在官方文档的描述中,API FlinkKafkaConsumer和FlinkKafkaProducer将在后续版本陆续弃用、移除,所以在未来生产中有版本升级的情况下,新API KafkaSource和KafkaSink还是有必要学会使用的。下面介绍下基于新API的一些自定义类以及主程序的简单实践。

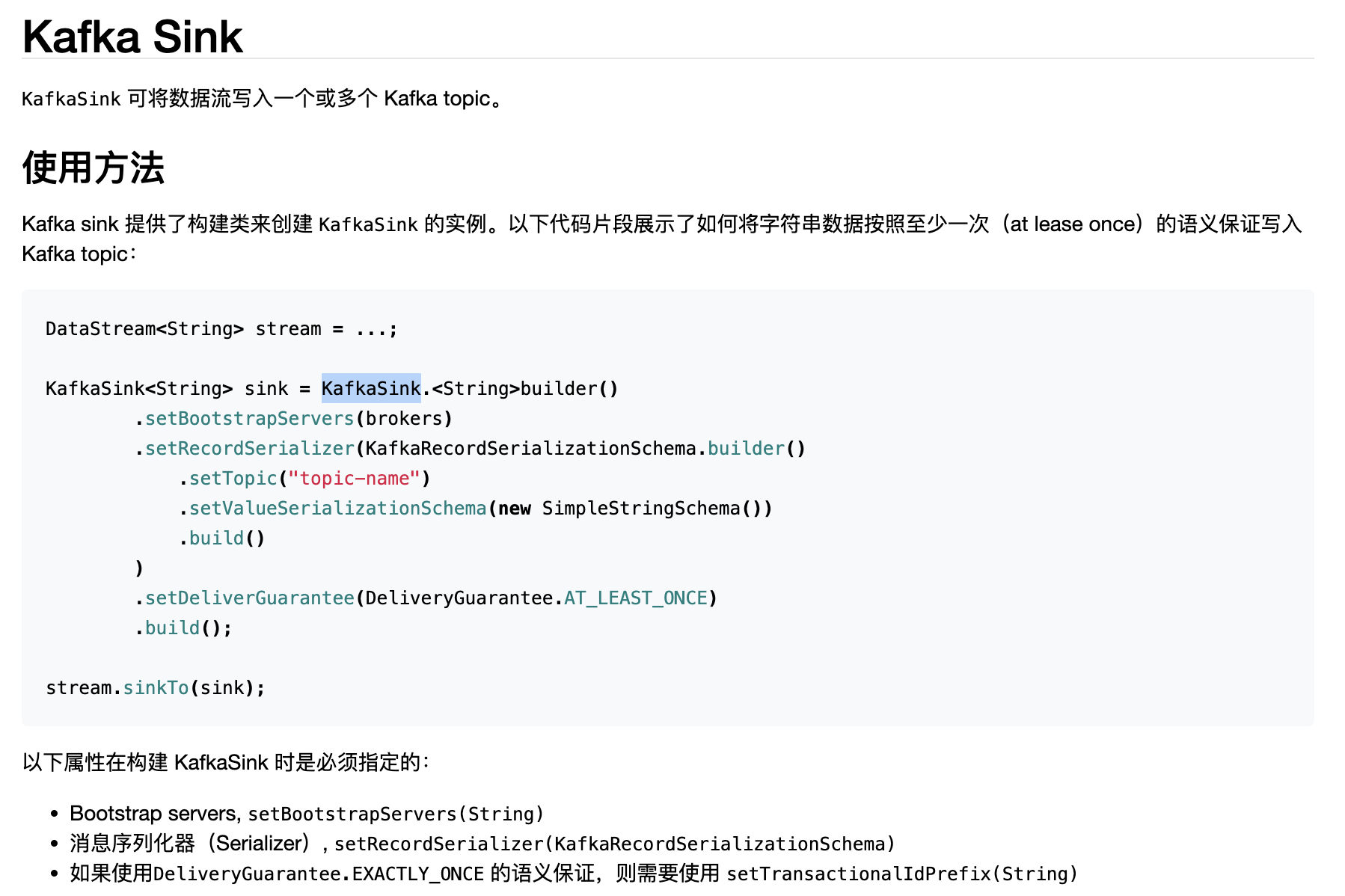


官方文档地址:
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/datastream/kafka/
自定义反序列化器可以以指定的格式取到来源Kafka消息中我们想要的元素。该类需要继承 KafkaDeserializationSchema ,这里简单将来源Kafka的topic、key、value以Tuple3[String, String, String]的格式取出来。
MyKafkaDeserializationSchemaTuple3.scala
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
import java.nio.charset.StandardCharsets
/**
* @author hushhhh
*/
class MyKafkaDeserializationSchemaTuple3 extends KafkaDeserializationSchema[(String, String, String)] {
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String, String) = {
new Tuple3[String, String, String](
record.topic(),
new String(record.key(), StandardCharsets.UTF_8),
new String(record.value(), StandardCharsets.UTF_8))
}
override def isEndOfStream(nextElement: (String, String, String)): Boolean = false
override def getProducedType: TypeInformation[(String, String, String)] = {
TypeInformation.of(classOf[(String, String, String)])
}
}
自定义一个 TopicSelector 可以将流中多个topic里的数据根据一定逻辑分发到不同的目标topic里。该类需要继承 TopicSelector ,这里简单根据来源Kafka的topic名拼接下。
MyTopicSelector.scala
import org.apache.flink.connector.kafka.sink.TopicSelector
/**
* @author hushhhh
*/
class MyTopicSelector extends TopicSelector[(String, String, String)] {
override def apply(t: (String, String, String)): String = {
// t: 来源kafka的topic、key、value
"TOPIC_" + t._1.toUpperCase()
}
}
自定义序列化器可以将数据根据自己的业务格式写到目标Kafka的key和value里,这里将来源Kafka里的key和value直接写出去,这两个类都需要继承 SerializationSchema 。
MyKeySerializationSchema.scala
import org.apache.flink.api.common.serialization.SerializationSchema
/**
* @author hushhhh
*/
class MyKeySerializationSchema extends SerializationSchema[(String, String, String)] {
override def serialize(element: (String, String, String)): Array[Byte] = {
// element: 来源kafka的topic、key、value
element._2.getBytes()
}
}MyValueSerializationSchema.scala
import org.apache.flink.api.common.serialization.SerializationSchema
/**
* @author hushhhh
*/
class MyValueSerializationSchema extends SerializationSchema[(String, String, String)] {
override def serialize(element: (String, String, String)): Array[Byte] = {
// element: 来源kafka的topic、key、value
element._3.getBytes()
}
}
自定义分区器可以根据具体逻辑对要写到目标Kafka 里的数据进行partition分配。该类需要继承 FlinkKafkaPartitioner ,这里根据key的hash分配到不同的partition里(如果目标topic有多个partition的话)。
MyPartitioner.scala
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner
/**
* @author hushhhh
*/
class MyPartitioner extends FlinkKafkaPartitioner[(String, String, String)] {
override def partition(record: (String, String, String), key: Array[Byte], value: Array[Byte], targetTopic: String, partitions: Array[Int]): Int = {
// record: 来源kafka的topic、key、value
Math.abs(new String(record._2).hashCode % partitions.length)
}
}
Main.scala
import format.{MyKafkaDeserializationSchemaTuple3, MyKeySerializationSchema, MyPartitioner, MyTopicSelector, MyValueSerializationSchema}
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.connector.base.DeliveryGuarantee
import org.apache.flink.connector.kafka.sink.{KafkaRecordSerializationSchema, KafkaSink}
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema
import org.apache.kafka.clients.consumer.OffsetResetStrategy
import java.util.Properties
import scala.collection.JavaConverters._
/**
* @author hushhhh
*/
object Main {
def main(args: Array[String]): Unit = {
/**
* env
*/
// stream环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* source
*/
// 定义 KafkaSource
lazy val kafkaSource: KafkaSource[(String, String, String)] = KafkaSource.builder()
// Kafka消费者的各种配置文件,此处省略配置
.setProperties(new Properties())
// 配置消费的一个或多个topic
.setTopics("sourceTopic1,sourceTopic2,...".split(",", -1).toList.asJava)
// 开始消费位置,从已提交的offset开始消费,没有的话从最新的消息开始消费
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// 反序列化,使用之前我们自定义的反序列化器
.setDeserializer(KafkaRecordDeserializationSchema.of(new MyKafkaDeserializationSchemaTuple3))
.build()
// 添加 kafka source
val inputDS: DataStream[(String, String, String)] = env.fromSource(
kafkaSource,
WatermarkStrategy.noWatermarks(),
"MyKafkaSource")
.setParallelism(1)
/**
* transformation
*/
// 数据加工处理,此处省略
/**
* sink
*/
// 定义 KafkaSink
lazy val kafkaSink: KafkaSink[(String, String, String)] =
KafkaSink.builder[(String, String, String)]()
// 目标集群地址
.setBootstrapServers("bootstrap.servers")
// Kafka生产者的各种配置文件,此处省略配置
.setKafkaProducerConfig(new Properties())
// 定义消息的序列化模式
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
// Topic选择器,使用之前我们自定义的Topic选择器
.setTopicSelector(new MyTopicSelector)
// Key的序列化器,使用之前我们自定义的Key序列化器
.setKeySerializationSchema(new MyKeySerializationSchema)
// Value的序列化器,使用之前我们自定义的Value序列化器
.setValueSerializationSchema(new MyValueSerializationSchema)
// 自定义分区器,使用之前我们自定义的自定义分区器
.setPartitioner(new MyPartitioner)
.build()
)
// 语义保证,保证至少一次
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build()
// 添加 kafka sink
inputDS.sinkTo(kafkaSink)
.name("MyKafkaSink")
.setParallelism(1)
/**
* execute
*/
env.execute("myJob")
}
}
以上就是KafkaSource和KafkaSink API的简单使用。大佬们感觉有用的话点个赞吧~😉
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
状态:我正在构建一个应用程序,其中需要一个可供用户选择颜色的字段,该字段将包含RGB颜色代码字符串。我已经测试了一个看起来很漂亮但效果不佳的。它是“挑剔的颜色”,并托管在此存储库中:https://github.com/Astorsoft/picky-color.在这里我打开一个关于它的一些问题的问题。问题:请建议我在Rails3应用程序中使用一些颜色选择器。 最佳答案 也许页面上的列表jQueryUIDevelopment:ColorPicker为您提供开箱即用的产品。原因是jQuery现在包含在Rails3应用程序中,因此使用基
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
如何使此根路径转到:“/dashboard”而不仅仅是http://example.com?root:to=>'dashboard#index',:constraints=>lambda{|req|!req.session[:user_id].blank?} 最佳答案 您可以通过以下方式实现:root:to=>redirect('/dashboard')match'/dashboard',:to=>"dashboard#index",:constraints=>lambda{|req|!req.session[:user_id].b
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara