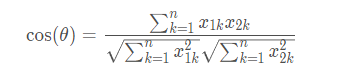
这个在具体实现的时候, 可以使用cosine_similarity进行实现:
from sklearn.metrics.pairwise import cosine_similarity
i = [1, 0, 0, 0]
j = [1, 0.5, 0.5, 0]
consine_similarity([a, b])
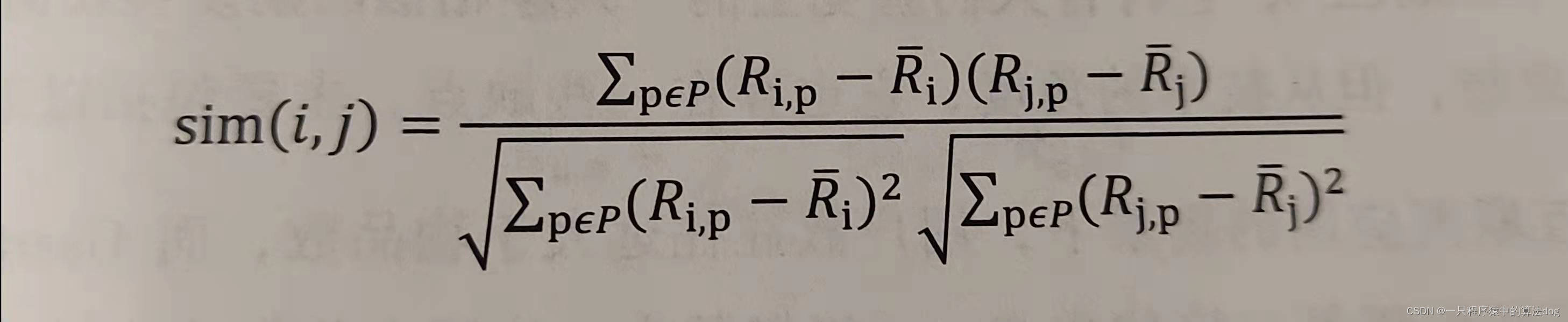
from scipy.stats import pearsonr
i = [1, 0, 0, 0]
j = [1, 0.5, 0.5, 0]
pearsonr(i, j)
根据上面的几种方法, 我们可以计算出向量之间的相似程度, 也就是可以计算出Alice和其他用户的相近程度, 这时候我们就可以选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值, 那么是怎么计算的呢?
可以根据相似用户的已有评价对目标用户的偏好进行预测。这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。如:

还有一种方式如下, 这种方式考虑的更加全面, 依然是用户相似度作为权值, 但后面不单纯的是其他用户对物品的评分, 而是该物品的评分与此用户的所有评分的差值进行加权平均, 这时候考虑到了有的用户内心的评分标准不一的情况, 即有的用户喜欢打高分, 有的用户喜欢打低分的情况。
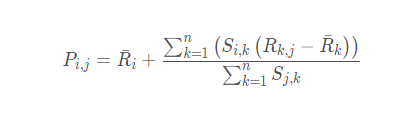
这里的Si,k是用户i和用户k的相似度,Rk,j是用户k对商品j的评分。
1、计算Alice与其他四个用户的相似度(使用皮尔逊相关系数):

如上,Alice与用户1的相似度为0.85,同样方式可以计算出Alice与用户2、用户3、用户4的相似度为0.7,0,-0.79。如果n=2的话,取最相似的两个用户为用户1和用户2。
2、根据相似度用户计算Alice对物品5的最终得分 用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式:

3、根据用户评分对用户进行推荐 这时候, 我们就得到了Alice对物品5的得分是4.87, 根据Alice的打分对物品排个序从大到小:
物
品
1
>
物
品
5
>
物
品
3
=
物
品
4
>
物
品
2
物品1>物品5>物品3=物品4>物品2
物品1>物品5>物品3=物品4>物品2 这时候,如果要向Alice推荐2款产品的话, 我们就可以推荐物品1和物品5给Alice。
这就是userCF。
基于物品的协同过滤(ItemCF)的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c。
基于物品的协同过滤算法主要分为两步:
如果想知道Alice对物品5打多少分, 基于物品的协同过滤算法会这么做:
1、首先计算一下物品5和物品1, 2, 3, 4之间的相似性(它们也是向量的形式, 每一列的值就是它们的向量表示, 因为ItemCF认为物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c, 所以就可以基于每个用户对该物品的打分或者说喜欢程度来向量化物品);
2、找出与物品5最相近的n个物品
3、根据Alice对最相近的n个物品的打分去计算对物品5的打分情况
下面我们就可以具体计算一下, 首先是步骤1:

如上,物品5和物品1的相似度为0.9694,同样方式计算出物品5和物品2、物品3、物品4的相似度为:-0.478、-0.4276、0.5816.
如果n=2的话,取最相似的两个物品为物品1和物品4。
接下来,基于上面的公式计算最终得分:

这时候依然可以向Alice推荐物品5。
两大算法介绍结束。
UserCF代码实现
1、先把数据表给建立起
# 定义数据集, 也就是那个表格, 注意这里我们采用字典存放数据, 因为实际情况中数据是非常稀疏的, 很少有情况是现在这样
def loadData():
items={'A': {1: 5, 2: 3, 3: 4, 4: 3, 5: 1},
'B': {1: 3, 2: 1, 3: 3, 4: 3, 5: 5},
'C': {1: 4, 2: 2, 3: 4, 4: 1, 5: 5},
'D': {1: 4, 2: 3, 3: 3, 4: 5, 5: 2},
'E': {2: 3, 3: 5, 4: 4, 5: 1}
}
users={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
}
return items,users
items, users = loadData()
item_df = pd.DataFrame(items).T
user_df = pd.DataFrame(users).T
2、计算用户相似性矩阵
"""计算用户相似性矩阵"""
similarity_matrix = pd.DataFrame(np.zeros((len(users), len(users))), index=[1, 2, 3, 4, 5], columns=[1, 2, 3, 4, 5])
# 遍历每条用户-物品评分数据
for userID in users:
for otheruserId in users:
vec_user = []
vec_otheruser = []
if userID != otheruserId:
for itemId in items: # 遍历物品-用户评分数据
itemRatings = items[itemId] # 这也是个字典 每条数据为所有用户对当前物品的评分
if userID in itemRatings and otheruserId in itemRatings: # 说明两个用户都对该物品评过分
vec_user.append(itemRatings[userID])
vec_otheruser.append(itemRatings[otheruserId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[userID][otheruserId] = np.corrcoef(np.array(vec_user), np.array(vec_otheruser))[0][1]
#similarity_matrix[userID][otheruserId] = cosine_similarity(np.array(vec_user), np.array(vec_otheruser))[0][1]
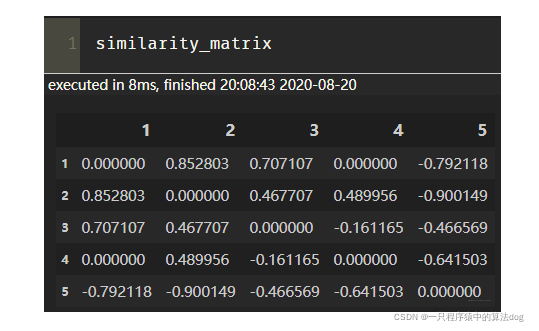
这里的similarity_matrix就是我们的用户相似性矩阵, 长下面这样:
3、计算前n个相似的用户
"""计算前n个相似的用户"""
n = 2
similarity_users = similarity_matrix[1].sort_values(ascending=False)[:n].index.tolist() # [2, 3] 也就是用户1和用户2
4、计算最终得分
"""计算最终得分"""
base_score = np.mean(np.array([value for value in users[1].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for user in similarity_users: # [2, 3]
corr_value = similarity_matrix[1][user] # 两个用户之间的相似性
mean_user_score = np.mean(np.array([value for value in users[user].values()])) # 每个用户的打分平均值
weighted_scores += corr_value * (users[user]['E']-mean_user_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
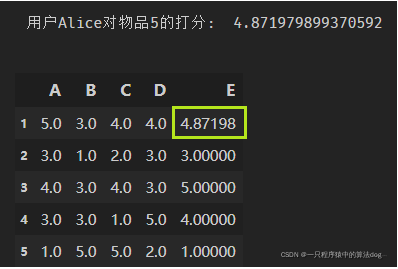
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:
ItemCF代码实现
计算物品的相似矩阵:
"""计算物品的相似矩阵"""
similarity_matrix = pd.DataFrame(np.ones((len(items), len(items))), index=['A', 'B', 'C', 'D', 'E'], columns=['A', 'B', 'C', 'D', 'E'])
# 遍历每条物品-用户评分数据
for itemId in items:
for otheritemId in items:
vec_item = [] # 定义列表, 保存当前两个物品的向量值
vec_otheritem = []
#userRagingPairCount = 0 # 两件物品均评过分的用户数
if itemId != otheritemId: # 物品不同
for userId in users: # 遍历用户-物品评分数据
userRatings = users[userId] # 每条数据为该用户对所有物品的评分, 这也是个字典
if itemId in userRatings and otheritemId in userRatings: # 用户对这两个物品都评过分
#userRagingPairCount += 1
vec_item.append(userRatings[itemId])
vec_otheritem.append(userRatings[otheritemId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[itemId][otheritemId] = np.corrcoef(np.array(vec_item), np.array(vec_otheritem))[0][1]
#similarity_matrix[itemId][otheritemId] = cosine_similarity(np.array(vec_item), np.array(vec_otheritem))[0][1]
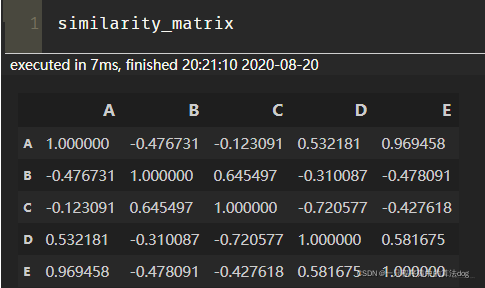
物品的相似矩阵,如下:
然后也是得到与物品5相似的前n个物品, 计算出最终得分来
"""得到与物品5相似的前n个物品"""
n = 2
similarity_items = similarity_matrix['E'].sort_values(ascending=False)[:n].index.tolist() # ['A', 'D']
"""计算最终得分"""
base_score = np.mean(np.array([value for value in items['E'].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for item in similarity_items: # ['A', 'D']
corr_value = similarity_matrix['E'][item] # 两个物品之间的相似性
mean_item_score = np.mean(np.array([value for value in items[item].values()])) # 每个物品的打分平均值
weighted_scores += corr_value * (users[1][item]-mean_item_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:
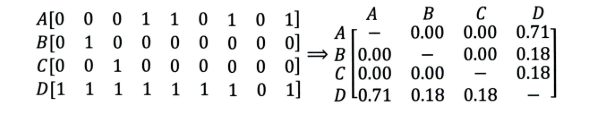
参考:
协同过滤算法
AI-RecommenderSystem
王喆 - 深度学习推荐系统
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实