目录
参考学习:
了解YOLO: https://baijiahao.baidu.com/s?id=1664853943386329436&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/25236464
了解目标检测(推荐):https://www.bilibili.com/video/BV1m5411A7FD
“YOLO”是一个对象检测算法的名字,YOLO将对象检测重新定义为一个回归问题。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。YOLO非常快。由于检测问题是一个回归问题,所以不需要复杂的管道。它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍。YOLOv5是YOLO最新的版本。
在接下来的文章中,我使用的是比较新的版本,YOLOv5-5.0,具有四个输出层,而非三个,其使用PyTorch编写的(PyTorch是一个开源的Python机器学习库)。
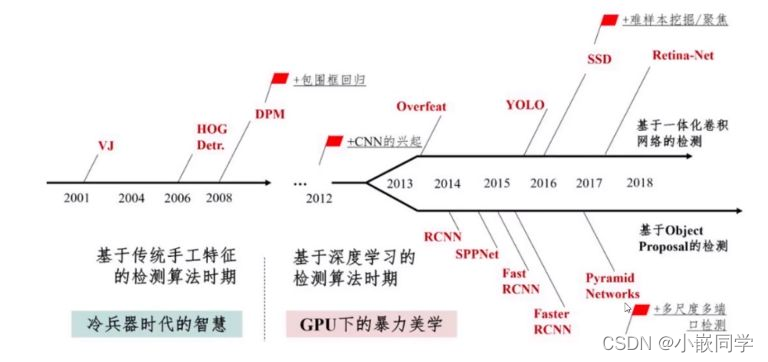
------图片来源于百度百科
参考学习:
https://blog.csdn.net/Prepared/article/details/107294961
https://blog.csdn.net/qq_40716944/article/details/114822515?spm=1001.2014.3001.5501
首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图,比如13*13
(相当于416*416图片大小 ),然后将输入图像分成13*13个grid cells
➢ YOLOv3/v4: 如果GT中某个目标的中心坐标落在哪个grid cell中,那么就由
该grid cell来预测该目标。每个grid cell都会预测3个不同尺度的边界框 。
➢ YOLOv5: 不同于yolov3/v4,其GT可以跨层预测,即有些bbox在多个预测
层都算正样本;匹配数范围可以是3-9个。
预测得到的输出特征图有两个维度是提取到的特征的维度,比如13*13,还有一个
维度(深度)是 B*(5+C)
➢ 注:B表示每个grid cell预测的边界框的数量 (YOLO v3/v4中是3个);
C表示边界框的类别数(没有背景类,所以对于VOC数据集是20); 5表示
4个坐标信息和一个目标性得分(objectness score)

损失函数包括:
• classification loss, 分类损失
• localization loss, 定位损失(预测边界框与GT之间的误差)
• confidence loss, 置信度损失(框的目标性;objectness of the box)
总的损失函数:
classification loss + localization loss + confidence loss
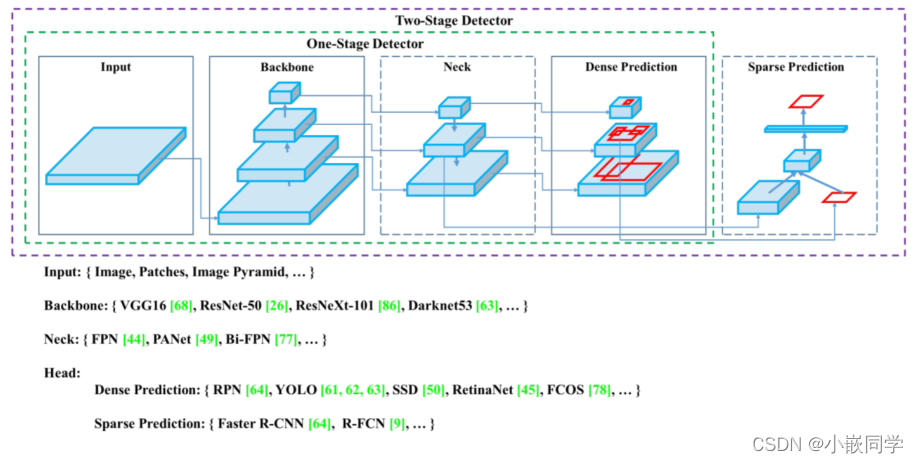
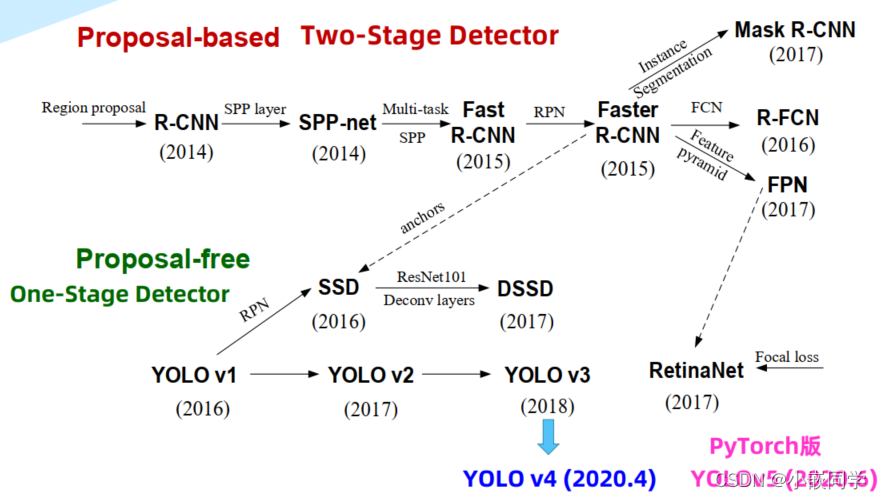
目前目标检测领域的深度学习方法主要分为两类:two stage 的目标检测算法;one stage 的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
YOLOv5 包括
• Backbone: Focus, BottleneckCSP, SPP
• Head: PANet + Detect (YOLOv3/v4 Head)
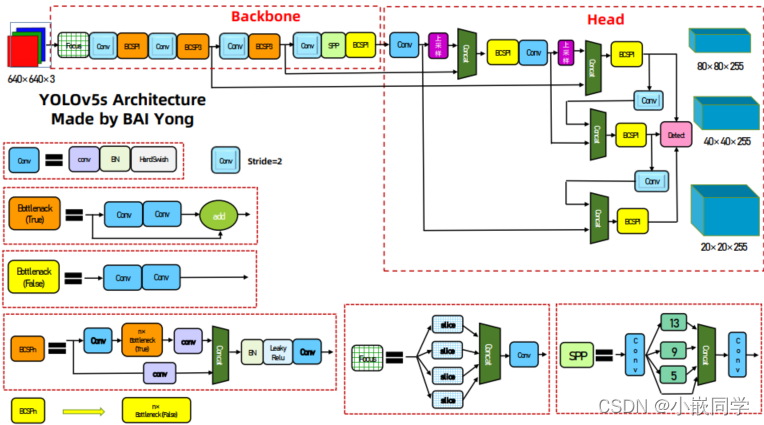
参考学习(必读):
https://zhuanlan.zhihu.com/p/172121380
注:这部分内容其实我并不很懂,也只是看个大概,大致了解,因为我主要是简单了解下,然后直接使用这个开源项目实现我想要的一个功能,并不是去深入学习。自己当前的主要技术积累还是在嵌入式Linux这块,AI这块之后有时间才会去逐步学习。
本文章参考了百度百科,他人技术文章以及哔哩哔哩免费教程,综合整理而来,如有侵权联系删除,小白一个,欢迎大家指导交流!
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使